文章目录
- CAS介绍
- CAS在Java中的底层实现
- Java源码中使用举例
- 自己实际运用乐观锁举例
- 简单的CAS操作
- ABA问题及优化实践
- 缺陷及优化
- 只能保证单个变量操作原子性
- 当比较失败后,通常需要不断重试,浪费CPU
CAS介绍
CAS(Compare And swap),比较并交换,是一种乐观锁.它是解决多线程并行情况下使用悲观锁造成性能损耗的一种机制.
CAS 是实现乐观锁的核心算法,它包含了 3 个参数:V(需要更新的变量)、E(预期值)和 N(最新值)。只有当需要更新的变量等于预期值时,需要更新的变量才会被设置为最新值,如果更新值和预期值不同,则说明已经有其它线程更新了需要更新的变量,此时当前线程不做操作,返回失败
乐观锁相比悲观锁来说,不会带来死锁、饥饿等活性故障问题,线程间的相互影响也远远比悲观锁要小。更为重要的是,乐观锁没有因竞争造成的系统开销,所以在性能上也是更胜一筹。
CAS在Java中的底层实现
CAS在Java中的最底层实现其实都封装在Unsafe(sun.misc.Unsafe)类中.
主要提供了三个比较并交换的方法.
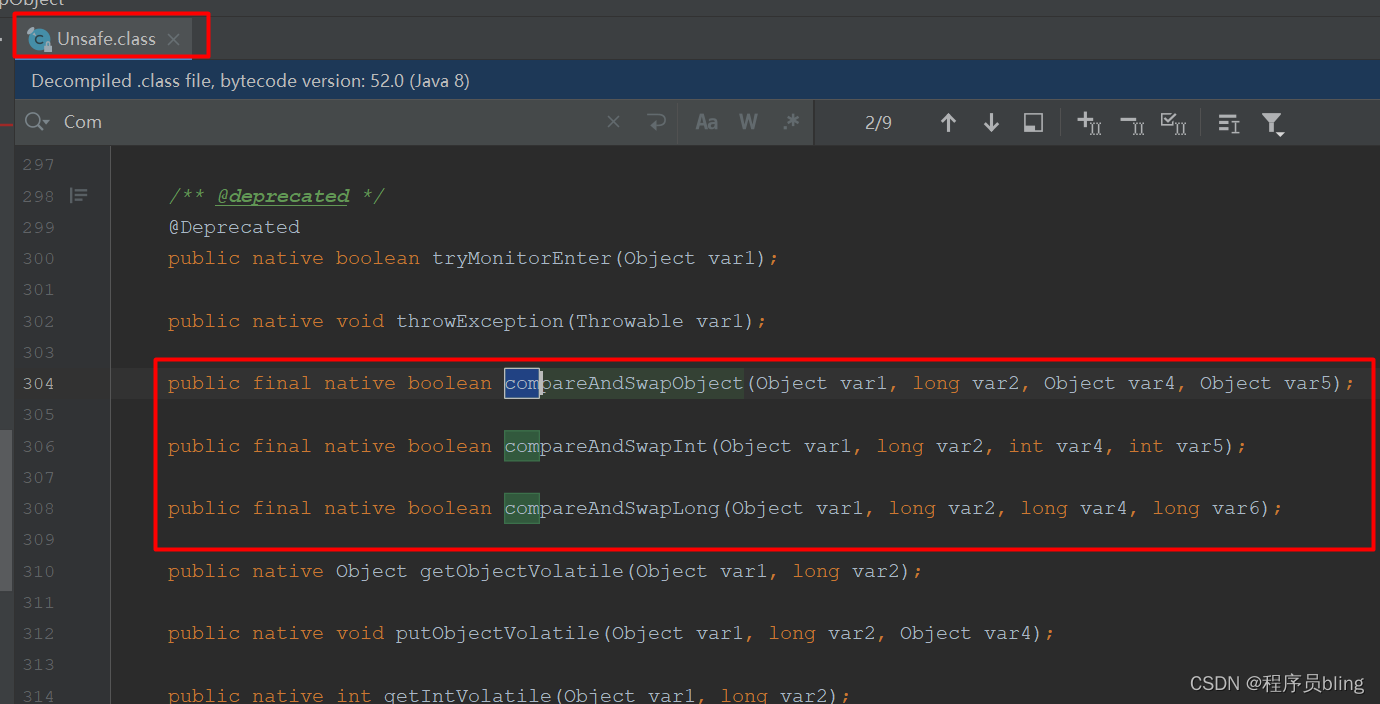
为什么叫Unsafe类呢?
