java线程池详解
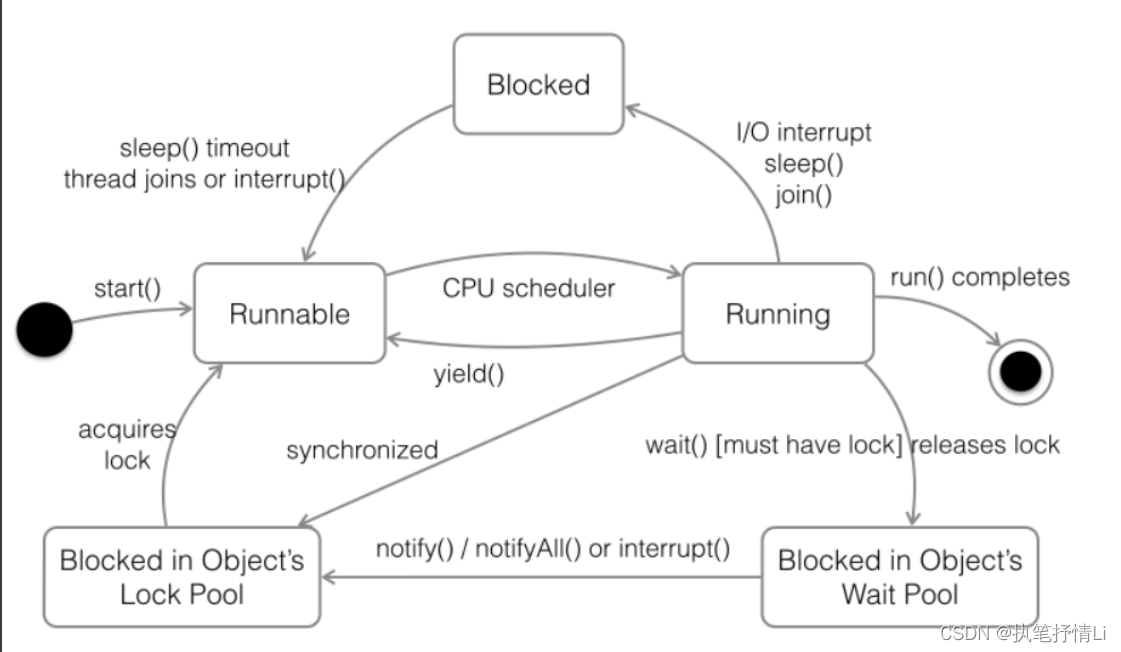
- 线程的基本状态
- Executor框架
- Executor框架组成部分
- Executor框架使用示意图
- Runnable接口、Callable接口
- Executors
- Future接口和实现Future接口的FutureTask类
- Future和FutureTask的关系
- ThreadPoolExecutor类
- ThreadPoolExecutor 饱和策略(拒绝策略)
线程的基本状态
为什么要使用线程池:
- 提高响应速度(减少了创建线程的时间)
- 降低资源消耗(重复利用线程池中的线程,不需要每次创建)
- 便于线程管理
Executor框架
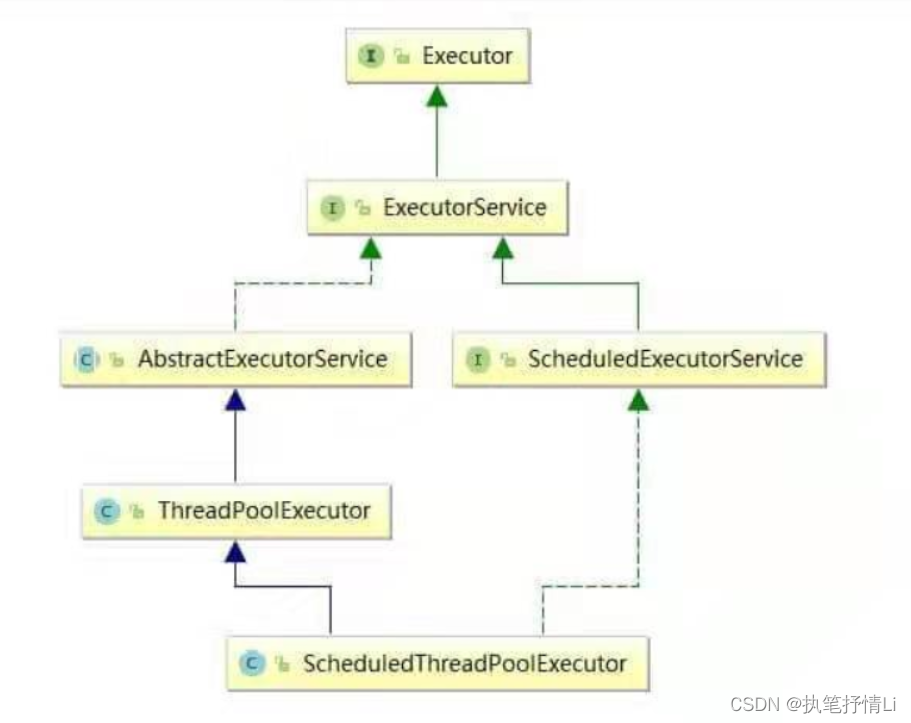
Executor框架组成部分
Executor框架主要由3大部分组成如下。
- 任务。包括被执行任务需要实现的接口:Runnable接口或Callable接口。
- 任务的执行。包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口。Executor框架有两个关键类实现了ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor)。
- 异步计算的结果。包括接口Future和实现Future接口的FutureTask类。
Executor框架使用示意图
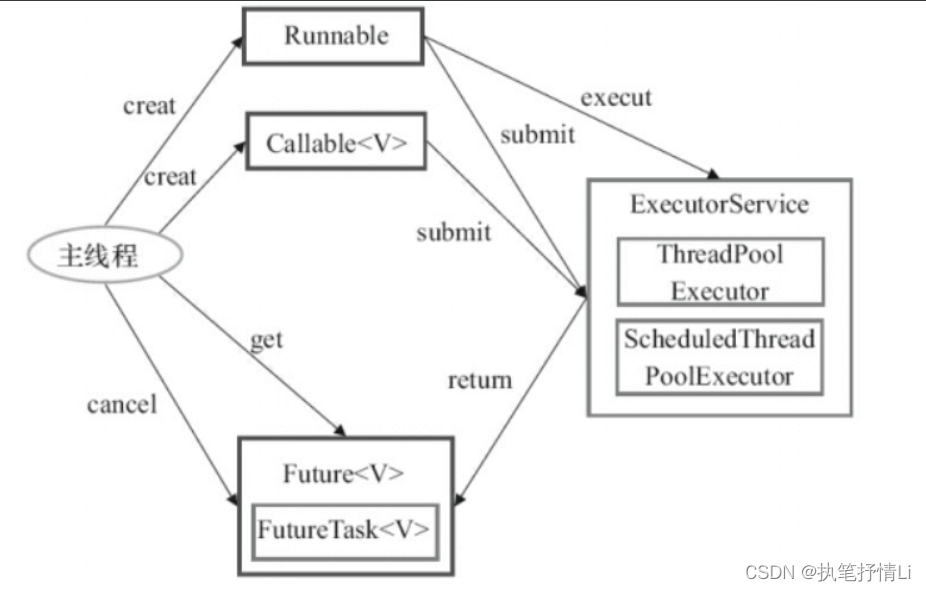
