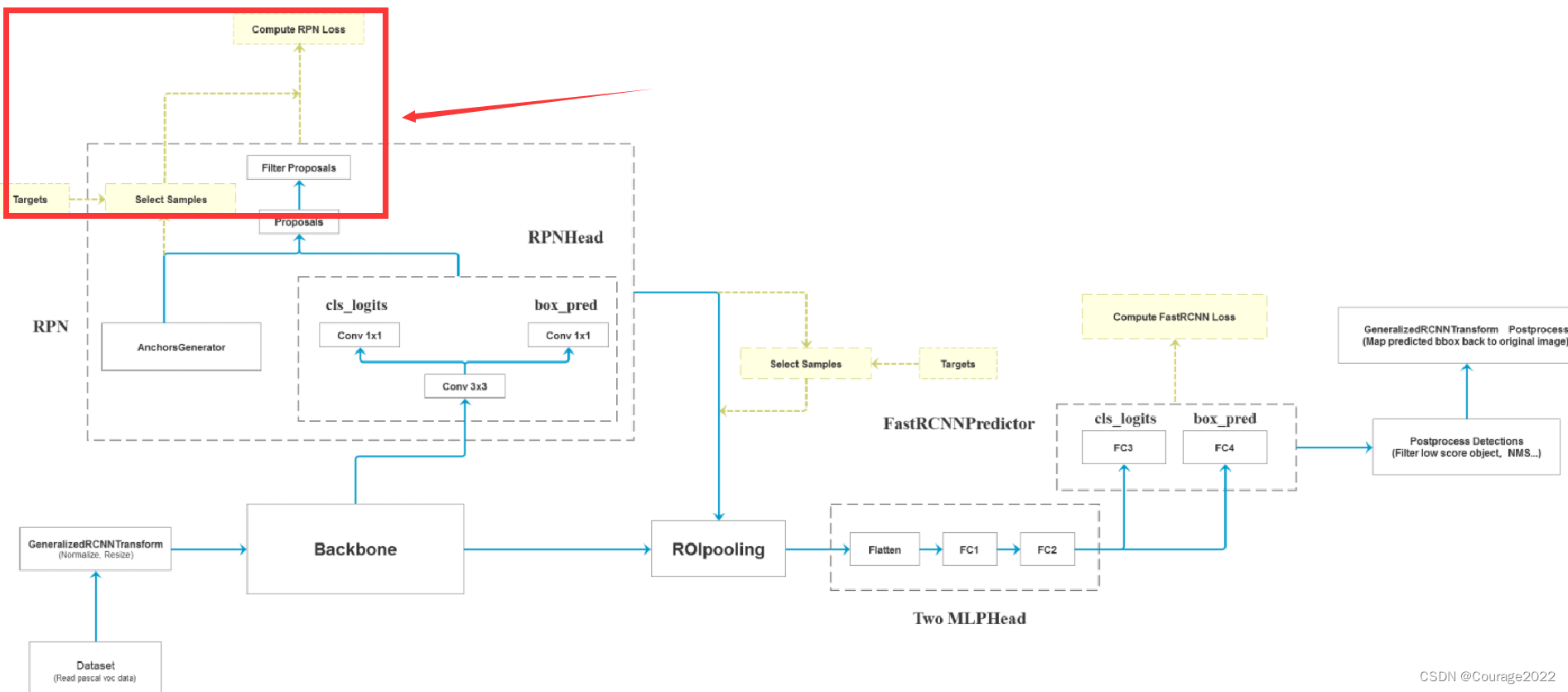
#features是预测特征层的特征矩阵
def forward(self,
images, # type: ImageList
features, # type: Dict[str, Tensor]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
# type: (...) -> Tuple[List[Tensor], Dict[str, Tensor]]
"""
Arguments:
images (ImageList): images for which we want to compute the predictions
features (Dict[Tensor]): features computed from the images that are
used for computing the predictions. Each tensor in the list
correspond to different feature levels
targets (List[Dict[Tensor]): ground-truth boxes present in the image (optional).
If provided, each element in the dict should contain a field `boxes`,
with the locations of the ground-truth boxes.
Returns:
boxes (List[Tensor]): the predicted boxes from the RPN, one Tensor per
image.
losses (Dict[Tensor]): the losses for the model during training. During
testing, it is an empty dict.
"""
# RPN uses all feature maps that are available
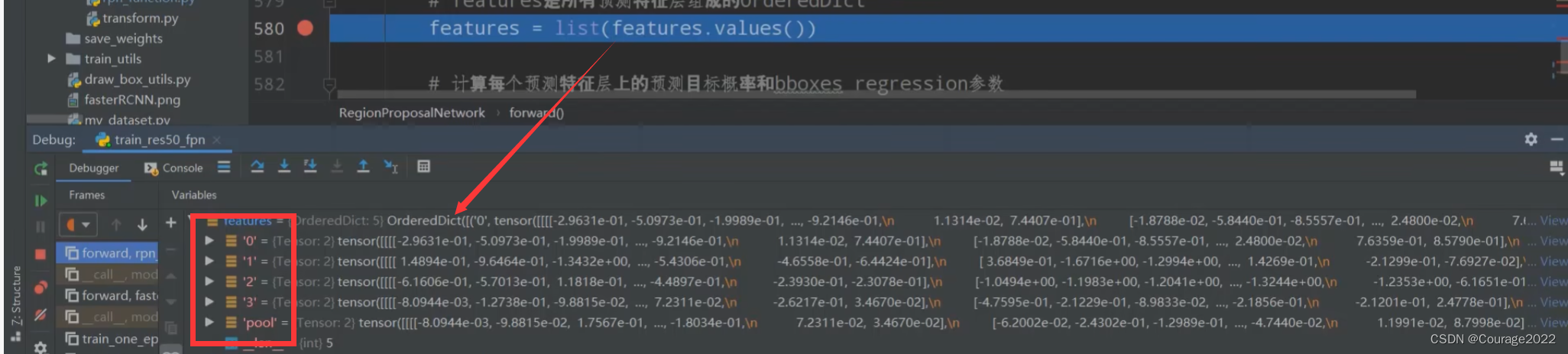
# features是所有预测特征层组成的OrderedDict
#提取预测特征层的特征矩阵 ,是个字典类型,我们将key抽出去只留val
features = list(features.values())
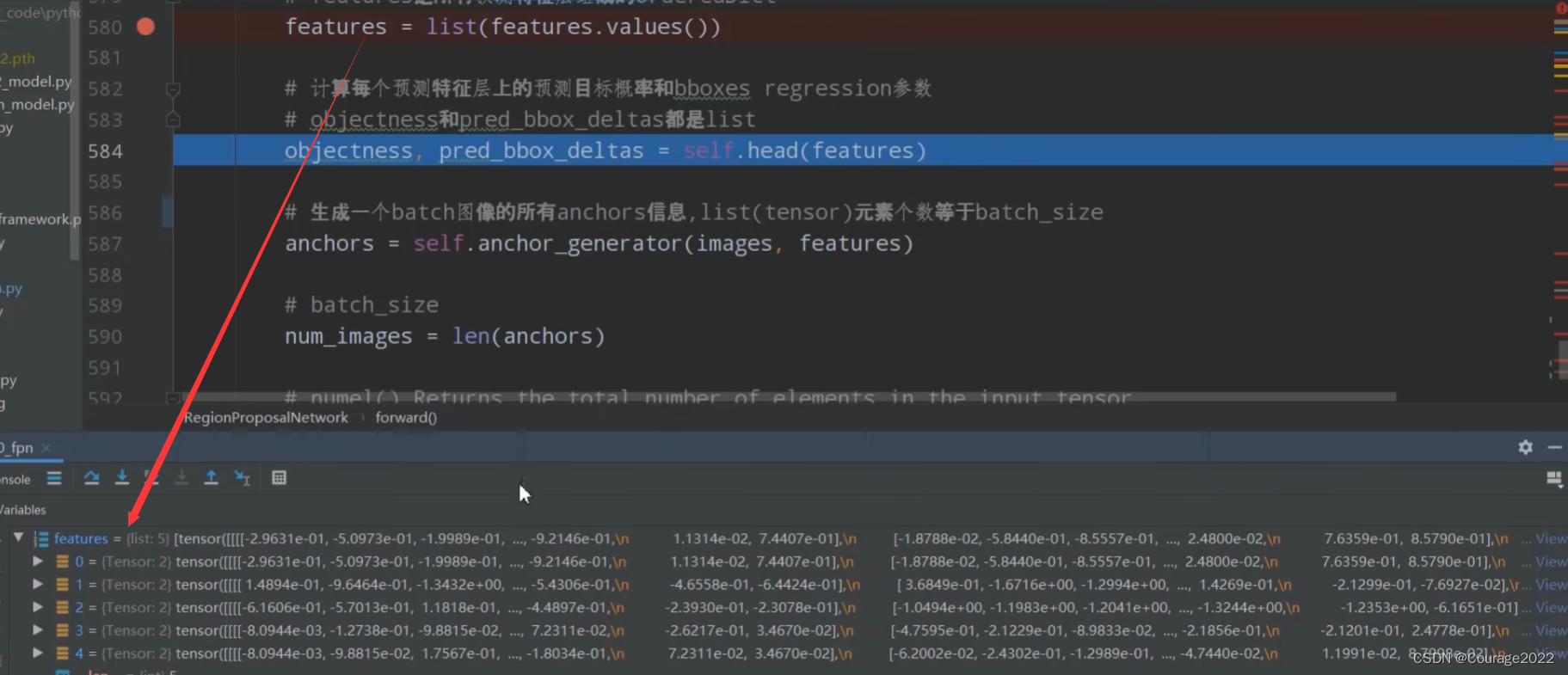
# 计算每个预测特征层上的预测目标概率和bboxes regression参数
# objectness和pred_bbox_deltas都是list
#均以预测特征层进行划分 shape 8(batch) 15(每个预测特征层有多少个anchor 5scanle 3 ratio) 34(高) 42(宽度)
#shape 8 60(在每个cell中参数个数 每个anchor需要四个参数 15*4) 34 42
objectness, pred_bbox_deltas = self.head(features)
# 生成一个batch图像的所有anchors信息,list(tensor)元素个数等于batch_size
#是一个列表,有8个,每一个对应的就是图片的anchor信息 21420*4
anchors = self.anchor_generator(images, features)
# batch_size = 8
num_images = len(anchors)
