文章目录
- 背景
- Executor 本身做的一些优化
- LLVM JIT 的优化
- 本地以及全局优化
- 执行 query 时的优化
- JIT调度优化 过程
背景
之前介绍过一次 PostgreSQL JIT with LLVM 实现,因为有一些细节没有介绍得很清楚,需要额外做一些补充。
关于LLVM 的IR 以及 如何 用LLVM 实现 JIT 的基本过程本篇不会做过多细节上的描述,主要关注的是 JIT 为 PG 的 query 到底优化了一些什么?
Executor 本身做的一些优化
创建如下表 以及 插入1000w 行数据
postgres=# create table t2(id integer primary key,c1 integer,c2 integer,c3 integer,c4 integer,c5 integer,c6 integer,c7 integer,c8 integer,c9 integer);
postgres=# insert into t2 (id,c2,c3,c4,c5,c6,c7,c8,c9) values (generate_series(1,10000000),8,7,6,5,4,3,2,1);
之后,我们对其中的某一个attr 执行了一个 sum 聚合操作,会有如下plan:
postgres=# explain analyze select sum(c2) from t2;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=146541.58..146541.59 rows=1 width=8) (actual time=8089.728..8092.541 rows=1 loops=1)
-> Gather (cost=146541.36..146541.57 rows=2 width=8) (actual time=8089.710..8092.528 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=145541.36..145541.37 rows=1 width=8) (actual time=8078.459..8078.464 rows=1 loops=3)
-> Parallel Seq Scan on t2 (cost=0.00..135124.69 rows=4166669 width=4) (actual time=0.027..4053.919 rows=3333333 loops=3)
Planning Time: 0.159 ms
JIT:
Functions: 11
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 2.697 ms, Inlining 0.000 ms, Optimization 0.879 ms, Emission 12.148 ms, Total 15.723 ms
