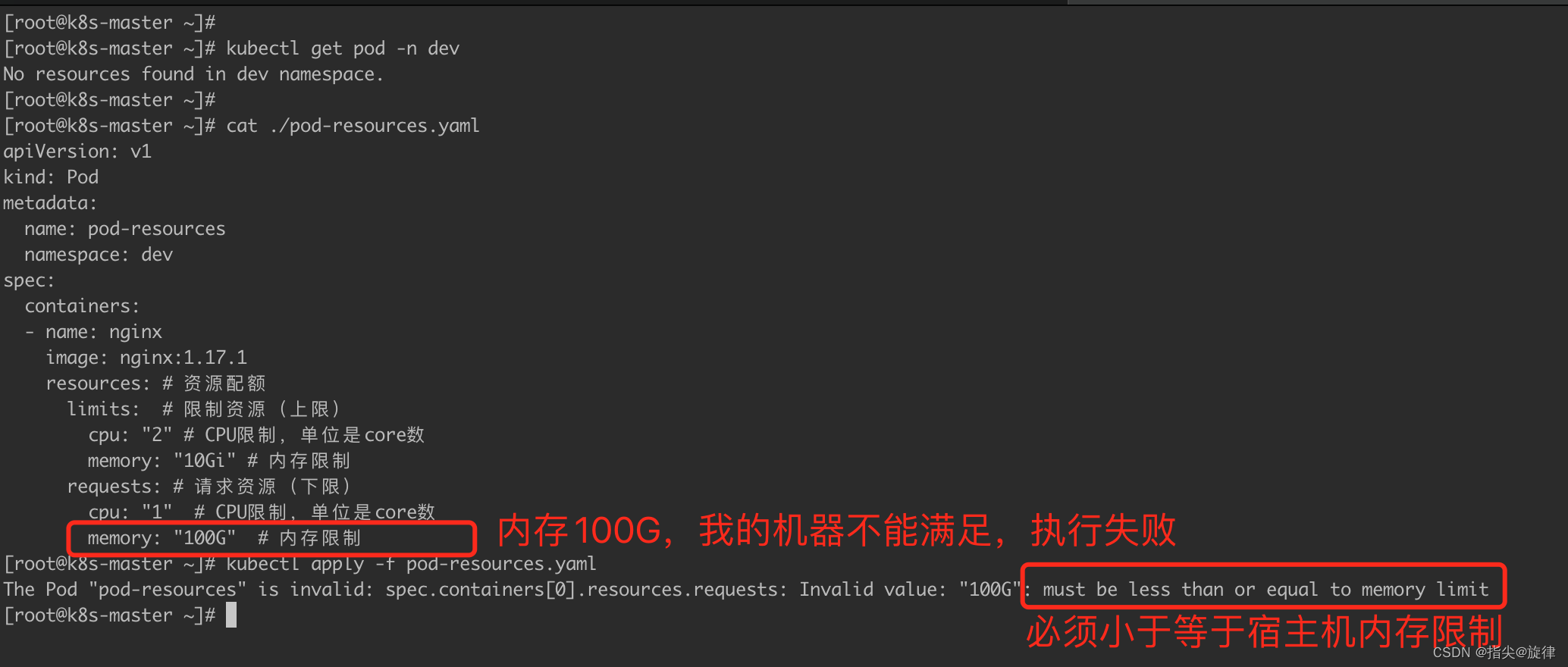
HIVE 核心技能之窗口函数
大家好呀,这节课我们学习 Hive 核心技能中最难的部分——窗口函数。窗口函数我们之前在学 MySQL 的时候有学过一些,但是只学了三个排序的窗口函数。这节课我们会学习更多的窗口函数,包括累计计算、分区排序、切片排序以及偏移分析。
在正式学习之前,我们需要先明确一下窗口函数和GROUP BY分组的区别。二者在功能上有相似之处,但是它们存在本质区别。
1. 分组会改变表的结构,而窗口函数不会改变表的结构。比如原表有10行数据,分成两组后只有两行,而窗口函数仍然返回十行数据。
2. 分组只能查询分组后的字段,包括分组字段(组名)和聚合函数字段。而窗口函数对查询字段没有限制,也就是可以查询原表的任意字段,再加上窗口函数新增的一列值。
好啦,现在让我们一起进入窗口函数的世界吧~
本节课主要内容:
1、累计计算窗口函数
(1)sum(…) over(……)
(2)avg(…) over(……)
(3)语法总结
2、分区排序窗口函数
(1)row_number()
(2)rank()
(3)dense_rank()
3、切片排序窗口函数
(1)ntile(n) over(……)
4、偏移分析窗口函数
5、重点练习
大家在做报表的时候,经常会遇到计算截止某月的累计数值,通常在EXCEL里可以通过函数来实现。
那么在HiveSQL里,该如何实现这种累计数值的计算呢?那就是利用窗口函数!