# numel() Returns the total number of elements in the input tensor.
# 计算每个预测特征层上的对应的anchors数量
# o[0].shape 15 34 42 相乘得到每个预测特征层上anchor的个数
num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness]
num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]
# 调整内部tensor格式以及shape
# #8 21420 1 8 21420 4
objectness, pred_bbox_deltas = concat_box_prediction_layers(objectness,
pred_bbox_deltas)
#objectness 171360 1
#pred_bbox_deltas 171360 4
# apply pred_bbox_deltas to anchors to obtain the decoded proposals
# note that we detach the deltas because Faster R-CNN do not backprop through
# the proposals
# 将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
#155040*1*4
proposals = proposals.view(num_images, -1, 4)
#8 19380 4
# 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
losses = {}
#如果是训练模式
if self.training:
assert targets is not None
# 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors
#labels tensor261888 0 0 0 0 1 0.....0
#matched_gt_boxes 每张图片的anchors所对应的gtbox
labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)
# 结合anchors以及对应的gt,计算regression参数
regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
loss_objectness, loss_rpn_box_reg = self.compute_loss(
objectness, pred_bbox_deltas, labels, regression_targets
)
losses = {
"loss_objectness": loss_objectness,
"loss_rpn_box_reg": loss_rpn_box_reg
}
return boxes, losses
# numel() Returns the total number of elements in the input tensor.
# 计算每个预测特征层上的对应的anchors数量
# o[0].shape 15 34 42 相乘得到每个预测特征层上anchor的个数
num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness]
num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]
Faster RCNN网络源码解读(Ⅰ) --- Fast RCNN、Faster RCNN论文解读https://blog.csdn.net/qq_41694024/article/details/128483662
2.1.5 smooth_l1_loss
def smooth_l1_loss(input, target, beta: float = 1. / 9, size_average: bool = True):
"""
very similar to the smooth_l1_loss from pytorch, but with
the extra beta parameter
"""
n = torch.abs(input - target)
# cond = n < beta
cond = torch.lt(n, beta)
loss = torch.where(cond, 0.5 * n ** 2 / beta, n - 0.5 * beta)
if size_average:
return loss.mean()
return loss.sum()
我在论文解读的时候推导过,这里不加阐述。
Faster RCNN网络源码解读(Ⅰ) --- Fast RCNN、Faster RCNN论文解读https://blog.csdn.net/qq_41694024/article/details/128483662
2.2 Matcher类(det_utils.py)
2.2.1 __call__
class Matcher(object):
BELOW_LOW_THRESHOLD = -1
BETWEEN_THRESHOLDS = -2
__annotations__ = {
'BELOW_LOW_THRESHOLD': int,
'BETWEEN_THRESHOLDS': int,
}
def __init__(self, high_threshold, low_threshold, allow_low_quality_matches=False):
# type: (float, float, bool) -> None
"""
Args:
high_threshold (float): quality values greater than or equal to
this value are candidate matches.
low_threshold (float): a lower quality threshold used to stratify
matches into three levels:
1) matches >= high_threshold
2) BETWEEN_THRESHOLDS matches in [low_threshold, high_threshold)
3) BELOW_LOW_THRESHOLD matches in [0, low_threshold)
allow_low_quality_matches (bool): if True, produce additional matches
for predictions that have only low-quality match candidates. See
set_low_quality_matches_ for more details.
"""
self.BELOW_LOW_THRESHOLD = -1
self.BETWEEN_THRESHOLDS = -2
assert low_threshold <= high_threshold
self.high_threshold = high_threshold # 0.7
self.low_threshold = low_threshold # 0.3
self.allow_low_quality_matches = allow_low_quality_matches
#match_quality_matrix为我们的iou矩阵
def __call__(self, match_quality_matrix):
"""
计算anchors与每个gtboxes匹配的iou最大值,并记录索引,
iou<low_threshold索引值为-1, low_threshold<=iou<high_threshold索引值为-2
Args:
match_quality_matrix (Tensor[float]): an MxN tensor, containing the
pairwise quality between M ground-truth elements and N predicted elements.
Returns:
matches (Tensor[int64]): an N tensor where N[i] is a matched gt in
