章节目录:
- 一、线性查找
- 1.1 概述
- 1.2 代码示例
- 二、二分查找
- 2.1 概述
- 2.2 代码示例
- 三、插值查找
- 3.1 概述
- 3.2 代码示例
- 四、斐波那契查找
- 4.1 概述
- 4.2 代码示例
- 五、结束语
一、线性查找
1.1 概述
- 线性查找又称顺序查找,是一种最简单的查找方法,它的基本思想是从第一个记录开始,逐个比较记录的关键字,直到和给定的K值相等,则查找成功;若比较结果与文件中n个记录的关键字都不等,则查找失败。
- 该算法的优点是简单,缺点是效率较低。
1.2 代码示例
public class SeqSearch {
public static void main(String[] args) {
int[] array = {1, 2, 3, 5, 6, 7};
int index = seqSearch(array, 2);
System.out.println("index=" + index);
// index=1
}
public static int seqSearch(int[] array, int val) {
for (int i = 0; i < array.length; i++) {
// 找到值则返回索引。
if (val == array[i]) {
return i;
}
}
return -1;
}
}
二、二分查找
2.1 概述
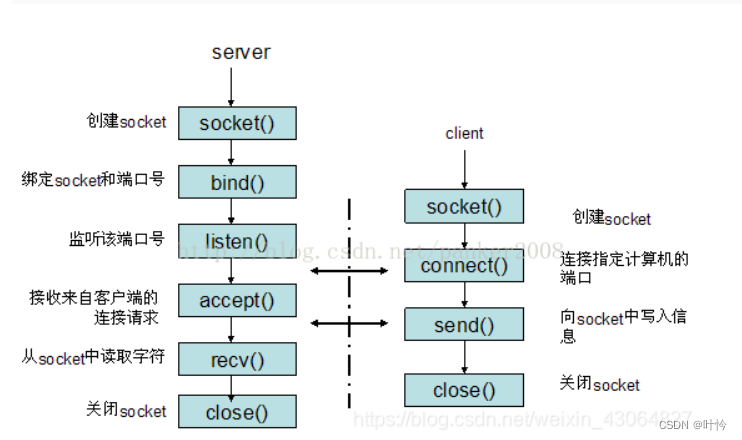
- 二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
- 示意图(与顺序查找的对比):

2.2 代码示例
public class BinarySearch {
public static void main(String[] args) {
int[] array = {1, 8, 10, 89, 1000, 1000, 1234};
List<Integer> indexs = binarySearch(array, 0, array.length - 1, 1000);
System.out.println("indexs=" + indexs);
// indexs=[4, 5]
}
/**
* 二分查找。
*
* @param array 数组
* @param left 左端索引
* @param right 右端索引
* @param findVal 查找的值
* @return {@link List}<{@link Integer}>
*/
public static List<Integer> binarySearch(int[] array, int left, int right, int findVal) {
// 整个递归查找阶段结束都没有找到值。
if (left > right) {
return Collections.emptyList();
}
// 1.找到中间值。
int midIndex = (left + right) / 2;
int midVal = array[midIndex];
// 2.如果查找的值小于中间值则向左递归,否则向右进行递归查找。
if (findVal < midVal) {
return binarySearch(array, left, midIndex - 1, findVal);
} else if (findVal > midVal) {
return binarySearch(array, midIndex + 1, right, findVal);
} else {
// 3.若查找的值等于中间值,再继续看有没有相同值。
List<Integer> indexs = new ArrayList<>();
// 继续向左扫描。
int pointer = midIndex - 1;
while (pointer > 0 && array[pointer] == findVal) {
indexs.add(pointer);
// 左移。
pointer--;
}
// 存入当前中间值。
indexs.add(midIndex);
// 继续向右扫描。
pointer = midIndex + 1;
while (pointer < (array.length - 1) && array[pointer] == findVal) {
indexs.add(pointer);
// 右移。
pointer++;
}
return indexs;
}
}
}
三、插值查找
3.1 概述
- 插值查找,有序表的一种查找方式,插值查找是根据查找关键字与查找表中最大最小记录关键字比较后的查找方法。
- 插值查找基于二分查找,将查找点的选择改进为自适应选择,提高查找效率。
- 公式优化:
low+high 1
mid = ———————— = low + —(high-low)
2 2
optimize
⇩
findVal-array[low]
mid = low + —————————————————————— (high-low)
array[high]-array[low]
- 注意事项:对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找, 速度较快。而关键字分布不均匀的情况下,该方法不一定比折半查找要好。
3.2 代码示例
public class InsertValueSearch {
private static int counter = 0;
public static void main(String[] args) {
int[] array = {1, 8, 10, 89, 1000, 1000, 1234};
int index = insertValueSearch(array, 0, array.length - 1, 1234);
System.out.println("search count=" + counter + ",index=" + index);
// search count=1,index=6
}
public static int insertValueSearch(int[] array, int left, int right, int findVal) {
counter++;