关于窗口函数的几点说明:
需求分析 :既然要进行按月累计,我们就先要把2018年的每笔交易时间转换成月并按月分组聚合计算,得出一个2018年每月支付金额总合表,再基于这张表用窗口函数进行累计计算。
2018年每月支付金额总和表:
再用窗口函数进行月度累计:
年度进行汇总。
这个需求比需求1多了一个需求,那就是年度汇总。那我们只需要在上个需求的子查询中加一个 year 字段即可。
说明:
1、over 中的 partition by 起到了窗口内将数据分组的作用。事实上,加上partition by之后,可以理解为分成了多个窗口,并在每个窗口内进行累加计算或者分区。
如果不加 partition by a.year 的话,运行结果就是这样单纯按月份进行分组的:
2、order by 按照什么顺序进行累加,升序ASC、降序DESC,默认是升序。
大家看股票的时候,经常会看到这种K线图,里面经常用到的就是7日、30日移动平均的趋势图,那如何使用窗口函数来计算移动平均值呢?
需求分析 :这个需求要求每个月近三个月的移动平均支付金额,这里我们要用到一个新知识点,在窗口函数 avg over 的 order by a.month 之后加一句 rows between 2 preceding and current row 来设定计算移动平均的范围,这个语句的含义就是包含本行及前两行。其他部分的写法跟前面的需求类似,先取出2018年每个月的支付金额总和,再用窗口函数求移动平均。
注意:
sum(…A…) over(partition by …B… order by …C… rows between …D1… and …D2…)
avg(…A…) over(partition by …B… order by …C… rows between…D1… and …D2…)
A:需要被加工的字段名称
B:分组的字段名称
C:排序的字段名称
D:计算的行数范围
rows between unbounded preceding and current row
——包括本行和之前所有的行
rows between current row and unbounded following
——包括本行和之后所有的行
rows between 3 preceding and current row
——包括本行以内和前三行
rows between 3 preceding and 1 following
——从前三行到下一行(5行)
max(……) over(partition by …… order by …… rows between ……and ……)
min(……) over(partition by …… order by …… rows between ……and ……)
row_number() 、rank()、dense_rank()
用法:这三个函数的作用都是返回相应规则的排序序号
row_number() over(partition by …A… order by …B… )
rank() over(partition by …A… order by …B… )
dense_rank() over(partition by …A… order by …B… )
A:分组的字段名称
B:排序的字段名称
注意: 这3个函数的括号内是不加任何字段名称的!
row_number :它会为查询出来的每一行记录生成一个序号,依次排序且不会重复。
rankdense_rank :在各个分组内, rank() 是跳跃排序,有两个第一名时接下来就是第三名, dense_rank() 是连续排序,有两个第一名时仍然跟着第二名。
实例练习:
再眼熟一下 user_trade 的表结构:
需求分析 :先限定时间范围,然后根据 user_name 进行分组,接着选出 分组去重后的 user_name,并计算每个用户 goods_category 的数量(记得 distinct 去重),再然后就是用窗口函数对 goods_category 的数量进行排序,当然选择哪一种排序方法要看具体要求,这里我们可以三种方法都试一下看看结果:
注意 :窗口函数中的 order by 字段不能用 select 中字段的重命名,因为二者是同时执行的。
需求分析 : 先用窗口函数将2019年每个用户的支付总金额算出来并进行排序,再以此作为子查询,从中取出排名在第10、20、30名的用户名、支付总金额以及排名次序。企业一般会使用 dense_rank 进行排序,所以我们这里直接用 dense_rank。
2019年每个用户的支付总金额排名:
2019年支付金额排名在第10、20、30名的用户:
ntile(n) over(partition by …A… order by …B… )
n:切分的片数
A:分组的字段名称
B:排序的字段名称
需求分析 :这个需求很简单,把需求5第一步的排序窗口函数变成切片即可。注意时间筛选条件变成2019年1月。
需求分析 : 排名前10%,也就是一共分成10组,取第1组。那么我们先切片分组:
然后再取第一组:
说明:Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与left join、right join等自连接相比,效率更高,SQL语句更简洁。
