本文是由张彬彬在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对WeNet开源社区的一些工作上的整理,内容涵盖了 WeNet 的最新进展、新项目WeKws,WeSpeeker和WeTextProcessing的介绍,以及去年发布的两个数据集Opencpop和WenetSpeech在今年的一些使用情况。

各位老师,各位同学,各位专家大家下午好。今天很高兴也很荣幸给大家介绍我们WeNet开源社区的一些工作。

在去年的语音技术研讨会上,我们是第一次向大家介绍了WeNet开源社区的一些工作。经过一年的时间,整个开源社区原有的一些项目有进一步的一些最新的进展。同时我们社区也发布了一些新的项目,像WeKws、WeSpeaker、WeTextProcessing,在这里也会给大家做一个介绍。那还有我们社区的两个数据集,在新的一年有一些新的实用情况,在本次报告中也给大家同步一下。

第一部分先给大家简介一下我们的开源社区。

WeNet开源社区是一个专注在语音任务上的社区,也是国内最大的一个开源的语音社区。它的名字跟我们的微信WeChat比较像,寓意的话也非常符合开源的精神。社区的Slogan是“把AI变得更简单”。整个社区的目标还是推动基于深度学习的语音的落地,还有推动开源语音的生态建设。在做整个开源语音的过程中,我们和很多这种国内的一些芯片公司有些交流。整体上,我们看到国内芯片公司其实在生态这方面也有很多很强的一些诉求。所以我们给自己也定了一个小目标,那就是我们能通过开源这件事情,能够助力国产平台和芯片的语音生态建设。

我们的整个方案,算法的方案包括数据,在整个行业内也获得了非常广泛的应用。那我们同时也做了很多的这种知识渠道,像官方的公众号、多达8个的微信交流群、知乎、语音之家WeNet专区等等的一些知识渠道,方便大家快速地去获取我们社区一些算法和数据的一些情况。我们社区和其他语音社区也有比较好的这种互动和合作。整个社区也获得了整个业界包括高校、数据公司、企业、个人开发者等等地广泛支持。

整个社区的项目其实在行业里面有非常非常多的应用案例,像华为、腾讯、京东、网易等等。那也有一些细分领域的独角兽公司,像虎牙、喜马拉雅、58同城、作业帮等等。最近我们也发现其实有很多的这种造车企业特别是一些新势力的造车企业也在用我们的一些方案。那还有就是刚才提到很多芯片公司也在用WeNet社区的一些方案。很多企业在使用WeNet社区的方案之后,获得了比较好的效果,那也和WeNet社区一块去做了技术上的一些推广。
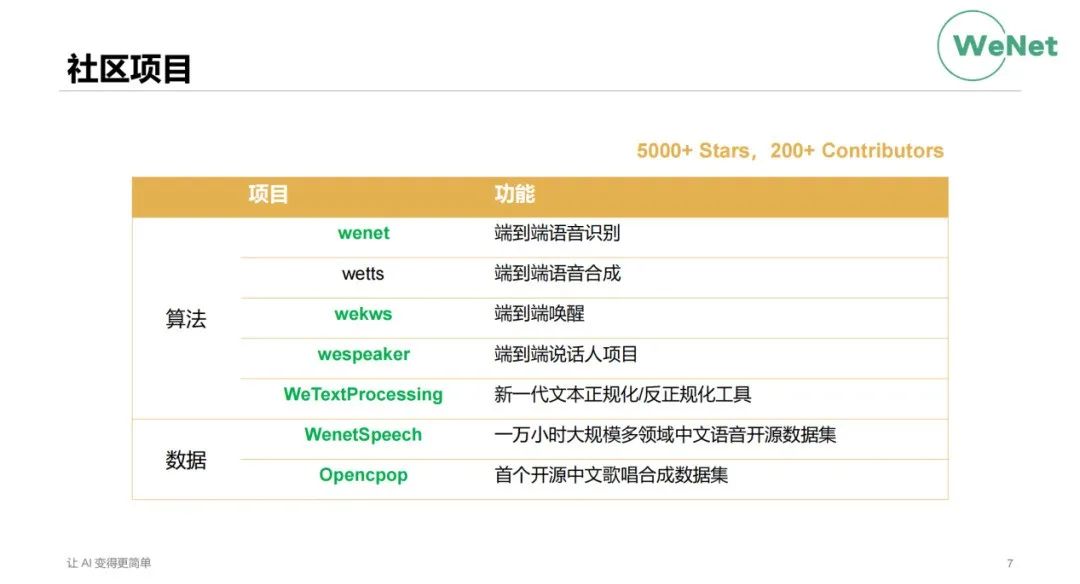
目前社区有下面这几个项目,整体上是包含算法和数据两大块的项目。在算法项目上,目前是包含了识别、合成、唤醒、说话人然后文本正规化、反正规化这几个典型项目。数据上包含了WenetSpeech一万小时大规模中文识别数据集和Opencpop这个国内首个开源的歌唱合成数据集。绿色的是目前我们已经正式发布的一些项目,wetts还是属于我们目前正在研发当中的项目。那今天的话我会给大家重点介绍我们已经发布的项目的一些情况。