[0, M - 1] or a negative value indicating that prediction i could not
be matched.
"""
if match_quality_matrix.numel() == 0:
# empty targets or proposals not supported during training
if match_quality_matrix.shape[0] == 0:
raise ValueError(
"No ground-truth boxes available for one of the images "
"during training")
else:
raise ValueError(
"No proposal boxes available for one of the images "
"during training")
# match_quality_matrix is M (gt) x N (predicted)
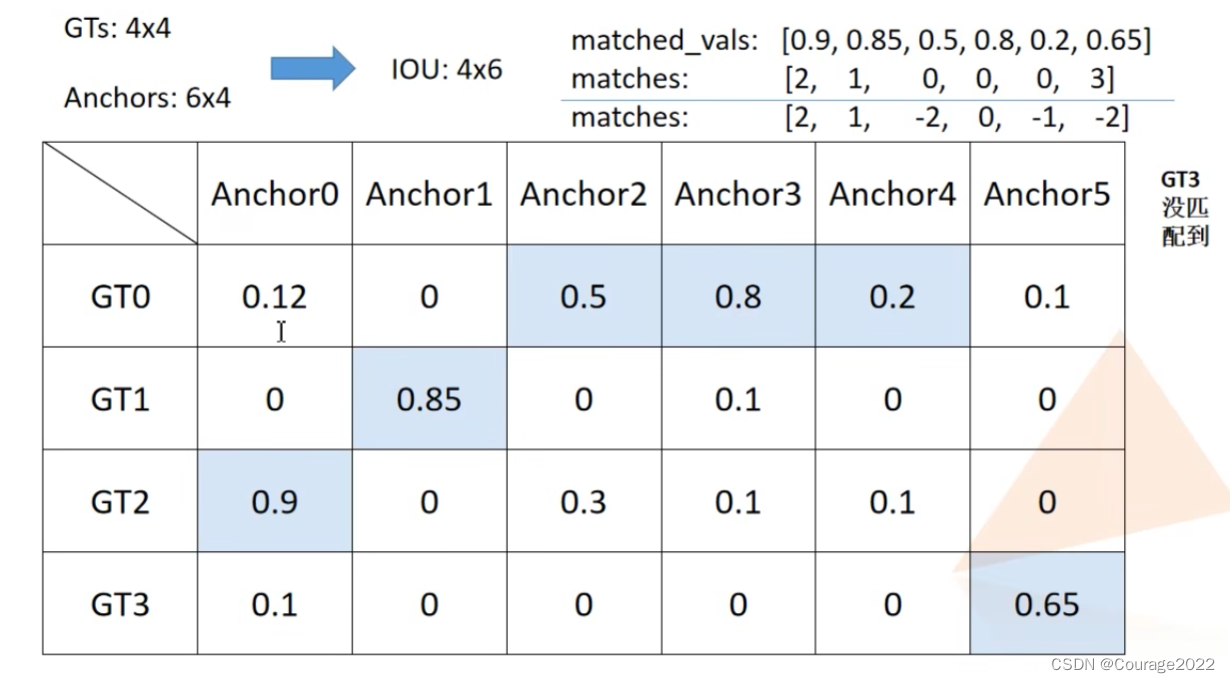
# Max over gt elements (dim 0) to find best gt candidate for each prediction
# M x N 的每一列代表一个anchors与所有gt的匹配iou值
# matched_vals代表每列的最大值,即每个anchors与所有gt匹配的最大iou值
# matches对应最大值所在的索引
#即对每个anchor求与标注框的最大值
matched_vals, matches = match_quality_matrix.max(dim=0) # the dimension to reduce.
if self.allow_low_quality_matches:
all_matches = matches.clone()
else:
all_matches = None
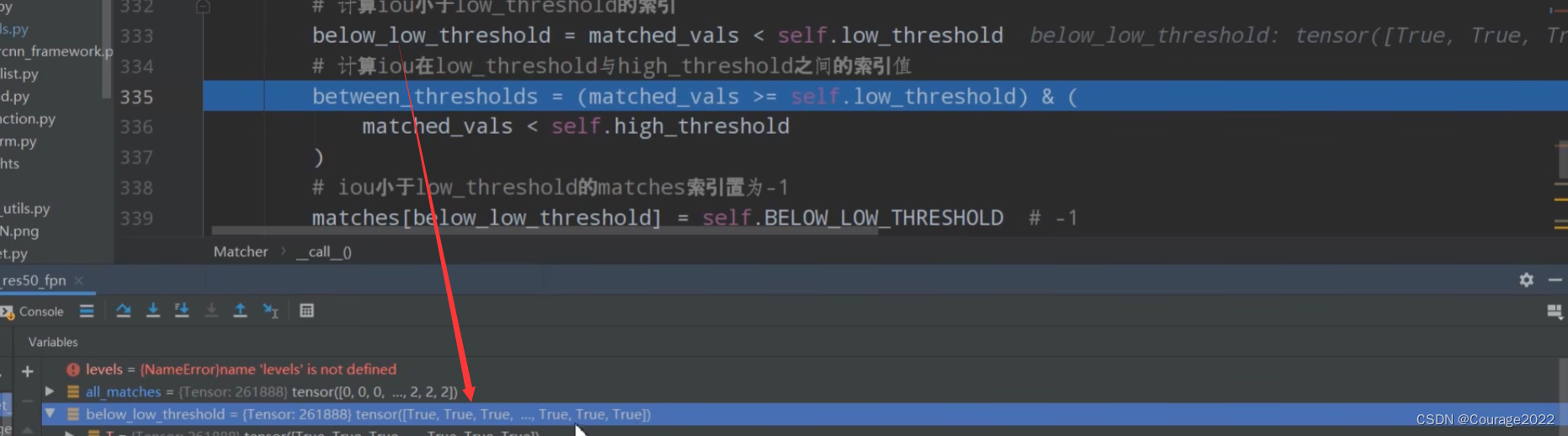
# Assign candidate matches with low quality to negative (unassigned) values
# 计算iou小于low_threshold的索引
below_low_threshold = matched_vals < self.low_threshold
# 计算iou在low_threshold与high_threshold之间的索引值
between_thresholds = (matched_vals >= self.low_threshold) & (
matched_vals < self.high_threshold
)
# iou小于low_threshold的matches索引置为-1
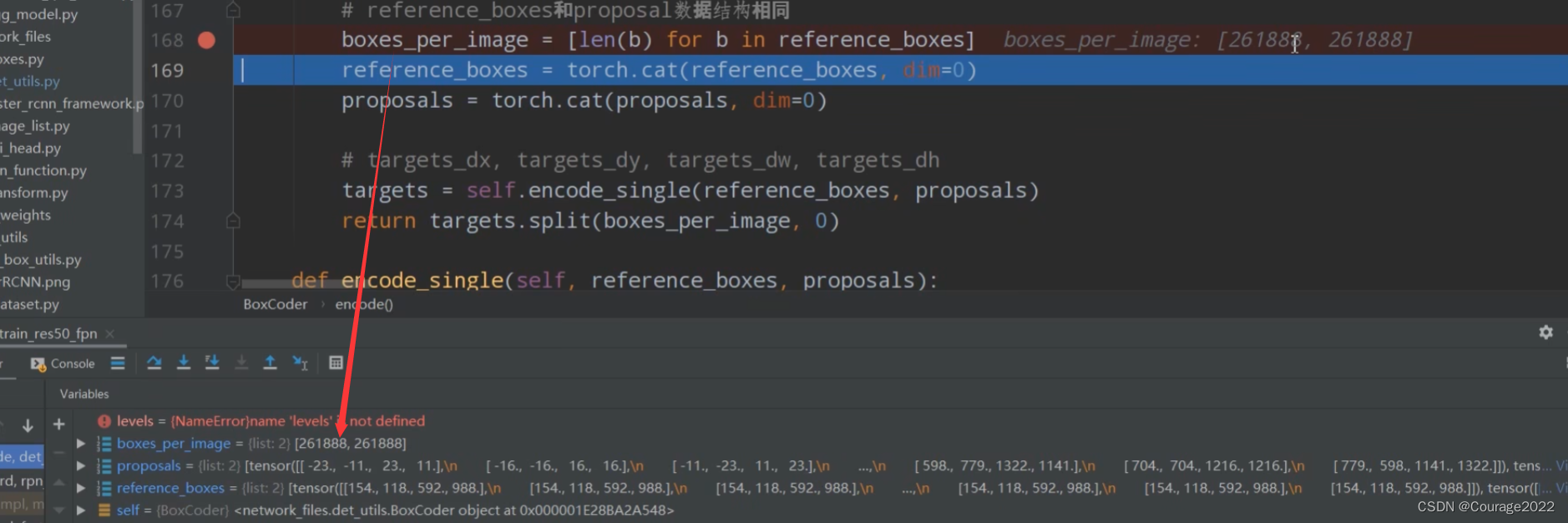
matches[below_low_threshold] = self.BELOW_LOW_THRESHOLD # -1
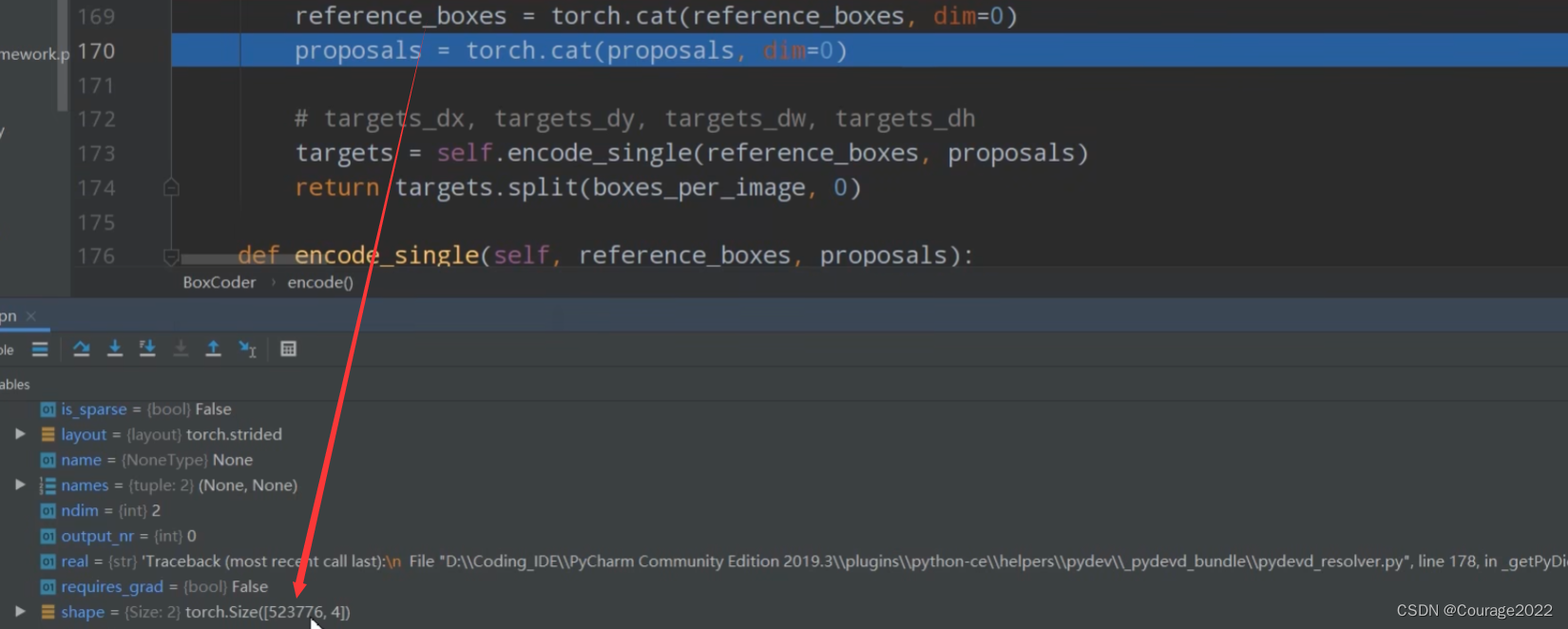
# iou在[low_threshold, high_threshold]之间的matches索引置为-2
matches[between_thresholds] = self.BETWEEN_THRESHOLDS # -2
#启动规则:将匹配度最大的也设置为正样本
if self.allow_low_quality_matches:
assert all_matches is not None
self.set_low_quality_matches_(matches, all_matches, match_quality_matrix)
return matches
def set_low_quality_matches_(self, matches, all_matches, match_quality_matrix):
"""
Produce additional matches for predictions that have only low-quality matches.
Specifically, for each ground-truth find the set of predictions that have
maximum overlap with it (including ties); for each prediction in that set, if
it is unmatched, then match it to the ground-truth with which it has the highest
quality value.
"""
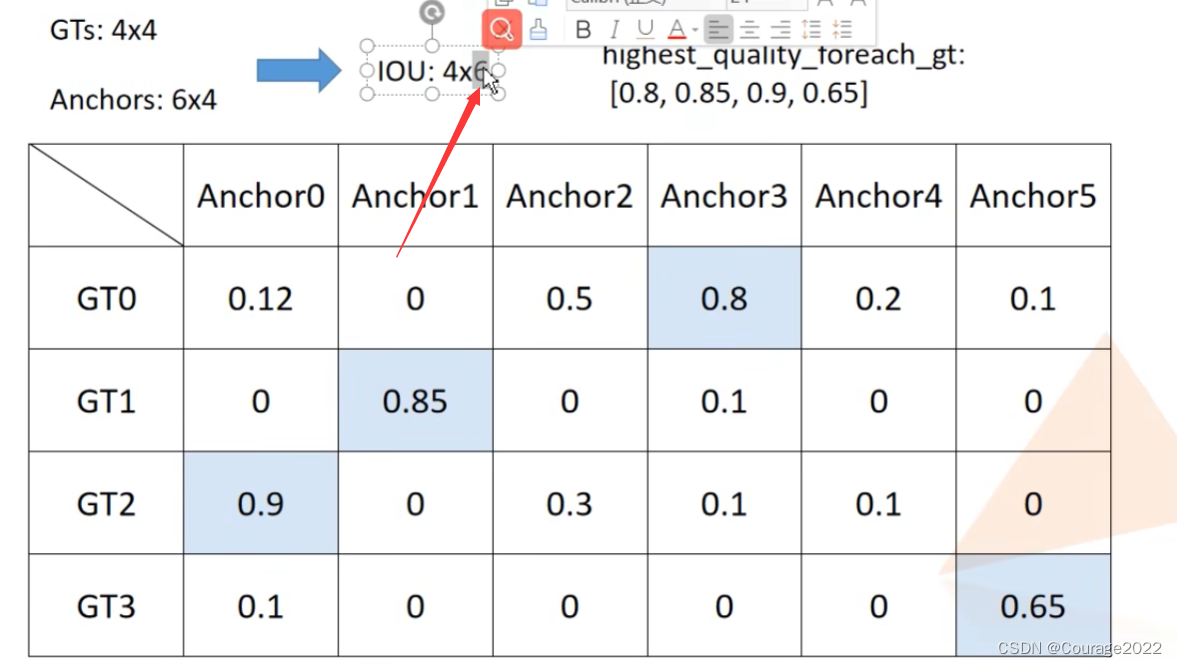
# For each gt, find the prediction with which it has highest quality
# 对于每个gt boxes寻找与其iou最大的anchor,
# highest_quality_foreach_gt为匹配到的最大iou值
highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1) # the dimension to reduce.
# Find highest quality match available, even if it is low, including ties
# 寻找每个gt boxes与其iou最大的anchor索引,一个gt匹配到的最大iou可能有多个anchor
# gt_pred_pairs_of_highest_quality = torch.nonzero(
# match_quality_matrix == highest_quality_foreach_gt[:, None]
# )
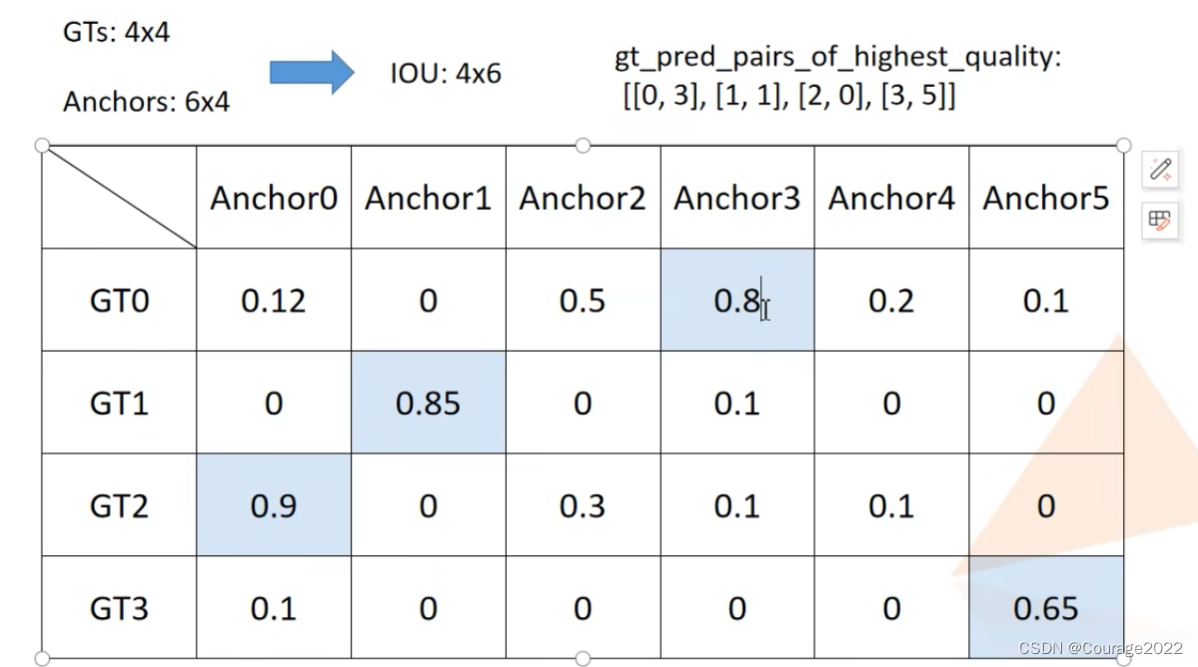
gt_pred_pairs_of_highest_quality = torch.where(
torch.eq(match_quality_matrix, highest_quality_foreach_gt[:, None])
)
# Example gt_pred_pairs_of_highest_quality:
# tensor([[ 0, 39796],
# [ 1, 32055],
# [ 1, 32070],
# [ 2, 39190],
# [ 2, 40255],
# [ 3, 40390],
# [ 3, 41455],
# [ 4, 45470],
# [ 5, 45325],
# [ 5, 46390]])
# Each row is a (gt index, prediction index)
# Note how gt items 1, 2, 3, and 5 each have two ties
# gt_pred_pairs_of_highest_quality[:, 0]代表是对应的gt index(不需要)
# pre_inds_to_update = gt_pred_pairs_of_highest_quality[:, 1]
pre_inds_to_update = gt_pred_pairs_of_highest_quality[1]
# 保留该anchor匹配gt最大iou的索引,即使iou低于设定的阈值
matches[pre_inds_to_update] = all_matches[pre_inds_to_update]
# match_quality_matrix is M (gt) x N (predicted)
# Max over gt elements (dim 0) to find best gt candidate for each prediction
# M x N 的每一列代表一个anchors与所有gt的匹配iou值
# matched_vals代表每列的最大值,即每个anchors与所有gt匹配的最大iou值
# matches对应最大值所在的索引
#即对每个anchor求与标注框的最大值
matched_vals, matches = match_quality_matrix.max(dim=0) # the dimension to reduce.