lag(exp_str,offset,defval) over(partion by ……order by ……)
lead(exp_str,offset,defval) over(partion by ……order by ……)
lag() 函数示例:
lead() 函数示例:
需求分析: 先要从 user_trade 表中取出每个用户的支付时间,把每个用户放到一个窗口中,按照支付时间进行排序,取出偏移列: lead(dt,1,dt) over(partition by user_name order by dt)。接着基于该子查询,筛选出时间间隔大于100天的用户,并计算数量。
注意 : 如果上面偏移分析函数写成 lead(dt,1,dt) 就不用加后面的 dt is not null 了,因为有默认值的话,间隔就是0,肯定是不满足条件的。
需求分析 :
第一步 :这个需求要用到 user_trade 和 user_info 两张表,前者取支付时间和金额,后者取城市和性别。先对这两张表基于 user_name 进行左连接,并取出相应字段,用窗口函数进行分组排序:
这一步的运行结果是这样的:
第二步 :基于上述结果取出TOP3:
需求分析:
第一步 :这个需求同样要用到两张表 user_refund 和 user_info。我们先把每个退款用户的退款金额和手机品牌取出来,并用窗口函数进行切片排序,25%就是分成4片:
注意 :这里之所以要加 WHERE dt is not null 是因为 user_refund 是一个分区表,分区表要对分区字段进行限制,否则 hive 会报错。
第二步 :选择前25%,也就是第一片:
最后补充一个从 hive 导出结果数据的命令:
以上就是这节课的全部内容了。做完整个练习,真的半条命都没了。窗口函数果然很难,不过掌握方法、多多练习,学会拆解需求,一步一步来做,就能明显降低难度。希望以后有机会能用到这么复杂的技能,哈哈~!

Hive sql及窗口函数
hive函数:
1、根据指定条件返回结果:case when then else end as
2、基本类型转换:CAST()
3、nvl:处理空字段:三个str时,是否为空可以指定返回不同的值
4、sql通配符:
5、count(1)与COUNT(*):返回行数
如果表没有主键,那么count(1)比count(*)快;
如果有主键,那么count(主键,联合主键)比count(*)快;
count(1)跟count(主键)一样,只扫描主键。count(*)跟count(非主键)一样,扫描整个表。明显前者更快一些。
性能问题:
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择,(指没有where的情况);
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。
count(expression):查询 is_reply=0 的数量: SELECT COUNT(IF(is_reply=0,1,NULL)) count FROM t_iov_help_feedback;
6、distinct与group by
distinct去重所有distinct之后所有的字段,如果有一个字段值不一致就不作为一条
group by是根据某一字段分组,然后查询出该条数据的所需字段,可以搭配 where max(time)或者Row_Number函数使用,求出最大的一条数据
7、使用with 临时表名 as() 的形式,简单的临时表直接嵌套进sql中,复杂的和需要复用的表写到临时表中,关联的时候先找到关联字段,过滤条件最好在临时表中先过滤后关联
处理json的函数:
split(json_array_string(schools), '\\|\\|') AS schools
get_json_object(school, '$.id') AS school_id,
字符串函数:
1、instr(’源字符串’ , ‘目标字符串’ ,’开始位置’,’第几次出现’)
instr(sourceString,destString,start,appearPosition)
1.sourceString代表源字符串; destString代表要从源字符串中查找的子串;
2.start代表查找的开始位置,这个参数可选的,默认为1;
3.appearPosition代表想从源字符中查找出第几次出现的destString,这个参数也是可选的, 默认为1
4.如果start的值为负数,则代表从右往左进行查找,但是位置数据仍然从左向右计算。
5.返回值为:查找到的字符串的位置。如果没有查找到,返回0。
最简单例子: 在abcd中查找a的位置,从第一个字母开始查,查找第一次出现时的位置
select instr(‘abcd’,’a’,1,1) from dual; —1
应用于模糊查询:instr(字段名/列名, ‘查找字段’)
select code,name,dept,occupation from staff where instr(code, ‘001’) 0;
