KVM虚拟化技术方案介绍
1.背景介绍
KVM(Kernel-based Virtual Machine)
开源全虚拟化方案
- 支持体系结构
- x86(32位,64位)、IA64、PowerPC、S390
- 依赖x86硬件支持:Intel VT-x/ AMD-V
- 内核模块,使得linux内核成为hypervisor
XEN架构
-
domainU:普通用户虚拟机
-
domain0:特权虚拟机
-
唯一
-
拥有设备驱动,可以直接认识硬件设备
-
拥有后端驱动,可以与众多普通虚拟机交互,实现IO虚拟化
-
最先启动。
-
可以管理其他domainU虚拟机
-
早期是半虚拟化,现在是全虚拟化。性能较差,但是安全性较好。

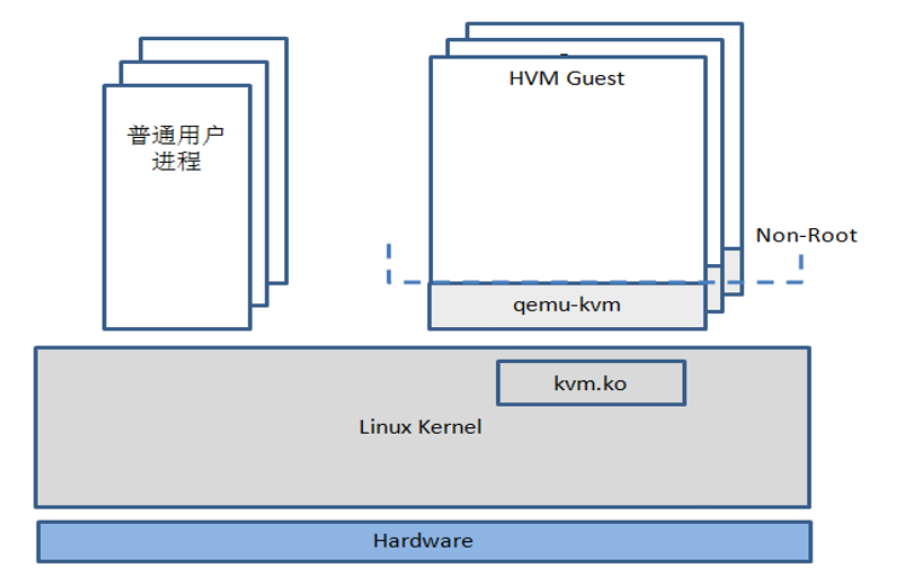
KVM架构:
- KVM:内核中的一个模块,部署在linux kernel中,使得linux kernel变为hypervisor。可以实现CPU虚拟化、内存虚拟化。无法实现IO虚拟化。运行内核态。
- QEMU-KVM:实现IO虚拟化。运行在用户空间中,用户态。
优点:全虚拟化性能较好
QEMU:与KVM、XEN一样,也是属于虚拟化解决方案的一种,也就是说,它能够实现CPU虚拟化、内存虚拟化、IO虚拟化。轻量级,性能较差。单线程。
KVM调用QEMU实现IO虚拟化,反过来,也可以认为是QEMU调用KVM,增强CPU、内存虚拟化的性能。