因为在Java中,基本没有直接的指针组件,一般也不能使用偏移量对某块内存进行操作。这些操作相对来讲是安全(safe)的。
而这个Unsafe类使 Java 拥有了像 C 语言的指针一样直接操作内存空间的能力,可用来直接访问系统内存资源并进行自主管理,是Java并发的基础.
但是同时也带来了指针的问题。即一个新手在编程时,没有考虑指针的安全性,错误的操作指针把某块不该修改的内存值修改,容易导致整个程序崩溃。
所以官方并不建议我们直接使用Unsafe类.
Java源码中使用举例
- AQS中加锁操作
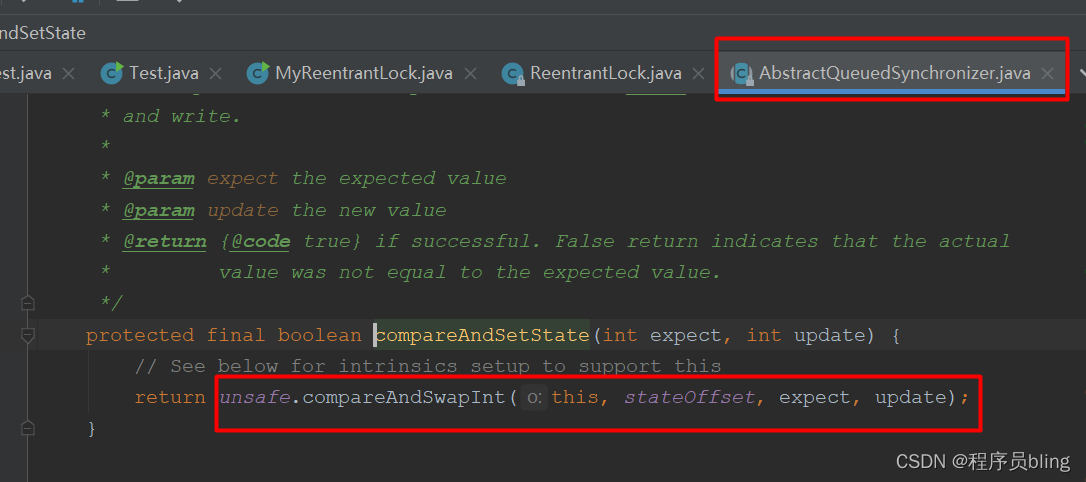
- ConcurrentHashMap中加锁操作.

- atomic 路径下的所有类.
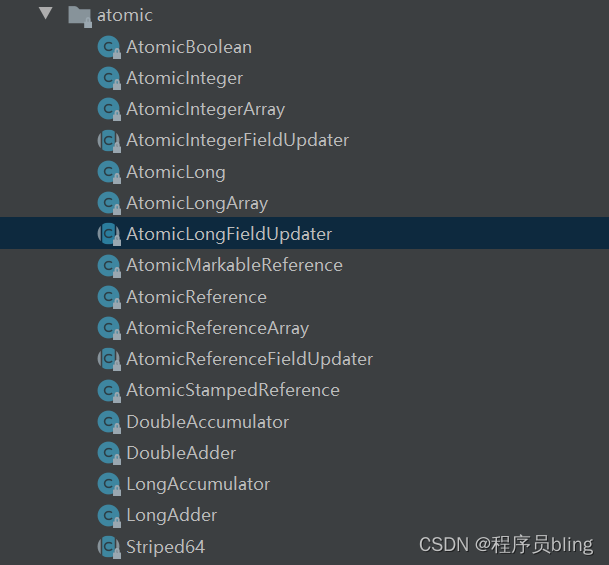
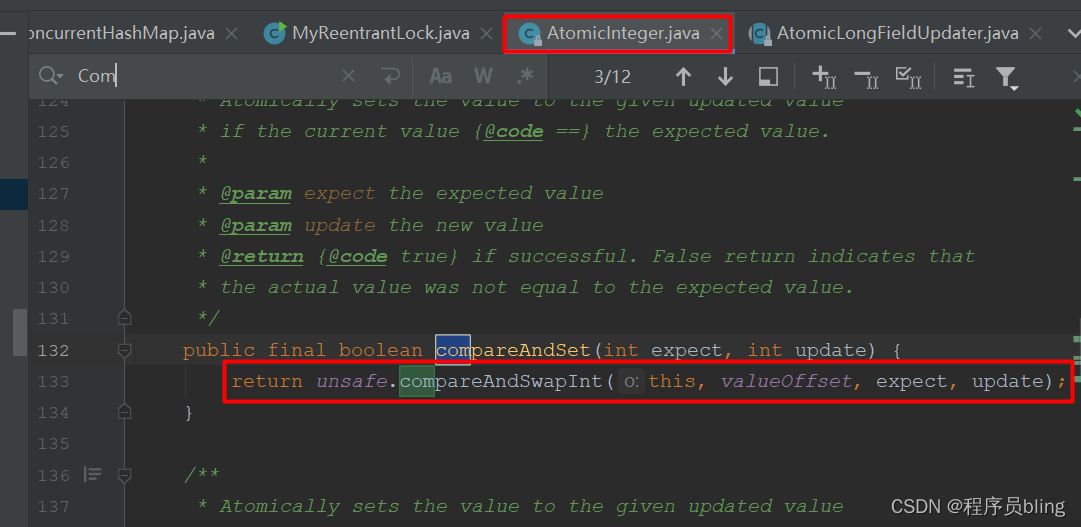
这些原子类底层其实都是运用的CAS操作,调用Unsafe类中的方法.如:
自己实际运用乐观锁举例
如果我们想自己在项目中运用乐观锁,应该怎样去用呢?
简单的CAS操作