第二部分给大家介绍一下我们最核心的一个项目,也就是端到端语音识别项目WeNet的一些最新进展。

第一部分先给大家介绍一下整个WeNet最早的时候关于流式这个问题的一些思考。流式是语音这个任务在产品应用层面上的一个特性。最早的时候,在做WeNet之前,整个国内行业在做流式识别的方案主要还是围绕RNN-T这一块儿在做。那为什么呢?因为很多大公司像谷歌、微软、facebook包括K2都使用RNN-T的一个方案。当时我们自己最早在做的时候也是围绕RNN-T在进行,但是真真正正在做的过程中碰到了很多的一些障碍。首先RNN-T的整个训练代价比较高,可能你需要很多计算资源才能把这个RNN-T跑起来。在当时,整个训练不是特别的稳定,最终效果的话也不尽如人意。所以基于当时那样一个背景,我们做了WeNet这样一个工具。是通过joint CTC/Attention这样一个模型的架构,然后通过U2的算法,最后实现了一个“多快好省”的流式方案。
-
“多”是指WeNet里面基于U2这样一个框架,在同一套模型框架下,它既可以做流式识别也可以做非流式的识别;
-
“快”是指WeNet这种方案相比于RNN-T在损失函数计算上更快和推理时也更快;
-
“好”是指最终我们通过这么一套框架下来在多个数据集上也取得了当时比较领先的效果;
-
“省”是指我们整个训练推理快了,所以也节省了相应的计算和服务资源。
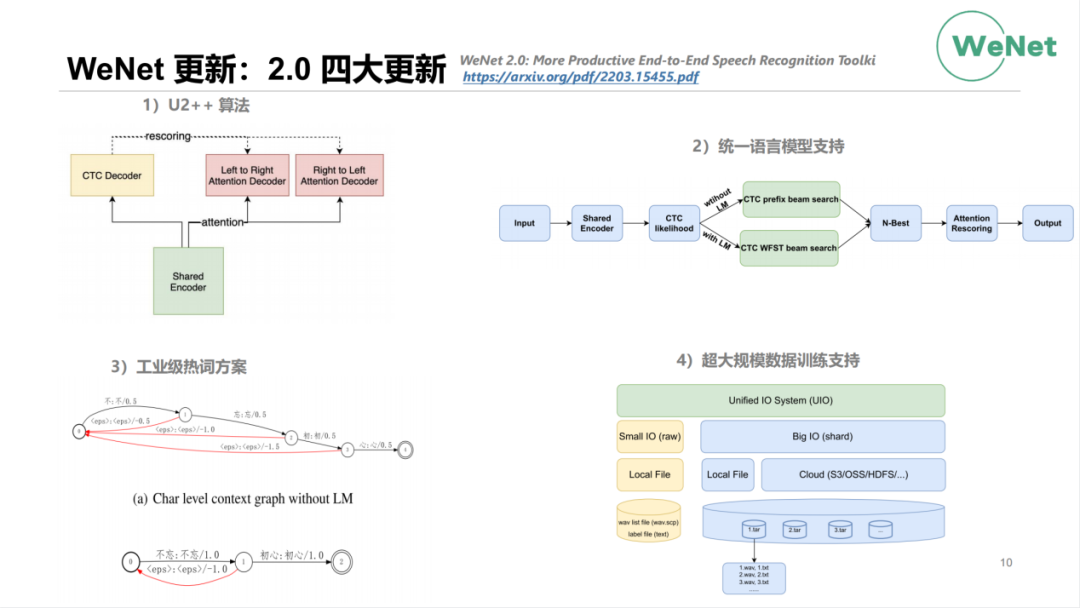