#启动规则:将匹配度最大的也设置为正样本
if self.allow_low_quality_matches:
assert all_matches is not None
self.set_low_quality_matches_(matches, all_matches, match_quality_matrix)
def set_low_quality_matches_(self, matches, all_matches, match_quality_matrix):
"""
Produce additional matches for predictions that have only low-quality matches.
Specifically, for each ground-truth find the set of predictions that have
maximum overlap with it (including ties); for each prediction in that set, if
it is unmatched, then match it to the ground-truth with which it has the highest
quality value.
"""
# For each gt, find the prediction with which it has highest quality
# 对于每个gt boxes寻找与其iou最大的anchor,
# highest_quality_foreach_gt为匹配到的最大iou值
highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1) # the dimension to reduce.
# Find highest quality match available, even if it is low, including ties
# 寻找每个gt boxes与其iou最大的anchor索引,一个gt匹配到的最大iou可能有多个anchor
# gt_pred_pairs_of_highest_quality = torch.nonzero(
# match_quality_matrix == highest_quality_foreach_gt[:, None]
# )
gt_pred_pairs_of_highest_quality = torch.where(
torch.eq(match_quality_matrix, highest_quality_foreach_gt[:, None])
)
# Example gt_pred_pairs_of_highest_quality:
# tensor([[ 0, 39796],
# [ 1, 32055],
# [ 1, 32070],
# [ 2, 39190],
# [ 2, 40255],
# [ 3, 40390],
# [ 3, 41455],
# [ 4, 45470],
# [ 5, 45325],
# [ 5, 46390]])
# Each row is a (gt index, prediction index)
# Note how gt items 1, 2, 3, and 5 each have two ties
# gt_pred_pairs_of_highest_quality[:, 0]代表是对应的gt index(不需要)
# pre_inds_to_update = gt_pred_pairs_of_highest_quality[:, 1]
pre_inds_to_update = gt_pred_pairs_of_highest_quality[1]
# 保留该anchor匹配gt最大iou的索引,即使iou低于设定的阈值
matches[pre_inds_to_update] = all_matches[pre_inds_to_update]
还是拿上面的做例子:
highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1) # the dimension to reduce.
def __init__(self, batch_size_per_image, positive_fraction):
# type: (int, float) -> None
"""
Arguments:
batch_size_per_image (int): number of elements to be selected per image
positive_fraction (float): percentage of positive elements per batch
"""
self.batch_size_per_image = batch_size_per_image
self.positive_fraction = positive_fraction
简单的赋初值。
2.3.2 正向传播过程__call__
def __call__(self, matched_idxs):
# type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]
"""
Arguments:
matched idxs: list of tensors containing -1, 0 or positive values.
Each tensor corresponds to a specific image.
-1 values are ignored, 0 are considered as negatives and > 0 as
positives.
Returns:
pos_idx (list[tensor])
neg_idx (list[tensor])
Returns two lists of binary masks for each image.
The first list contains the positive elements that were selected,
and the second list the negative example.
"""
pos_idx = []
neg_idx = []
# 遍历每张图像的matched_idxs
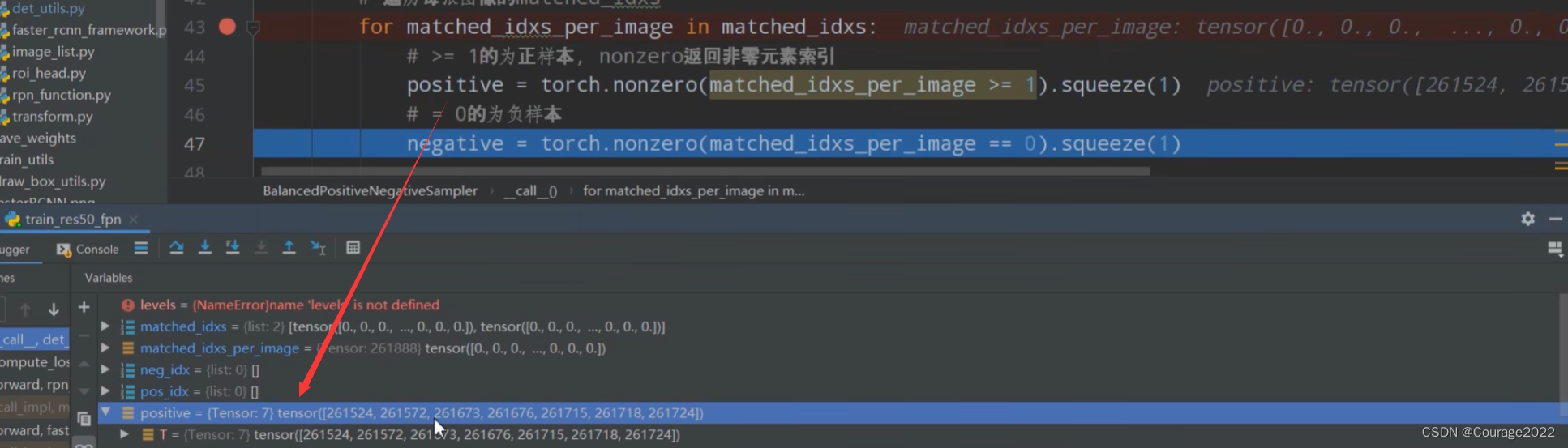
for matched_idxs_per_image in matched_idxs:
# >= 1的为正样本, nonzero返回非零元素索引
# positive = torch.nonzero(matched_idxs_per_image >= 1).squeeze(1)
positive = torch.where(torch.ge(matched_idxs_per_image, 1))[0]
# = 0的为负样本
# negative = torch.nonzero(matched_idxs_per_image == 0).squeeze(1)
negative = torch.where(torch.eq(matched_idxs_per_image, 0))[0]
# 指定正样本的数量
num_pos = int(self.batch_size_per_image * self.positive_fraction)
# protect against not enough positive examples
# 如果正样本数量不够就直接采用所有正样本
num_pos = min(positive.numel(), num_pos)
# 指定负样本数量
num_neg = self.batch_size_per_image - num_pos
# protect against not enough negative examples
# 如果负样本数量不够就直接采用所有负样本
num_neg = min(negative.numel(), num_neg)
