OOM分析&实战
- 引言:
- 一、JVM内存结构
- 二、JVM OOM错误情况
- 三、实践
- 案例一
- 案例二
- 案例三
- 四、总结
- 五、分析工具推荐
- 六、参考文献
引言:
在Java开发中,随着应用程序变得越来越复杂,内存管理问题也变得愈加重要。而在JVM中的"OOM"(Out of Memory)错误是Java程序员经常面临的一种挑战。本文将深入探讨JVM OOM错误,了解其原因、种类以及如何处理,在文中的最后,也总结了常用的JVM内存分析工具。
一、JVM内存结构
知其然,知其所以然。为了更好地理解JVM OOM错误,首先可以先了解JVM的内存结构。JVM将内存划分为以下几个区域:
- 堆内存(Heap): 堆内存是用于存储对象实例的主要区域。在堆中,包括新生代(Young Generation)、老年代(Old Generation)和永久代(或元数据区,Metaspace)等子区域。
这里的新生代、老年代…只针对部分虚拟机而言,众所周知,虚拟机发展至今,也有不采用分代设计思想的虚拟机。
- 方法区(Method Area): 方法区用于存储类的信息、常量池、静态变量等。在Java 8及之后的版本中,方法区被取代为Metaspace。
- 虚拟机栈(Stack): 栈内存用于存储方法调用的局部变量、操作数栈、方法出口等信息。
- 本地方法栈(Native Method Stack): 用于执行本地方法(Native Method)的栈。
在Java虚拟机规范中,对这一部分的实现并没有规定,像Hot-Spot虚拟机会把它和虚拟机栈合二为一。
- 程序计数器(Program Counter Register): 记录正在执行的字节码指令地址。

值得一提的是在上述区域中,程序计数器是唯一一个在Java虚拟机规范中没有规定任何OOM情况的区域。那么其他区域会在什么情况出现OOM呢?
二、JVM OOM错误情况