KVM使用的QEMU不一样的。多线程。QEMU-KVM
2.KVM简介
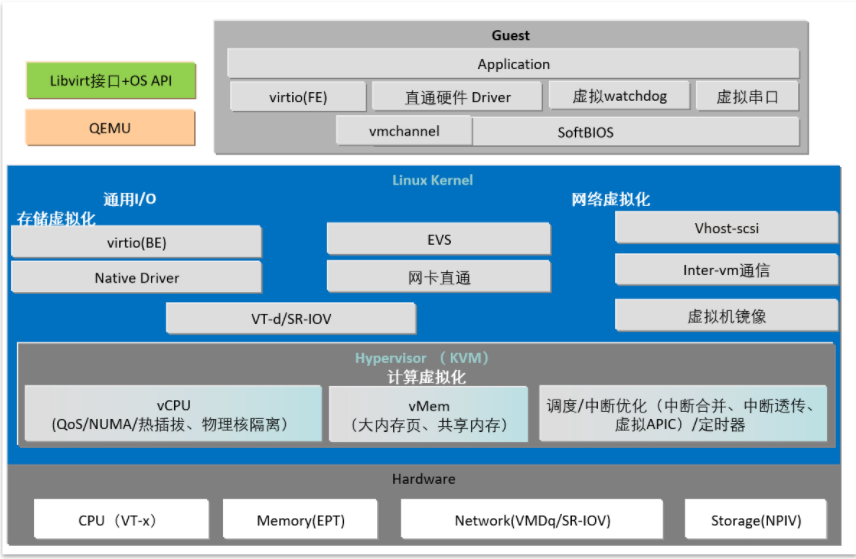
UVP虚拟化架构中KVM架构
FusionCompute,简称FC。有2部分组成:CNA+VRM。
- CNA又由两部分组成:UVP+VNA。UVP实现底层硬件的虚拟化,VNA实现对接VRM。
- VRM是集群级的一个管理平台(具体是以2台虚拟机主备形式部署在2个管理节点上)。
libvirtd
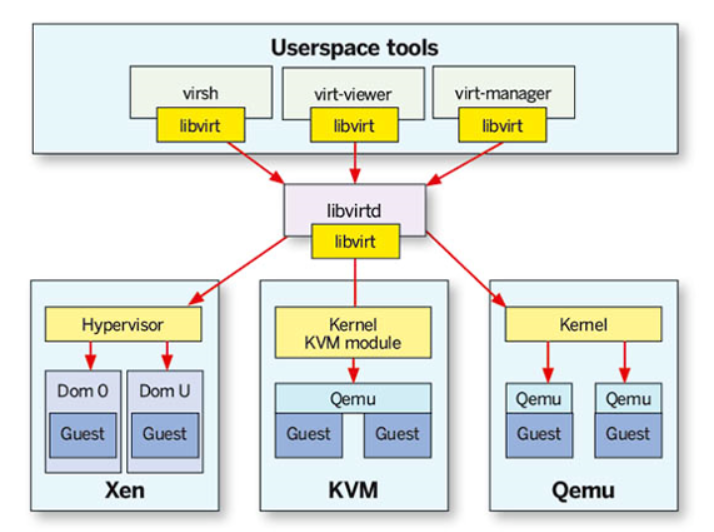
libvirtd:统一的接口。兼容不同的虚拟化方案,统一管理。
- 南向可以接入不同虚拟化产品。
- 北向提供统一接口,通过不同工具(cli\图形化),管理虚拟机。
- 通过xml文件,统一定义虚拟机。
CPU虚拟化
X86架构CPU拥有四种等级的指令:
-
ring0特权指令,给操作系统使用
-
ring1\2给驱动程序使用
-
ring3非特权指令,给应用程序使用
操作系统对CPU的认识与管理达成以下两点认识:
- CPU资源永远就绪
- OS对CPU具有最高权限

引入虚拟化后出现的问题:
- 多个VM之间共享CPU资源
- 部分指令只有hypervisor有权限使用
-
多个VM之间共享CPU资源的问题?
将VM的vCPU调度到CPU的线程上运行,实现物理CPU资源的分时复用。 -
虚拟机指令越级的问题?