我们可以直接使用Atomic路径下封装好的CAS方法.
如果是数值类型的我们可以直接用AtomicInteger、AtomicLong这些类
如果是其他类型我们可以用AtomicReference,它可以传入一个泛型,从而进行一个复杂对象的比较并替换,这里举例假如比较的是Char类型.
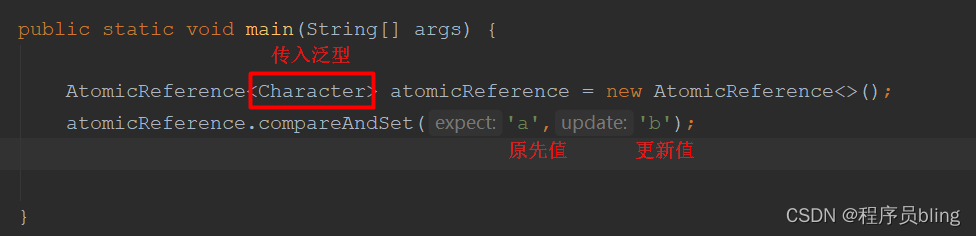
该方法会返回更新成功或者失败,那如果更新失败,我们应该怎样做?
这里就要区分不同的业务场景了,通常来说有两种情况.
- 直接返回失败,返回一个友好提示由上层进行处理
- 获取当前最新值,然后重新计算更新值,不断进行重试.
ABA问题及优化实践
这里还有一个问题,就是CAS常见的ABA问题,
CAS 算法是基于值来做比较的,如果当前有两个线程,一个线程将变量值从 A 改为 B ,再由 B 改回为 A ,当前线程开始执行 CAS 算法时,就很容易认为值没有变化,误认为读取数据到执行 CAS 算法的期间,没有线程修改过数据。
解决这个问题的常见方法就是增加版本号或者时间戳作为额外验证手段,确保在当前期间没有其他线程对其做过操作.