等同于 select code, name, dept, occupation from staff where code like ‘%001%’ ;
应用于判断包含关系:
select ccn,mas_loc from mas_loc where instr(‘FH,FHH,FHM’,ccn)0;
等同于 select ccn,mas_loc from mas_loc where ccn in (‘FH’,’FHH’,’FHM’);
2、substr(string A,int start,int len)和 substring(string A,int start,int len),用法一样
substr(time,1,8) 表示将time从第1位开始截取,截取的长度为8位
第一种用法:
substr(string A,int start)和 substring(string A,int start),用法一样
功效:返回字符串A从下标start位置到结尾的字符串
第二种用法:
substr(string A,int start,int len)和 substring(string A,int start,int len),用法一样
功效:返回字符串A从下标start位置开始,长度为len的字符串
3、get_json_object(form_data,'$.学生姓名') as student_name
json_tuple 函数的作用:用来解析json字符串中的多个字段
4、split(full_name, '\\.') [5] AS zq; 取的是数组里的第六个
日期(时间)函数:
1、to_date(event_time) 返回日期部分
2、date_sub:返回当前日期的相对时间
当前日期:select curdate()
当前日期前一天:select date_sub(curdate(),interval 1 day)
当前日期后一天:select date_sub(curdate(),interval -1 day)
date_sub(from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss'), 14) 将现在的时间总秒数转为标准格式时间,返回14天之前的时间
时间戳日期:
from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') 将现在的时间总秒数转为标准格式时间
from_unixtime(get_json_object(get_json_object(form_data,'$.挽单时间'),'$.$date')/1000) as retain_time
unix_timestamp('2019-08-15 16:40:00','yyyy-MM-dd HH:mm:ss') --1565858400
日期时间戳:unix_timestamp()
date_format:yyyy-MM-dd HH:mm:ss 时间转格式化时间
select date_format('2019-10-07 13:24:20', 'yyyyMMdd000000')-- 20191007000000select date_format('2019-10-07', 'yyyyMMdd000000')-- 20191007000000
1.日期比较函数: datediff语法: datediff(string enddate,string startdate)
返回值: int
说明: 返回结束日期减去开始日期的天数。
举例: hive select datediff('2016-12-30','2016-12-29'); 1
2.日期增加函数: date_add语法: date_add(string startdate, intdays)
返回值: string
说明: 返回开始日期startdate增加days天后的日期。
举例: hiveselect date_add('2016-12-29',10); 2017-01-08
3.日期减少函数: date_sub语法: date_sub (string startdate,int days)
返回值: string
说明: 返回开始日期startdate减少days天后的日期。
举例: hiveselect date_sub('2016-12-29',10); 2016-12-19
4.查询近30天的数据
select * from table where datediff(current_timestamp,create_time)=30;
create_time 为table里的字段,current_timestamp 返回当前时间 2018-06-01 11:00:00
3、trunc()函数的用法:当前日期的各种第一天,或者对数字进行不四舍五入的截取
日期:
1.select trunc(sysdate) from dual --2011-3-18 今天的日期为2011-3-18
2.select trunc(sysdate, 'mm') from dual --2011-3-1 返回当月第一天.