在今年3月份的时候,我们发布了WeNet2.0的四大更新。我们也有写专门的paper去描述WeNet的四大更新,这个paper也是被今年的ICASSP收录。那WeNet的这四个更新包括:
-
第一:新的U2算法的增强版,也就是U2++的算法。它是在U2的基础上,原来我们只有一个前向的attention decoder,那现在的话做了升级,同时增加了前向和反向的attention decoder,能够同时去学习标注序列里前向和后向的信息;
-
第二:是实现了统一语言模型支持。在WeNet中可以使用语言模型也可使用不带语言模型,这个方案对用户整个使用都是透明的;
-
第三:是工业级热词的一个方案;
-
第四:是超大规模数据训练的支持。现在整个工业界语音识别的数据规模都是在10w小时以上这么一个量级,对训练时的I/O提出了一个非常大的挑战。WeNet2.0里我们做了一个UIO的方案,它可以支持从几百小时到数百万小时这样数据规模的训练。它支持本地的存储,也支持分布式的存储。
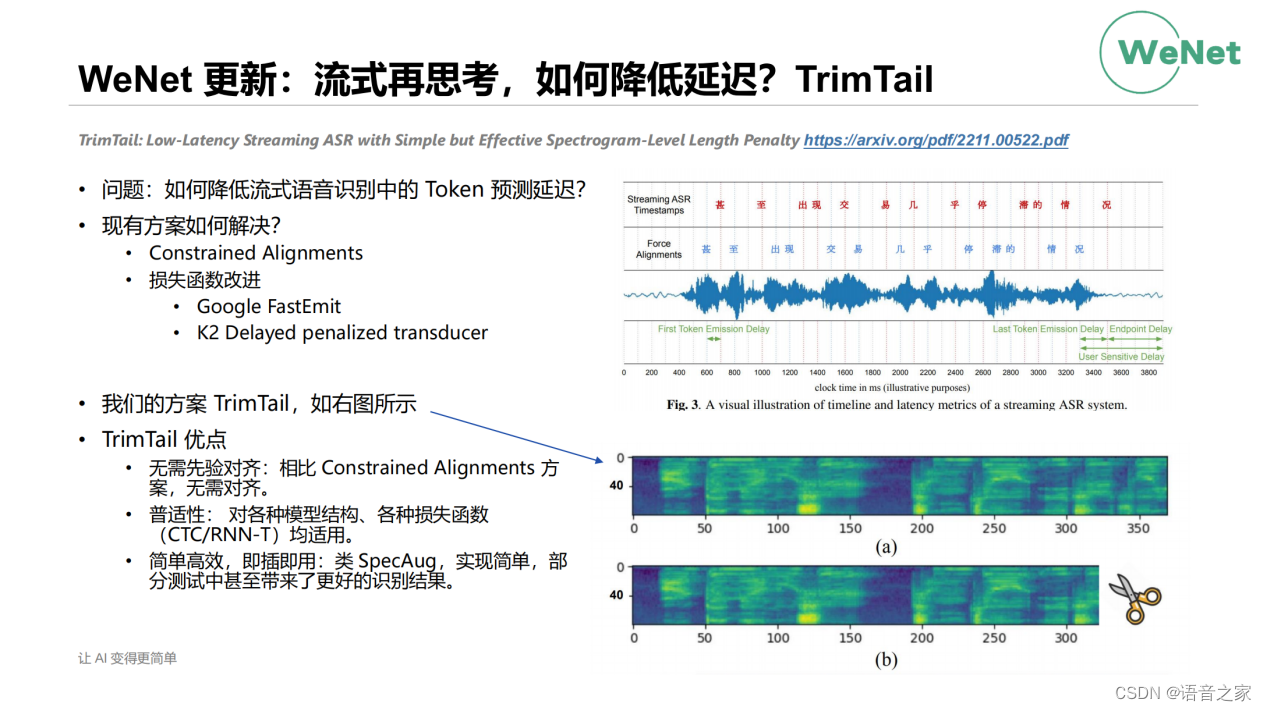
最近也做了很多工作跟大家同步一下。第一个是关于流式的再思考,前面我们是解决了流式能力的问题。流式模型还有另一个问题,就是现在我们所有流式模型在流式预测的时候都会有模型预测出的字的时间较语音中真实时间有一个向后飘移的现象。我们称之为token的预测延迟。