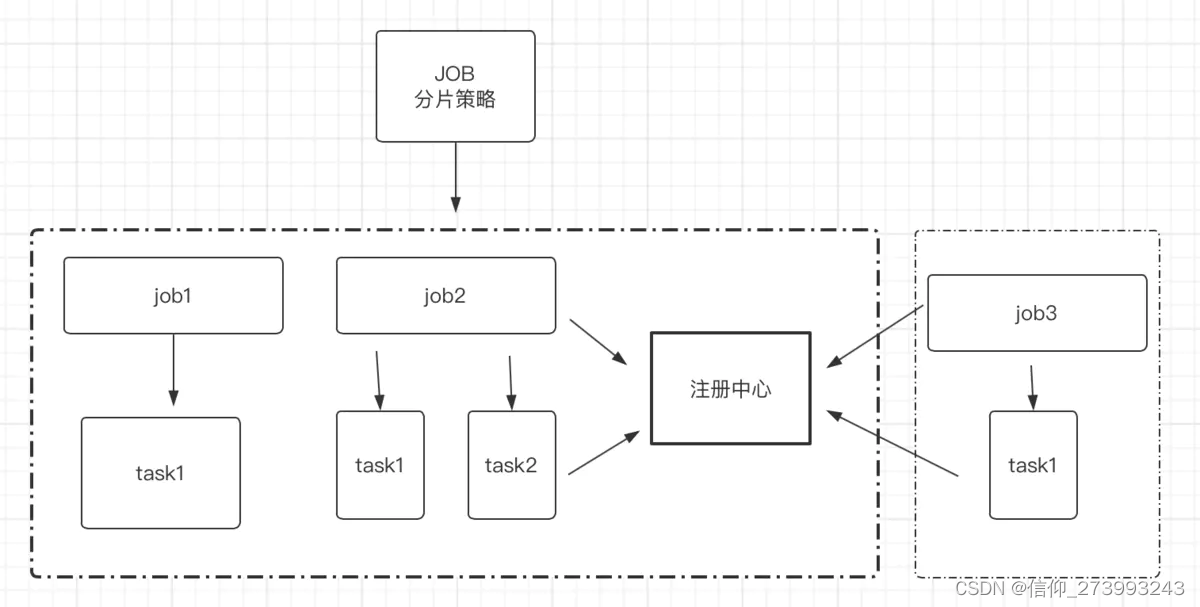
本文是19年学生时学习林子雨老师课程中的一些学习笔记,主要内容包括RDD的概念和运行原理,rdd相关编程api接口以及对应的实例。关于RDD的内容,这个笔记描述的2019年年底之前的pyspark版本,2023年年初时在pyspark的实际工作中rdd已经很少用或者说被弃用了,2023年目前主要用的都是用pyspark中的 DataFrame来进行相关操作了。 了解下就好。
目录
RDD
RDD概念
RDD典型的执行过程如下:(了解)
RDD特性:
RDD 编程
RDD创建与文件读写
创建RDD的途径
RDD操作
转换操作 transformation
filter(func)
map(func)
flatMap(func)
groupByKey()
reduceByKey(func)
reduceByKey与groupBykey的区别:
values()
sortByKey()
sortBy(func)
mapValues(func)
join()
转换操作一个综合案例
综合案例2 : 求top 值
案例3 文件数值排序
案例4 二次排序
行动操作 Action
常见RDD行动操作API
持久化cache 与unpersist
wordCount综合RDD综合项目
RDD
RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“动作”(Action)和“转换”(Transformation)两种类型
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)
RDD典型的执行过程如下:(了解)
RDD读入外部数据源进行创建
RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
RDD特性:
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
(2)中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
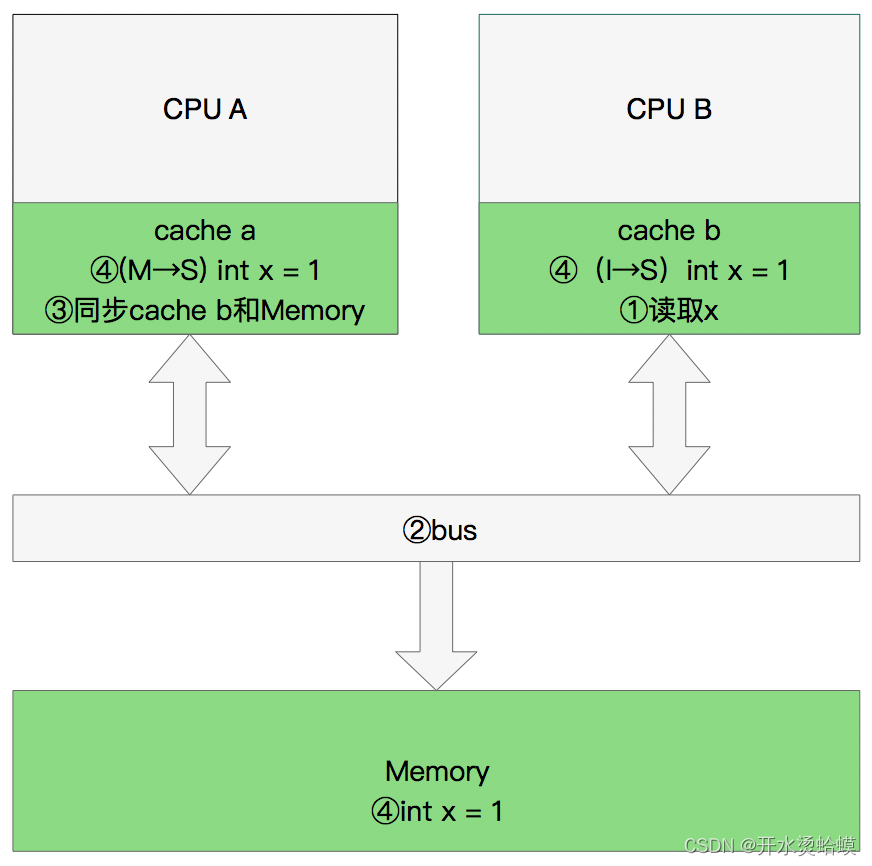
通过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。