上月1号 trunc(add_months(current_date(),-1),'MM')
3.select trunc(sysdate,'yy') from dual --2011-1-1 返回当年第一天
4.select trunc(sysdate,'dd') from dual --2011-3-18 返回当前年月日
5.select trunc(sysdate,'yyyy') from dual --2011-1-1 返回当年第一天
6.select trunc(sysdate,'d') from dual --2011-3-13 (星期天)返回当前星期的第一天
7.select trunc(sysdate, 'hh') from dual --2011-3-18 14:00:00 当前时间为14:41
8.select trunc(sysdate, 'mi') from dual --2011-3-18 14:41:00 TRUNC()函数没有秒的精确
数字:TRUNC(number,num_digits) Number 需要截尾取整的数字。Num_digits 的默认值为 0。TRUNC()函数截取时不进行四舍五入
11.select trunc(123.458,1) from dual --123.4
12.select trunc(123.458,-1) from dual --120
4、round():四舍五入:
select round(1.455, 2) #结果是:1.46,即四舍五入到十分位,也就是保留两位小数
select round(1.5) #默认四舍五入到个位,结果是:2
select round(255, -1) #结果是:260,即四舍五入到十位,此时个位是5会进位
floor():地板数
ceil()天花板数
5、
6.日期转年函数: year语法: year(string date)
返回值: int
说明: 返回日期中的年。
举例:
hive select year('2011-12-08 10:03:01') from dual;
2011
hive select year('2012-12-08') fromdual;
2012
7.日期转月函数: month语法: month (string date)
返回值: int
说明: 返回日期中的月份。
举例:
hive select month('2011-12-08 10:03:01') from dual;
12
hive select month('2011-08-08') fromdual;
8
8.日期转天函数: day语法: day (string date)
返回值: int
说明: 返回日期中的天。
举例:
hive select day('2011-12-08 10:03:01') from dual;
8
hive select day('2011-12-24') fromdual;
24
9.日期转小时函数: hour语法: hour (string date)
返回值: int
说明: 返回日期中的小时。
举例:
hive select hour('2011-12-08 10:03:01') from dual;
10
10.日期转分钟函数: minute语法: minute (string date)
返回值: int
说明: 返回日期中的分钟。
举例:
hive select minute('2011-12-08 10:03:01') from dual;
3
11.日期转秒函数: second语法: second (string date)
返回值: int
说明: 返回日期中的秒。
举例:
hive select second('2011-12-08 10:03:01') from dual;
1
12.日期转周函数: weekofyear语法: weekofyear (string date)
返回值: int
说明: 返回日期在当前的周数。
举例:
hive select weekofyear('2011-12-08 10:03:01') from dual;
49
查看hive表在hdfs中的位置:show create table 表名;
在hive中hive2hive,hive2hdfs:
HDFS、本地、hive ----- Hive:使用 insert into | overwrite、loaddata local inpath "" into table student;
Hive ---- Hdfs、本地:使用:insert overwrite | local
网站访问量统计:
uv:每用户访问次数
ip:每ip(可能很多人)访问次数
PV:是指页面的浏览次数
VV:是指你访问网站的次数
sql:
基本函数:
count、max、min、sum、avg、like、rlike('2%'、'_2%'、%2%'、'[2]')(java正则)
and、or、not、in
where、group by、having、{ join on 、full join} 、order by(desc降序)
sort by需要与distribut by集合结合使用:
hive (default) set mapreduce.job.reduces=3; //先设置reduce的数量
insert overwrite local directory '/opt/module/datas/distribute-by'
row format delimited fields terminated by '\t'
先按照部门编号分区,再按照员工编号降序排序。
select * from emp distribute by deptno sort by empno desc;
外部表 create external table if not exists dept
分区表:create table dept_partition ( deptno int, dname string, loc string ) partitioned by ( month string )
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201809');
alter table dept_partition add/drop partition(month='201805') ,partition(month='201804');
多分区联合查询:union
select * from dept_partition2 where month='201809' and day='10';
show partitions dept_partition;
desc formatted dept_partition;
二级分区表:create table dept_partition2 ( deptno int, dname string, loc string ) partitioned by (month string, day string) row format delimited fields terminated by '\t';
分桶抽样查询:分区针对的是数据的存储路径;分桶针对的是数据文件
create table stu_buck(id int, name string) clustered by(id) into 4 bucketsrow format delimited fields terminated by '\t';
