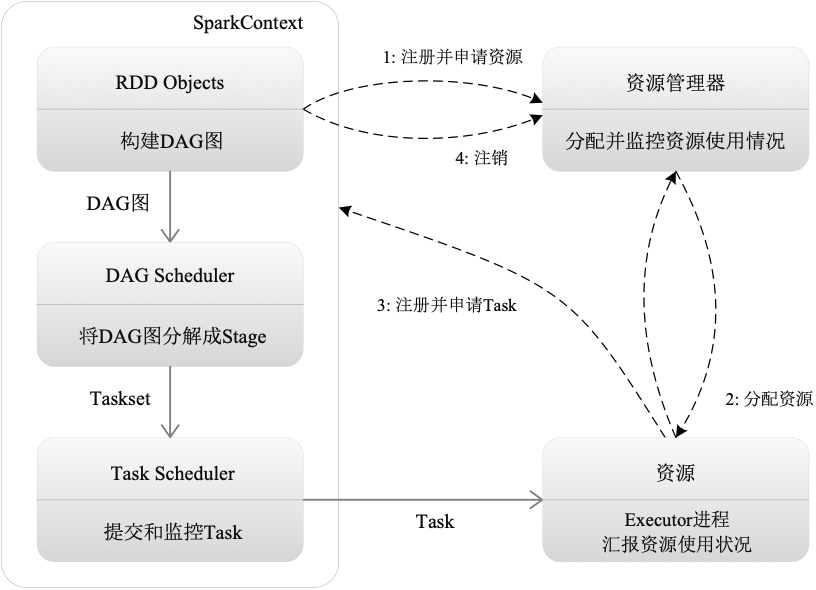
1. KeyValue
- dict.clear() 删除字典内所有元素
- dict.copy()返回一个字典的浅复制
- [dict.fromkeys(seq, val])创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值
- dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
- dict.has_key(key)如果键在字典dict里返回true,否则返回false
- dict.items()以列表返回可遍历的(键, 值) 元组数组
- dict.keys() 以列表返回一个字典所有的键
注意这里面的括号 - dict.setdefault(key, default=None)和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
- dict.update(dict2) 把字典dict2的键/值对更新到dict里
- dict.values()以列表返回字典中的所有值
- [ pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
- popitem() 返回并删除字典中的最后一对键和值。
注意,使用append 添加一行数据时候,要使用按行或者按列追加,否则会出现错误,
data={}
for i in range(0,len(test_x)):
if test_y[i] in data:
data[test_y[i]]=np.row_stack((data[test_y[i]],test_x[i]))
else:
print("addd:",test_y[i])
data[test_y[i]]=test_x[i]
2. 固定长度数组
class HandBase():
def __init__(self,length):
self.A=[]
self.B=[]
self.C=[]
self.D=[]
self.E=[]
self.length=length
def add(self,data):
'''
data=[a,b,c,d,e], 如果不是该格式,则舍弃
'''
if len(data)!=5:
return
#todo arduino 上面sleep(50ms), 选择什么参数比较合适
if len(self.A)>self.length:
self.A.pop(0)
self.B.pop(0)
self.C.pop(0)
self.D.pop(0)
self.E.pop(0)
self.A.append(data[0])
self.B.append(data[1])
self.C.append(data[2])
self.D.append(data[3])
self.E.append(data[4])
#todo 后续可以再这里面添加数据拟合算法
def getMean(self):
return np.mean(self.A),np.mean(self.B),np.mean(self.C),np.mean(self.D),np.mean(self.E)
def getLength(self):
return len(self.A)
def saveData(self,filename):
strflex=",".join([str(i) for i in self.A])+"\n"+",".join([str(i) for i in self.B])+"\n"+",".join([str(i) for i in self.C])+"\n"+",".join([str(i) for i in self.D])+"\n"+",".join([str(i) for i in self.E])
#todo 存储到文件中,还是数据库中? 存储到文件中已经完成,是否需要存储到数据库中
with open(filename, 'w') as f:
f.write(strflex)
print("saveData Ok",filename)
def clear(self):
self.A.clear()
self.B.clear()
self.C.clear()
self.D.clear()
self.E.clear()
3. 行列操作
3.1. 逆序遍历
a = [1,3,6,8,9]
print("通过下标逆序遍历1:")
for i in a[::-1]:
print(i, end=" ")
print("\n通过下标逆序遍历2:")
for i in range(len(a)-1,-1,-1):
print(a[i], end=" ")
print("\n通过reversed逆序遍历:")
for i in reversed(a):
print(i, end=" ")
3.2. 行列拼接
#方法一
# 该方法只能将两个矩阵合并
# 注意要合并的两矩阵的行列关系
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
b = np.array([[0,0,0]])
c = np.r_[a,b] # 按行拼接,添加在行尾部
d = np.c_[a,b.T] # 按列拼接,添加在列尾部
#方法二:
# 将一个集合插入到一个矩阵中,对于b可以是列表或元组,它仅仅提供要插入的值,但个数要对
# np.insert的第二个参数是插入的位置从0开始,axis用来控制是插入行还是列!
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
b = np.array([[0,0,0]])
c = np.insert(a, 0, values=b, axis=0) #axis=0 代表 按行插入,使其成为一行
d = np.insert(a, 0, values=b, axis=1) #axis=1 代表 按列插入,使其成为一列
#方法三
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
b = np.array([[0,0,0]])
c = np.row_stack((a,b)) # 按行拼接,添加在行尾部, 注意俩个元素用括号括起来了
d = np.column_stack((a,b.T)) # 按列拼接,添加在列尾部
.1. concatenate
0轴的数组对象进行纵向的拼接(纵向的拼接沿着axis= 1方向);注:
一般axis = 0,就是对该轴向的数组进行操作,操作方向是另外一个轴,即axis=1。
Join a sequence of arrays along an existing axis.
Parameters
a1, a2, ... : sequence of array_like
The arrays must have the same shape, except in the dimension
corresponding to `axis` (the first, by default).
axis : int, optional
The axis along which the arrays will be joined. Default is 0.
Returns
res : ndarray
The concatenated array.
See Also
--------
ma.concatenate : Concatenate function that preserves input masks.
array_split : Split an array into multiple sub-arrays of equal or
near-equal size.
split : Split array into a list of multiple sub-arrays of equal size.
hsplit : Split array into multiple sub-arrays horizontally (column wise)
vsplit : Split array into multiple sub-arrays vertically (row wise)
dsplit : Split array into multiple sub-arrays along the 3rd axis (depth).
stack : Stack a sequence of arrays along a new axis.
hstack : Stack arrays in sequence horizontally (column wise)
vstack : Stack arrays in sequence vertically (row wise)
dstack : Stack arrays in sequence depth wise (along third dimension)