图 RDD在Spark中的运行过程
RDD 编程
一个Driver就包括main方法和分布式数据集,spark Shell本身就是一个Driver,里面已经包含了main方法
spark-shell命令及其常用的参数如下:
./bin/spark-shell --master <master-url>
Spark的运行模式取决于传递给SparkContext的Master URL的值。Master URL可以是以下任一种形式:
* local 使用一个Worker线程本地化运行SPARK(完全不并行)
* local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
* local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
* spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077
* yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
* mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050
* yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
RDD创建与文件读写
通常而言,RDD是非常灵活的数据集合,其中可以存放类型相同或者互异的数据,同时可以指定任何自己期望的函数对其中的数据进行处理。
创建一个普通RDD
| # 从list中创建 rdd = sc.parallelize([1, '2', (3, 4), ['5', '6']]) # 从文件中读取 rdd = sc.textFile('\path\to\file') |
还有一类RDD是key-value Pair RDD,即规定RDD每个元素都是一个二元组,其中第一个值是key,第二个值为value,key一般选取RDD中每个元素的一个字段。
创建一个PairRDD:
| rdd = sc.parallelize([('a', 1, 2), ('b', 3, 4), ('c', 5, 6)]) #词默认的values只是第二个元素 rdd.values().collect() #输出只有[1, 3, 5] # pair_rdd = rdd.map(lambda x: (x[0], x[1:])) #提取每个元素的第一个元素作为key,剩余元素作为value(需要用x[1: ]创建Pair RDD, >>> pair_rdd.values().collect() [(1, 2), (3, 4), (5, 6)] >>> |
Pair RDD由于有key的存在,与普通的RDD相比更加格式化,这种特性就会给Pair RDD赋予一些特殊的操作,例如groupByKey()可以将具有相同key进行分组,其结果仍然得到Pair RDD,然后利用mapValues()对相同key的value进行函数计算reduceByKey()、countByKey()和sortByKey()等一系列“ByKey()”操作同理。
此处参考:PySpark中RDD与DataFrame相互转换操作_Data_IT_Farmer的博客-CSDN博客_pyspark rdd转dataframe
创建RDD的途径
- 从文件系统中加载数据创建RDD
- Spark采用textFile()方法来从文件系统中加载数据创建RDD
- 该方法把文件的URI作为参数,这个URI可以是:
- 本地文件系统的地址
- 或者是分布式文件系统HDFS的地址
- 或者是Amazon S3的地址等等
lines=sc.textFile(文件路径与文件名),lines即为一个RDD
文件读写:可以分为从本地文件系统数据读写创建RDD和从hdfs中读取
1)本地文件数据读写:
textRDD=sc.textFile(“file:///本地文件路径”) 注意file后面为三个反斜杠,本地文件路径(或目录(目录则目录下的全部文件)直接复制到电脑即可。
将RDD写入到文本文件中:
textRDD2.saveAsTextFile(“fille:///本地目录”) .注意是目录,多个RDD分区都会写到这个目录中。
2) 分布式文件系统HDFS的数据读和写
读入:
textRDD=sc.textFile(“hdfs://文件位置或者目录)注意此为两个反斜杠。
或者相对路径。不同公司安装的配置文件可能只允许其中的一种。
写入hdfs :
textRDD.saveAsTextFile(“hdfs://文件路径”)
注意读取数据,需要遇到第一个rdd的动作时才会实际执行读取数据操作。所以刚开始即使路径不对,在没有执行rdd.动作类型的方法前,也不会报错。
如果要求以保存为逗号分隔的csv格式,可以在前面用逗号去分隔(整体一行转为字符串)
#将value以字符串的格式保存,以逗号分隔,将结果保存为csv格式
json_data_to_string = json_data_selected_3.map(lambda x: ','.join(list(map(str,x))))
json_data_to_string.saveAsTextFile('/dw_ext/sinarecmd/zhaojia5/zhaowang/recall_stat/taskfirst1_2')
JSON 文件读取
还是利用sc.textFile。返回的是一个RDD
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,Spark提供了一个JSON样例数据文件,存放在“/usr/local/spark/examples/src/main/resources/people.json”中
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
jsonStr = sc.textFile("file:///usr/local/spark/examples/src/main/resources/people.json")
jsonStr.foreach(print)
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2. 通过并行集合(数组)创建RDD
array=[1,2,3,4,5]
rdd=sc.parallelize(array)
rdd.foreach(print)
将1,2,3,4,5逐个打印
键值对RDD的创建
可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
lines=sc.textFile(file:///user/local/word.txt) #创建了RDD
pairRDD=lines.flatMap(lambda line:line.split(“ “).map(lambda word: (word,1))
##即键值对,不一定非得要字典,用(,)也可以
pairRDD.foreach(print)
输出:
(“I”,1) #这也是键值对啊!
(“love”,1)
(“Hadoop”,1)
…..
方式2:
通过并行集合(列表)创建RDD
list=[“I”,”love”,”Hadoop”,”Hadoop”]
rdd=sc.parallelize(list)
pairRDD=rdd.map(lambda word: (word:1))
pairRDD.foreach(print)
。。。。
RDD操作
转换操作 transformation
• 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算
转换操作只是记录要操作的轨迹,并不会马上执行计算。直到遇到第一个动作类型操作,才会执行计算。