Execution Time: 8094.750 ms
(12 rows)
需要调整默认的jit配置,即 jit_inline_above_cost = 100000, 以及 jit_optimize_above_cost = 100000才行,否则当前的查询cost 没法开启JIT 的 inline和optimize。
可以看到 执行器执行的 plan-tree 形态如下:
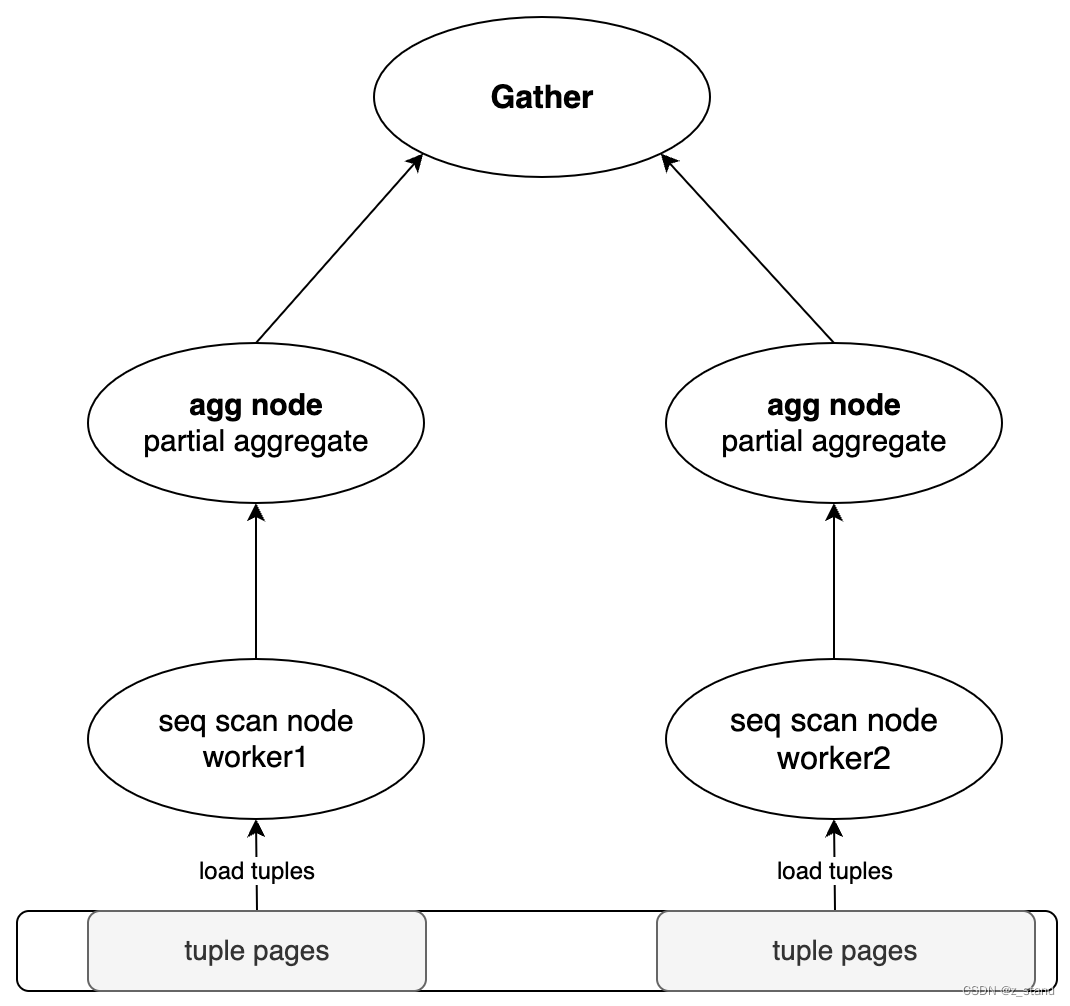
由于 PG 的执行器是火山模型,也就是 pull 形态。是一种自顶向下的执行方式,从最顶层的输出节点开始不断得从下层节点拉取数据。其中的每一个算子都实现了GetNext 函数,用来获取从下层节点返回的一条元组或者标识读取完毕的NULL 指针。通过上层节点循环执行 GetNext函数从而得到最终的结果。
因为我们这个Query 比较简单,所以用到的算子并不是很多:
- 扫描节点(seq scan node),以并发方式执行(会启动两个parallel worker子进程从各自提前初始化好的block 起始位置开始扫描blocks并解析tuple)。扫描节点负责每次拉取一条tuple 输出到 上层的 聚合节点。
- 聚合节点(agg node) 接收到 下层节点传递上来的tuple之后,负责执行用户指定的聚合函数,即sum,实际就是 int4_sum。
- 收集节点(Gather) 通过 GetNext 将 partial 聚合的 agg node的结果做一个最终聚合,返回给用户
通过cost 也能看出来,扫描的过程代价最高(为了加速这样的场景,PG 支持了parallel seq scan),其次就是聚合(对每一个parallel work 进行agg),因为聚合的过程需要执行聚合函数,Gather 作为结果收集,基本没有什么开销。
这也是 Planner 所期望的执行器最终的执行形态,即使是通过JIT执行,整个plantree 也大概就是这个样子了。
上一篇中提到了 JIT 可能的优化 (表达式参数实例化)中描述的一个场景,比如 select sum(c2) from t2; 中sum(c2) 这个表达式的执行底层解析到的 int4_sum 并不是 JIT 优化的,我们开启 jit_dump_bitcode = on 时,能够看到 int4_sum 在执行 optimize之前就已经被 inline到 IR module中了。
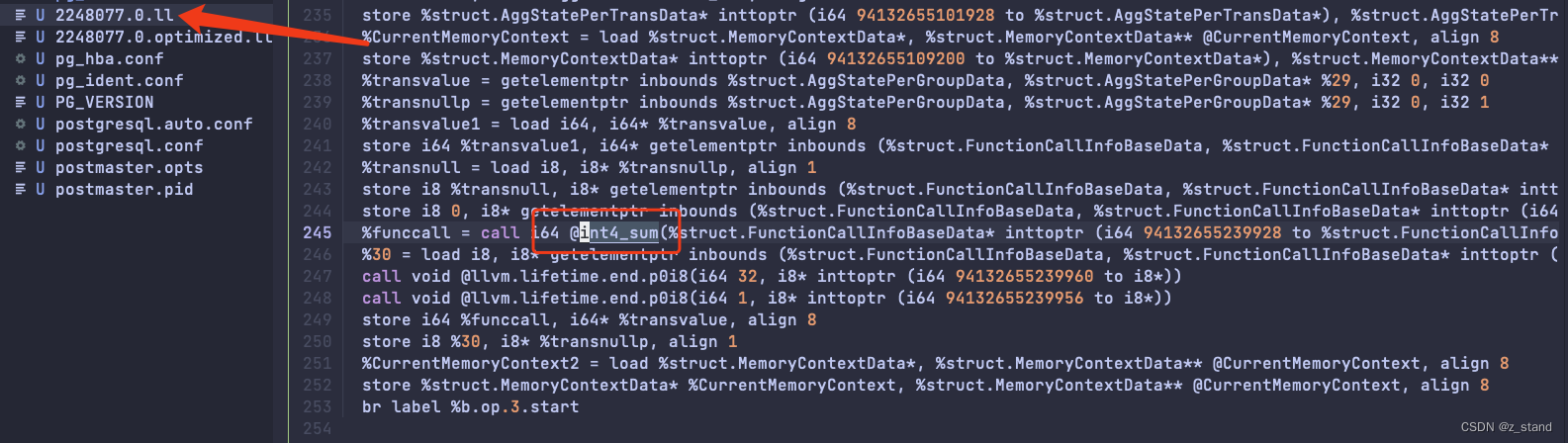
所以这个聚合函数 本身就应该是在 plan生成的时候 执行器就已经知道了 要具体执行哪一个聚合函数,这也是Executor本身所做的一些优化。