除去程序计数器,其他区域根据Java虚拟机规范,在无法满足新的内存分配需求时,将抛出OOM异常。根据区域的不同,大致可以划分为如下几种情况:
- 堆内存溢出(Heap Space OOM): 当堆内存无法满足新对象的分配请求时,会发生堆内存溢出错误。这通常是由于创建了太多的对象或某些对象过大,而堆内存不足以容纳它们引起的。
- 方法区溢出(Metaspace OOM): 在Java 8及之后的版本中,方法区被取代为Metaspace,如果加载的类或元数据信息过多,会导致Metaspace溢出错误。
- 栈内存溢出: 这个区域在递归调用的深度过深,导致栈帧无法被正常释放时,会抛出Stack OverflowError,如果虚拟机栈支持动态扩展,则扩展失败时会抛出OOM。
- 本地方法栈溢出(Native Method Stack Overflow): 类似于栈内存溢出,但是发生在本地方法调用时。
上述区域为虚拟机运行时数据区的一部分,而在这之外,还有一个叫做直接内存的区域,该区域也不是Java虚拟机规范中定义的区域。我们知道,在JDK1.4 中,NIO类引入了基于Channel与Buffer的I/O方式,通过Native函数库直接分配堆外内存。而对这部分的内存使用,如果不加以管理,同样存在OOM情况。
尽管我们知道了可能发生OOM的区域,但在OOM发生时还是容易头大,这一方面可能是由于日志链路不足以支撑分析,一方面也可能是经验不足,排查思路不够清晰。下面以业务上的几次OOM实践经历作为分析,会讲述在日志情况不足以定位到OOM时,做了哪些尝试,同时梳理了排查定位思路,希望能帮上一二。
三、实践
案例一
某次午休时间,突然告警,原因是OOM导致容器重启了。由于重启后,日志文件随之情况(该服务平常无日志采集),无开启OOM dump现场配置,可以说是两眼一黑。

该情况无从下手,那么我们优先开启如下配置,在OOM时进行dump,并保存至/app目录,观察分析一段时间。