# randomly select positive and negative examples
# Returns a random permutation of integers from 0 to n - 1.
# 随机选择指定数量的正负样本
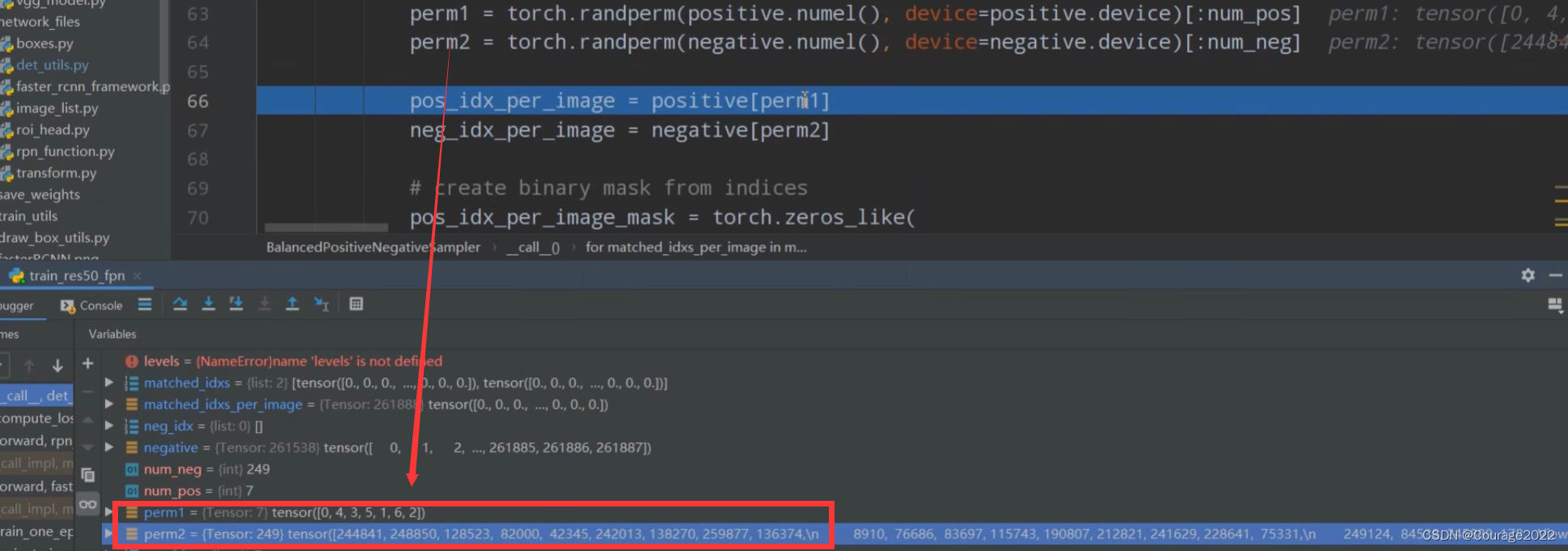
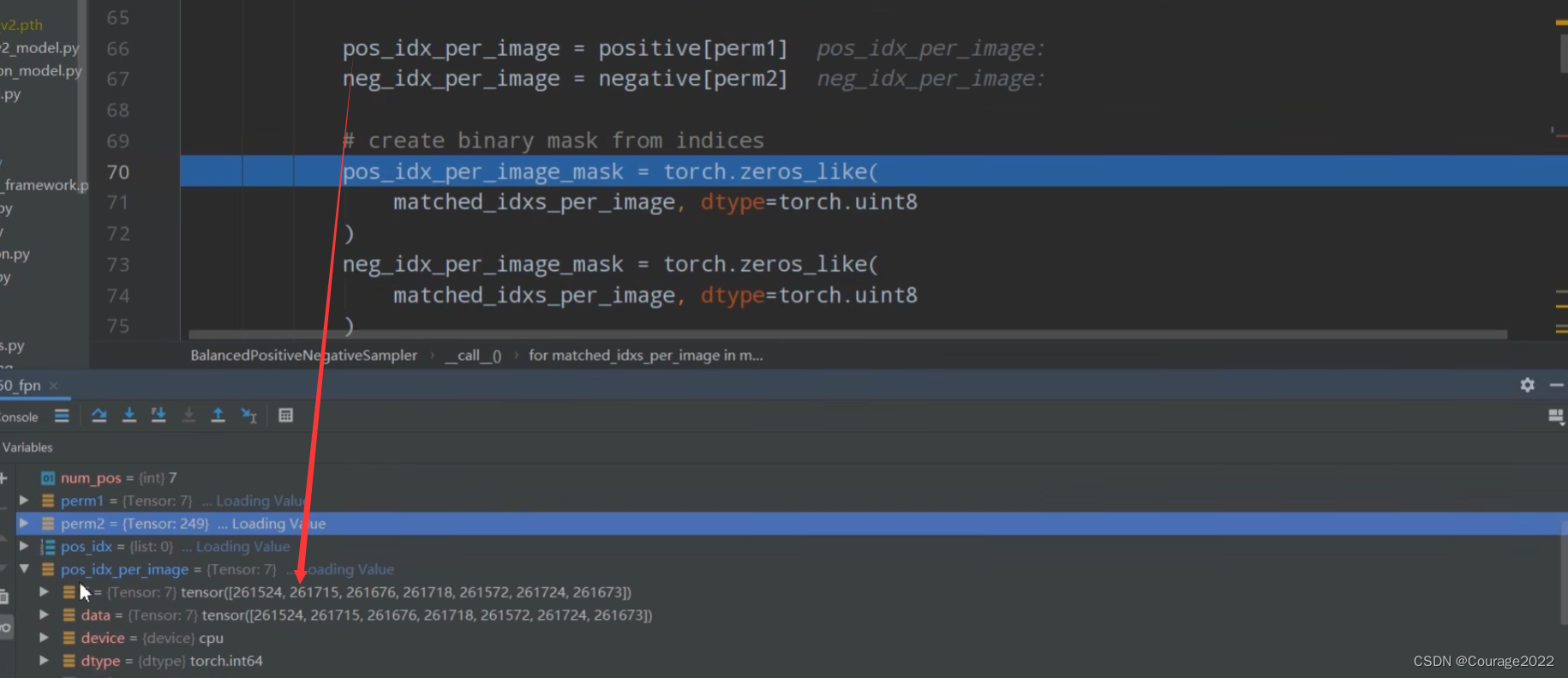
perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
pos_idx_per_image = positive[perm1]
neg_idx_per_image = negative[perm2]
# create binary mask from indices
pos_idx_per_image_mask = torch.zeros_like(
matched_idxs_per_image, dtype=torch.uint8
)
neg_idx_per_image_mask = torch.zeros_like(
