文章目录
- 线程的开销
- 线程池的工作方式
- ThreadPoolExecutor基础
- 线程池结果的处理
线程的开销
线程作为一种昂贵的资源,开销包括如下几点:
1、线程的创建与启动的开销。
2、线程的销毁的开销。
3、线程调度的开销。线程的调度会产生上下文切换,从而增加处理器资源的消耗。
4、一个系统可以创建的线程数受限于该系统的处理器数目。线程数量的临界值总是处理器的数目。
线程池的工作方式
鉴于以上线程资源的消耗,我们需要一种有效的使用线程的方式,线程池就是高效利用线程的一种常见方式。它的工作原理如下:
线程池内部可以预先创建好一定数量的工作者线程,客户端将其需要执行的任务作为一个对象提交给线程池,线程池可以将这些任务缓存到工作队列中,而线程池内部则不断的从队列中取出任务并执行。因此,线程池可以看做是生产者消费者模式,其内部维护的工作者线程相当于消费者线程,客户端的线程相当于生产者线程,客户端提交的代码相当于产品,线程池内部的工作队列相当于信道。
ThreadPoolExecutor基础
ThreadPoolExecutor就是一个常用的线程池,它参数最多的构造器声明如下
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize: 它是线程池的核心线程大小,在线程池初期,来一个任务就会创建一个线程,当线程池中的线程数达到核心线程时,新来的任务就会存入到工作队列中。所以corePoolSize相当于一个临界值。
maximumPoolSize:它用来指定最大线程池大小。当线程池中工作队列满了之后,线程池就会继续创先线程,但是创建的线程数量不能超过maximumPoolSize。
keepAliveTime–unit:这两个参数一起用来指定线程中空闲线程的最大存活时间。空闲线程数即
maximumPoolSize-corePoolSize。
workQueue:工作队列,相当于生产者消费者模式中的传输通道。
threadFactory:指定用于创建工作者线程的线程工厂。
handler:线程池的拒绝策略。该方法如下:

r代表的是执行的任务,executor代表的是当前的线程池实例。
其中RejectedExecutionHandler 有几个默认的实现类:
1、ThreadPoolExecutor.AbortPolicy
ThreadPoolExecutor.AbortPolicy是默认的执行器,当线程池的线程数量超过了最大线程数,则会直接抛出异常。
2、ThreadPoolExecutor.DiscardPolicy
ThreadPoolExecutor.DiscardPolicy表示丢弃当前执行的任务,但是不抛出任何异常。
3、ThreadPoolExecutor.DiscardOldestPolicy
ThreadPoolExecutor.DiscardOldestPolicy将工作中最老的任务丢掉,然后从新尝试接纳被拒绝的任务。
4、ThreadPoolExecutor.CallerRunsPolicy
ThreadPoolExecutor.CallerRunsPolicy表示在客户端执行被拒绝的任务。
各个参数的整体配合流程如下:
客户端不断的给线程池提交任务,每提交一个新的任务,线程池就创建一个线程来处理该任务,当任务数量超过核心线程数大小时,新来的任务就会存入到工作队列中,然后这些核心线程会不断的从工作队列中取出任务来执行。线程池将任务存入到工作队列中使用的BlockingQueue的非阻塞方法offer,因此工作队列满并不会使提交任务的客户端暂停。当工作队列满了之后,线程池会继续创建新的线程,直到当前线程数达到最大线程数大小,如果此时再有新的任务,客户端执行的任务就会被拒绝。那些超出线程池核心大小的线程如果没有任务的时间达到了keepAliveTime,就会被清理掉,如果keepAliveTime设置的值太小,可能导致线程池持续的创建销毁线程,反而增加了开销。
ThreadPoolExecutor.shutdown()表示用来关闭线程池,已提交到队列中的任务会继续执行,但新提交的任务则会被拒绝。
ThreadPoolExecutor.shutdownNow()关闭线程池时,正在执行的任务也会停止,新的任务也会不会执行。
线程池结果的处理
public Future<?> submit(Runnable task) 方法的参数是Runnable 接口,其抽象方法run() 没有返回值,其作用是向线程池中提交任务,并不关心返回值,且无法抛出异常。
public Future submit(Callable task)可以处理任务的返回结果,其参数是一个Callable接口,其泛型是任务返回的类型,该方法可以抛出异常。结果可以通过Future.get()来获取,当处理的任务发生异常时,Future.get()也会将异常抛出:
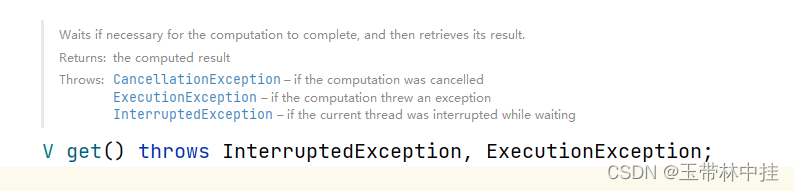
当get方法被调用时,如果该任务还未完成,则会阻塞代码。所以应该尽可能的向线程池提交任务,并且get的调用应该放到需要数据的时刻,这期间先执行其他任务。
举一个使用Fucture接口的例子,我们从网上买完东西之后不会一直等待着收货,这期间肯定会去做别的事情,以此举例写一个小demo
public class ExecutorDemo {
final static int cpuNum = Runtime.getRuntime().availableProcessors();
static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(0,
cpuNum * 2,
4,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
new ThreadPoolExecutor.CallerRunsPolicy());
public static void main(String[] args) {
List<String> list = new ArrayList<String>() {{
add("护肤品");
add("水果");
}};
List<Future<String>> futures = new CopyOnWriteArrayList<>();
//从网上买东西,异步处理
list.forEach(item -> {
Future<String> stringFuture = buySomething(item);
futures.add(stringFuture);
});
//dosomething else
//东西到了,进行验货
futures.forEach(item -> {
//最多等待3秒
try {
String something = item.get(3, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
});
}
public static Future<String> buySomething(String something) {
return threadPoolExecutor.submit(new Callable<String>() {
@Override
public String call() {
return something.concat("is coming");
}
});
}
}