java -XX:HeapDumpPath=/app/dumpfile.hprof -jar YourApplication.jar
一天过去后,仍然无果,无OOM、无告警。那么此时暂且排除某个大对象直接导致OOM可能,怀疑是否存在内存泄漏,即应用程序中存在着回收不掉的对象,一直在堆积,且有较大概率非用户操作引起的(因为之前在一天的用户操作过程中也没再发生)。那么开启第二个参数(NMT),用于Java虚拟机(JVM)本机内存跟踪,这个参数会让程序有一定的性能损耗,线上服务需要进行足够的评估。这里在预发机器上添加了该配置:
- -XX:NativeMemoryTracking
启动机器,打印内存情况,打印参数如下:
jcmd pid VM.native_memory summary
内存情况如下:
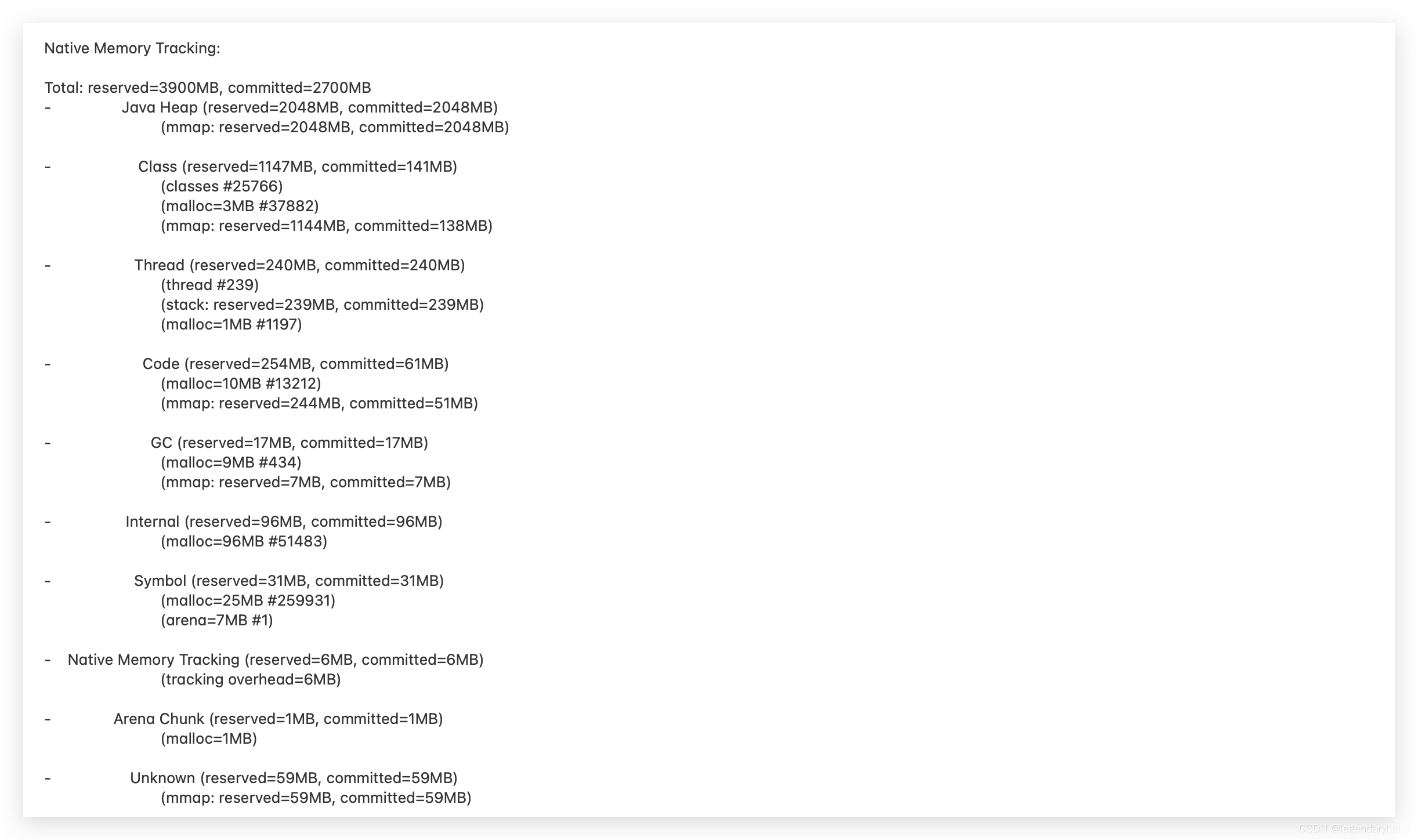
同样在运行一天后,再打印内存情况:
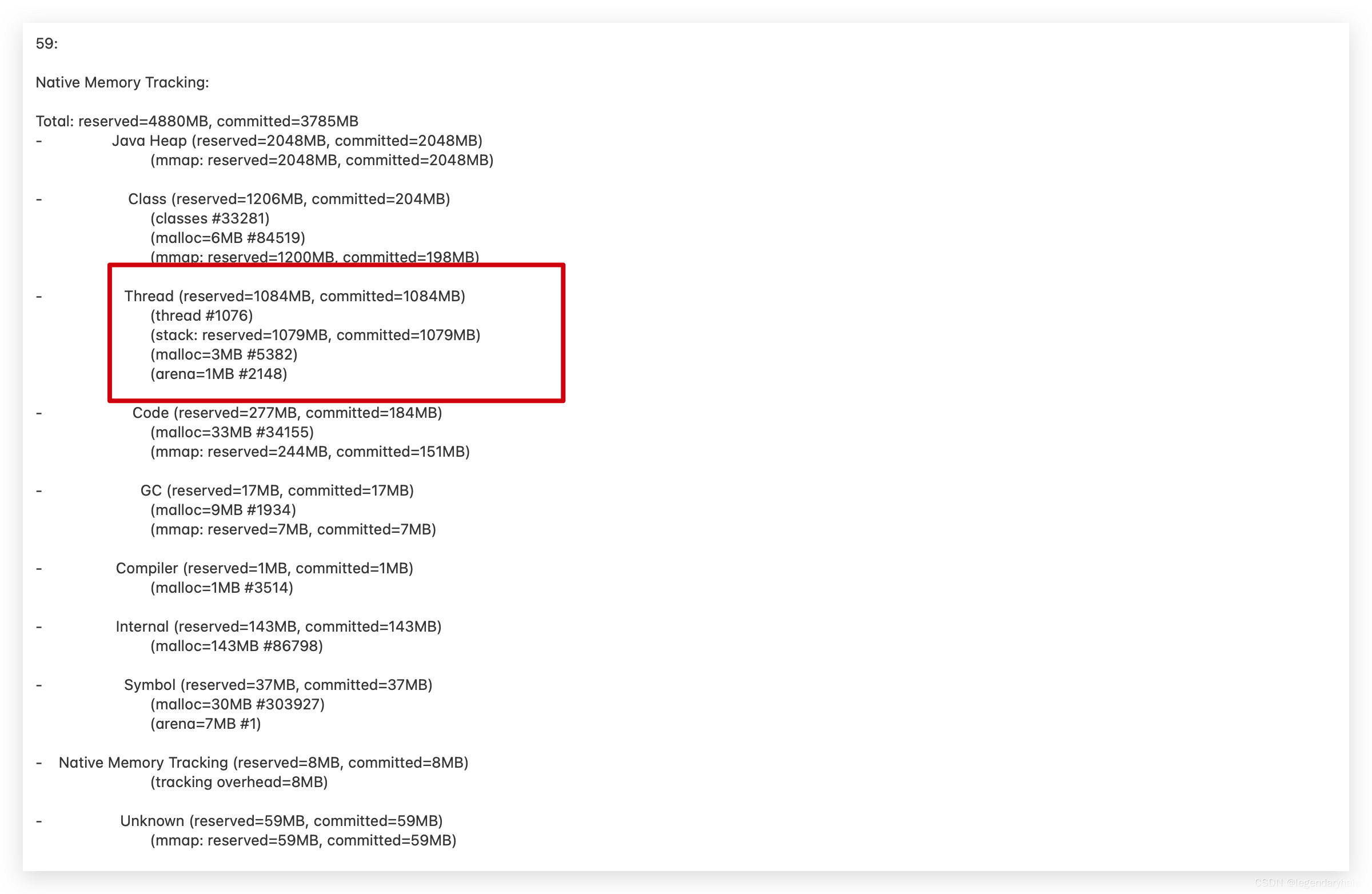
这里可以看到Thread占用的内存上涨得很快,其中 reserved 为1084M,committed 为1084M,每个栈大小为1M。那么我们可以dump一下线程的情况,这里直接用了arthas 中的thread命令,去查看线程的基本信息:

可以观察到存在着大量的myScheduler线程,其中不少处于waiting 状态。这时我们可以在业务代码里搜索myScheduler 相关的配置,可以发现该线程池大小为1000,再了解相关的业务是否真的需要这么多的线程执行,那么找到了解决方式:
- 优化线程池配置,调整核心线程数,调整线程池大小
- 根据业务实际情况,调整-Xmx 对应内存大小
案例二
某次傍晚晚时间,线上一核心服务重启告警。此时第一反应为什么重启了呢?观察容器错误日志,可以发现导火索是容器健康检测失败后,重启了容器。
