简介
分词器是es中的一个组件,通俗意义上理解,就是将一段文本按照一定的逻辑,分析成多个词语,同时对这些词语进行常规化的一种工具;ES会将text格式的字段按照分词器进行分词,并编排成倒排索引,正是因为如此,es的查询才如此之快。
一个analyzer即分析器,无论是内置的还是自定义的,只是一个包含character filters(字符过滤器)、 tokenizers(分词器)、token filters(令牌过滤器)三个细分模块的包。
看下这三个细分模块包的作用:
character filters(字符过滤器):分词之前的预处理,过滤无用字符
token filters(令牌过滤器):停用词、时态转换,大小写转换、同义词转换、语气词处理等。
tokenizers(分词器):切词
自定义分词器
先来看个自定义分词器,了解整个分析器analyzer的构造
PUT custom_analysis
{
"settings":{
"analysis":{ #分析配置,可以设置char_filter(字符过滤器)、filter(令牌过滤器)、tokenizer(分词器)、analyzer(分析器)
"char_filter": { # 字符过滤器配置
"my_char_filter":{ #定义一个字符过滤器:my_char_filter
"type":"mapping", # 字符过滤器类型:主要有三种:html_strip(标签过滤)、mapping(字符替换)、pattern_replace(正则匹配替换)
"mappings":[ # mapping的参数:表示 '&' 会被替换成 'and'
"& => and",
"| => or"
]
},
"html_strip_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"filter": { # 令牌过滤器配置
"my_stopword":{ # 定义一个令牌过滤器:my_stopword
"type":"stop", # 令牌过滤器类型:stop(停用(删除)词)
"stopwords":[ # stop的参数:表示这些词会被删除
"is",
"in",
"the",
"a",
"at",
"for"
]
}
},
"tokenizer": { # 分词器配置
"my_tokenizer":{ # 定义一个分词器my_tokenizer
"type":"pattern", # 分词器类型:pattern 正则匹配
"pattern":"[ ,.!?]" # pattern的参数:会根据这几个字符进行分割
}
},
"analyzer": { # 分析器:可以理解成组合了字符过滤器、令牌过滤器、分词器的一个整体。
"my_analyzer":{ #定义一个分析器:my_analyzer
"type":"custom",
"char_filter":["my_char_filter","html_strip_char_filter"], # 使用的字符过滤器
"filter":["my_stopword"], # 使用的令牌过滤器
"tokenizer":"my_tokenizer" # 使用的分词器
}
}
}
}
}
字符过滤器(character filters)
字符过滤器是分词之前的预处理,过滤无用字符,主要有这三种:html_strip、mapping、pattern_replace
html_strip
html_strip用于过滤html标签,它有个参数escaped_tags可以设置保留的标签
看下面例子
PUT index_html_strip
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "<p>要的话就<a>点击</a></p>"
}
结果:p标签过滤掉了,而a标签保留了

mapping
mapping是字符替换
看下面例子,可以设置一些敏感词替换成*
PUT index_mapping
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"mapping",
"mappings":[
"滚 => *",
"垃圾 => *",
"手枪 => *",
"你妈 => *"
]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET index_mapping/_analyze
{
"analyzer": "my_analyzer",
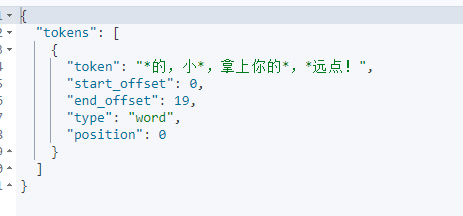
"text": "你妈的,小垃圾,拿上你的手枪,滚远点!"
}
结果:可以看到设置的敏感词被替换成*了
pattern_replace
pattern_replace是正则匹配替换
可以匹配手机号码,将中间四个数字加密处理
PUT index_pattern_replace
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"pattern_replace",
"pattern":"(\\d{3})\\d{4}(\\d{4})",
"replacement":"$1****$2"
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET index_pattern_replace/_analyze
{
"analyzer": "my_analyzer",
"text": "你的手机号是18814142694"
}
结果:

令牌过滤器(token filters)
停用词(stop)、大小写转换(lowercase)、同义词转换(synonym)等。
stop-停用词
停用词有个参数可以设置删除的词语:stopwords
PUT /index_stop
{
"settings": {
"analysis": {
"analyzer": {
"my_stop": {
"tokenizer": "whitespace",
"filter": [ "my_stop" ]
}
},
"filter": {
"my_stop": {
"type": "stop",
"stopwords": [
"is",
"in",
"the",
"a",
"at",
"for"
]
}
}
}
}
}
GET index_stop/_analyze
{
"analyzer": "my_stop",
"text": ["What is a apple?"]
}
结果:

synonym-同义词
同义词过滤器需要配置同义词的文件路径synonyms_path,需要放在项目目录下的config文件目录里
(本项目同义词文件完整路径:/app/elasticsearch-8.4.2/config/analysis/synonym.txt)
蒙丢丢 => 'DaB'
PUT /index_synonym
{
"settings": {
"analysis": {
"analyzer": {
"synonym": {
"tokenizer": "whitespace",
"filter": [ "synonym" ]
}
},
"filter": {
"synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
}
}
}
}
}
GET index_synonym/_analyze
{
"analyzer": "synonym",
"text": ["蒙丢丢"]
}
结果:

分词器(tokenizer)
分词器的作用就是用来切词的。
常见的分词器有:
standard:默认分词器,中文支持的不理想,会逐字拆分
pattern:以正则匹配分隔符,把文本拆分成若干词项
simple pattern:以正则匹配词项,速度比pattern tokenizer快
whitespace:以空白符分割
GET _analyze
{
"analyzer": "whitespace",
"text": ["What is a apple?"]
}
结果

中文分词器
ES的中文分词器需要下载插件安装使用的。
安装&部署
ik下载地址:GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.
点击Releases,选择版本下载

在根目录下的plugins文件夹下,创建ik文件目录,将下载的插件解压到ik目录下
ik配置文件说明
IKAnalyzer.cfg.xml:IK分词配置文件
main.dic:主词库:
stopword.dic:英文停用词,不会建立在倒排索引中
quantifier.dic:特殊词库:计量单位等
suffix.dic:特殊词库: 后级名
surname.dic: 特殊词库: 百家姓
preposition:特殊词库: 语气词
自定义词库:网络词汇、流行词、自造词等
重启ES
/app/elasticsearch-8.4.2/bin/elasticsearch -d /app/kibana-8.4.2/bin/kibana &
使用
GET _analyze
{
"analyzer": "ik_max_word", #中文分词器:ik_max_word
"text": ["今天真是美好的一天"]
}
结果
{
"tokens": [
{
"token": "今天",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "天真",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "真是",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "美好",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "的",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 4
},
{
"token": "一天",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 5
},
{
"token": "一",
"start_offset": 7,
"end_offset": 8,
"type": "TYPE_CNUM",
"position": 6
},
{
"token": "天",
"start_offset": 8,
"end_offset": 9,
"type": "COUNT",
"position": 7
}
]
}