- 主线程首先要创建实现Runnable或者Callable接口的任务对象。工具类Executors可以把一个Runnable对象封装为一个Callable对象(Executors.callable(Runnable task)或Executors.callable(Runnable task,Object resule))。
- 然后可以把Runnable对象直接交给ExecutorService执行(ExecutorService.execute(Runnable command));或者也可以把Runnable对象或Callable对象提交给ExecutorService执行(Executor-Service.submit(Runnable task)或ExecutorService.submit(Callabletask))。
- 如果执行ExecutorService.submit(…),ExecutorService将返回一个实现Future接口的对象(到目前为止的JDK中,返回的是FutureTask对象)。由于FutureTask实现了Runnable,程序员也可以创建FutureTask,然后直接交给ExecutorService执行。
- 最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
Runnable接口、Callable接口
runnable和callable区别
- 与runnable接口相比,callable更加强大,相比run()方法,可以有返回值,使用get()方法获取返回值
- 方法可以抛出异常
- 支持泛型的返回值
- 需要借助FutureTask类,比如获取返回结果
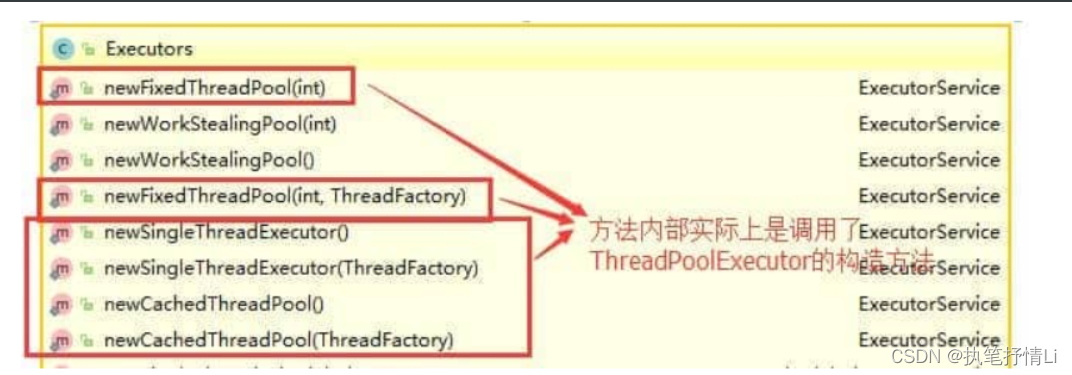
Executors
Executors类,提供了一系列工厂方法用于创建线程池,返回的线程池都实现了ExecutorService接口。

