前言:
一个成熟的符合一般人预想的资源监控平台应该是能够多维度的展示各种各样的数据,比如,服务器的内存使用率,磁盘io状态,磁盘使用率,CPU的负载状态,某个服务的状态(比如,MySQL数据库的使用情况)等等各类的资源使用实时情况,并通过多样的展示方式将以上这些数据展示出来,比如,直方图,饼状图等等形式。
那么,在某些时刻可能由于某些原因导致资源的使用超出了正常的使用范围,比如,某个服务器的某个分区可用率不足百分之20,亦或者某个服务器的CPU负载达到了50,亦或者某个服务器关机了,这个时候的服务器可能出现明显的卡顿了或者并不能正常工作了,这个时候就需要监控平台能够提供预警和告警服务,能够自动化的告诉管理人员:这个服务器有毛病了或者这个服务器即将出现问题了,请来看看是什么情况,而不是由管理人员无休止的反复人工巡检,从而发现问题并解决问题。很显然,Prometheus+Grafana这个组合是完全符合我们的预期的(酷炫多样的数据展示层面+自动化的监控预警和告警)。
OK,本文就将详细的讲述如何安装部署Prometheus的套件之一alertmanager-0.24.0,在服务器的内存使用率高于75%,磁盘使用率高于80%,或者服务器关机的情况下,向指定的服务器管理人员发送告警信息到电子邮件或者发送告警信息到企业微信内。
一,
邮箱设置
接收告警信息的邮箱设置邮箱需要开启POP3/SMTP服务,否则将不能发送告警邮件到指定邮箱,这里以QQ邮箱为例(其它邮箱,比如163,129等等基本都一样的)
登录网页版邮箱:
设置 ------- 账户


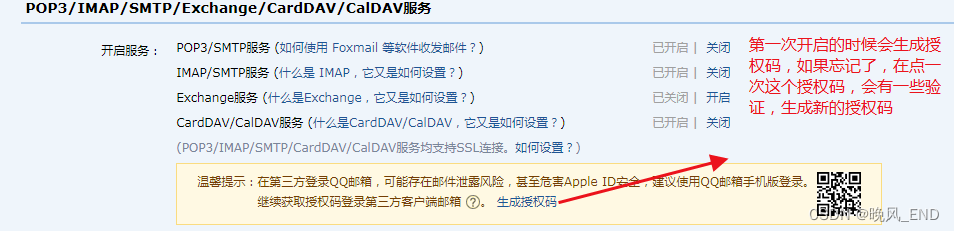
生成的授权码位数是16位,如果不想每次都点击生成授权码,建议保存到某个地方。 保证POP3/SMTP服务状态是开启的就可以了,后面将会把授权码填入到altermanager的配置文件内。
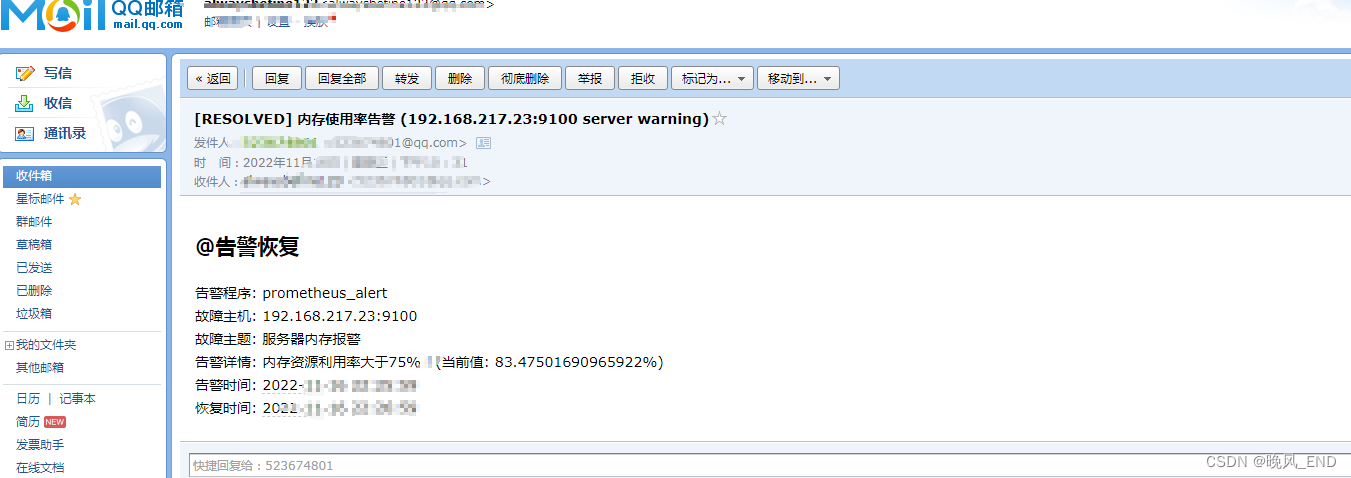
接收到的告警邮件示例:
二,
企业微信的设置
注册企业微信,注册完成后,点击应用管理->应用->创建应用

按照要求创建应用后,点击创建的应用就能看到我们的应用id和秘钥,这两个信息很重要,后面在prometheus中会用到

获取需要接收告警的部门或组ID,注意ID为1,表示整个公司,慎用!

