End-to-End Object Detection with Transformers
端到端,不需要NMS后处理了,直接出结果。
1、Abstract
将目标检测作为一个集合预测问题来解决。简化了检测的整体流程,有效的消除了许多人工设计的部分,比如NMS,anchor这些针对任务类型的先验知识。DETR的主要组成有一个基于集合的全局损失函数,通过二分图匹配来为每个目标确定唯一的预测结果,以及一个transformer的encoder-decoder架构。给一个固定长度(论文中固定为100)的可以学习的object queries,DETR通过物体和全局图片内容之间的关系,直接并行输出一组预测集。DETR概念上非常简单,而且也不要求你有拥有专业知识。DETR在检测的精度和运行时间和Faster RCNN相当。而且DETR还可以拓展到全景分割的任务当中。
2、Introduction
目标检测的目标是预测感兴趣的目标的bbox以及对应的类别。现在的目标检测方法都是通过间接的方式去处理集合预测问题,比如proposals、anchor、window center等方法,都是设计了一个替代的,将其当作回归、分类问题。它们的性能明显的受后处理操作的影响,因为其之前会生成大量的冗余框、所以需要使用NMS方法将冗余框抑制。为了简化这些流程,本文提出了一种直接进行集合预测的方法去绕过了那些代理问题。这种端到端的思想已经在其他复杂的预测任务中大量的使用了,并且取得了非常明显的效果,但是还没有应用到目标检测任务当中,之前的也有一些类似的尝试,但其要么就是需要融入更多的先验知识,要么就是在比较难的benchmarks数据集上取得不了很好的成绩。这篇文章弥补了这一gap。
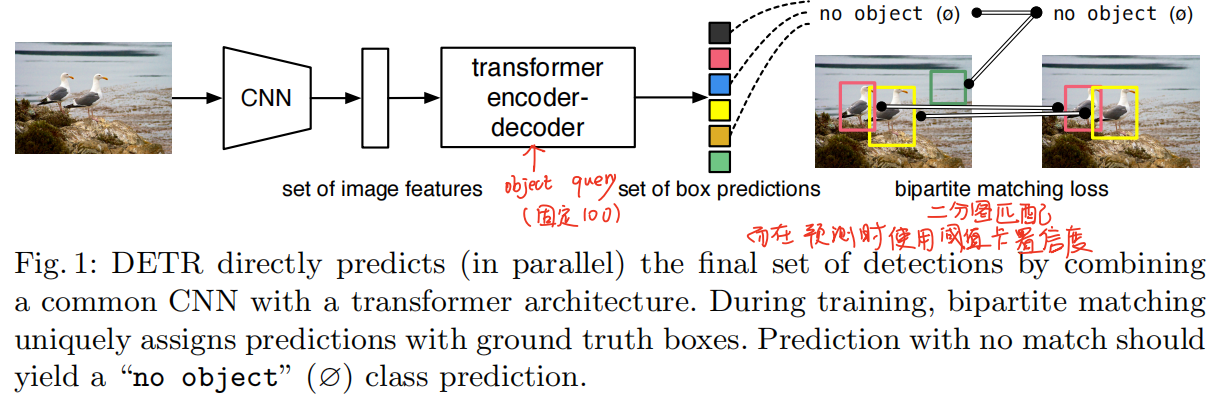
其中encoder可以寻找每个点与图像中其他部分之间的关系,这就可以让网络学习得到哪些区域属于同一个物体,哪些属于不同的物体。这有助于去除冗余的预测框。
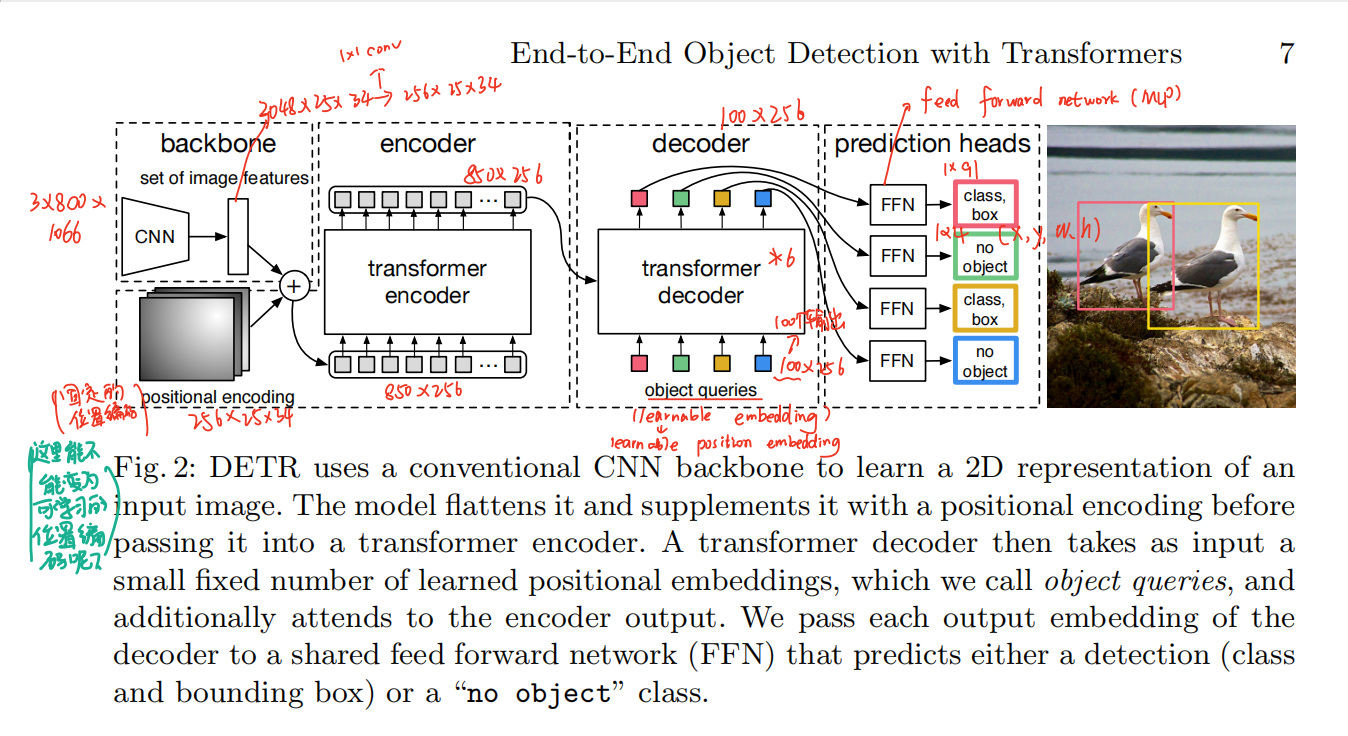