传统架构中,操作使用ring0,应用程序使用ring3。
在虚拟化架构当中,VM可看作上面的应用程序,只能使用ring3。但里面实际上有OS,需要使用ring0。所以,指令越级。经典虚拟化:特权解除、陷入模拟。
当虚拟机操作系统需要使用ring0指令,解除特权,由host os的ring1模拟。
缺点:在X86架构中,遇到问题:在非特权指令中,有19条敏感指令。
解决方案
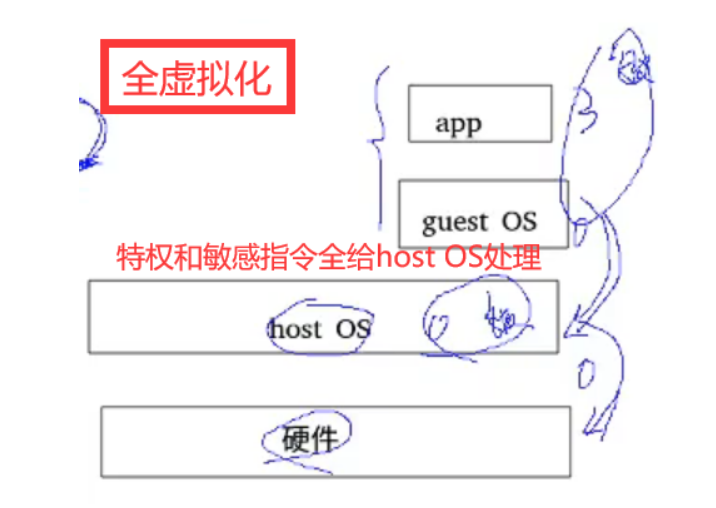
1、操作系统辅助的全虚拟化
修改host OS,接收VM全部指令进行处理。优点:解决敏感指令的问题。
缺点:1、host OS压力较大,2、host 0S需要修改,难度较大。
2、半虚拟化
修改guest os,VM不发出敏感指令。优点: host OS压力较小
缺点:需要修改guest 0S,只有开源可以修改,不能运行闭源操作系统。

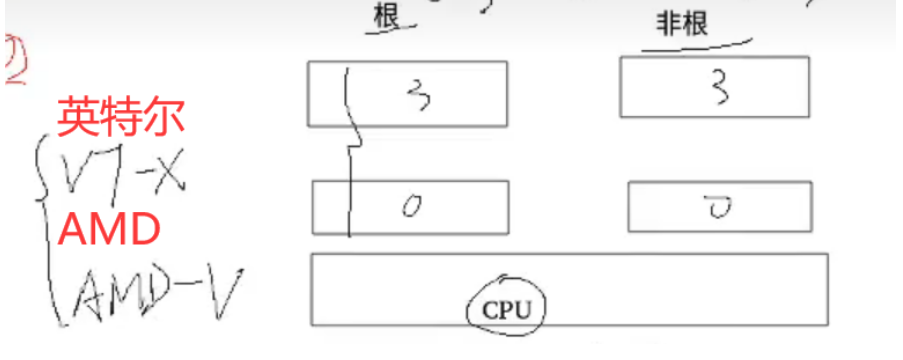
3、硬件辅助的全虚拟化:
在CPU层面,引入根与非根,分别拥有ring0-3,根给host os 使用,非根给Guest os
全虚、半虚
区别:虚拟机操作系统是否修改。如果修改就是半虚,不修改就是全虚
KVM CPU虚拟化
- 非根模式:客户机模式
- 根模式ring0:内核态模式
- 根模式ring3:用户态模式
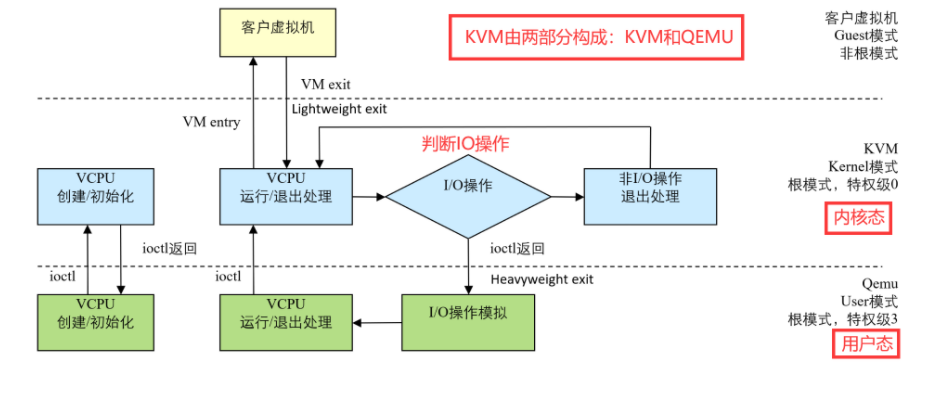
