背景
我们在进行ARIMA建模时,有一个非常重要的事情就是确定其中超参数p, d, q。
一般的流程需要先根据平稳性来确认差分的阶数d,然后根据平稳序列来观察ACF图和PACF图来确认p和q,当然中间还要根据网格训练查看AIC的值来确认,真个过程非常复杂,而且结果还不一定准确;
同时在涉及周期性参数时,工作量会加倍,所以auto_arima自动调参的出现就省去很多麻烦。
auto_arima
auto_arima可以自动尝试不同的阶数组合并挑选出可能的最优模型。可以帮助我们进行定阶,确认模型的参数。
auto_arima参数
class AutoARIMA(BaseARIMA):
# Don't add the y, exog, etc. here since they are used in 'fit'
__doc__ = _doc._AUTO_ARIMA_DOCSTR.format(
y="",
X="",
fit_args="",
return_valid_fits="",
sarimax_kwargs=_doc._KWARGS_DOCSTR)
# todo: someday store defaults somewhere else for single source of truth
def __init__(
self,
start_p=2,
d=None,
start_q=2,
max_p=5,
max_d=2,
max_q=5,
start_P=1,
D=None,
start_Q=1,
max_P=2,
max_D=1,
max_Q=2,
max_order=5,
m=1,
seasonal=True,
stationary=False,
information_criterion='aic',
alpha=0.05,
test='kpss',
seasonal_test='ocsb',
stepwise=True,
n_jobs=1,
start_params=None,
trend=None,
method='lbfgs',
maxiter=50,
offset_test_args=None,
seasonal_test_args=None,
suppress_warnings=True,
error_action='trace',
trace=False,
random=False,
random_state=None,
n_fits=10,
out_of_sample_size=0,
scoring='mse',
scoring_args=None,
with_intercept="auto",
**kwargs,
):
| 参数 | 含义 | 备注 |
|---|---|---|
| y | 要拟合的时间序列 | 必要,array-like or iterable, shape=(n_samples,),⼀维的浮点型数组,不能包含空值和或者无穷’ |
| X | 外置变量 | 非必要,给定额外的特征来帮助预测,需要注意的是,对于预测未来的时序数据的时候,也要提供未来的特征数据 |
| start_p | 参数p的下界 | int, 默认为2 |
| d | ⾮周期的差分阶数 | int, 默认None,如果是None,则⾃动选择,此时,运⾏时间会显著增加。 |
| start_q | 参数q时的下界 | int, 默认为2 |
| max_p | 参数p的上界 | int, 默认为5,max_p>=start_p |
| max_d | ⾮周期的差分阶数d的上界 | int, 默认2,max_d>=d |
| max_q | 参数q时的上界 | int, 默认5,max_q>=start_q |
| start_P | 周期参数P的下界 | int,默认1 |
| D | 周期差分的阶数 | int,默认None,如果是None,则⾃动选择 |
| start_Q | 周期参数Q的下界 | int, 默认1 |
| max_P | 周期参数P的上界 | int,默认2 |
| max_D | 周期的差分阶数的上界 | int, 默认1, max_D>=D |
| max_Q | 周期参数Q的上界 | int,默认2 |
| max_order | p+q+P+Q 组合最大值 | int, 默认5,如果p+q≥max_order,该组合对应的模型将不会被拟合,如果是None的话,对最大阶没有限制 |
| m | 周期数 | int, 默认1,例如年数据 m=1,季度数据m=4,月度数据m=12,周数据52;如果m=1, 则seasonal会被设置为False |
| seasonal | 是否进⾏周期性ARIMA拟合 | bool, 默认True,如果seasonal=True同时m=1,seasonal会被设置为False |
| stationary | 标志该序列是否是平稳序列 | bool, 默认False |
| information_criterion | 模型评价指标 | str, 默认’aic’,可选‘aic’, ‘bic’, ‘hqic’,'oob’ |
| alpha | test的显著性⽔平 | float,默认0.05 |
| test | 单位根检验的类型 | str, 默认’kpss’,当非平稳且d=None才会进⾏检验, 当出现奇异值分解错误可选adf |
| seasonal_test | 周期单位根检验⽅法的标志 | str, 默认‘ocsb’,可选’ch’ |
| stepwise | 是否采用stepwise 算法 | bool, 默认True,可以更快速的找到最佳模型和防止过拟合,但存在不是最佳模型的风险,这样课可以设置成False,模型搜寻范围扩大,耗时也会增加 |
| n_jobs | 并行拟合模型的数目 | int,默认1,如果为-1,则尽可能多的并行,提速用 |
| start_params | ARMA(p,q)的起始参数 | array-like, 默认None |
| trend | 多项式趋势的多项式的系数 | str or iterable,‘n’, ‘c’, ‘t’ , ‘ct’ 选择 ,其中n表示没有,c表示常数,t:线性,ct:常数+线性 |
| method | 似然函数的类型 | str, 默认lbfgs, 可选{‘css-mle’,‘mle’,‘css’}之⼀ |
| maxiter | 求解最大迭代次数 | int, 默认50 |
| transparams | 是否检验平稳性和可逆性 | bool,默认True,如果为True,则进⾏变换确保平稳性,如果为False,不检验平稳性和可逆性 |
| suppress_warnings | 是否过滤掉警告 | bool, 默认True |
| error_action | 是否跟踪错误提示 | str, 默认 ‘trace’,如果由于某种原因无法匹配ARIMA,则可以控制错误处理行为。(warn,raise,ignore,trace) |
| trace | 是否跟踪拟合过程 | bool, 默认False |
| random | 是否随机搜索,而不是超参数空间全搜索或者stepwise搜索 | bool, 默认False |
| with_intercept | 是否需要截距 ,均值漂移 | str, 默认auto |
| disp | 收敛信息的打印控制 | int, 默认0,disp<0表⽰不打印任何信息 |
重要参数解读:
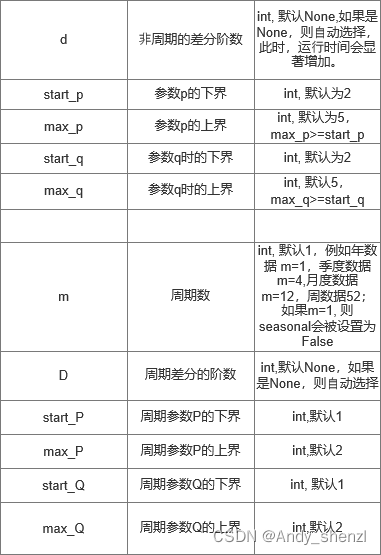
一般情况下差分阶数是需要我们根据平稳性来判定的,所以d和D我们可以自主设置,
如:d = 1 D = 1
start_p、max_p、start_q、max_q,这几个参数可以参照ACF和PACF图给定一个上限值,一般
start_p = 1,start_q = 1,
max_p、max_q根据观察图给定一个上限,模型自行Fit,如果自己不去查看ACF和PACF图,随意写一个比较大的值,也是可以的,但是时间成本比较高;
m 是周期数,这个一般需要配合decompose来查看,不过一般我们可以根据数据的频次来定,比如是月数据那么m=12,周数据m=52等等,m=1则认为没有周期性
start_P、max_P、start_Q、max_Q,只能手动赋值了,如果有知道这个周期性P和Q的定阶方法的大佬请说一下
其他参数:
n_jobs = -1 这样会快一点(其他的函数,只要有这个参数,也建议设置成-1)
stepwise = True,可以更快速的找到最佳模型和防止过拟合
其他参数暂时没有发现特别需要说明的,大家有需要了解的也可以评论区留言