那PG 是 如何通过 sum(c2) 来知道最后要执行的是哪一个聚合函数呢?
client --> parser --> rewriter --> planner --> executor --> client
整个sql statement 在执行链路中有一步就是 rewriter,用来将 解析器 解析的parsetree 转为 querytree,这个过程需要有两步操作:
- 将 parsetree 解析为一个query,解析的过程就需要提取 dml/ddl/dcl的关键字 ,识别出query要执行的算子,比如是否有聚合函数、窗口函数、子查询等等。
- 根据 rule system 进行query的重写,大多数rewrite 主要是处理
create view生成的一些rules。
我们的 int4_sum部分的关键解析就是在 rewriter 的第一步完成。
通过如下执行调用链路:
PostgresMain
exec_simple_query
pg_analyze_and_rewrite_fixedparams # rewriter的过程
parse_analyze_fixedparams
transformTopLevelStmt
transformStmt
transformTargetList
transformTargetEntry
transformExpr
transformExprRecurse
transformFuncCall
ParseFuncOrColumn
在函数 ParseFuncOrColumn 中对 聚合函数 sum(c2) 进行解析,通过传入的 c2 进行type解析,得到了其在 pg_type catalog 中的 oid – 23,即 int4。
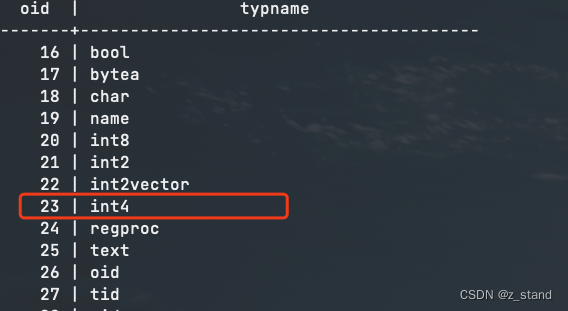
因为知道函数名称是 sum,且参数类型是23,所以就通过函数ParseFuncOrColumn --> func_get_detail --> FuncnameGetCandidates 在 pg_proc(数据会被保存在syscache) 中筛选所有 oid name包含int4 对应的全局func,得到了一个func列表。
可能就像这个表达式执行的结果一样:
postgres=# select oid,proname from pg_proc where proname like 'int4%';
oid | proname
------+---------------------
42 | int4in
43 | int4out
65 | int4eq
66 | int4lt
77 | int4
141 | int4mul
144 | int4ne
147 | int4gt
149 | int4le
150 | int4ge
154 | int4div
...