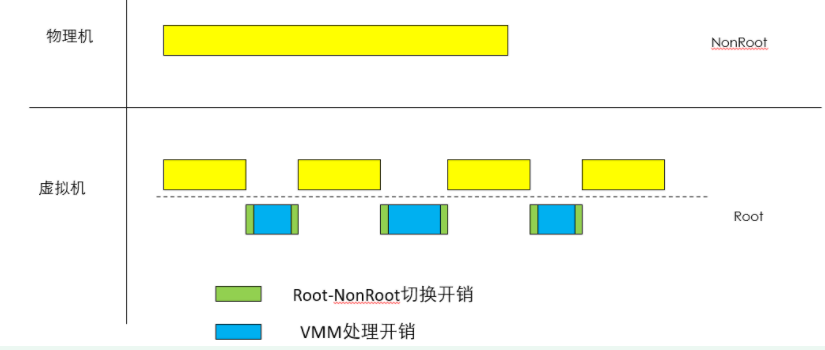
vm entry:由内核态进入客户机模式
vm exit:由客户机模式进入内核态
以上两个切换,会有切换开销。本身VMM运行,也需要消耗性能。所以,虚拟化后的性能损耗,来自切换开销、VMM的性能消耗。
内存虚拟化
操作系统对内存的认识与管理达成以下两点认识:
- 内存都是从物理地址0开始的
- 内存都是连续的
引入虚拟化后出现的问题:
- 从物理地址0开始的:物理地址0只有一个,无法同时满足所有客户机从0开始的要求;
- 地址连续:虽然可以分配连续的物理地址,但是内存使用效率不高,缺乏灵活性。
| GVA: Guest virtual Address | 客户机虚拟地址 | 客户机给应用程序分配地址,可能是真实内存,也可能是硬盘 |
|---|---|---|
| GPA: Guest Physical Address | 客户机物理地址 | 客户机以为真实内存 |
| HVA: Host Virtual Address | 宿主机虚拟地址 | 宿主机给应用程序(VM)分配地址,可能是真实内存,也可能是硬盘 |
| HPA: Host Physical Address | 宿主机物理地址 | 实际上就是服务器真实内存 |
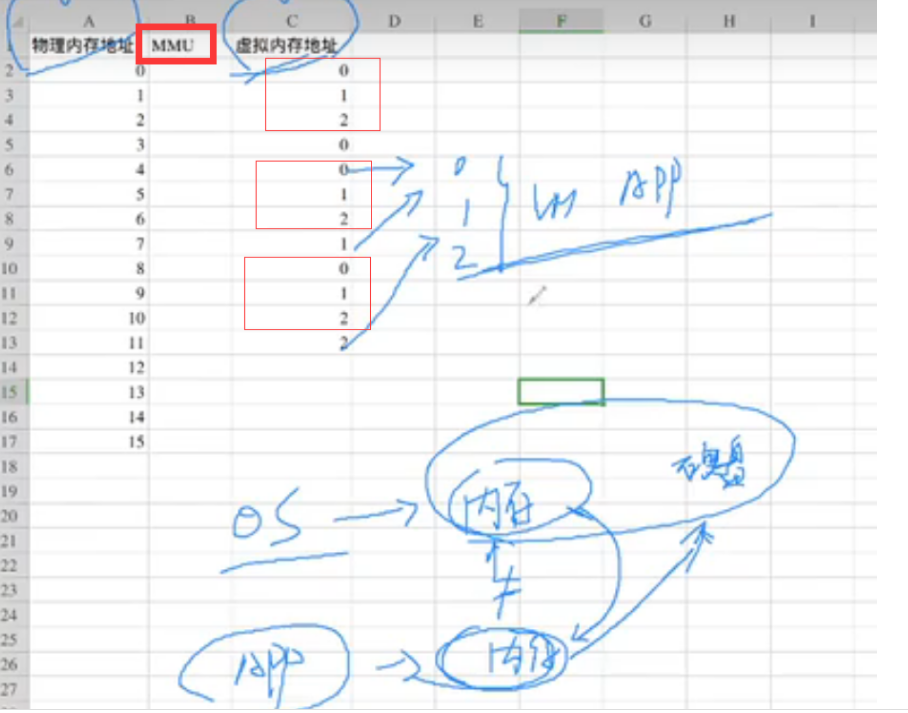
HPA-》 HVA-》GPA-》GVA
HPA-》HVA 本身OS具有MMU,就可以实现
HVA-》GPA MMU虚拟化