// < array[0] || > array[array.length - 1] 是为了防止中间索引越界。
if (left > right || findVal < array[0] || findVal > array[array.length - 1]) {
return -1;
}
// 1.与二分查找不同,这里通过公式自适应计算出中间值。
int midIndex = left + (right - left) * (findVal - array[left]) / (array[right] - array[left]);
int midVal = array[midIndex];
// 2.向左向右递归查找。
if (findVal < midVal) {
return insertValueSearch(array, left, midIndex - 1, findVal);
} else if (findVal > midVal) {
return insertValueSearch(array, midIndex + 1, right, findVal);
} else {
return midIndex;
}
}
}
四、斐波那契查找
4.1 概述
黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。取其前三位数字的近似值是 0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比。这是一个神奇的数字,会带来意向不大的效果。
- 斐波那契搜索(Fibonacci search) ,又称斐波那契查找,是区间中单峰函数的搜索技术。
- 斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid 不再是中间或插值得到,而是位于黄金分割点附近,即
mid=low+F(k-1)-1(F 代表斐波那契数列)。 - 斐波那契搜索就是在二分查找的基础上根据斐波那契数列进行分割的。在斐波那契数列找一个等于略大于查找表中元素个数的数
F[n],将原查找表扩展为长度为F[n](如果要补充元素,则补充重复最后一个元素,直到满足F[n]个元素),完成后进行斐波那契分割,即F[n]个元素分割为前半部分F[n-1]个元素,后半部分F[n-2]个元素,找出要查找的元素在那一部分并递归,直到找到。 - 斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89… (这个数列从第3项开始,每一项都等于前两项之和。)
- 示意图:

- 由斐波那契数列
F[k]=F[k-1]+F[k-2]的性质,可以得到(F[k]-1) = (F[k-1]-1) + (F[k-2]-1) +1。该式说明:只要顺序表的长度为F[k]-1,则可以将该表分成长度为F[k-1]-1和F[k-2]-1的两段,即如上图所示。从而中间位置为mid=low+F(k-1)-1; - 类似的,每一子段也可以用相同的方式分割;
- 但顺序表长度 n 不一定刚好等于
F[k]-1,所以需要将原来的顺序表长度 n 增加至F[k]-1。这里的 k 值只要能使得F[k]-1恰好大于或等于 n 即可,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),都赋为 n 位置的值即可。
4.2 代码示例
public class FibonacciSearch {
public static void main(String[] args) {
int[] arr = {1, 8, 10, 89, 1000, 1234};
System.out.println("index=" + fibSearch(arr, 1));
// index=0
}
private static int[] getFib(int size) {
if (3 > size) {
throw new IllegalArgumentException("size it has to be greater than or equal to 3.");
}
int[] fib = new int[size];
// 前两个数固定为1。
fib[0] = 1;
fib[1] = 1;
// 从第三个数开始赋值。
for (int i = 2; i < fib.length; i++) {
// 当前值等于前两个数的和。
fib[i] = fib[i - 1] + fib[i - 2];
}
return fib;
}
public static int fibSearch(int[] array, int findVal) {
int low = 0;
int high = array.length - 1;
int[] fib = getFib(20);
// 记录斐波那契分隔数值的下标。
int k = 0;
// 用于记录中间索引。
int midIndex = 0;
// 1.找到斐波那契数值的下标。
while (high > fib[k] - 1) {
k++;
}
// 2.拷贝完整长度的数组,当值的数量不够长度时默认填充为0进行占位。
int[] temp = Arrays.copyOf(array, fib[k]);
// 3.填充temp数组中为0数值。
// 假设当前temp={1,8,10,89,1000,1234, 0,0} => 填充后得到:{1,8,10,89,1000,1234, 1234,1234}
for (int i = high + 1; i < temp.length; i++) {
temp[i] = array[high];
}
// 4.开始查找。
while (low <= high) {
midIndex = low + fib[k - 1] - 1;
// 左移。
if (findVal < temp[midIndex]) {
high = midIndex - 1;
k--;
// 右移。
} else if (findVal > temp[midIndex]) {
low = midIndex + 1;
k -= 2;
} else {
// 返回下标。
return (midIndex <= high) ? midIndex : high;
}
}
return -1;
}
}
五、结束语
“-------怕什么真理无穷,进一寸有一寸的欢喜。”
微信公众号搜索:饺子泡牛奶。