在现有的方案里,整个学术界和工业界有通过Constrained Alignments,就是在训练的时候通过一些先验的信息强制模型不要学的太偏,向后移动的不要太远。还有的话就是通过一些损失函数的改进,像Google的FastEmit和K2的Delayed penalized transducer,去达成这样的一个目标。那我们是提出了一个Trim Tail,那整个想法的话是非常非常的简单。就训练的时候直接对数据的尾部进行一个TrimTail,如其名字直接将尾部减掉一块。通过剪掉这一块,能迫使我的模型在预测上整体向前移动。它的优点在于不需要先验对齐,同时我们做了很多实验发现这种方法对各种模型、各种损失函数都适用。整个方法非常简单,即插即用,它未来会成为语音识别训练中类似SpecAug,一个标配性的东西。
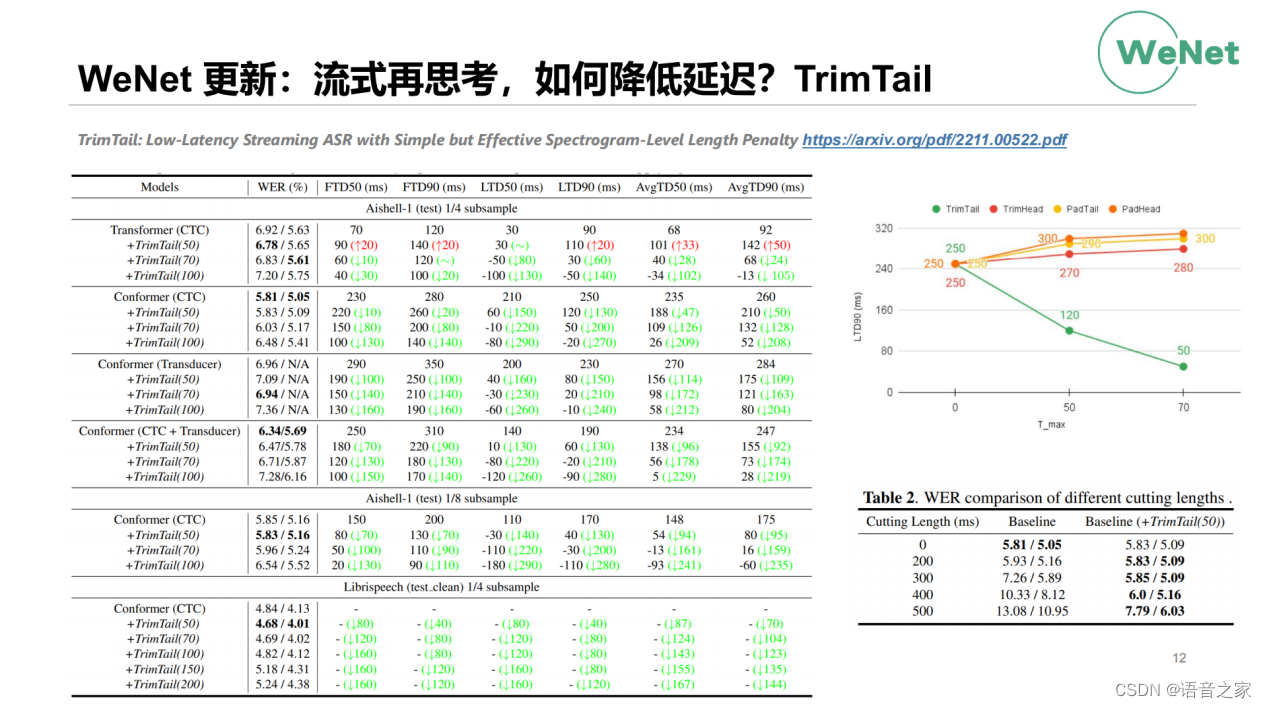
那下面给大家看一下实验结果,绿色是整个延迟降低量。可以看到通过TrimTail这个操作,我们无论是在Transformer、Conformer模型结构上,还是在CTC、Transducer或者CTC+Transducer架构下,无论模型是4还是8的降采样,在AISHELL中文数据集和Librispeech英文数据集上都能获得延迟的下降。基本上整个延迟会在100ms到200ms之间,是一个非常大的收益。同时我们文章也分析了为什么能获得这样的效果,在这里不详细展开。