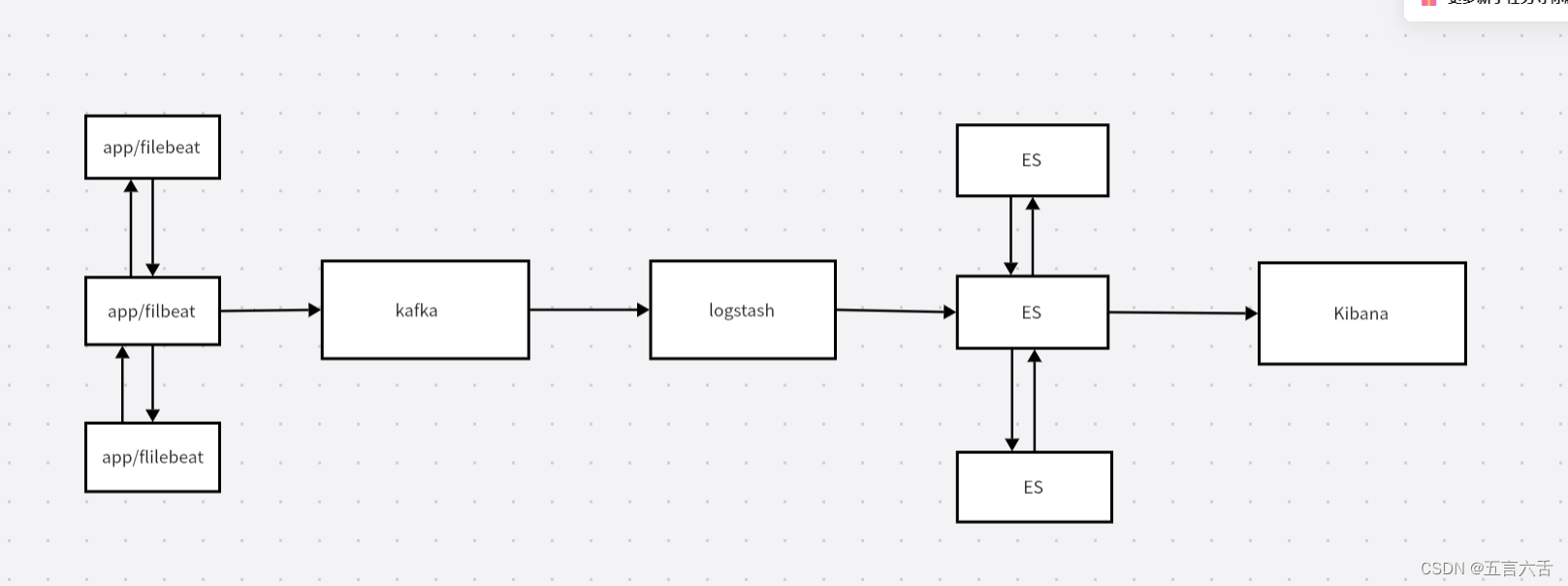
看上面的拓扑图,我们至少准备七台机器进行下面的实验项目。
机器主要作用分布如下:
三台安装elasticsearch来搭建ES集群实现高可用,其他机器就依次安装filebeat,kafka,logstash和kibana软件
一、部署elasticsearch来搭建ES集群
1.安装jdk
由于ES运行依赖于java环境,所以在部署es之前,我们要安装好jdk
我们事先在官网上下载好jdk的安装包并上传到机器,接下来就可以直接安装了,三台机器都需要安装好
tar xzf jdk-8u191-linux-x64.tar.gz -C /usr/local/ #解压
mv /usr/local/jdk1.8.0_191/ /usr/local/java #改名
echo '
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
source /etc/profile安装好jdk环境,我们就可以安装ES了
2、创建运行ES的普通用户(三台机器都需要操作)
useradd elsearch #创建用户
echo "123456" | passwd --stdin "elsearch" #给用户设置密码
3、安装配置ES
[root@mes-1 ~]# tar xzf elasticsearch-6.5.4.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/elasticsearch-6.5.4/config/
[root@mes-1 config]# ls
elasticsearch.yml log4j2.properties roles.yml users_roles
jvm.options role_mapping.yml users
[root@mes-1 config]# cp elasticsearch.yml elasticsearch.yml.bak
[root@mes-1 config]# vim elasticsearch.yml ----找个地方添加如下内容
cluster.name: elk
cluster.initial_master_nodes: ["192.168.246.234","192.168.246.231","192.168.246.235"]
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.246.234", "192.168.246.235"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
配置项含义
cluster.name 集群名称,各节点配成相同的集群名称。
cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock
bootstrap.system_call_filter
network.host 绑定节点IP。
http.port 端口。
transport.tcp.port 集群内部tcp连接端口
discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。4、设置JVM堆大小
[root@mes-1 config]# vim jvm.options ----将
-Xms1g ----修改成 -Xms2g
-Xmx1g ----修改成 -Xms2g
5、创建ES数据及日志存储目录
[root@mes-1 ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@mes-1 ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)6、修改安装目录及存储目录权限
[root@mes-1 ~]# chown -R elsearch:elsearch /data/elasticsearch
[root@mes-1 ~]# chown -R elsearch:elsearch /usr/local/elasticsearch-7.13.27、系统优化
#增加最大文件打开数
echo "* - nofile 65536" >> /etc/security/limits.conf
#增加最大进程数
[root@mes-1 ~]# vim /etc/security/limits.conf ---在文件最后面添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
更多的参数调整可以直接用这个
#增加最大内存映射数
[root@mes-1 ~]# vim /etc/sysctl.conf ---添加如下
vm.max_map_count=262144
vm.swappiness=0
[root@mes-1 ~]# sysctl -p
8、启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0
错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个
