一、闲话
这是2023年的第一篇博客,祝大家在新的一年里一帆风顺,身体健康
二、基本要点
1、Kafka概述
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要用于大数据实时处理领域
2、消息队列的好处
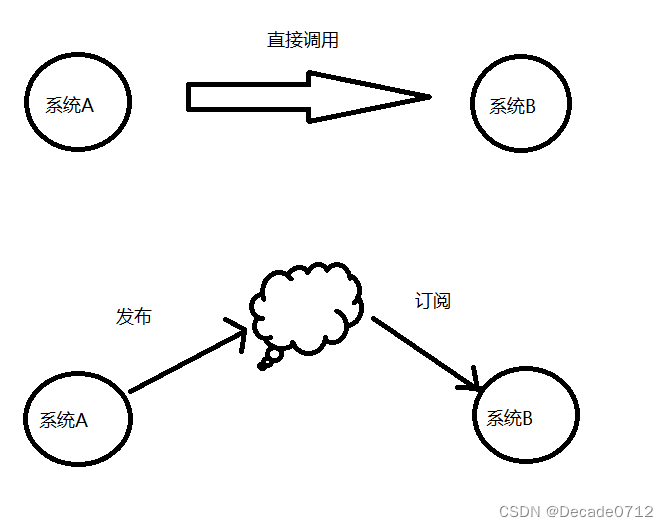
- 解耦:利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果调用的接口出了问题,将不会影响到当前的功能
- 流量削峰:高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力
- 异步处理:不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可,减少了客户的等待时间
3、消息队列的两种模式
-
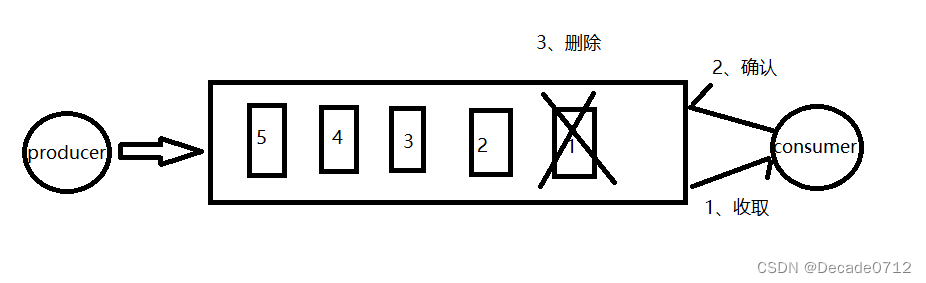
点对点(一对一模式,消费者主动拉取消息,收到消息后清除消息)
生产者生产消息发送到队列Queue中,然后消费者从Queue中取出消息并消费,消息被消费后,Queue不再存储此消息。一条消息只能被一个消费者消费
-
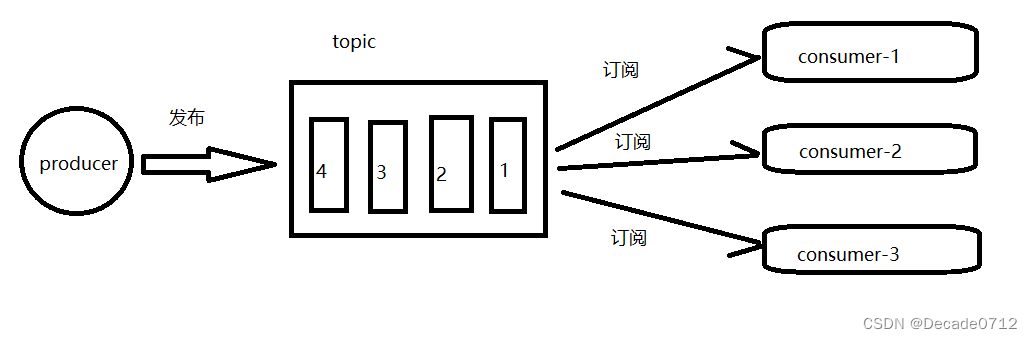
发布/订阅模式(一对多模式,消费者消费消息后不会清除消息)
消息生产者将消息发布到topic中,同时有多个消息订阅者来消费该消息。与点对点模式不同的是,发布到topic的消息可以被所有消费者消费
