前言: 本文是之前19年学生时学习林子雨老师《Spark大数据 》网易公开课的中关于spark的理论部分的部分笔记。主要包括大数据产品与spark的一些概念与运行原理介绍。
目录
大数据产品与hadoop生态系统
Spark概念
MapReduce与spark的比较
Spark运行
Spark运行基本流程
大数据产品与hadoop生态系统
| 大数据计算模式 | 解决问题 | 代表产品 |
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
(19年时的图)
Hadoop不是单一的,是一个生态系统
HDFS:分布式文件系统,分布式批处理
MapReduce : 分布式计算框架
Hive : 数据仓库,相当于编程接口,将写的SQL语句转换为MapReduce的执行程序
Mahout : 数据挖掘库,机器学习函数库
Yarn : 资源管理框架
。。。。
MapReduce 工作流程(此了解即可,hadoop的原生mapReduce 已被弃用)
• MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理

Spark概念
spark也是一个生态系统
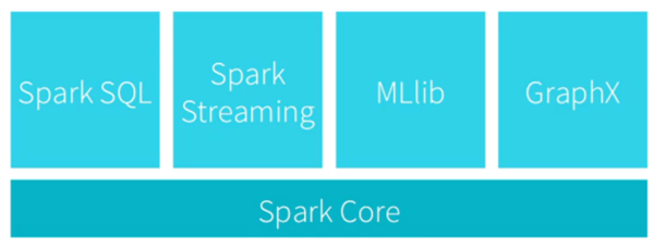
图 MapReduce工作流
Hadoop存在如下一些缺点:
• 表达能力有限
• 磁盘IO开销大
• 延迟高
• 任务之间的衔接涉及IO开销
• 在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
Spark 本质上也是基于MapReduce的计算框架,但是提供了更多数据集的操作。
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题
相比于Hadoop MapReduce,Spark主要具有如下优点:
• Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型(包括groupBy、Filter、join等),编程模型比Hadoop MapReduce更灵活
• Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
Spark 生态系统:通常是HDFS 存储数据,Spark负责数据的计算与处理。
实现SQL查询: Spark SQl
流式计算: Spark Streaming
机器学习: Spark MLlib
图算法组件: Spark 的GraphX
MapReduce与spark的比较
Spark是基于内存的计算,是指计算过程中能够不落磁盘的就尽量不落磁盘,能占内存的就尽量占内存,留在内存中计算。
| MapReduce | Spark |
| 数据存储结构:磁盘HDFS文件系统的split | 使用内存构建弹性分布式数据集RDD 对数据进行运算和cache |
| 编程范式:Map + Reduce | DAG: Transformation + Action |
| 计算中间结果落到磁盘,IO及序列化、反序列化代价大 | 计算中间结果在内存中维护 存取速度比磁盘高几个数量级 |
| Task以进程的方式维护,需要数秒时间才能启动任务 | Task以线程的方式维护 对于小数据集读取能够达到亚秒级的延迟 |
Spark 运行模式: 即可以单机模式又可以集群模式。
• Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
• 因此,Spark所提供的生态系统同时支持批处理、交互式查询和流数据处理
Spark生态系统组件的应用场景
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统中的组件 |
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒、秒级 | Storm、S4 | Spark Streaming |
| 基于历史数据的数据挖掘 | - | Mahout | MLlib |
| 图结构数据的处理 | - | Pregel、Hama | GraphX |
Spark运行

图 Spark运行架构
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
一是利用多线程来执行具体的任务,减少任务的启动开销
二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中

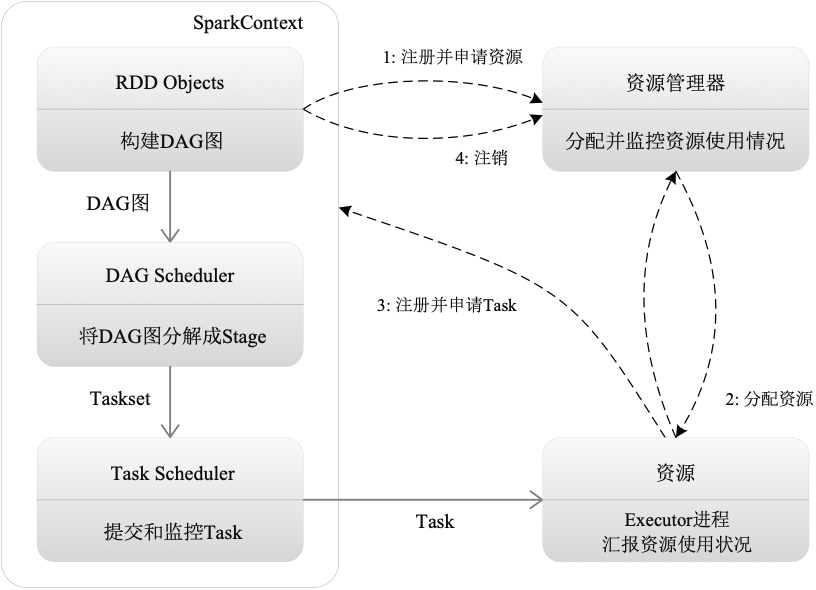
图 Spark运行基本流程图
SparkContext对象代表了和一个集群的连接
Spark运行基本流程
(1)首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控
(2)资源管理器为Executor分配资源,并启动Executor进程
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码
(4)Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
总体而言,Spark运行架构具有以下特点:
(1)每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task
(2)Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
(3)Task采用了数据本地性和推测执行等优化机制








![[OC学习笔记]启动流程](https://img-blog.csdnimg.cn/29d971ee750649b5aa9e8d537e5d7f20.png)