解决:
切换到root用户下面,
vim /etc/security/limits.conf
在最后添加
* hard nofile 65536
* hard nofile 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适
启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
# sysctl -w vm.max_map_count=262144
就可以了完成以上操作,我们就可以启动了
9、启动
[root@mes-1 ~]# su - elsearch
[root@mes-1 ~]$ cd /usr/local/elasticsearch-6.5.4/
[root@mes-1 elasticsearch-6.5.4]$ ./bin/elasticsearch #先启动看看报错不,需要多等一会
终止之后
[root@mes-1 elasticsearch-6.5.4]$ nohup ./bin/elasticsearch & #放后台启动
[1] 11462
nohup: ignoring input and appending output to ‘nohup.out’
[root@mes-1 elasticsearch-6.5.4]$ tail -f nohup.out #看一下是否启动二、安装head插件和部署Kibana(安装在同一台机器上)
1、安装node
# wget https://npm.taobao.org/mirrors/node/v14.15.3/node-v14.15.3-linux-x64.tar.gz
# tar xzvf node-v14.15.3-linux-x64.tar.gz -C /usr/local/
# vim /etc/profile
NODE_HOME=/usr/local/node-v14.15.3-linux-x64
PATH=$NODE_HOME/bin:$PATH
export NODE_HOME PATH
# source /etc/profile
# node --version #检查node版本号2、下载head插件
# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
# unzip -d /usr/local/ master.zip3、安装grunt
# cd /usr/local/elasticsearch-head-master/
# npm config set registry https://registry.npm.taobao.org #更换一个镜像,如果不更换下载会很慢
# npm install -g grunt-cli #时间会很长
# grunt --version #检查grunt版本号4、修改head源码
# vim /usr/local/elasticsearch-head-master/Gruntfile.js (95左右)
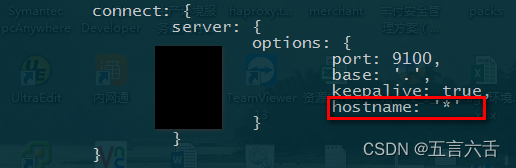
# vim /usr/local/elasticsearch-head-master/_site/app.js (4359左右)

5、下载head必要的文件
# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
# yum -y install bzip2
# tar -jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp/ #解压6、运行head
# cd /usr/local/elasticsearch-head-master/
# npm config set registry https://registry.npm.taobao.org #先执行这条命令更换一个镜像
# npm install
# nohup grunt server &7、部署kibana
# tar zvxf kibana-6.5.4-linux-x86_64.tar.gz -C /usr/local/
# cd /usr/local/kibana-7.13.2-linux-x86_64/config/
# vim kibana.yml
server.port: 5601
server.host: "192.168.246.235"
elasticsearch.hosts: ["http://192.168.246.234:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"配置项含义
server.port kibana服务端口,默认5601
server.host kibana主机IP地址,默认localhost
elasticsearch.hosts 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存
dashboards,默认.kibana8、启动kibana
[root@es-3-head-kib config]# cd ..
