文章目录
- 一、数据集介绍
- 1.1 lufei(路飞)
- 1.2 luobin(罗宾)
- 1.3 namei(娜美)
- 1.4 qiaoba(乔巴)
- 1.5 shanzhi(山智)
- 1.6 suolong(索隆)
- 1.7 wusuopu(乌索普)
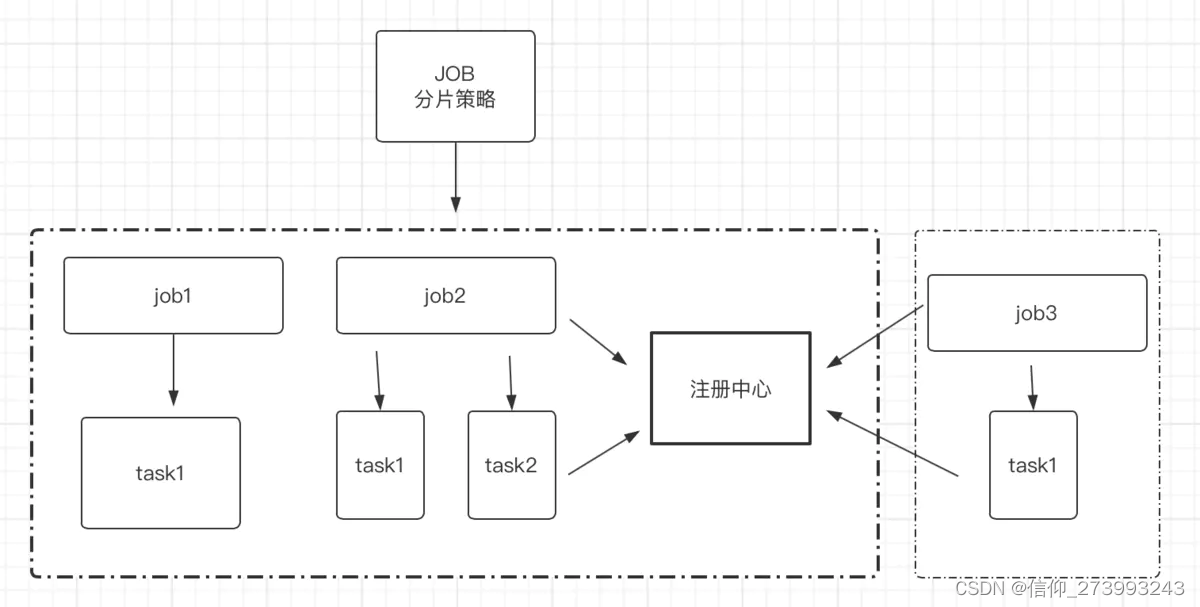
- 二、项目结构
- 三、代码实现
- 3.1 DataSet.py
- 3.2 Model.py
- 3.3 Run_Test.py
- 3.4 Run_Train.py
- 3.5 TrainFunction.py
- 3.6 TestFunction.py
- 3.7 Util.py
- 四、效果展示
- 五、RuntimeError: DataLoader worker (pid(s) 26192, 29160) exited unexpectedly
关于生成对抗网络(GAN)的介绍可以参考链接:【深度学习】李宏毅2021/2022春深度学习课程笔记 - Generative Adversarial Network 生成式对抗网络(GAN)
一、数据集介绍
海贼王图像数据集下载链接:hzw-photos.rar

1.1 lufei(路飞)
1.2 luobin(罗宾)
1.3 namei(娜美)
1.4 qiaoba(乔巴)