我们同时看到通过这种操作,WER的变化,在很多情况下,通过TrimTail这种操作可以理解为对训练数据做了一定程度上的增强。在部分的测试结果当中,我们可以看到它还可以取得WER上的一些进步。上述是在训练过程中做这个事情,同样我们在测试过程中使用TrimTail,相当于最后的一部分就不用来做推理了,可以看到测试场景下也能取得一部分WER的进步。
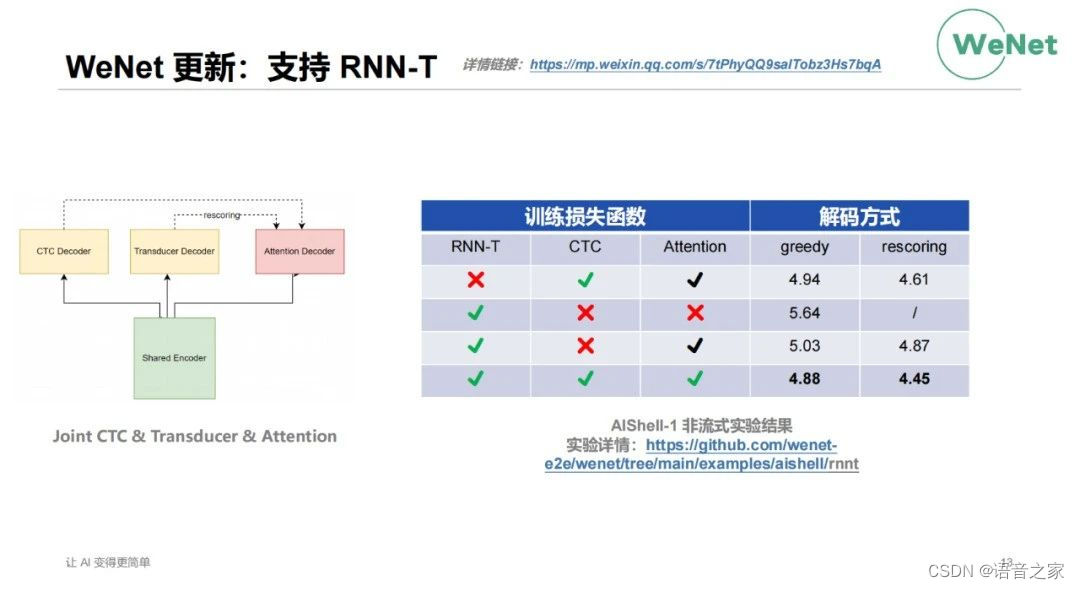
WeNet里最近更新的另一个工作是RNN-T的支持,之前提到最早的时候由于种种原因WeNet没有选择使用RNN-T。但是社区在发展的过程中发现,特别是做研究的同学,整体对RNN-T还是有比较高的诉求。所以整个社区里有一些同学贡献了RNN-T的方案。目前整个方案是一个Joint CTC & Transducer & Attetion,每个部分都可以选择用或不用。根据社区的同学在AISHELL-1上做的实验,单使用RNN-T损失函数,较CTC+Attention的原方案效果较差。RNN-T加上Attention损失函数,相当于是使用Joint CTC+Attention后,效果有较大的提升。三个loss同时使用在流式与非流式上都可以获得进一步的收益。
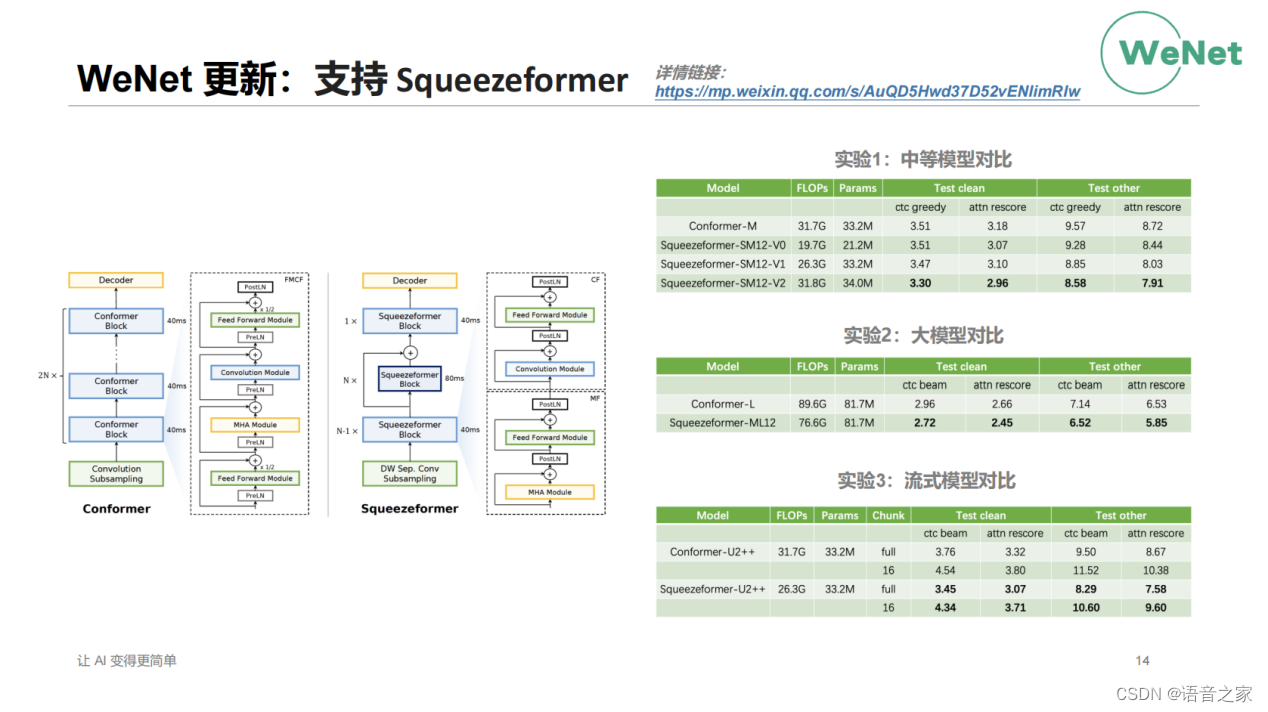
