总结
在选择维度时,有点意思。
FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
一般对话生成任务的评测也是从多个维度出发,这篇文章先选择了几个相关性程度低的维度,然后,在挑选后的维度上,测评相关性分值。
多个维度下的测评采用了metric ensemble和multi-task learning的方法。
第一步:维度选择
我们希望选择相关性较小的维度,以便我们的度量能够从不同角度全面地捕捉对话质量。
**以往的对话评测矩阵不同维度下的相关性:**选择了FED 的人类评级(Mehri 和 Eskenazi,2020a),一个高质量的对话级评估基准。

维度选择:
首先,考虑与“总体”类别 (> 0.75) 高度相关的维度。直觉是,与“整体”的高相关性表明细粒度维度对人类注释者对对话的整体印象的影响更大。其次,我们过滤掉注释者间一致性较低 (< 0.6)5 的维度,因为注释者间一致性较低可能表明该维度评估起来很复杂,并且人类注释者对该维度有不同的理解(Mehri 等人,2015 年)。 , 2022).最后,我们根据人类评委将它们标记为“N/A”(不适用)的频率来选择维度。高频表示该维度在不同的上下文中并不普遍适用。大多数维度不包含“N/A”评级,除了"Error recovery",有 25% 的时间被标记为“N/A”
**最终选择的维度有:**coherence, likability, and topic depth.
第二步:维度下的评测
文章的目标是在每个特定维度下,学习相应的评测函数。
在每个维度下,构建pair数据集,判断是good diagonal 还是 bad diagonal. 如果是good,则y越接近于1,如果是bad,则y越接近于-1.
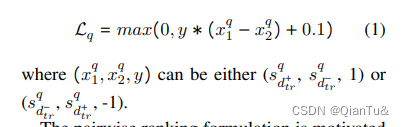
网络架构非常简单。 RoBERTa-base (Liu et al., 2019) 被用作文本编码器 T,它将 (d + tr, d − tr) 映射到密集表示 (H + tr, H − tr)。 d + tr 和 d − tr 都被制定为带有特殊 to ken “” 的标记序列来分隔不同的话语。接下来,将 (H + tr, H − tr) 转换为具有平均池化的向量表示 (h + tr, h − tr)。通过输出大小为 1 的线性层和 Sigmoid 激活函数,h + tr 和 h − tr 分别转换为标量值 s q d + tr 和 s q d − tr
2.1 每个维度下的采样策略
Coherence (Coh) :第一个是语句重排,将人-人之间的对话作为positive pairs,将随机采样的对话作为negative pairs。
第二个是问题问答,采用PLM下的QA模型,计算QA pairs的分值,将低于最低阈值的pairs作为negative pairs,将高于某个阈值的作为positive pairs。
Likability:第一个策略是contradiction scoring,采用预训练的自然语言推理 (NLI) 模型 为人与人对话中的相邻话语对提供矛盾分数(介于 0 和 1 之间)。对于包含 k 个话语的对话,我们有 k -1 个邻接对,因此有 k -1 个矛盾分数。对话级别的矛盾分数是通过计算 k-1 个分数的平均值得出的。最后,设置两个阈值 (τ contra low , τ contra high )。矛盾分数低于 τ contra low 的对话被认为是 d + tr,那些分数高于 τ contra high 的对话被认为是 d − tr。第二种策略是基于对话中带有积极情绪的话语的数量,我们假设这可以作为一个代理指标来衡量对话者有多喜欢彼此交谈。直觉上,如果用户觉得对话系统讨人喜欢,他们往往会做出更有吸引力的回应。为了实施该策略,我们采用了预训练的情感分类模型并将其应用于对 w.r.t 的情感进行分类。对话中的所有话语。我们将所有话语都被归类为积极类别的对话视为 d + tr,将包含少于两个积极话语的对话视为 d - tr。
Topic Depth (Top):对于包含 k 个话语的对话,使用预训练的 NLI 模型 为对话中的每个话语对提供蕴含分数。类似地,应用两个阈值(τ 需要低,τ 需要高)来获得正面和负面的对话。蕴涵分数低于 τ 的对话被认为是 d + tr,那些分数高于 τ 的对话被认为是高的。
2.2 问题:如何组合多个评测矩阵下的评测分值?——metric ensemble and multitask learning
Metric Ensemble:计算多个维度下的算数平均数作为最终评测分值。
Multitask Learning:采用硬参数共享网络来同时学习这三个任务。更具体地说,文本编码器 T 在三个任务之间共享。在 T 之上,有三个独立的线性层,输出大小为 1,分别作为连贯性、可爱性和主题深度的子指标
losses of three tasks are summed together, Ltotal =Lcoh + Llik + Ltop
在推理过程中,给定 dj ∈ D,FineD-Evalmu 从三个线性层分别输出三个标量值 s coh dj 、 slik dj 和 s top dj 。与met ric ensemble类似,最终的metric score 是通过取三个分数的算术平均值得出的