表:常用转换操作
filter(func)
filter(func): 筛选出满足函数func为真的元素,并返回一个新的数据集
map(func)
将每个元素传递到函数func中,并将结果返回为一个新的数据集
map()操作实例执行过程示意图

flatMap(func)

flatMap在理解的时候,可以看成是两步,先map再对map的结果进行flat.
map(func)函数会对输入中的每一条小输入进行指定的func操作,然后为每一条小输入分别返回一个对象,;而flatMap(func)也会对每一条输入进行执行的func操作,然后每一条输入返回一个相对,但是最后会将所有的对象先合成为一个对象后再返回;从返回的结果的数量上来讲,map返回的数据对象的个数和原来的输入数据是相同的,而flatMap返回的个数则是不同的。
可参考:Spark中map和flatMap的区别详解-优米格
groupByKey()
groupByKey()的功能是,对具有相同键的值进行分组
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(k,Iterable)形式的数据集。其中iterable为可迭代的python对象。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))

图 groupByKey()操作实例执行过程示意图
reduceByKey(func)
reduceByKey(func)用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过func函数自定义
应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果。可以看成相当于先groupByKey后,再用里面的函数去作用iterable对象中的元素


reduceByKey与groupBykey的区别:
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
虽然groupByKey可以通过map函数实现与reduceByKey的结果一样,但是内部实现的深层原理是不一样的,计算开销不同。
深层原因:
(1)当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合