GPA-》GVA VM本身OS也具有MMU,也可以实现
MMU虚拟化**(MMU本质是是内存管理模块)**
-
软件 XEN 可以是半虚、全虚
-
直接模式:半虚化,知道自己是处于虚拟化环境当中,可以直接在hypervisor当中实现HVA-》GVA的转化。(宿主机虚拟地址-》客户机虚拟地址)
-
影子列表:全虚化,不知道自己运行··在物理服务器或虚拟化环境中,可以在hypervisor当中实现HVA-》GPA的转化。再由虚拟机本身实现GPA-》GVA的转化。(宿主机虚拟地址-》客户机物理地址-》客户机虚拟地址)
-
-
硬件:由CPU直接实现HVA-》GPA的转化。
- EPT: intel
- NPT: amd
大页内存
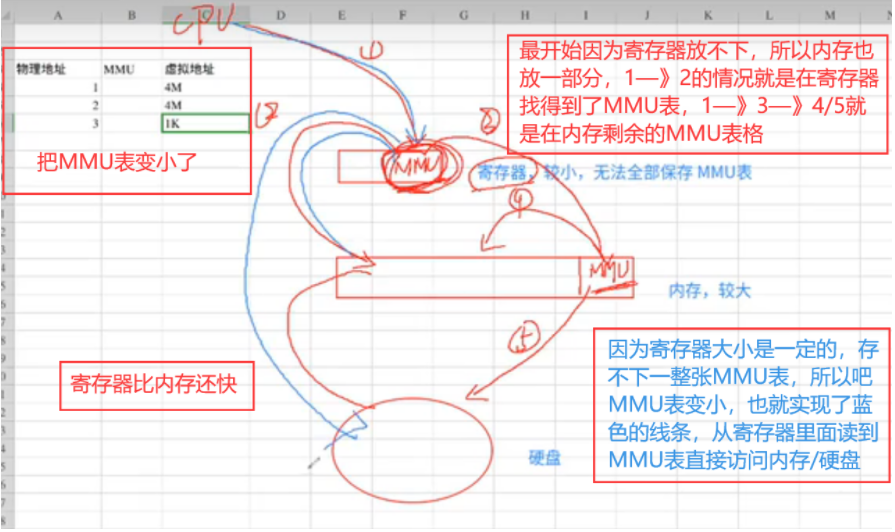
MMU
会拥有内存映射表,记录物理地址—》虚拟地址(包含真实内存、硬盘)
该表,一般存在于内存当中
为了配置大页内存把MMU表存放在CPU寄存器上
配置主机大页内存,优化主机内存访问效率,从而提升性能。大页虚拟机不支持计算资源调度,无法给出正确的调度策略,建议将大页虚拟机部署到独立集群,所在集群无需开启计算资源调度。
I/O虚拟化
软件与软件、硬件的通信:
(需要CPU)——》数据拷进去写入在拷出来
- Port IO 使用专门的IO空间,由CPU拷贝
- MMIO 使用内存空间,由CPU拷贝
(服务器里面专门负责)——》数据拷进去写入在拷出来
- DMA 由DMA控制器拷贝

I/0虚拟化需要解决两个问题
设备发现:
需要控制各虚拟机能够访问的设备访问截获:
- 通过I/0端口或者MMIO对设备的访问
- 设备通过DMA与内存进行数据交换
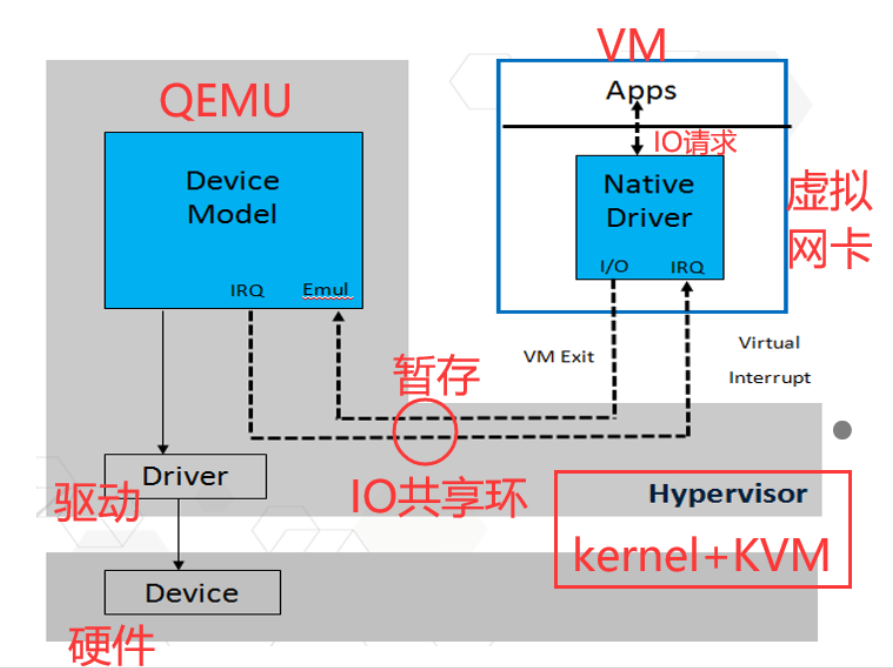
全模拟(完全由软件实现)
原理:
- VM中的APP进行IO,通过VM中驱动发送虚拟设备
- 虚拟设备往外发送
- KVM拦截
- KVM发送IO共享环,告诉QEMU,完成操作
- QEMU从IO共享环中取出
- 通过真实设备驱动,发送设备
优点:兼容很好
缺点:IO路径长,需要上下文切换,开销大。性能差
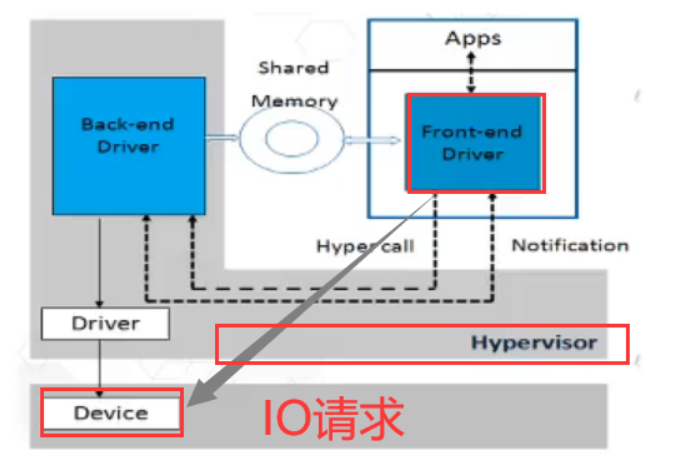
virtio(主流)
原理:
- VM中的APP进行I0,通过前端驱动发送出去
- 发送IO共享环,告诉后端驱动,完成操作
- QEMU从IO共享环中取出
- 通过真实设备驱动,发送设备
优点:相比全模拟,路径较短,性能较好
缺点:某些操作系统不支持,比如windows默认不支持,需要额外的驱动
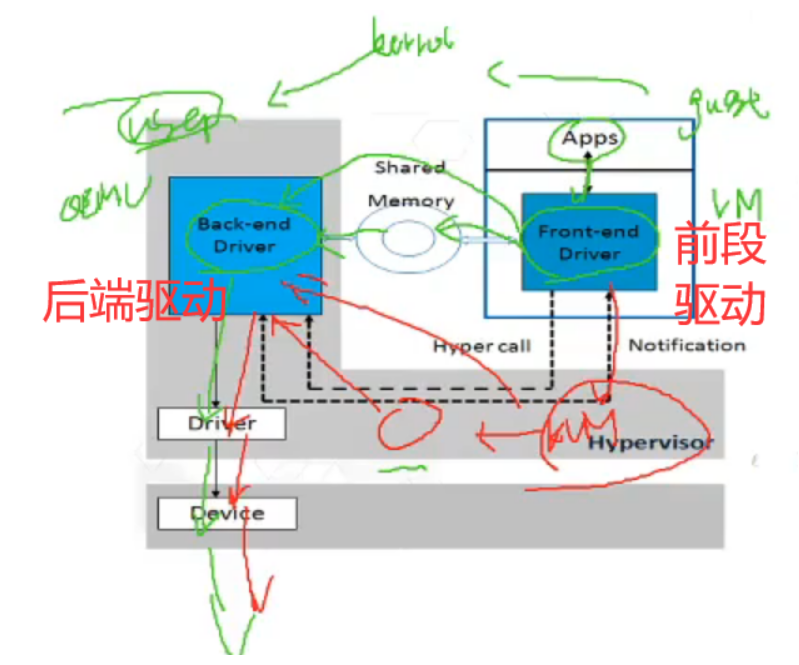
vhost
相比virtio,路径更短,不需要经过qemu,直接由kernel的vhost模块处理。
缺点:兼容性更差。
对比virtio
Virtio
HW=> Host Kernel
Host Kerne=>qemu
Qemu=>guest
Vhost
HW=> Host Kernel(内核)
Host Kernel=> Guest