健康检测:定期地检测容器内的应用程序或服务,并在出现问题时采取适当的措施(如:重启)
为什么健康检测会失败?因为线上服务开启了 -XX:+PrintGCDetails 参数,我们可以比较方便的拿到了gc-log文件。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/gc-log.log
-XX:+PrintGCDetails:打印详细的 GC 信息。-XX:+PrintGCDateStamps:在 GC 日志中包括日期时间戳。- -Xloggc:/path/gc-log.log:指定 GC 日志的输出文件路径。
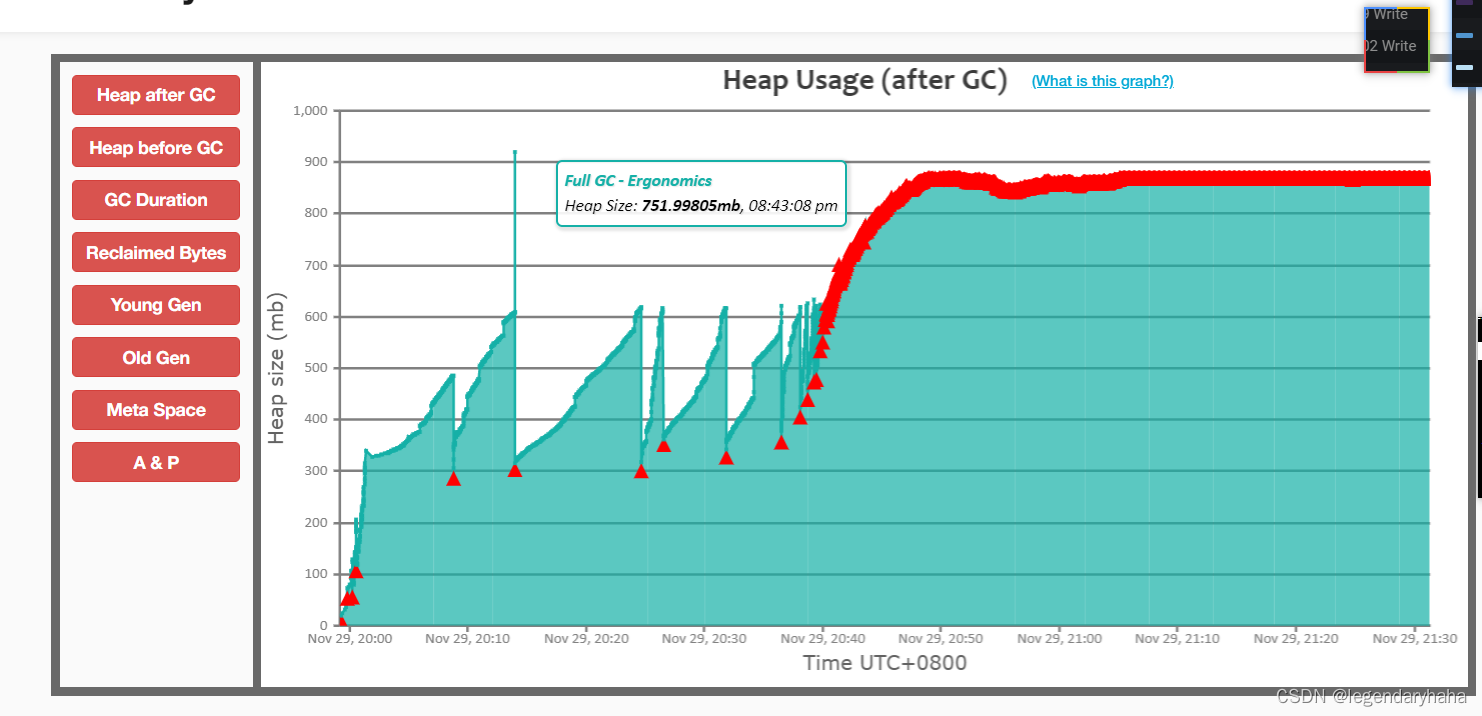
拿到gc-log文件,我们可以借助 gceasy.io网站分析,该网站提供了直观的图形化界面,帮助开发者轻松地监测和分析垃圾回收事件。如图:我们可以很直观的看到在20:40-21:30的时间段内heap飙升,且GC 之后,几乎没有效果。观察STW 时间最长的可以去到2min,同时CPU几乎拉满了,那么这里我们怀疑是否存在内存泄漏。
这次,因为启动参数配置了参数: -XX:HeapDumpPath,且在对应路径下,找到了现场dump文件,那么我们可以借助MAT(Eclipse Memory Analyzer)工具分析。在加载完dump文件,可以看到MAT分析的结果似乎也没有什么明显的异常提示, 那么我们可以尝试从占用空间比较大的的对象入手,从根节点开始分析,在MAT中,使用"Path to GC Roots"功能,即可从根对象开始查找对象引用链:
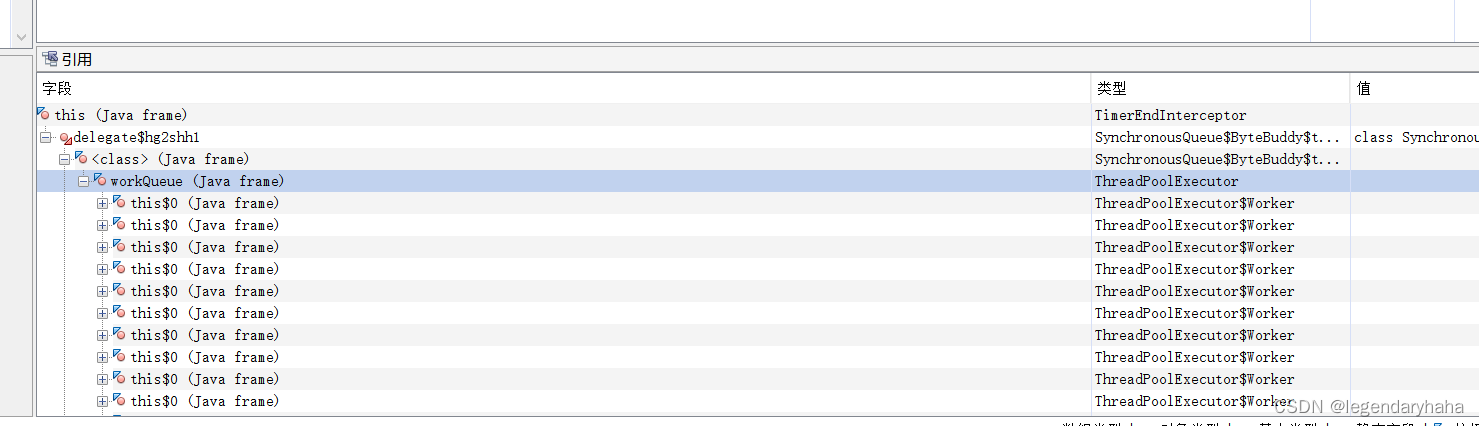
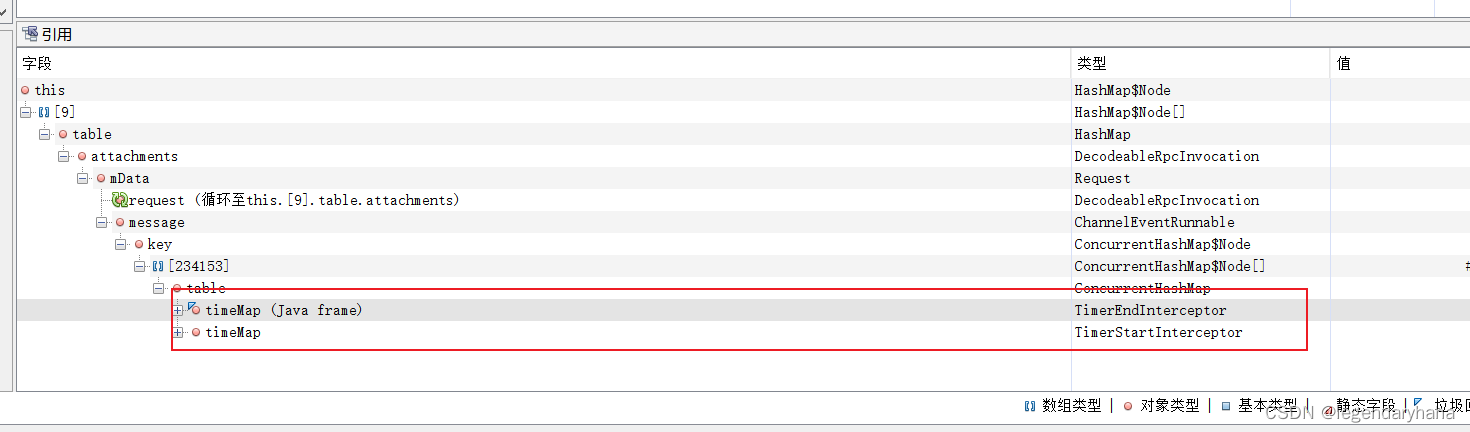