WeNet最近的另外一个更新是支持了Squeezeformer,Squeezeformer通过中间层的下采样,实现了更高效的计算。同时在模型结构上做了一些调整,会让模型训练的更好。整个实验结果表明,无论是在中等模型还是大模型,流式模型还是非流式模型上,Squeezeformer像比如Conformer在LibriSpeech数据集上都获得了WER的降低。
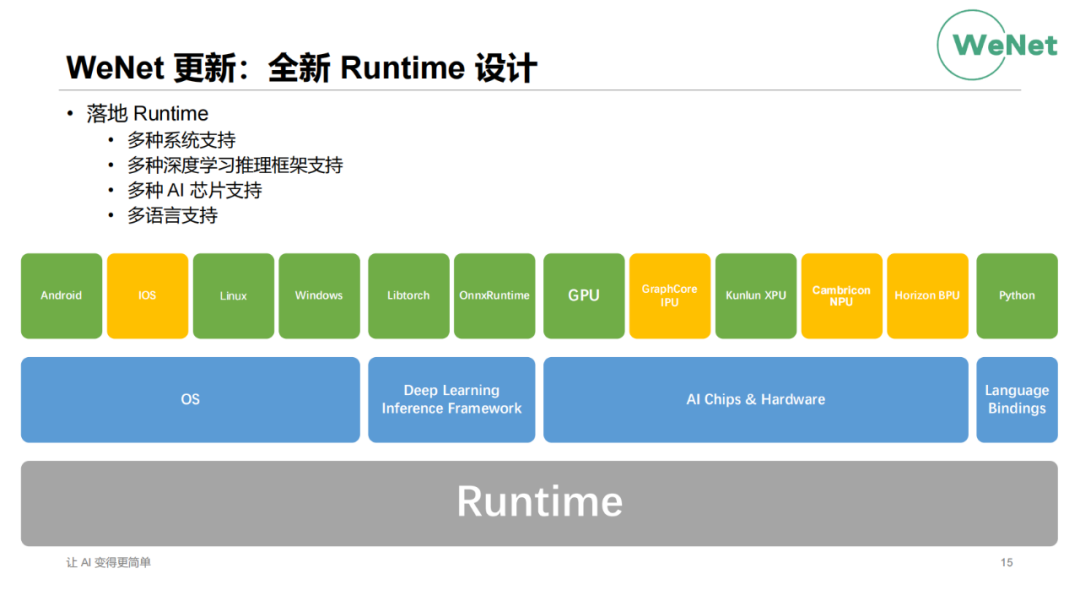
WeNet的第四个更新是全新的Runtime设计。我们知道WeNet最典型的一个特点就是产品优先的方案,这个方案正是依托于Runtime。如图是现在Runtime的大一统的支持,包括多种系统的支持,多种推理框架的支持,多种AI芯片的支持,刚才提到会支持国产的一些芯片。有部分像昆仑芯的国产芯片我们已经做进去它的支持,还有更多的是由社区或芯片公司在持续开发中。还有在做语言Binding方面的一些支持,帮助第三方语言更好地调用WeNet。
WeNet社区内部也进行了下一步计划的讨论,在github上放出了WeNet3.0的Roadmap,大家有兴趣可通过链接前往了解评论。
https://github.com/wenet-e2e/wenet/blob/main/ROADMAP.md
3.0的规划中有以下工作(部分工作已经完成),像onnx的支持、RNN-T的支持、不同语言的一些支持。未来我们想探索的无监督模型,更轻量的端侧模型,多模态的语音识别,其他平台AI芯片的支持。