1.5 shanzhi(山智)
1.6 suolong(索隆)
1.7 wusuopu(乌索普)
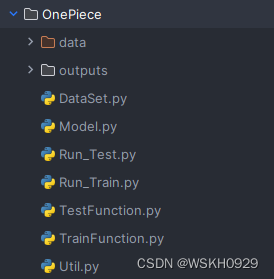
二、项目结构
其中 data 为数据集的根目录;outputs目录是自动生成的,不用手动创建。其余py文件会在下一章进行介绍
三、代码实现
3.1 DataSet.py
用来获取数据集,并返回继承于Dataset的自定义的MyDataset对象
import glob
import torchvision.transforms as transforms
import os
import torchvision
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, fnames, transform):
self.transform = transform
self.fnames = fnames
self.num_samples = len(self.fnames)
def __getitem__(self, idx):
fname = self.fnames[idx]
img = torchvision.io.read_image(fname)
resize_transform = transforms.Compose([transforms.Resize((64, 64))])
img = resize_transform(img)
img = self.transform(img)
return img
def __len__(self):
return self.num_samples
def get_dataset(root):
fnames = []
for sub_dir in os.listdir(root):
fnames.extend(glob.glob(os.path.join(os.path.join(root, sub_dir), '*')))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = MyDataset(fnames, transform)
return dataset
3.2 Model.py
用来定义 Generator 生成器模型和 Discriminator 判别器模型
import torch.nn as nn
# setting for weight init function
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
# input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU()
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(feature_dim * 8, feature_dim * 4), # (batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(feature_dim * 4, feature_dim * 2), # (batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(feature_dim * 2, feature_dim), # (batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(feature_dim, 3, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False),
nn.Tanh()
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False), # double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True)
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
# input: (batch, 3, 64, 64)
"""
NOTE FOR SETTING DISCRIMINATOR:
Remove last sigmoid layer for WGAN
"""
self.l1 = nn.Sequential(
nn.Conv2d(in_dim, feature_dim, kernel_size=4, stride=2, padding=1), # (batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), # (batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), # (batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), # (batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
"""
NOTE FOR SETTING DISCRIMINATOR:
You can't use nn.Batchnorm for WGAN-GP
Use nn.InstanceNorm2d instead
"""
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y
3.3 Run_Test.py
对训练好的模型进行测试
import json
import pickle
from TestFunction import *
from Model import *
from Util import *
from pathlib import Path
if __name__ == '__main__':
# 防止报错 OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# load and print config
with open("./outputs/models/config", "rb") as file:
config = pickle.load(file)
print("config:")
print(json.dumps(config, indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':')))
# Set seed for reproducibility
# same_seed(config['seed'])
# create test_save_dir
Path(config['test_save_dir']).mkdir(parents=True, exist_ok=True)
# init Model and load saved model's parameter
G = Generator(100).cuda()
# Load your best model
ckpt = torch.load(config['model_save_dir'] + "G_0.pth")
G.load_state_dict(ckpt)
# test process
test(G, config)
3.4 Run_Train.py
利用数据集进行训练
import pickle
from torch.utils.data import DataLoader