3.3. 数组转置
np.transpose(arr)
3.4. 维度
array.shape返回数组的行数和列数;array.size返回数组的元素个数;array.dtype返回数组里元素的数据类型。
- x.shape[:3]表示返回(3, 2, 3),分别表示三维数组中二维数组的个数、单个二维数组的行数、单个二维数组的列数。
- #转化为一维
numpy.flatten()返回一份拷贝,对拷贝所做的修改不会影响(reflects)原始矩阵;numpy.ravel()返回的是视图(view,也颇有几分C/C++引用reference的意味),会影响(reflects)原始矩阵。
- reshape
# 转化一行
z.reshape(1,-1)
# 转化一列
z.reshape(-1,1)
# 转化x行y列
z.reshape(x,y)
- numpy 初始化
# numpy 创建方式一
list = [1 , 2 , 3 , 4]
array_1 = np.array(list_1)
# numpy 创建方式二
array_4 = np.arange(1 ,10)
3.5. 切片
# 首先看数组维度
c[:2,1:] # 对于二维数组,“:2”表示行:即从第0行开始到第2行(不包括第2行)结束的行的元素,“1:”表示从第1列到后面几列的元素。
4. 打乱数据
np.random.shuffle(x):在原数组上进行,
改变自身序列,无返回值。np.random.permutation(x):不在原数组上进行,
返回新的数组,不改变自身数组。
- 都是按行进行打乱,如果只有一行则按列进行打乱;
5. 数据维度
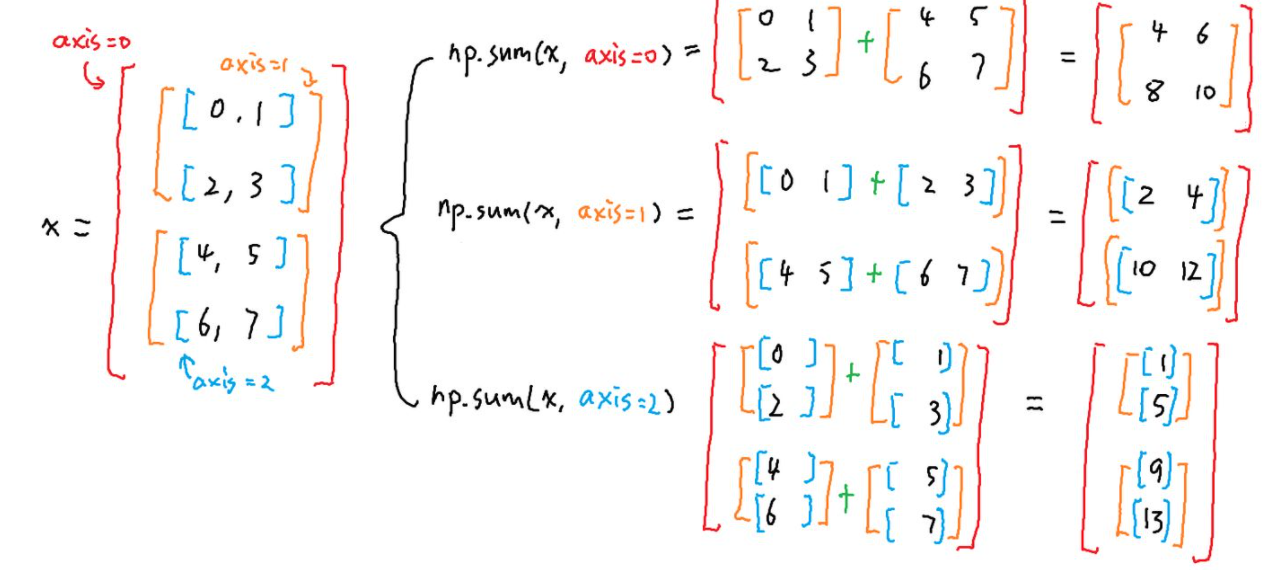
einops主要是rearrange, reduce, repeat这3个方法,下面介绍如何通过这3个方法如何来起到 stacking, reshape, transposition, squeeze/unsqueeze, repeat, tile, concatenate, view 以及各种reduction操作的效果)
#pip install einops
y = x.transpose(0, 2, 3, 1)
y = rearrange(x, 'b c h w -> b h w c')
rearrange(ims[0], 'h w c -> w h c')
# length of newly composed axis is a product of components
# [6, 96, 96, 3] -> [96, (6 * 96), 3]
rearrange(ims, 'b h w c -> h (b w) c').shape
# let's flatten 4d array into 1d, resulting array has as many elements as the original
rearrange(ims, 'b h w c -> (b h w c)').shape
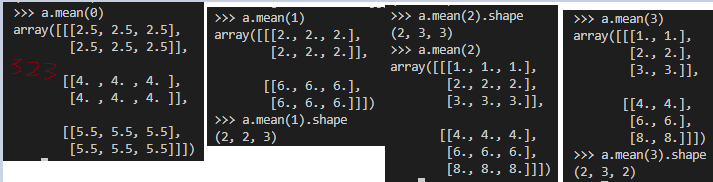
6. numpy 高维数据计算
# a.shape (2,3,2,3)
a = np.array([[[[1, 1, 1], [1, 1, 1]],[[2, 2, 2], [2, 2, 2]], [[3, 3, 3], [3, 3, 3]]],
[[[4, 4, 4], [4, 4, 4]],[[6, 6, 6], [6, 6, 6]], [[8, 8, 8], [8, 8, 8]]]])