matched_idxs_per_image, dtype=torch.uint8
)
pos_idx_per_image_mask[pos_idx_per_image] = 1
neg_idx_per_image_mask[neg_idx_per_image] = 1
pos_idx.append(pos_idx_per_image_mask)
neg_idx.append(neg_idx_per_image_mask)
return pos_idx, neg_idx
Nacos 注册中心 目录概述需求:设计思路实现思路分析1.增加 Maven 依赖2.Client端配置注册中心3.Server端配置注册中心4.Nacos 注册中心参考资料和推荐阅读Survive by day and develop by night. talk for import biz , show your perfect code,full busy,…
文章目录 1、你是否遇到过Too many connections?2、linux的文件句柄数量被限制1、你是否遇到过Too many connections?
今天要给大家分析另外一个真实的大家都经常会碰到的数据库生产故障,就是数据库无法连接的问题。
大家会看到的异常信息往往是“ERROR 1040(HY000): Too …
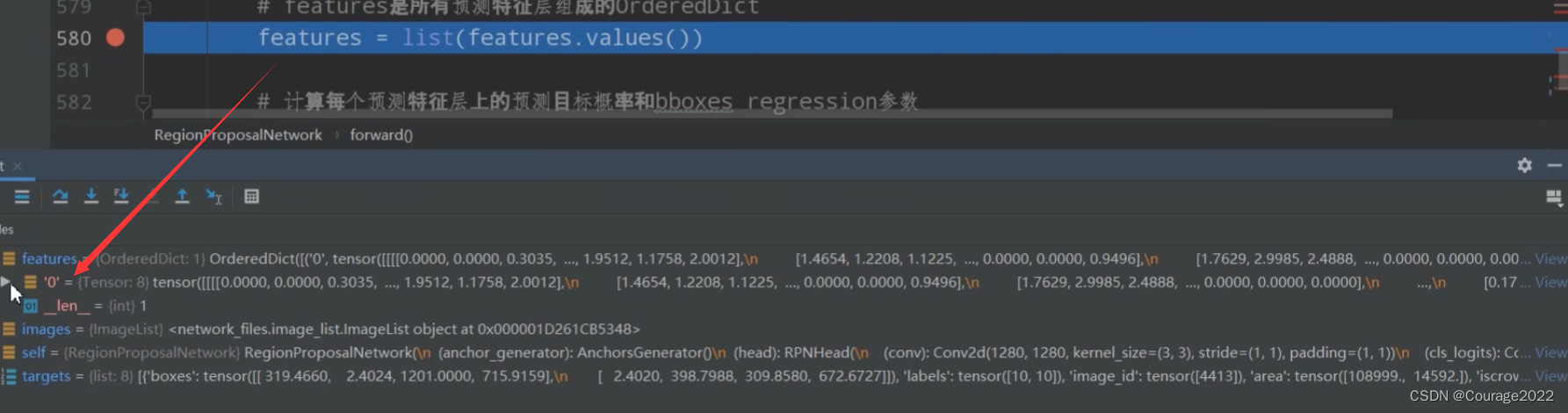
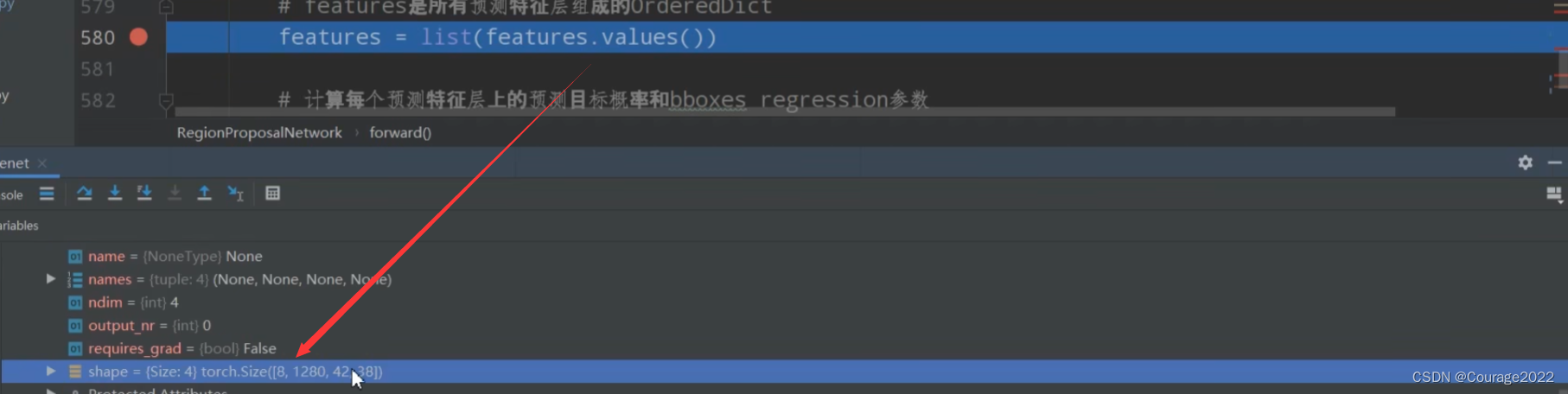
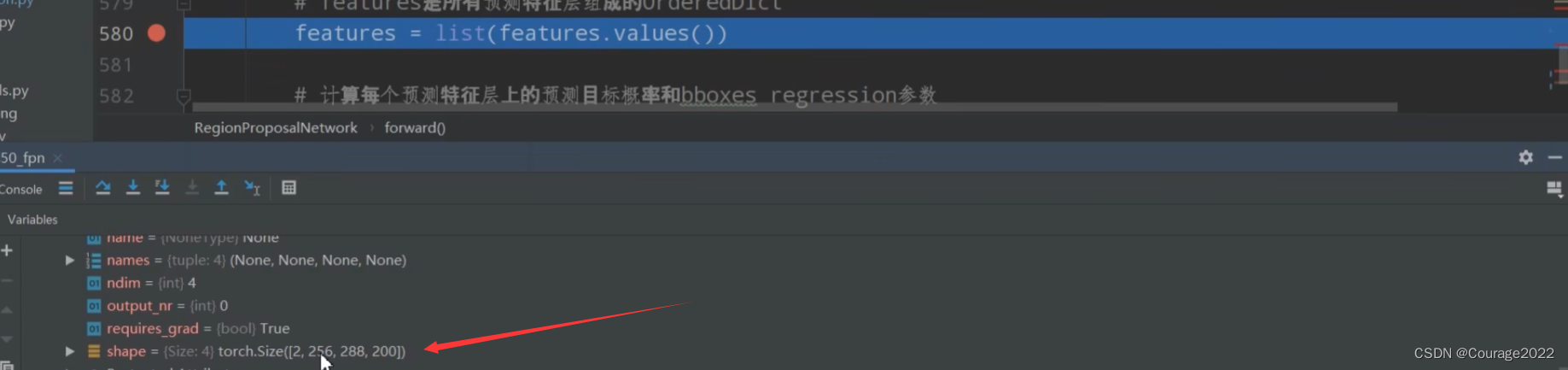
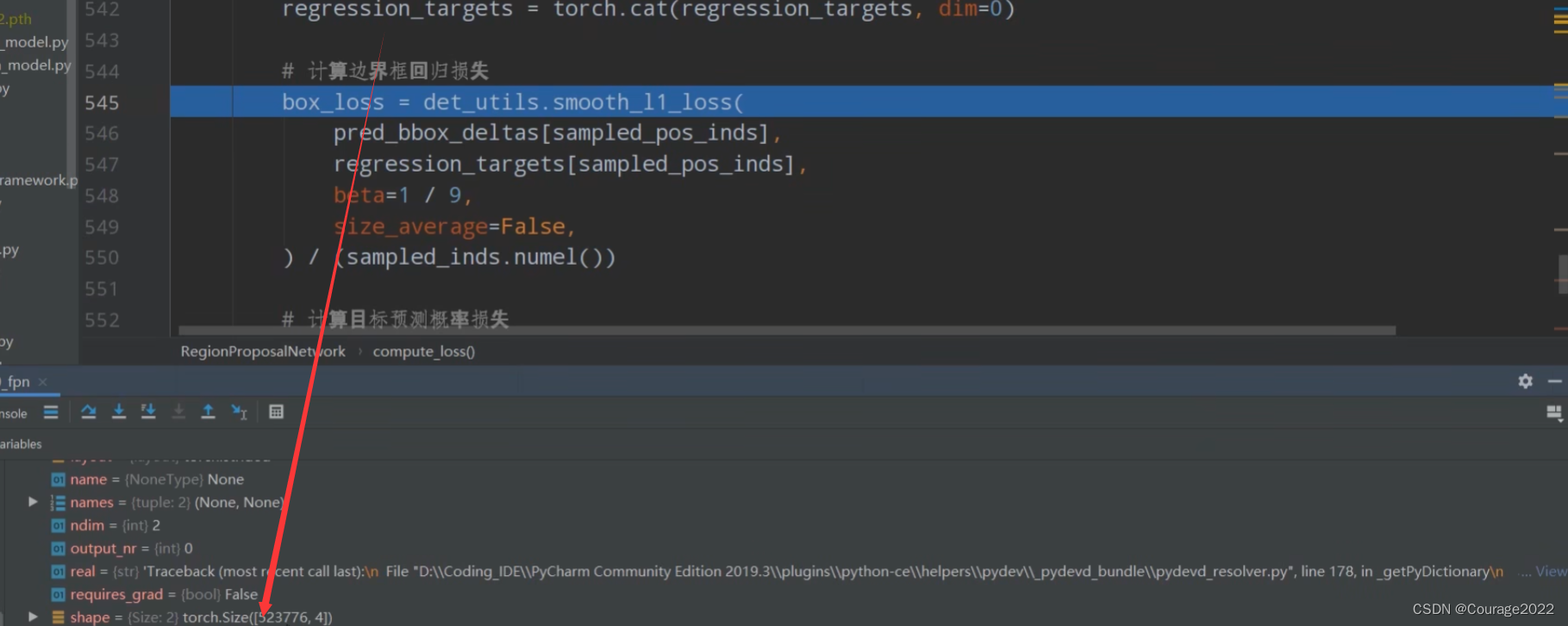
,8代表batchsize,1280代表预测特征层的channel,
代表着预测特征矩阵的宽和高。
的。
的。
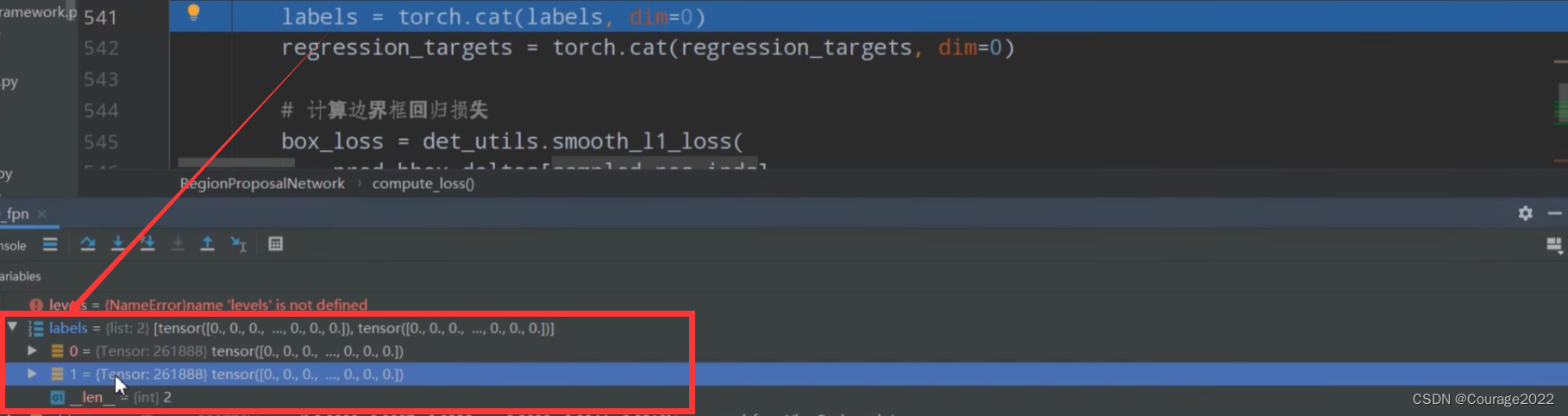
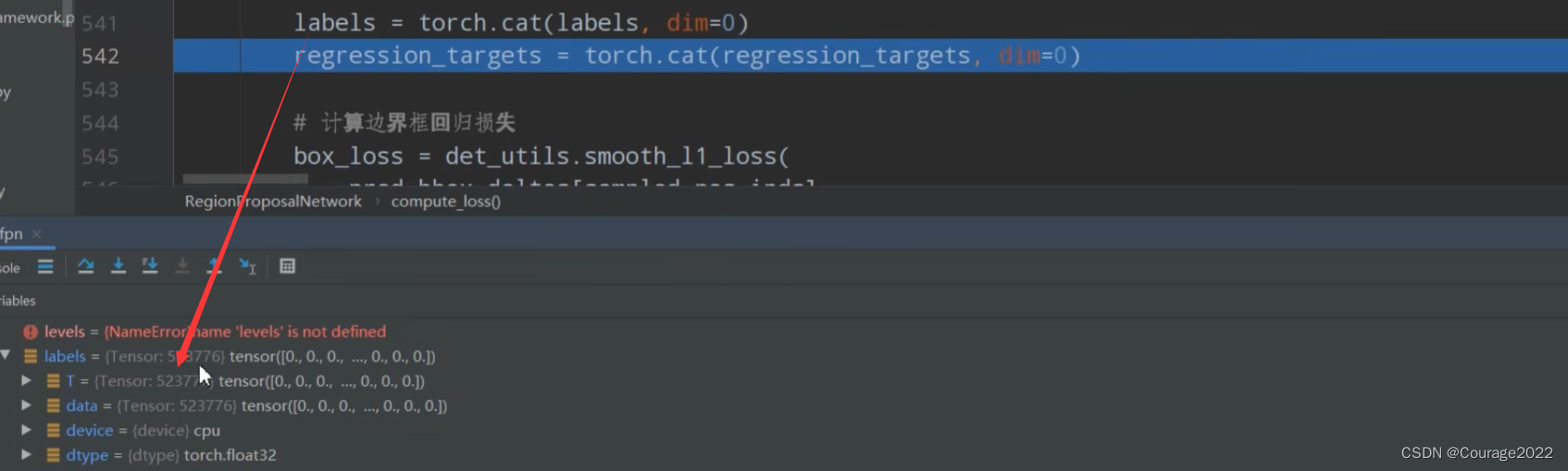
如果是训练模式求解损失:
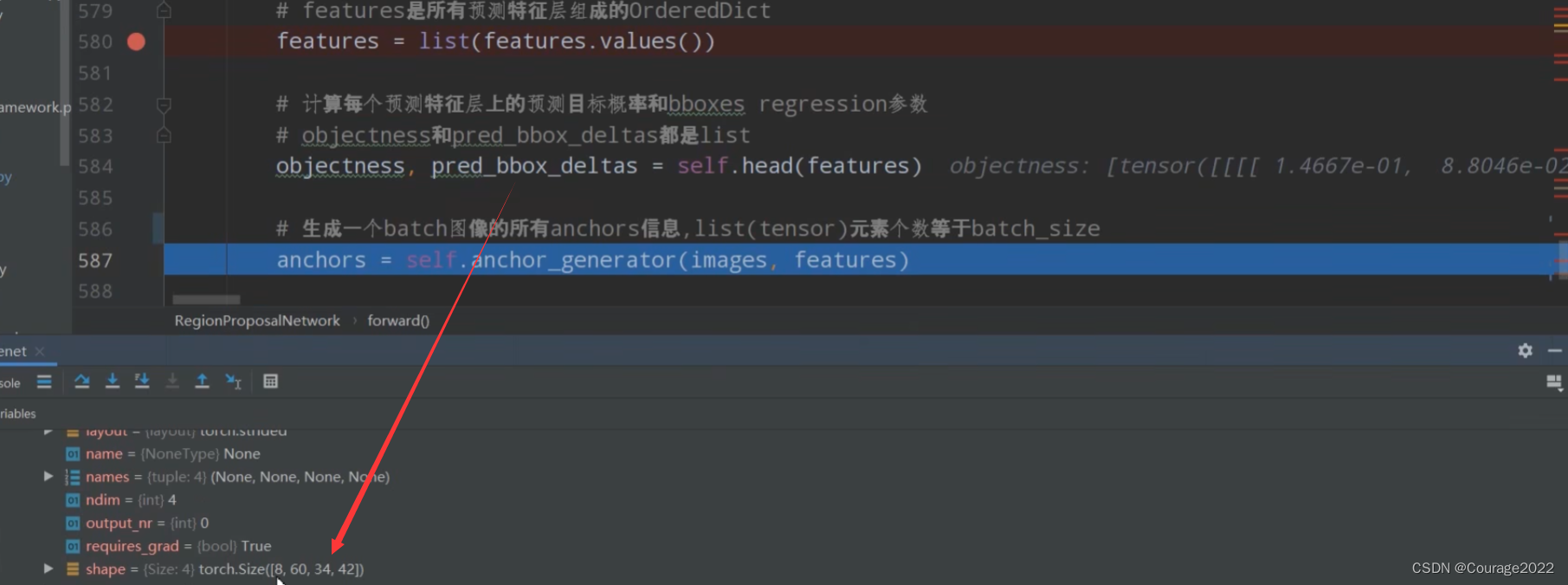
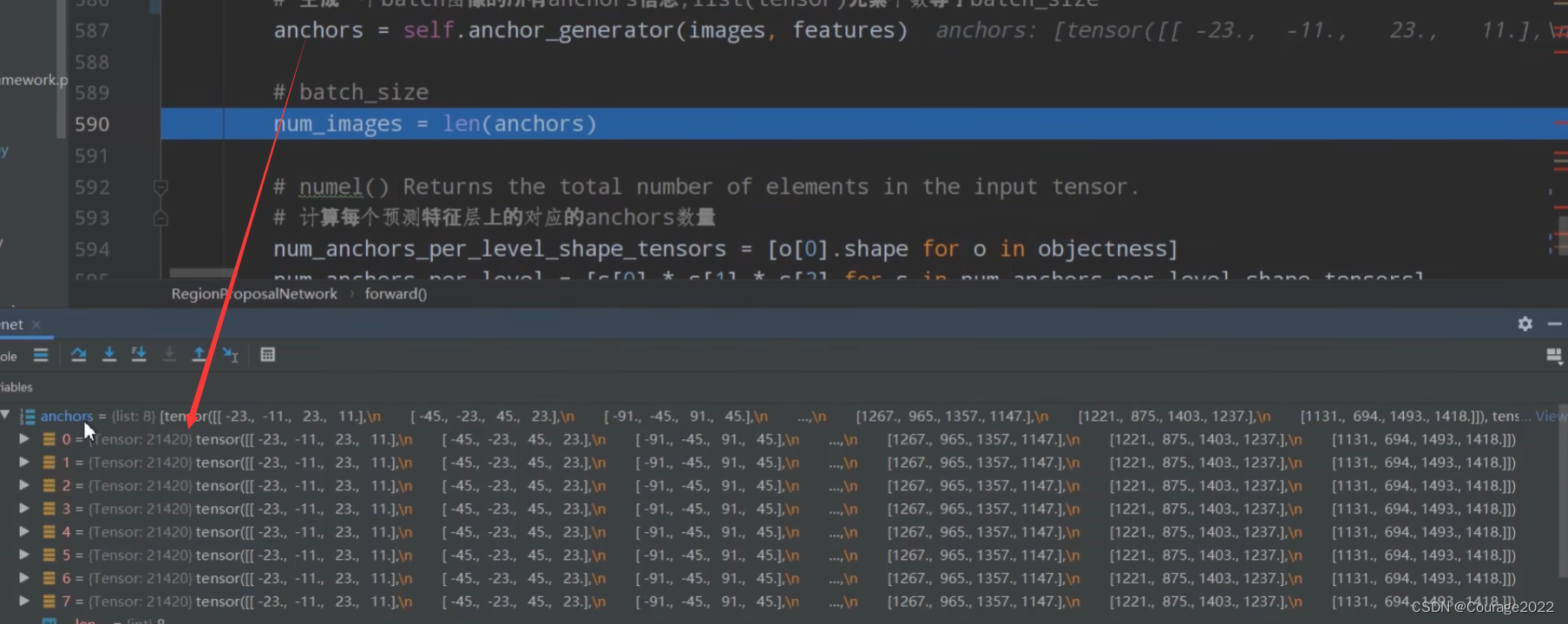