Future接口和实现Future接口的FutureTask类
Future和FutureTask的关系
-
Future 是一个接口,无法直接创建对象,需配合线程池使用.submit()方法返回值Future来保存执行结果;而使用.execute()方法传入Runnable接口无返回值
-
FutureTask 是一个类,可以直接创建对象,其实现了RunnableFuture接口(继承Future接口)
-
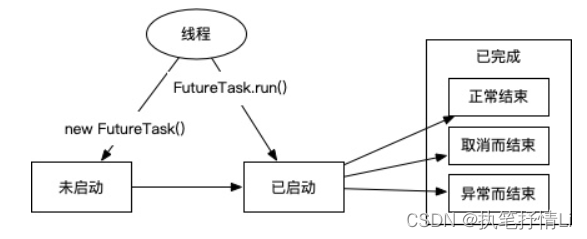
FutureTask除了实现Future接口外,还实现了Runnable接口。因此,FutureTask可以交给Executor执行,也可以由调用线程直接执行(FutureTask.run())。根据FutureTask.run()方法被执行的时机,FutureTask可以处于下面3种状态。
-
ThreadPoolExecutor类
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor 饱和策略(拒绝策略)
ThreadPoolTaskExecutor 定义一些策略:
ThreadPoolExecutor.AbortPolicy :抛出RejectedExecutionException来拒绝新任务的处理。
ThreadPoolExecutor.CallerRunsPolicy :调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
ThreadPoolExecutor.DiscardPolicy :不处理新任务,直接丢弃掉。
ThreadPoolExecutor.DiscardOldestPolicy : 此策略将丢弃最早的未处理的任务请求。