from TrainFunction import *
from Model import *
from Util import *
from pathlib import Path
if __name__ == '__main__':
# 防止报错 OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# data path
data_dir = './data'
# define config
config = {
'seed': 929, # Your seed number, you can pick your lucky number. :)
'device': 'cuda' if torch.cuda.is_available() else 'cpu',
"model_type": "GAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 1000,
"n_critic": 1,
"z_dim": 100,
"workspace_dir": data_dir, # define in the environment setting
'model_save_dir': './outputs/models/', # Your model will be saved here.
'train_save_dir': './outputs/train/', # Your model train pred valid data and learning curve will be saved here.
'test_save_dir': './outputs/test/', # Your model pred test data will be saved here.
'log_dir': './outputs/log/',
}
print("device:", config['device'])
# Set seed for reproducibility
same_seed(config['seed'])
# create save dir
Path(config['model_save_dir']).mkdir(parents=True, exist_ok=True)
Path(config['train_save_dir']).mkdir(parents=True, exist_ok=True)
Path(config['log_dir']).mkdir(parents=True, exist_ok=True)
# Get Data
dataset = get_dataset(os.path.join(config["workspace_dir"]))
train_loader = DataLoader(dataset, batch_size=config["batch_size"], shuffle=True, num_workers=2)
# init Model (Construct model and move to device)
G = Generator(100).cuda()
D = Discriminator(3).cuda()
# train process
loss_record = train(train_loader, config, G, D)
# plot and save learning curve and valid_pred image
plot_GAN_learning_curve(loss_record, save_dir=config['train_save_dir'])
# save config
with open(config['model_save_dir'] + "config", "wb") as file:
pickle.dump(config, file)
3.5 TrainFunction.py
训练过程的函数
import logging
import torch
from matplotlib import pyplot as plt
from torch.autograd import Variable
from tqdm import tqdm
from DataSet import *
from Model import *
def train(train_loader, config, G, D):
# Setup optimizer
opt_D = torch.optim.Adam(D.parameters(), lr=config["lr"], betas=(0.5, 0.999))
opt_G = torch.optim.Adam(G.parameters(), lr=config["lr"], betas=(0.5, 0.999))
# loss function
loss = nn.BCELoss()
FORMAT = '%(asctime)s - %(levelname)s: %(message)s'
logging.basicConfig(level=logging.INFO,
format=FORMAT,
datefmt='%Y-%m-%d %H:%M')
z_samples = Variable(torch.randn(100, config["z_dim"])).cuda()
loss_record = {"G": [], "D": []}
steps = 0
for e, epoch in enumerate(range(config["n_epoch"])):
progress_bar = tqdm(train_loader)
progress_bar.set_description(f"Epoch {e + 1}")
for i, data in enumerate(progress_bar):
imgs = data.cuda()
bs = imgs.size(0)
# *********************
# * Train D *
# *********************
z = Variable(torch.randn(bs, config["z_dim"])).cuda()
r_imgs = Variable(imgs).cuda()
f_imgs = G(z)
r_label = torch.ones((bs)).cuda()
f_label = torch.zeros((bs)).cuda()
# Discriminator forwarding
r_logit = D(r_imgs)
f_logit = D(f_imgs)
"""
NOTE FOR SETTING DISCRIMINATOR LOSS:
GAN:
loss_D = (r_loss + f_loss)/2
WGAN:
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
WGAN-GP:
gradient_penalty = gp(r_imgs, f_imgs)
loss_D = -torch.mean(r_logit) + torch.mean(f_logit) + gradient_penalty
"""
# Loss for discriminator
r_loss = loss(r_logit, r_label)
f_loss = loss(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