(2)当采用groupByKey时,由于它不接收函数,Spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时

keys()
keys会只把Pair RDD中的key返回形成一个新的RDD

values()
values只会把Pair RDD中的value返回形成一个新的RDD。
在进行rdd.values()函数时,rdd里面的每一个元素要为tuple(key, value) 或者list[ key,value]的形式,此处上面的额元素为dict不能直接用values函数
案例:
我们用元素类型为tuple元组的数组初始化我们的RDD,这里,每个tuple的第一个值将作为键,而第二个元素将作为值。
kvRDD1 = sc.parallelize([(3,4),(3,6),(5,6),(1,2)])
可以使用keys和values函数分别得到RDD的键数组和值数组:
print (kvRDD1.keys().collect())
print (kvRDD1.values().collect())
输出:
[3, 3, 5, 1]
[4, 6, 6, 2]
https://www.jianshu.com/p/4cd22eda363f
sortByKey()
sortByKey()的功能是返回一个根据键排序的RDD,默认是升序。如果要为降序则里面为
sortByKey(False). 注意这个key可以是数值(除了单个数值外,甚至可以是也可以是字符串,但前提是需要可以比较的对象的key .
输入的RDD:

sortBy(func)
自定义排序规则。第一个参数(或者为函数),可以根据键排序也可以根据值排序,注意x[0]与x[1]的选择;第二个参数如果为True,则为升序,False则为降序。注意x

mapValues(func)
对键值对RDD中的每个元素的value都应用一个函数,进行操作,key不会发生变化。返回变换后的RDD

案例2 :rdd.mapValues(lambda x:(x,1)) 实现给每个元素的value添加一个值!!!直接这样括号里加值就行!

join()
join表示内连接。对于给定的两个输入数据集RDD1中的(K,V1)和RDD中的(K,V2),
只有在两个数据集都存在的相同的key才会被输出,最终得到一个含有相同key的元素的(K,(V1,V2))类型的数据集。

转换操作一个综合案例
题目:给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。

具体计算过程:

尤其是其中的reduceByKey的计算过程:注意x[0]与y[0]的含义,指的是value-list中的第一个元素的第一个值与第二个元素中的第二个值。(见下左图)

mapvalues(lambda x:x[0]/x[1])的过程见下图

综合案例2 : 求top 值
问题:在x/目录下有file1.txt和file2.txt文件,每个文件的每行由orderid,userid ,payment ,productid 四个属性组成。求其中top N 个payment的值
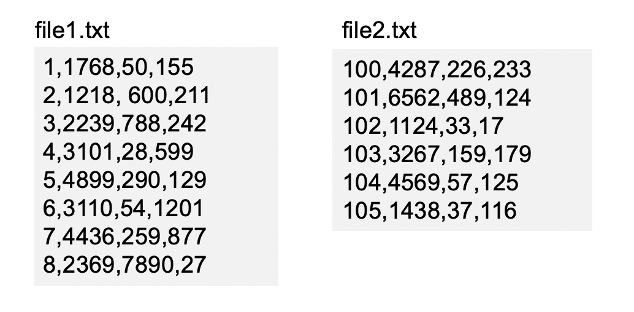
思路1:整体是借助sortByKey来排序。 先转换为RDD,然后取其中的目标列,对于取到的目标列为了借助sortByKey,将其转换为key-value的形式,添加的value可以为空,然后再取元素的x[0].
具体实现:
rdd.repartion(1)是为了将数据放在一个分区里,保证的是全局有序,而不是某些个分区的各分区的局部有序。
代码答案为:

其中过程为:



案例3 文件数值排序
视频链接参考:Spark编程基础(Python版) - 网易云课堂
任务描述

思路仍然是利用sortByKey,一个要注意用了rdd.repartion(1)函数(保证全局有序),另一个要注意自定义了getIndex函数里的全局变量获得全局排序的序号。
答案:

注意上面由result1得到result2的过程中,对x.strip()是把可能的行分割符号去掉。( strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。)