接下来介绍一下社区新发布的项目:WeKws,WeSpeeker和WeTextProcessing。这三个项目都是在近1个月内进行了一个密集发布。做这些事情的动机也非常简单,我们期望将WeNe上成功的产品优先的设计理念迁移到别的语音任务上,这三个工作就是给出的答案。

我这里做一些概要上的介绍。首先是端到端唤醒WeKws项目,该项目的动机在于目前唤醒在生活中应用广泛,工业界方案众多,部分方案训练部署难度大。同时唤醒由于是需要部署在端侧的任务,需要适配的芯片和平台也很多,适配工作量大。这种工作其实更适合使用开源的、即使开发的模式去做。在1、2基础上,我们发现业界缺乏一个好用的、统一的、针对语音唤醒人物的开源框架。所以我们做了WeKws,也写了相应的论文并投稿到明年的ICASSP。WeKws有以下几个特点:首先类似WeNet,整个设计产品优先,模型默认流式支持,也有像WeNet一样的Runtime框架去做生产力上的一些支持。第二个特点是纯粹的完全端到端方案,这个也是我们比较引以为豪的一个点。论文中我们也分析了我们端到端方案与一些需要VAD方案的比较。整体从性能上看,纯粹的端到端方案还是有一定的优势。第三个特点是整个比较轻量级,一个专注于唤醒的小而精的项目。还有一个特点是高准确率,在三个开源唤醒数据集上实验都取得了比较有竞争力的结果。