# Discriminator backwarding
D.zero_grad()
loss_D.backward()
opt_D.step()
"""
NOTE FOR SETTING WEIGHT CLIP:
WGAN: below code
"""
# for p in D.parameters():
# p.data.clamp_(-config["clip_value"], config["clip_value"])
# *********************
# * Train G *
# *********************
if steps % config["n_critic"] == 0:
# Generate some fake images.
z = Variable(torch.randn(bs, config["z_dim"])).cuda()
f_imgs = G(z)
# Generator forwarding
f_logit = D(f_imgs)
"""
NOTE FOR SETTING LOSS FOR GENERATOR:
GAN: loss_G = loss(f_logit, r_label)
WGAN: loss_G = -torch.mean(D(f_imgs))
WGAN-GP: loss_G = -torch.mean(D(f_imgs))
"""
# Loss for the generator.
loss_G = loss(f_logit, r_label)
# Generator backwarding
G.zero_grad()
loss_G.backward()
opt_G.step()
loss_record["G"].append(loss_G.item())
loss_record["D"].append(loss_D.item())
if steps % 10 == 0:
progress_bar.set_postfix(loss_G=loss_G.item(), loss_D=loss_D.item())
steps += 1
# 验证生成器效果,输出图片
G.eval()
f_imgs_sample = (G(z_samples).data + 1) / 2.0
filename = os.path.join(config['log_dir'], f'Epoch_{epoch + 1:03d}.jpg')
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
G.train()
# Save the checkpoints.
torch.save(G.state_dict(), os.path.join(config['model_save_dir'], f'G_{e}.pth'))
torch.save(D.state_dict(), os.path.join(config['model_save_dir'], f'D_{e}.pth'))
logging.info('Finish training')
return loss_record
3.6 TestFunction.py
测试过程的代码
import logging
import os
import torch
import torchvision
from matplotlib import pyplot as plt
from torch.autograd import Variable
def test(G, config):
G.eval()
z_samples = Variable(torch.randn(100, config["z_dim"])).cuda()
FORMAT = '%(asctime)s - %(levelname)s: %(message)s'
logging.basicConfig(level=logging.INFO,
format=FORMAT,
datefmt='%Y-%m-%d %H:%M')
f_imgs_sample = (G(z_samples).data + 1) / 2.0
filename = os.path.join(config['test_save_dir'], f'test.jpg')
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
3.7 Util.py
工具类
import numpy as np
import torch
import random
import matplotlib.pyplot as plt
def same_seed(seed):
"""
Fixes random number generator seeds for reproducibility
固定时间种子。由于cuDNN会自动从几种算法中寻找最适合当前配置的算法,为了使选择的算法固定,所以固定时间种子
:param seed: 时间种子
:return: None
"""
torch.backends.cudnn.deterministic = True # 解决算法本身的不确定性,设置为True 保证每次结果是一致的
torch.backends.cudnn.benchmark = False # 解决了算法选择的不确定性,方便复现,提升训练速度
np.random.seed(seed) # 按顺序产生固定的数组,如果使用相同的seed,则生成的随机数相同, 注意每次生成都要调用一次
torch.manual_seed(seed) # 手动设置torch的随机种子,使每次运行的随机数都一致
random.seed(seed)
if torch.cuda.is_available():
# 为GPU设置唯一的时间种子
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def plot_GAN_learning_curve(loss_record, save_dir=None):
x = range(len(loss_record['G']))
# Generator
plt.figure()
plt.plot(x, loss_record['G'], c='tab:red')
plt.xlabel('Generator Updates')
plt.ylabel('Loss')
plt.title('Learning curve of Generator')
plt.grid(False)
if save_dir is not None:
plt.savefig(save_dir + "generator_learning_curve.svg")
plt.show()
# Discriminator
plt.figure()
plt.plot(x, loss_record['D'], c='tab:red')
plt.xlabel('Discriminator Updates')
plt.ylabel('Loss')
plt.title('Learning curve of Discriminator')
plt.grid(False)
if save_dir is not None:
plt.savefig(save_dir + "discriminator_learning_curve.svg")
plt.show()
四、效果展示
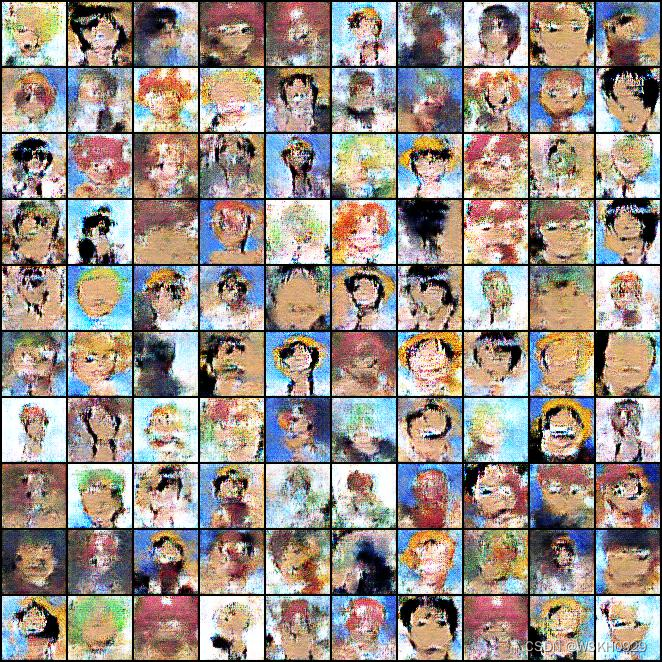
由于训练到一半内存不够报错了,我只训练了 506 个epoch
第 1 个epoch