DETR只预测一次,并将训练得到的预测结果和GT俩俩做二分图匹配,并计算loss function。DETR简化了目标检测流程,丢弃了人工设计的那些先验知识,比如anchor和nms。不像目前大多数检测方法,DETR没有任何定制化层,而且其可以非常简单的用任何包含标准CNN和transformer的架构复现。
与之前工作不一样的地方在于,DETR采用了二分图匹配计算loss,并且使用了没有自回归的decoder架构,decoder时可以并行。
结果显示DETR在大物体上的性能比较好,而在小目标检测性能比较差。而且其运行时间比较长。
整体流程就是:首先将图片通过CNN抽取特征,然后将其输入transformer架构,encoder有利于网络学习各个区域之间的关系,decoder生成预测框,并将其当做一个集合预测类型,将生成的预测框和GT做二分图匹配,计算bbox的loss和分类的loss。而在预测时没有GT框计算loss,那么就根据decoder输出的预测框的置信度的大小来输出最终的预测框。
3、The DETR model
3.1 Object detection set prediction loss
DETR推理得到固定的N个预测框。N比数据集中一张图片的最大物体个数多很多。如何设计预测框和GT之间的loss呢?将其当做一个二分图匹配问题。

在目标检测任务中,cost matrix中应该放loss。
loss可以包含了分类loss和bbox loss。
− 1 { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ∅ } L box ( b i , b ^ σ ( i ) ) . -\mathbb{1}_{\left\{c_{i} \neq \varnothing\right\}} \hat{p}_{\sigma(i)}\left(c_{i}\right)+\mathbb{1}_{\left\{c_{i} \neq \varnothing\right\}} \mathcal{L}_{\text {box }}\left(b_{i}, \hat{b}_{\sigma(i)}\right) . −1{ci=∅}p^σ(i)(ci)+1{ci=∅}Lbox (bi,b^σ(i)).
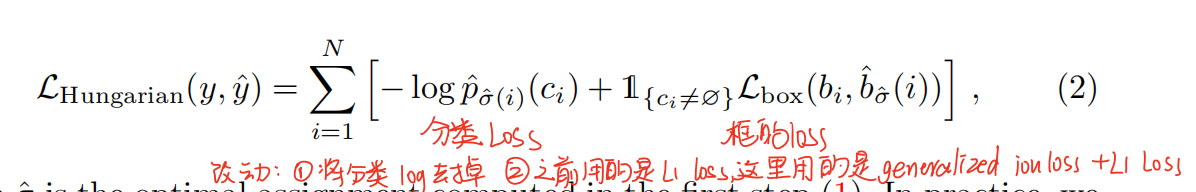
3.2 DETR architecture