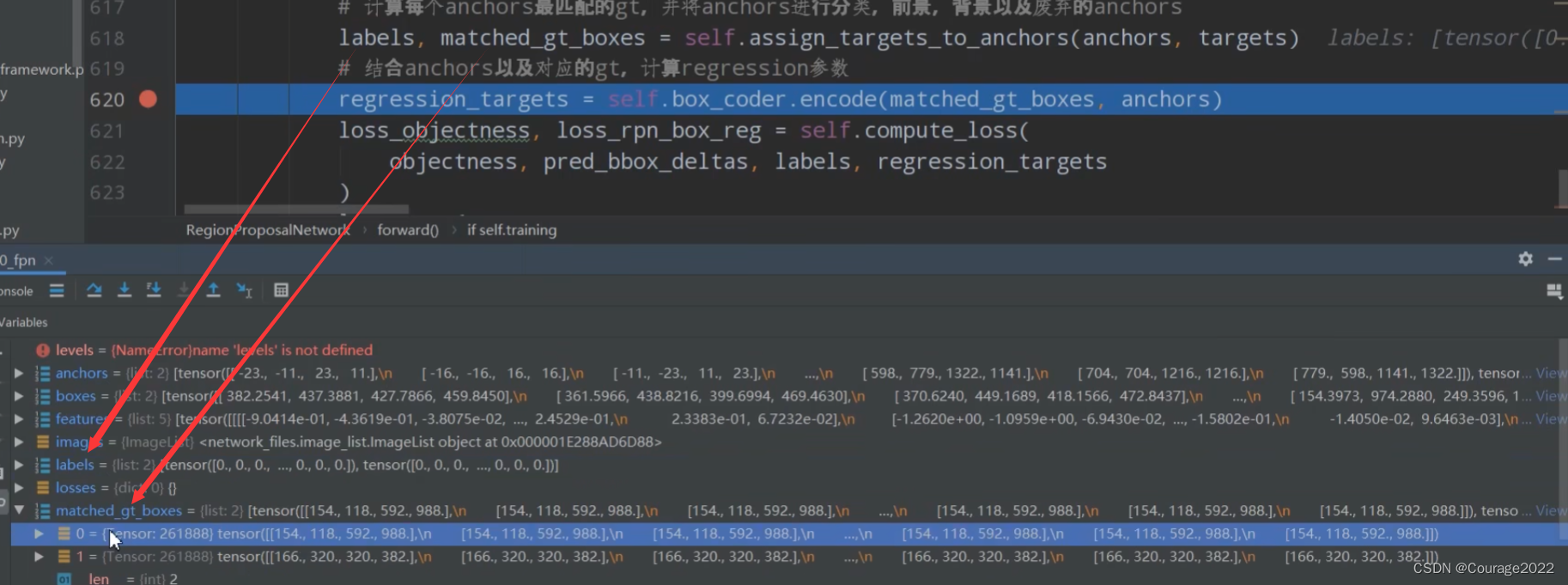
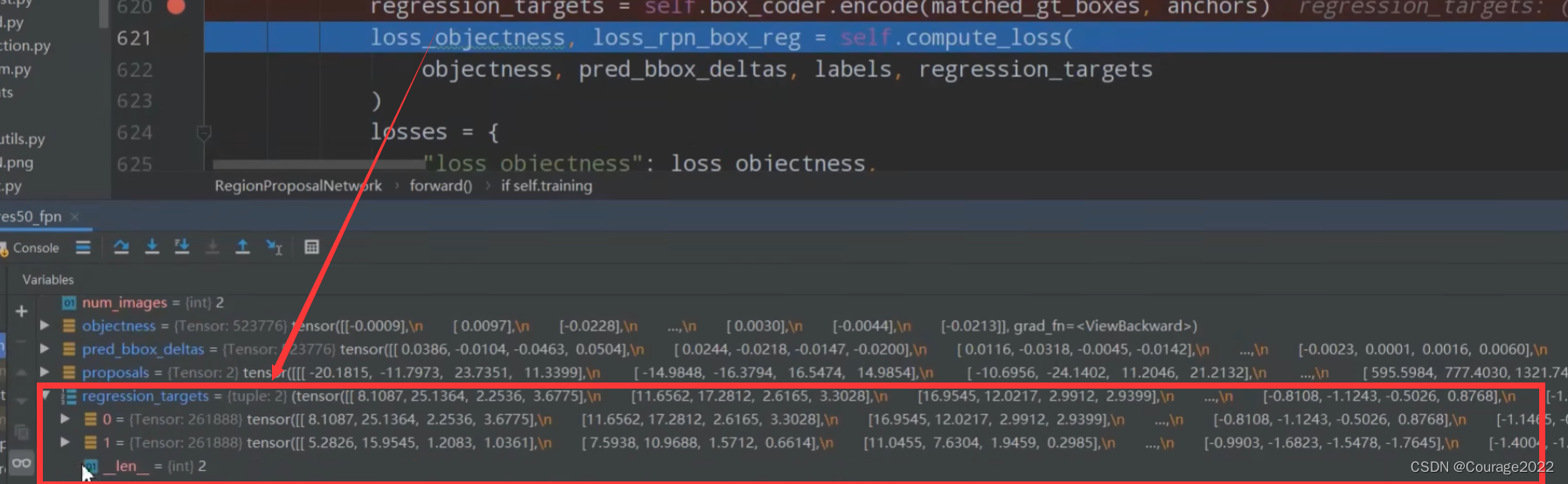

。假设我们图片中有6个anchors,每个anchors也有6个坐标,因此shape是
,当然,IoU的matrix就是4*6的了。对应每个gtbox与每个Anchor的IoU值。
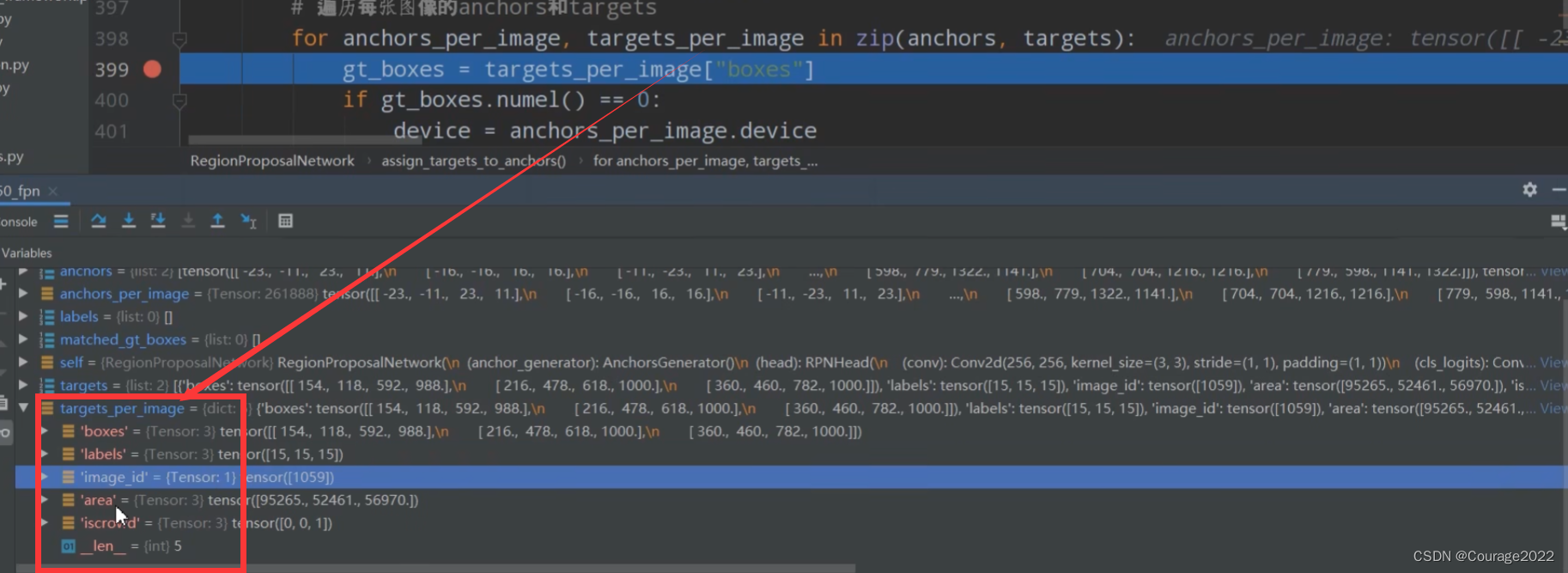
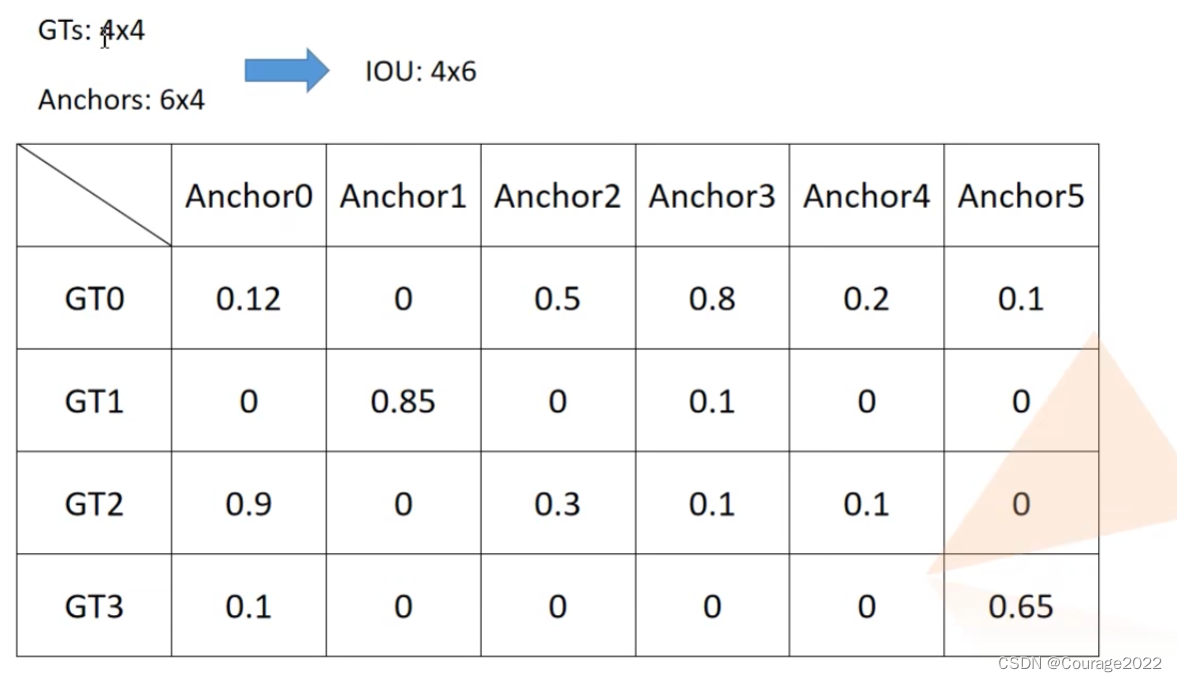
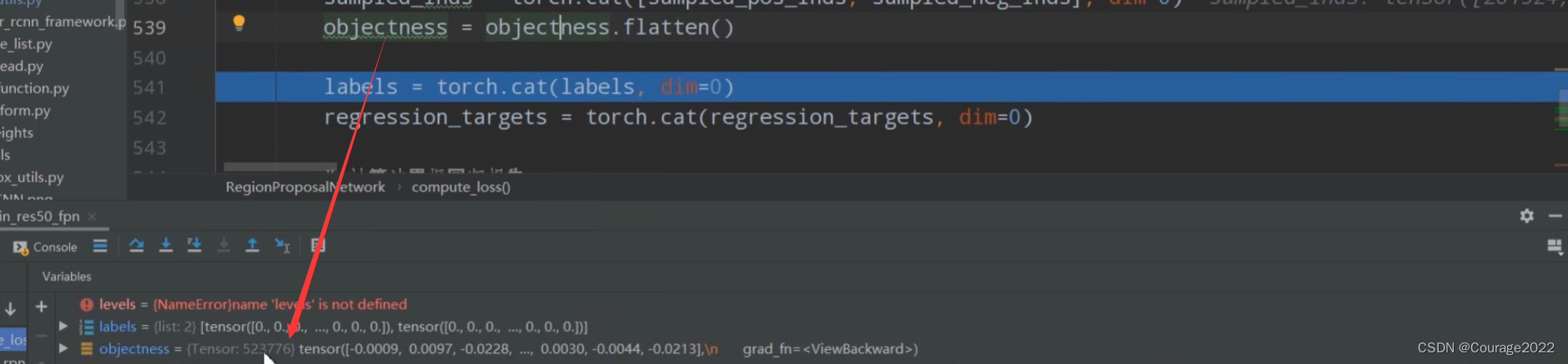
,展平之后变成了
。
大小的tensor。
https://blog.csdn.net/qq_41694024/article/details/128483662
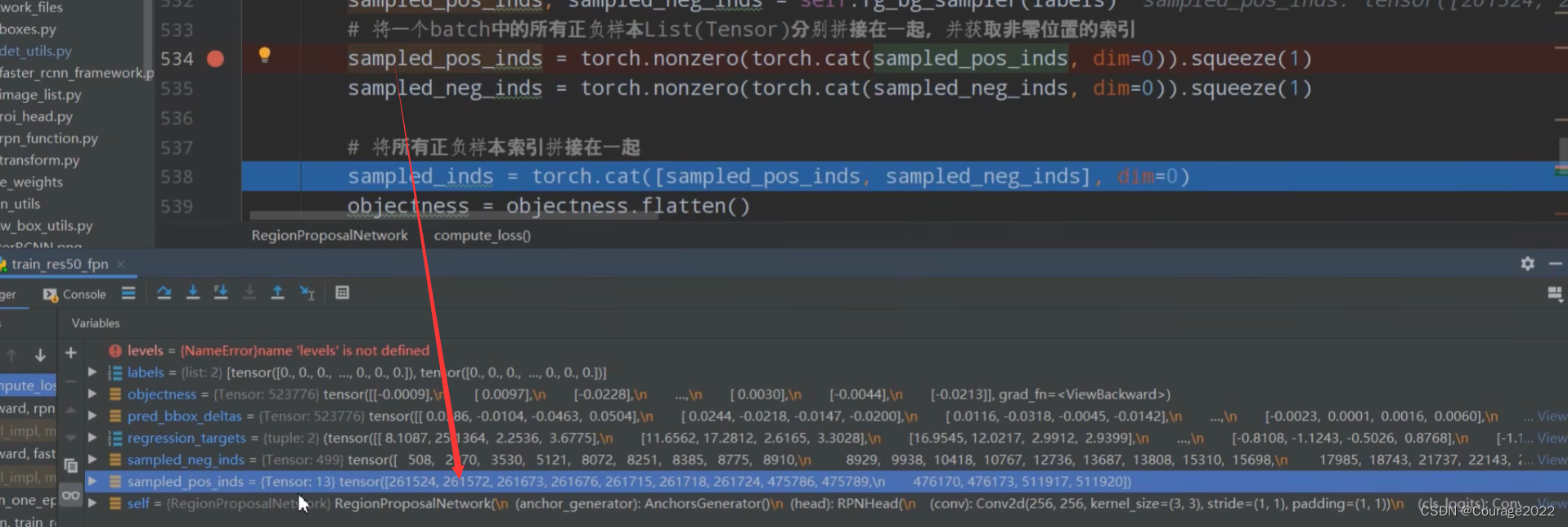
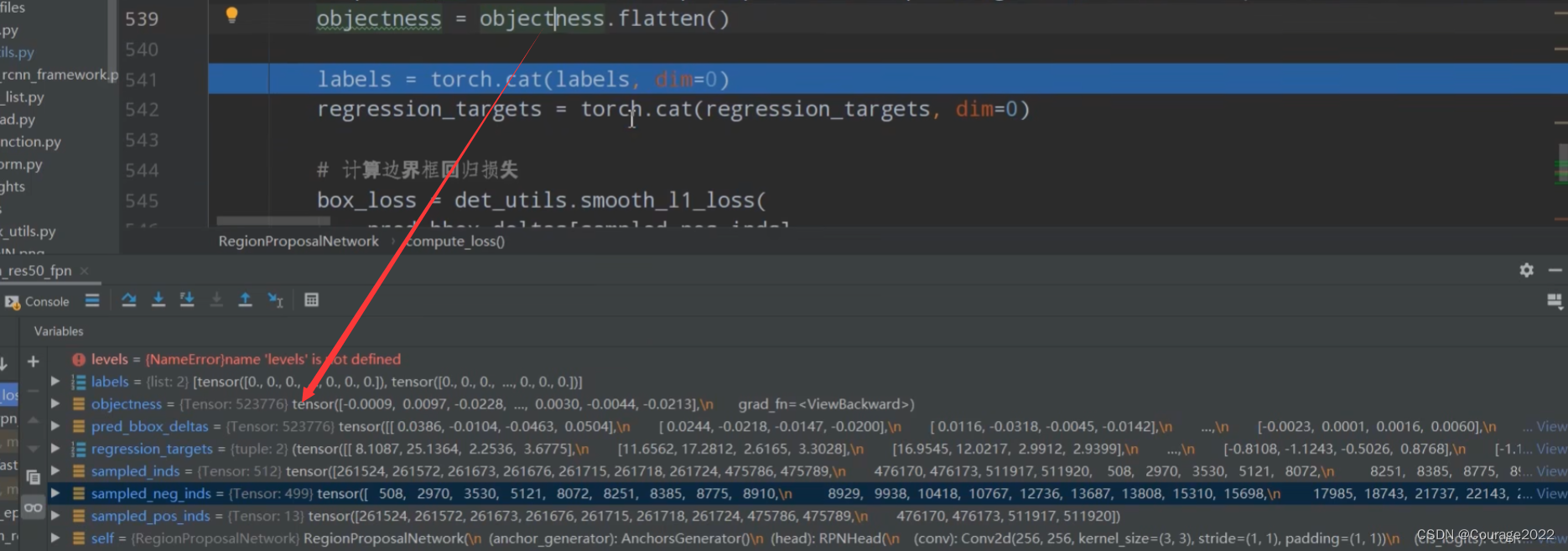

中的4,即求每列的最大值,即每个anchor与我们的每个gtbox的最大IoU值。