第 10 个epoch

第 50 个epoch

第 100 个epoch

第 200 个epoch

第 300 个epoch

第 400 个epoch

第 506 个epoch
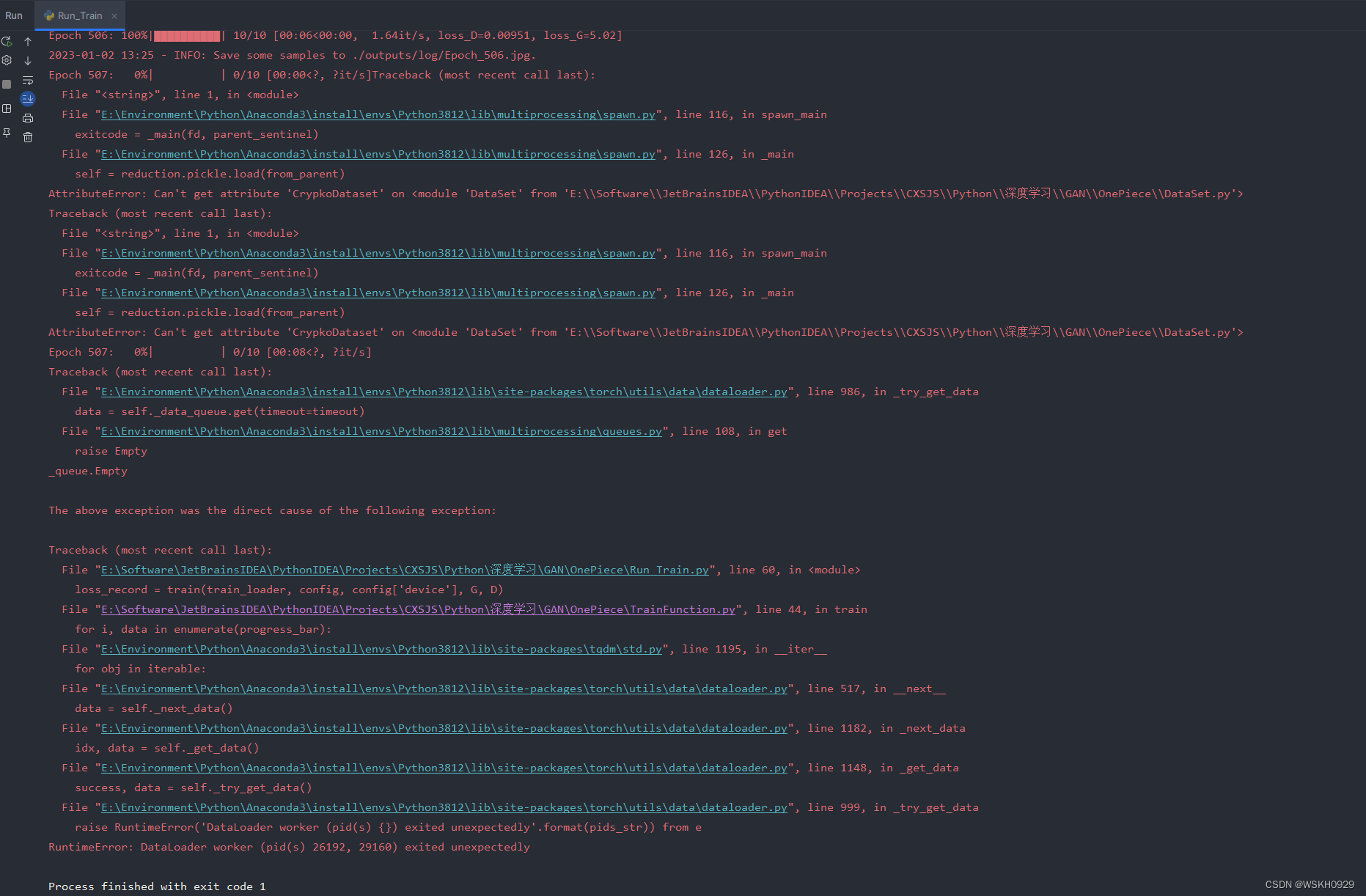
五、RuntimeError: DataLoader worker (pid(s) 26192, 29160) exited unexpectedly
下图所示就是我运行时报的错,查阅网上的回答,说最可能的原因是:cuda 虚拟环境的共享内存不足,解决办法是改成更小的 batch_size



![[torch]日志记录之SummaryWriter(持更)](https://img-blog.csdnimg.cn/d0d1e944840b4048818a6a156f5a28b8.png)

![[红明谷CTF 2021]JavaWeb](https://img-blog.csdnimg.cn/7ad0a11f2a3e461cbff3231299e29b1b.png)