然后 func_get_detail剩余的逻辑就是从 这个列表中筛选包含 sum的函数,从而拿到了这个函数的oid,并填充给 funcid,并识别出来这个函数类型是属于 FUNCDETAIL_AGGREGATE。所以在 ParseFuncOrColumn函数中剩余的部分会拿着 funcid 也就是函数的oid 从pg_aggregate 系统表中找到这个函数对应的tuple,将这个函数相关的信息填充到 pstate中。同时这个 函数的 oid也会传递到 ExecInitAgg,从而能够提取到聚合函数的具体信息。
在最后 ExecAgg --> agg_retrieve_direct 执行 agg 算子时 能够通过 int4_sum 对 从下层拿到的 tuple 进行聚合操作。
到这里 算是对上一篇文章中错误部分修正了。
LLVM JIT 的优化
回到我们想要继续描述的JIT 本身的优化,PG JIT的链路调度在上一篇中描述的比较清晰了。简单提一下,核心部分就是 llvm_compile_expr 以及 ExecRunCompiledExpr 两个函数的调度,分别是在执行器初始化plane 以及 最后执行表达式时调用的。
llvm_compile_expr的主要目标是根据执行器调度的算子类型构造对应算子的 内存IR 表示(说白了就是将这个算子的调度逻辑翻译为IR)ExecRunCompiledExpr会做 inline 和 optimize 两个核心的 llvm操作。 inline 的过程就是将上一步中翻译成功的算子执行过程中所依赖的其他的 函数添加到当前module,涉及到查 bc 文件,加载其中的function到当前module。optimize 则是 IR通过 Pass来做的核心优化。
我们重点关注 optimize过程 对前面提到的query select sum(c2) from t2; 做了哪一些优化。
本身 IR Pass阶段能做的优化分为两类:本地优化 和 全局优化。 在JIT的实现过程中
- 本地优化 针对的是 function 以及 basicblock 部分。可以做删除公共子表达式 、拷贝传播 以及 删除死代码 等优化工作,当然他们也可以在全局优化中做,只是面对的对象是 module。
- 全局优化中 出了本地优化能做的之外,还能做代码移动 以及 部分冗余代码的删除(甚至能够把一整个基本块都删除)。
本地以及全局优化
对于本地优化的表现,一个很清晰简单的例子:
如下代码 func.c