到这里我们发现占用的大量对象由TimerEndInterceptor类持有,每次GC回收都没有将其中对象回收掉。而这个 TimerEndInterceptor 类是基础服务团队维护的 metrics-agent 组件产生的。后续也是联系了他们回滚了metrics-agent 版本解决了问题。
简单而言就是,TimerEndInterceptor 类中的 ConcurrentHashMap(timeMap) 内存占用过高导致应用频繁FULL GC,打满了cpu导致dubbo服务不可用
案例三
在前两个案例归根到底是内存泄漏导致的OOM,这个过程的对象占用空间是缓慢增加的。那么在这个案例将以某次程序调用产生的大对象直接导致容器OOM为例子进行分析。同事A说某个线上服务运行一段时间就会挂了。对于这种必现的问题还是比较好下手的,我们同样加 -XX:HeapDumpPath 参数重启服务,在服务又挂了之后,我们在对应的路径下找到了dump文件,同样借助MAT工具分析。
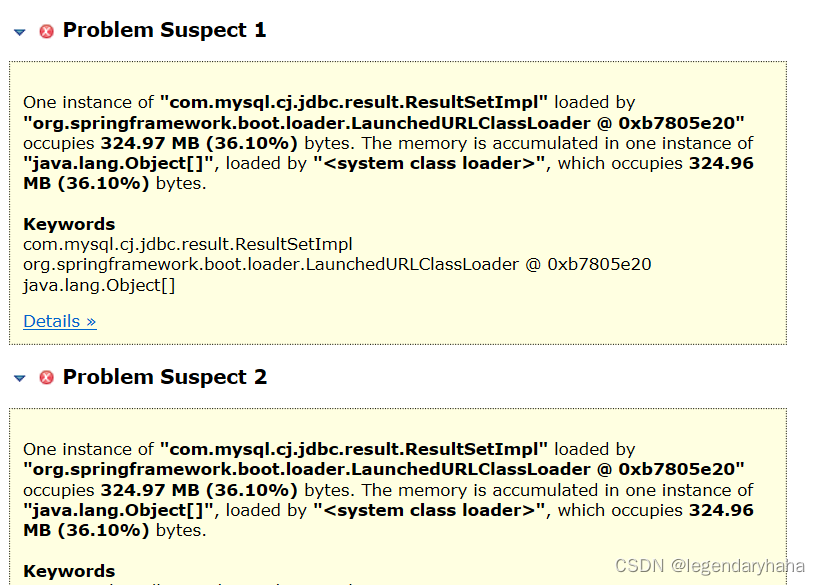
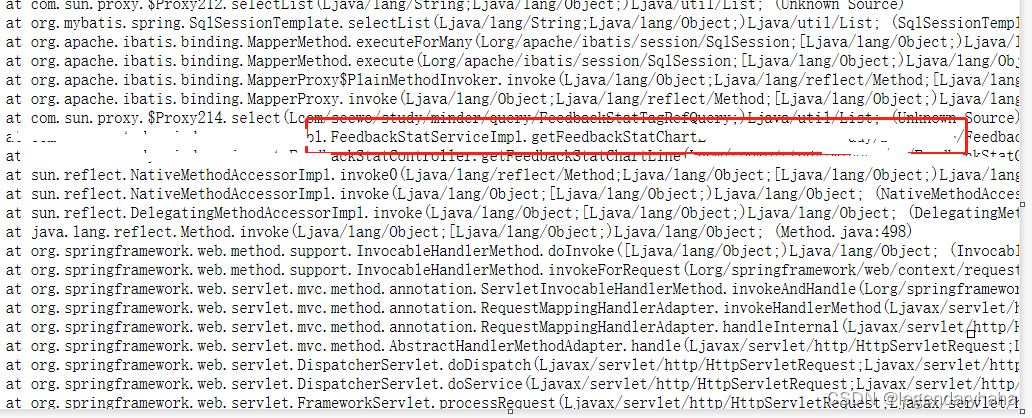
这次事故定位速度就很快了,因为MAT工具对于一些可疑大对象会有直接的提示,我们可以根据提示查找堆栈信息。在上图,通过堆栈链路我们定位到了代码位置。其实就是某个请求一次性从数据库捞出了很多数据,由于数据过大,直接分配在了老年代,而young gc 是不会回收这部分空间了,导致老年代不断膨胀,引发频繁的full gc,最终在内存超过限制后,触发OOM。那么争对这个问题我们可以有如下解决方式:
临时解决方案:
- 先调高JVM内存
- 配置 -XX:PretenureSizeThreshold 参数,适当调大对应的值,让大对象不要进入老年代在年轻代分配
年轻代的对象生命周期相比于老年代较短,如果能随着yong gc及时处理了这些对象,也可以及时释放掉这些空间
长久解决方案:
- 代码优化
四、总结