第二个我们最近发布的项目是端到端说话人项目WeSpeaker。该项目动机与前面的项目都比较像。它整个项目的特点是高质量、高精度。同样的整个项目我们也有写一个文章,投向ICASSP,这是文章的一个链接。在文章中我们也是在多个数据集上做了相应的实验,这里面也有列一些参考的方案。WeSpeaker的效果最终还是非常有竞争力。第二个特点是轻量级,也是专注与说话人表征学习任务,尽量做得专而精,小而美。第三个特点与WeNet的UIO比较像,在WeSpeaker里也做了相应的支持。Speaker一般训练的数据量也比较大,存在和ASR一样的问题。在WeSpeaker里我们还提供了在线的数据增强,和前两个项目一样,WeSpeaker也提供了部署的方案。

我们最近发布的另一个工具是WeTextProcessing,它是面向新一代的TN/ITN工具。TN/ITN这个任务看似简单,当你真正使用的时候,你会发现市面上的工具多多少少都有一些问题。这也是我们做WeTextProcessing这个项目的一个动机。WeTextProcessing的设计有两个准则:第一个产品优先,我们使用基于语法规则的WFST方案,使用户精准可用。第二是基于pynini的方案可以让用户方便的使用Python定制自己的语法或是快速修复badcase。整个工具使用上也是简单易用,Python环境可以一键安装。在C++生产环境下依赖也做到了最小,只依赖OpenFST这一个工具。

第四部分给大家介绍一下我们去年发布的两个数据集Opencpop和WenetSpeech在今年的一些使用情况。

WenetSpeech到现在一共有1500+的申请,包含高校、研究所、企业等等。我们做这个数据集的一个动机在于学术界和工业界由于数据的不匹配而有较大的鸿沟。可以看到申请数据里有高校也有企业的机构,那高校和企业在这一份数据上的研究成果就可以实现共享和相互参考。下面是WenetSpeech整个的一个下载情况,国内的省份都有下载WenetSpeech的数据,那也说明每个省份都有做相应的研究工作。这里注明一下,由于WenetSpeech数据量大而且copy数也非常高,数据托管的成本也非常高,免费的下载服务是由天籁实验室提供点。

我们另一个数据集是Opencpop,这个数据集是和网易伏羲、上海视觉艺术学院、西北工业大学、网易天音等一起做的歌唱合成的数据集,也是中文领域的首个歌唱合成数据集。截止目前为止,数据集有600+的申请,我们从后台看到申请的来源也非常的广泛,还是非常有力地去促进了中文歌唱合成的研究。

宝秋老师认为开源需要回归开源的本质:开放、共享、平等、协作、创新这五个基本点。在这里我借用宝秋老师对开源另一个更宏大的定义:在互联网、大数据和人工智能时代,开源是人类技术进步的最佳平台和模式。


![Bandit算法学习[网站优化]01——Multiarmed Bandit 算法引入](https://img-blog.csdnimg.cn/img_convert/b239898a02a96016e951d7da9471e9f3.png)