int func(int a, int b)
{
int x = a + b;
int y = x;
int z = 2 * y;
return z;
}
int func2()
{
return func(1,2);
}
通过clang编译两个版本:
clang -emit-llvm -S another.c -o func.ll不带优化的版本clang -emit-llvm -S -O2 another.c -o func-O2.ll带优化的版本
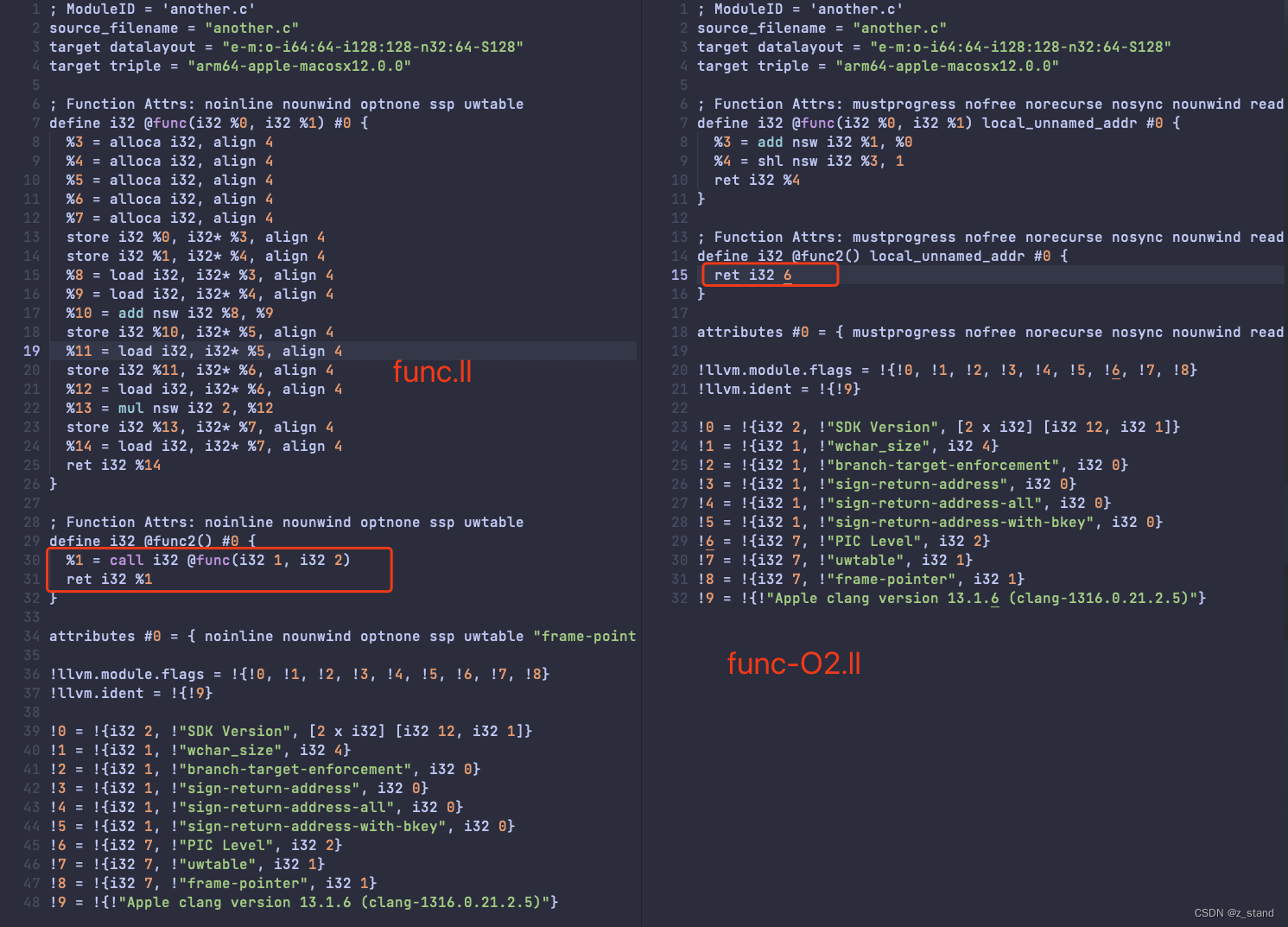
很清晰得看到优化后对 func.c 中函数调用的优化,func2执行直接就能返回一个常数,而不需要继续调用 func ,而且func 本身的优化也将 对memory(包含alloca 指令 且 以%开头的变量都是会存储到内存)的访问转为了对寄存器的访问(mem2reg) 且 做了拷贝传播,减少了中间变量的访问。
以上的整个过程都可以放在JIT inline之后的执行器执行过程,因为执行期间就能够动态得知道一些函数的输入值,从而进一步优化函数的执行效率。
全局优化则更为复杂,因为function 比较多 导致 基本块比较多,整个优化过程需要依赖 SSA(Single Static Assignment) 构造 CFG(Control Flow Graph),并依据 CFG 进行数据流分析,从而决定应该采用哪种优化(整个过程主要通过 半格理论 来对每一个CFG 中的图节点对应的 BB 做集合交并操作),在 LLVM 中的实现过程还是非常复杂的。
执行 query 时的优化
直接看我们 select sum(c2) from t2; query 执行过程中生成的 bc 文件,当我们开启bitcode dump之后 set jit_dump_bitcode = on ;就能在data目录下看到 几个 进程id 名 相关的 bc文件,包含optimize的则是optimize之后的。通过 llvm-dis 对 optimize 对应的.bc文件 转为可读的 ll文件之后能看到:
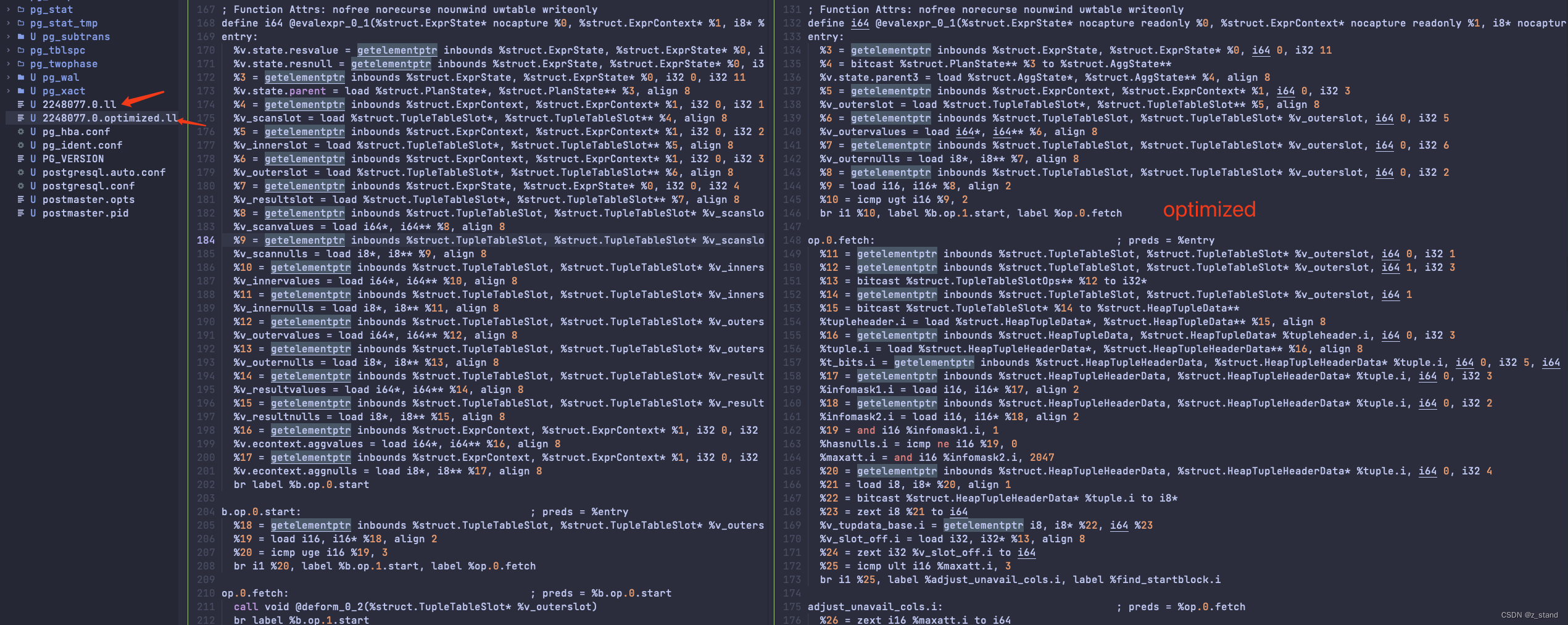
细节过多且不太容易看懂,总结下来就是
- 将元组变形
deform相关的函数 以及int4_sum都作为了evalexpr_0_1中的basicblock,达成了全局优化的代码移动。而在原本的 非optimize的ll 稳重 这两者都会被作为单独的func去在evalexpr_0_1调用执行。