设置开启分桶与reduce为1:
set hive.enforce.bucketing=true;
set mapreduce.job.reduces=-1;
分桶抽样:select * from stu_bucktablesample(bucket x out of y on id);
抽取,桶数/y,x是从哪个桶开始抽取,y越大 抽样数越少,y与抽样数成反比,x必须小于y
给空字段赋值:
如果员工的comm为NULL,则用-1代替或用其他字段代替 :select nvl(comm,-1) from emp;
case when:如何符合记为1,用于统计、分组统计
select dept_id, sum(case sex when '男' then 1 else 0 end) man , sum(case sex when '女' then 1 else 0 end) woman from emp_sex group by dept_id;
用于组合归类汇总(行转列):UDAF:多转一
concat:拼接查询结果
collect_set(col):去重汇总,产生array类型字段,类似于distinct
select t.base, concat_ws('|',collect_set(t.name)) from (select concat_ws(',',xingzuo,blood_type) base,name from person_info) t group by t.base;
解释:先第一次查询得到一张没有按照(星座血型)分组的表,然后分组,使用collect_set将名字组合成数组,然后使用concat将数组变成字符串
用于拆分数据:(列转行):UDTF:一转多
explode(col):将hive一列中复杂的array或者map结构拆分成多行。
lateral view 侧面显示:用于和UDTF一对多函数搭配使用
用法:lateral view udtf(expression) tablealias as cate
cate:炸开之后的列别名
temptable :临时表表名
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
开窗函数:
Row_Number,Rank,Dense_Rank over:针对统计查询使用
Row_Number:返回从1开始的序列
Rank:生成分组中的排名序号,会在名词s中留下空位。3 3 5
dense_rank:生成分组中的排名序号,不会在名词中留下空位。3 3 4
over:主要是分组排序,搭配窗口函数使用
结果:
SUM、AVG、MIN、MAX、count
preceding:往前
following:往后
current row:当前行
unbounded:unbounded preceding 从前面的起点, unbounded following:到后面的终点
sum:直接使用sum是总的求和,结合over使用可统计至每一行的结果、总的结果、当前行+之前多少行/之后多少行、当前行到往后所有行的求和。
over(rowsbetween 3/current rowprecedingandunboundedfollowing ) 当前行到往后所有行的求和
ntile:分片,结合over使用,可以给数据分片,返回分片号
使用场景:统计出排名前百分之或n分之一的数据。
lead,lag,FIRST_VALUE,LAST_VALUE
lag与lead函数可以返回上下行的数据
lead(col,n,dafault) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
使用场景:通常用于统计某用户在某个网页上的停留时间
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
范围内求和:
cume_dist,percent_rank
–CUME_DIST :小于等于当前值的 行数 / 分组内总行数
–比如,统计小于等于当前薪水的人数,占总人数的比例
percent_rank:分组内当前行的RANK值-1/分组内总行数-1
总结:
在Spark中使用spark sql与hql一致,也可以直接使用sparkAPI实现。
HiveSql窗口函数主要应用于求TopN,分组排序TopN、TopN求和,前多少名前百分之几。
与Flink窗口函数不同。
Flink中的窗口是用于将无线数据流切分为有限块处理的手段。
window分类:
CountWindow:按照指定的数据条数生成一个 Window,与时间无关。
TimeWindow:按照时间生成 Window。
1. 滚动窗口(Tumbling Windows):时间对齐,窗口长度固定,不重叠::常用于时间段内的聚合计算
2.滑动窗口(Sliding Windows):时间对齐,窗口长度固定,可以有重叠::适用于一段时间内的统计(某接口最近 5min 的失败率来报警)
3. 会话窗口(Session Windows)无时间对齐,无长度,不重叠::设置session间隔,超过时间间隔则窗口关闭。
MYSQL lag() 和lead()函数使用介绍
LAG()函数是一个窗口函数,允许您从当前行向前看多行数据。与LEAD()函数类似,LEAD()函数对于计算同一结果集中当前行和后续行之间的差异非常有用。
LAG语法: LAG(列名,[offset], [default_value]) OVER ( PARTITION BY 列名,... ORDER BY 列名 [ASC|DESC],... )
LEAD语法: LEAD(列名,[offset], [default_value]) OVER ( PARTITION BY 列名,... ORDER BY 列名 [ASC|DESC],... )
offset:offset是从当前行偏移的行数,以获取值。offset必须是一个非负整数。如果offset为零,则LEAD()函数计算当前行的值。如果省略 offset,则LEAD()函数默认使用一个。
default_value:如果没有后续行,则LEAD()函数返回default_value。例如,如果offset是1,则最后一行的返回值为default_value。如果您未指定default_value,则函数返回 NULL 。
PARTITION BY子句:PARTITION BY子句将结果集中的行划分LEAD()为应用函数的分区。如果PARTITION BY未指定子句,则结果集中的所有行都将被视为单个分区。
ORDER BY子句:ORDER BY子句确定LEAD()应用函数之前分区中行的顺序。
用途举例:
ps:
不适合计算留存,举例说明:
求3日留存用户,以下为用户登录表login_history_table:
首先使用LEAD函数对用户登录时间做偏移,SQL如下:
结果如下:
根据上面查询到的结果,3日留存用户中不能统计到abc,而实际应该包含abc,因为该用户20211022登录后,在3天后的20211025日又重新登录了。





![Docker安装Kibana整合Elasticsearch[包含账号密码设置]](https://img-blog.csdnimg.cn/d43e5238ef0b4e32aecb29442ca3c9fb.png)