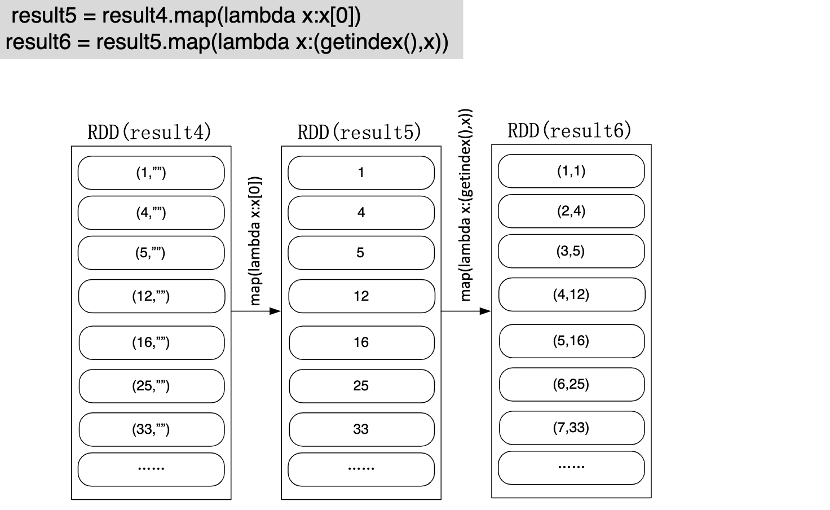
注意上面自定义的getindex()是拿到排序后的大小序号。
案例4 二次排序

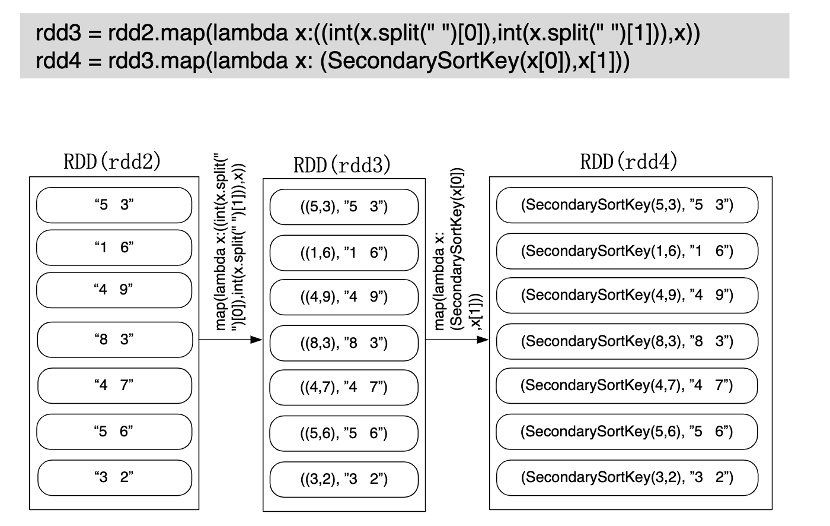
如果是在用sortByKey()的时候,里面的key必须为可以比较对对象,像元素的‘5 3’ 和元素为’1 6’为str类型时,就没法像题意的那样安装整型的值去排序。
需要做变换才能调用sortByKey()
解题思路:

其中自定义排序key的类函数为

注意上面的 gt 函数,为python3中的比较函数,gt,即greater than ,gt(a, b) 与 a > b 相同,返回布尔值。---此处别细究了。

详细过程:

详细过程为:



案例3 文件数值排序
视频链接参考:Spark编程基础(Python版) - 网易云课堂
任务描述

思路仍然是利用sortByKey,一个要注意用了rdd.repartion(1)函数(保证全局有序),另一个要注意自定义了getIndex函数里的全局变量获得全局排序的序号。
答案:

注意上面由result1得到result2的过程中,对x.strip()是把可能的行分割符号去掉。( strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。)


注意上面自定义的getindex()是拿到排序后的大小序号。
案例4 二次排序

如果是在用sortByKey()的时候,里面的key必须为可以比较对对象,像元素的‘5 3’ 和元素为’1 6’为str类型时,就没法像题意的那样安装整型的值去排序。
需要做变换才能调用sortByKey()
解题思路:

其中自定义排序key的类函数为

注意上面的 gt 函数,为python3中的比较函数,gt,即greater than ,gt(a, b) 与 a > b 相同,返回布尔值。---此处别细究了。

详细过程:

详细过程为:


行动操作 Action
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
常见RDD行动操作API
take、reduce、collect、count、foreach
表 常用的RDD行动操作API
| 操作 | 含义 |
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
持久化cache 与unpersist
在Spark中,RDD采用惰性求值的机制,如果没有将RDD持久化,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的
可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist()方法对一个RDD标记为持久化
一般而言,使用cache()方法时,就相当于调用persist(pyspark.StorageLevel.MEMORY_ONLY)
persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容。
之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
可以使用rdd.unpersist()方法手动地把持久化的RDD从缓存中移除
persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上

运行写了pyspark的.py文件

wordCount综合RDD综合项目