在Java中也有原子类AtomicStampedReference实现了这个功能,我们直接调用方法即可.
volatile int value=0; //初始值
volatile int stamp=0; //初始版本号
public void test(){
//初始化对象,传入初始值和初始的版本号
AtomicStampedReference<Integer> stampedReference = new AtomicStampedReference<Integer>(value,stamp);
//使用比较并交换进行CAS操作
//四个参数分别是初始值,更新值,初始版本,更新版本
boolean result = stampedReference.compareAndSet(0, 5, 0, 1);
System.out.println(result);
//获取最新值
System.out.println(stampedReference.getReference());
//获取最新版本
System.out.println(stampedReference.getStamp());
}
缺陷及优化
只能保证单个变量操作原子性
CAS 乐观锁在平常使用时比较受限,它只能保证单个变量操作的原子性,当涉及到多个变量时,CAS 就无能为力了,这个时候还是需要悲观锁,通过对整个代码块加锁来做到这点。
目前使用乐观锁最常见的场景就是数据库的更新操作了。为了保证操作数据库的原子性,我们常常会为每一条数据定义一个版本号,并在更新前获取到它,到了更新数据库的时候,还要判断下已经获取的版本号是否被更新过,如果没有,则执行该操作
当比较失败后,通常需要不断重试,浪费CPU
CAS 乐观锁在高并发写大于读的场景下,大部分线程的原子操作会失败,失败后的线程将会不断重试 CAS 原子操作,比如说 AtomicInteger 和 AtomicLong等都是这样的.这样就会导致大量线程长时间地占用 CPU 资源,给系统带来很大的性能开销。
在 JDK1.8 中,Java 提供了一个新的原子类 LongAdder。LongAdder 在高并发场景下会比 AtomicInteger 和 AtomicLong 的性能更好,代价就是会消耗更多的内存空间。
LongAdder 的原理就是降低操作共享变量的并发数,也就是将对单一共享变量的操作压力分散到多个变量值上,将竞争的每个写线程的 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的 value 值进行 CAS 操作,最后在读取值的时候会将原子操作的共享变量与各个分散在数组的 value 值相加,返回一个近似准确的数值。
这里返回一个近似准确的数值要怎么理解呢? 再说的具体一点,假设操作后立即要获取到值,这个值可能是一个不准确的值。如果我们等待所有线程执行完成之后去获取,这个值肯定是准确的值。一般在做统计时,会经常用到这种操作,实时展现的只要求一个近似值,但最终的统计要求是准确的,这个时候可以使用LongAdder。而在一些对实时性要求比较高的场景下,LongAdder 并不能取代 AtomicInteger 或 AtomicLong
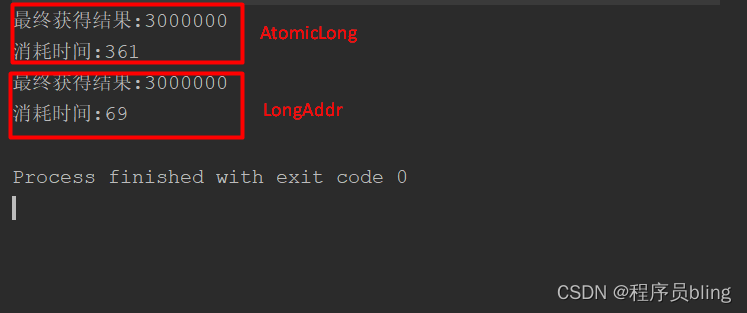
下面是LongAdder用法举例及和AtomicLong的性能对比.
分别使用这两个类对数值累加300w次.
public class Test {
public static void main(String[] args) {
calculateTime(new AtomicLong(), 300);
calculateTime(new LongAdder(), 300);
}
public static void calculateTime(Number count, int threadNum){
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
new Thread(() -> {
for (int j = 0; j < 10000; j++) {
count(count);
}
countDownLatch.countDown();
}).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("最终获得结果:"+get(count));
System.out.println("消耗时间:"+(System.currentTimeMillis() - startTime));
}
public static void count(Number count){
if(count instanceof LongAdder){
((LongAdder) count).increment();
}else if(count instanceof AtomicLong){
((AtomicLong) count).addAndGet(1);
}else {
throw new RuntimeException("其他实现类");
}
}
public static Long get(Number count){
if(count instanceof LongAdder){
return ((LongAdder) count).sum();
}
if(count instanceof AtomicLong){
return ((AtomicLong) count).get();
}
throw new RuntimeException("其他实现类");
}
}
运行结果:
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.