这个过程能够减少很多 instruction的执行,优化后的 evalexpr_0_1 执行的 instruction 只有 287,优化前执行的instruction 则有 396个。 - 对 memory 的访问都转化为 对寄存器的访问 – mem2reg,所有需要分配内存的指令 alloca 都会被移除。
因为 我们执行 select sum(c2) from t2; 这个query过程涉及到多个算子,其实每一个算子的执行 都会对应一组dump出来的 bitcode 文件。
而且优化之后的逻辑很难和实际的代码对应起来,是根据实际的输入参数来做动态调整的,单纯从instruction的数量上能够看到减少了很多。
JIT调度优化 过程
JIT 做optimize的过程通过 llvm_optimize_module 完成,主要做的事情有三个:
- 先 添加 mem2reg 优化到 function pass manager,后续 按照 function粒度将所有的对内存的访问转为寄存器访问。
- 遍历当前module 的所有function,每一个function都执行一趟 function级别的优化。 – 本地优化
- 构造module pass manager,对整个module做 一趟优化。 – 全局优化
其中代码涉及到的一些 PGJIT_OPT3 优化选项都是我们可以控制的,比如 当前plan的total_cost top_plan->total_cost > jit_optimize_above_cost 配置,都会开启 PGJIT_OPT3优化,所以我们可以调整 jit_optimize_above_cost 来控制是否调度jit优化。
实际 LLVM 通过 LLVMRunFunctionPassManager 以及 LLVMRunPassManager 实现时都会先对输入的 function/module 做analyze,构造一些有利于优化过程使用的信息,比如CFG等等。
实际优化时类型还是非常多的,细节实在是复杂,需要有一些理论基础才能深入分析LLVM 代码。
总的来说 query使用的一些 postgres本身支持的一些全局function,则都会在rewriter 过程完成function的解析 并填充到plan相关的数据结构中,执行的时候能够直接使用。对于 PG 内核执行链路上的一些优化,在JIT的过程都会由 llvm_optimize_module 通过 Pass 来达成。