在此次OOM分析和实战中,我们先了解了JVM内存结构,知道了OOM会存在于JVM的哪些区域,接着阐述了根据区域的不同,OOM大概有哪几种类及其产生的原因,最后我们我们以三个案例进行实践和分析。这里我们再把排查思路汇集一下:
- 程序OOM时,保留现场dump文件很重要的分析依据。那么根据服务重要性,我们平常可以在服务启动时配置 -XX:HeapDumpPath 参数。
- 如果程序重启时, -XX:HeapDumpPath 对应路径下无对应日志文件:
- 确认对应路径是容器路径还是挂载的磁盘路径,如果是前者,会随容器重启而消失
- 如果你的业务里也有类似健康检测机制,考虑是否存在检测超时间小于dump完成时间,导致还没来得及dump完成就重启了容器
第二种情况,还可以确认一下 -Xmx 对应内存大小,内存越大,dump时间越久
- 如果有开启 -XX:+PrintGCDetails 参数,我们还可以借助easygc 等网站,分析JVM 的GC情况。看看是否存在频繁full gc,full gc耗时是否过长。
- 针对dump文件的分析,我们可以借助MAT(Eclipse Memory Analyzer)工具。如果是大对象直接导致的OOM,我们一般可以在概览图(overview)里找到对应提示;如果是内存泄漏导致的OOM,MAT此时可能无明显提示,那么我们可以从占比较高的对象入手,从root 节点开始找引用链,从而最终定位到疑似对象。
- 除去以上方式,对于内存泄漏导致的OOM,如果线上服务实在缺乏充分条件分析,我们也可以在测试环境开启NMT(-XX:NativeMemoryTracking) 参数进行前后的对比分析。
五、分析工具推荐
在上述分析中,我们用到了 GC Easy和MAT工具,但除此之外,还有一些类似的网站和工具,可以帮助你分析和优化Java应用程序的性能和内存管理。以下是一些常用的网站和工具:
- FastThread.io: https://fastthread.io/ FastThread.io 是一个在线工具,用于分析Java线程转储文件(Thread Dump)和堆转储文件(Heap Dump),以帮助你识别性能问题和线程问题。
- jHiccup: https://github.com/jHiccup/jHiccup jHiccup 是一个工具,用于测量JVM的停顿时间(暂停时间)和延迟,有助于检测应用程序的性能问题。
- jProfiler: https://www.ej-technologies.com/products/jprofiler/overview.html jProfiler 是一款商业性能分析工具,提供了强大的性能分析和调试功能,包括堆分析、线程分析、方法追踪等。
- New Relic: https://newrelic.com/ New Relic 是一种全栈性能监控工具,可用于监控和分析应用程序的性能、事务、错误和分布式追踪等。
- AppDynamics: https://www.appdynamics.com/ AppDynamics 提供了应用性能监控和实时分析工具,可帮助你监视Java应用程序的性能指标和事务。
- Dynatrace: https://www.dynatrace.com/ Dynatrace 是一种全栈性能监控工具,提供了自动化的性能分析和故障检测功能,适用于各种应用程序类型。
这些工具和网站各有特点,可以根据实际情况选择合适的工具来分析和优化你的Java应用程序的性能和内存管理。
六、参考文献
[1]Ali Dehghani. Native Memory Tracking in JVM[EB/OL].
[2]hengyunabc, Fatpandac, Hearen, Hollow Man, gongdewei, 李鼎. arthas thread[EB/OL].
[3]周志明. 深入理解Java虚拟机.