此模式的消息消费有2种场景:一种是队列推送消息给消费者,另外一种是消费者主动去拉取(Kafka属于后者,此模式的优势在于可以由消费者自己去决定消息消费的速度,但是消费者要一直维持一个消息轮询任务,确认是否有新消息推送)
4、Kafka的基本架构
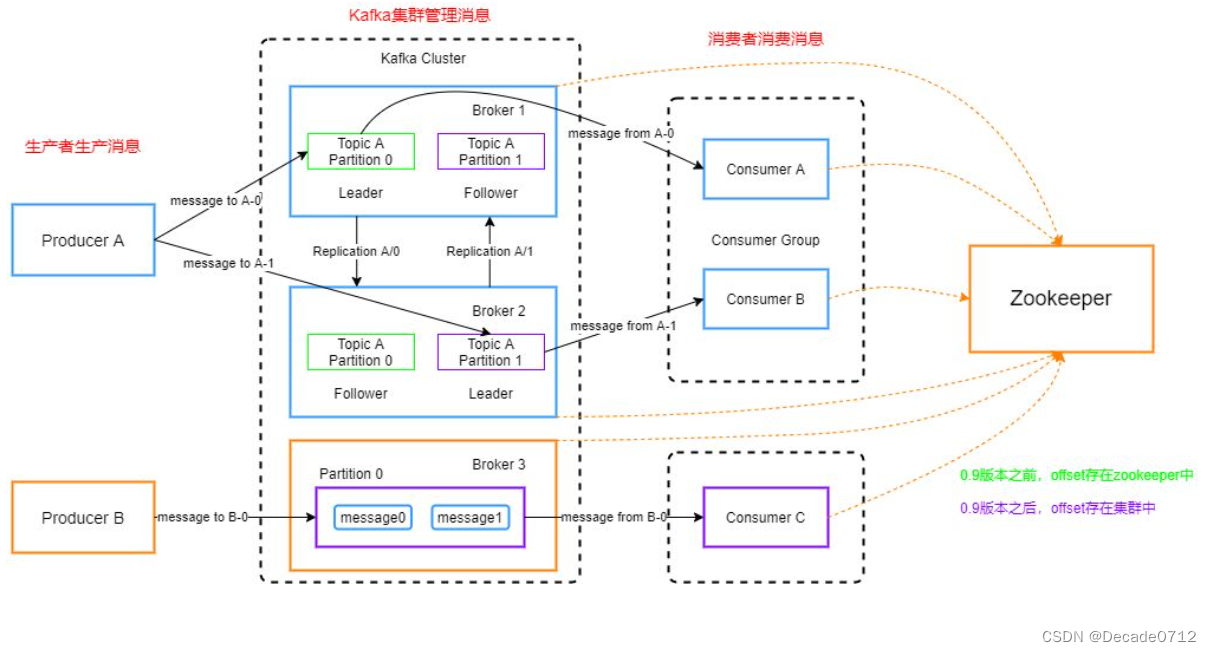
- Producer:消息生产者,向Kafka中发布消息的角色
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端
- Broker:就是一台Kafka服务器,集群由多个broker组成,一个Broker可以容纳多个Topic
- Topic:主题,可以理解为一个队列,生产者和消费者进行消息传递都是面向同一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Consumer Group:消费者组,一个消费者组中可以存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower(可以结合前面redis的集群进行理解)
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader
- Zookeeper的作用
- 存储Kafka集群的信息,当作注册中心使用
- 存储消费者消费到的位置信息,即offset偏移量(0.9版本之前存在zk上,后面的版本都存在Kafka上)
如有错误,欢迎指正!!!