[root@es-3-head-kib kibana-7.13.2-linux-x86_64]# nohup ./bin/kibana --allow-root &
[1] 12054
[root@es-3-head-kib kibana-7.13.2-linux-x86_64]# nohup: ignoring input and appending output to ‘nohup.out’9、配置Nginx反向代理
[root@es-3-head-kib ~]# cd /etc/nginx/conf.d/
[root@es-3-head-kib conf.d]# cp default.conf nginx.conf
[root@es-3-head-kib conf.d]# mv default.conf default.conf.bak
[root@es-3-head-kib conf.d]# vim nginx.conf
[root@es-3-head-kib conf.d]# cat nginx.conf
server {
listen 80;
server_name 192.168.246.235;
#charset koi8-r;
# access_log /var/log/nginx/host.access.log main;
# access_log off;
location / {
proxy_pass http://192.168.246.235:5601;
proxy_set_header Host $host:5601;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
location /head/{
proxy_pass http://192.168.246.235:9100;
proxy_set_header Host $host:9100;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
}
[root@es-3-head-kib conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
# 引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;
[root@es-3-head-kib ~]# systemctl start nginx
三、logstash部署
1、安装
tar xvzf logstash-6.5.4.tar.gz -C /usr/local/2、配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
1.安装nginx:
[root@es-2-zk-log ~]# rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
[root@es-2-zk-log ~]# yum install -y nginx
将原来的日志格式注释掉定义成json格式:
[root@es-2-zk-log conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
2.引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;
[root@es-2-zk-log ~]# systemctl start nginx
[root@es-2-zk-log ~]# systemctl enable nginx
浏览器多访问几次
[root@es-2-zk-log ~]# mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
[root@es-2-zk-log ~]# cd /usr/local/logstash-6.5.4/etc/conf.d/
[root@es-2-zk-log conf.d]# vim input.conf #---在下面添加
input{ #让logstash可以读取特定的事件源。
file{ #从文件读取
path => ["/var/log/nginx/access_json.log"] #要输入的文件路径
type => "shopweb" #定义一个类型,通用选项.
}
}
[root@es-2-zk-log conf.d]# vim output.conf
output{ #输出插件,将事件发送到特定目标
elasticsearch { #输出到es
hosts => ["192.168.246.234:9200","192.168.246.231:9200","192.168.246.235:9200"] #指定es服务的ip加端口
index => ["%{type}-%{+YYYY.MM.dd}"] #引用input中的type名称,定义输出的格式
}
}
启动:
[root@es-2-zk-log conf.d]# cd /usr/local/logstash-7.13.2/
[root@es-2-zk-log logstash-7.13.2]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic & 







![[ Tool ] celery分布式任务框架基本使用](https://img-blog.csdnimg.cn/direct/6dc4eed4bd4c4a76890d2a794654e20c.png)