添加的应用中需要设置告警可见范围,把需要接收告警的群组添加进去,不然告警会一直无法接受到

三,
安装部署alermanager
安装部署alermanager是在前面的文章Linux|centos二进制方式安装系统和网络监控神器prometheus+grafana(装逼神器它来了)_晚风_END的博客-CSDN博客
的基础上做的,为防止部分同学看不懂下面的安装,请先移步上面的文章在开始下面的步骤。
Download | Prometheus 下载alertmanager-0.24.0.linux-amd64.tar.gz,并将此文件传到服务器192.168.217.24上,解压后移动到指定位置:
tar zxf alertmanager-0.24.0.linux-amd64.tar.gz
mv alertmanager-0.24.0.linux-amd64 /opt/alertmanager告警管理器和节点信息收集器等等其它组件是十分类似的,因此,编写一个启停脚本:
cat >/usr/lib/systemd/system/alertmanager.service <<EOF
[Unit]
Description=alertmanager server daemon
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
ExecStart=/opt/alertmanager/alertmanager --config.file=/opt/alertmanager/alertmanager.yml --storage.path=/opt/alertmanager/data
ExecReload=/bin/kill -HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
EOF它的配置文件还没有修改,现在都是默认的,显然是不合适的,因此,修改它的配置文件:
cat >/opt/alertmanager/alertmanager.yml <<EOF
global:
resolve_timeout: 5m # 超时,默认5min
smtp_smarthost: 'smtp.qq.com:465' # 这里为 QQ 邮箱 SMTP 服务地址,官方地址为 smtp.qq.com 端口为 465 或 587,同时要设置开启 POP3/SMTP 服务。
smtp_from: '1234567@qq.com'
smtp_auth_username: '1234567@qq.com'
smtp_auth_password: 'glmzqwkcszrmbhjj' # 这里为第三方登录 QQ 邮箱的授权码,非 QQ 账户登录密码,否则会报错,获取方式在 QQ 邮箱服务端设置开启 POP3/SMTP 服务时会提示。
smtp_require_tls: false # 是否使用 tls
templates: # # 模板
- '/opt/alertmanager/alert.tmp' #这个文件主要是定义发送的邮件的格式
route:
group_by: ['alertname'] #分组依据,
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'email' #所有告警先找总路由,这段是接收人,是电子邮件。
continue: true # 如果是true则还需要去匹配子路由,一般为true,这样告警会更精确
routes: # 子路由,子路由可以定义多个
- receiver: 'wechat'
match: # 通过标签去匹配这次告警是否符合这个路由节点;也可以使用 match_re 进行正则匹配
severity: Disaster #如果告警级别是严重危害,那么,接收人是微信
# 定义了3个接收人
receivers: # 配置报警信息接收者信息。
- name: 'email' # 警报接收者名称
email_configs:#邮件配置,这里一般是固定格式
- to: '{{ template "email.to 1"}}' # 接收警报的email(这里是引用模板文件中定义的变量)
html: '{{ template "email.to.html" .}}' # 发送邮件的内容(调用模板文件中的)
# headers: { Subject: " {{ .CommonLabels.instance }} {{ .CommonAnnotations.summary }}" } # 邮件标题,不设定使用默认的即可
send_resolved: true # 故障恢复后是否通知,true是通知,也就是如果恢复了在发一个邮件
- name: 'wechat' #可以有多个警报接收人,这个是微信
wechat_configs: #微信配置,这里一般是固定的格式
- corp_id: wxe76c451b5fad6871 # 企业信息("我的企业"--->"CorpID"[在底部])
to_user: '@all' # 发送给企业微信用户的ID,这里是所有人
agent_id: 1000012 # 企业微信("企业应用"-->"自定应用"[Prometheus]--> "AgentId")
api_secret: AETETGEFGdwawb_ku0NblxKFrrmMwbLIZ7YxMa5rCg8g # 企业微信("企业应用"-->"自定应用"[Prometheus]--> "Secret")
message: '{{ template "email.to.html" .}}' # 发送内容(调用模板)
send_resolved: true # 故障恢复后通知,true是通知,也就是如果恢复了在发一个邮件
- name: 'receiver-01'
email_configs:
- to: '{{ template "email.to 2"}}' # 接收警报的email(这里是引用模板文件中定义的变量)
html: '{{ template "email.to.html" .}}' # 发送邮件的内容(调用模板文件中的)
# headers: { Subject: " {{ .CommonLabels.instance }} {{ .CommonAnnotations.summary }}" } # 邮件标题,不设定使用默认的即可
send_resolved: true # 故障恢复后是否通知,true是通知,也就是如果恢复了在发一个邮件
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
EOF以上配置文件的解读:
定义的告警级别有:warning,critical,Disaster,当然这些告警级别是由Prometheus的规则文件制定。
定义有三个联系人,分别是email,wechat,receiver-01
当告警级别是Disaster的时候,告警发送给定义的三个联系人里的微信,是其它级别时发送给三个联系人里的邮件,是warning级别的时候不发送。
主要有五个字段
- global:全局配置
resolve_timeout:告警恢复超时时间,当接收的告警没有EndsAt字段时,经过该时间就将该告警标志为已解决,prometheus上用不上,告警都会带EndsAt字段
电子邮件发件人的相关信息配置
- route:告警分配配置
group_by:设置分组标签,告警时出现的labels都可用于分组,如果需要对所有不同label都分组,可以使用’…’
group_wait:告警发送等待时间,时间拉长便于告警聚合
group_interval:前后两组告警发送间隔时间repeat_interval:重复告警发送间隔时间
- 定义模板路径
- receiver:定义接收告警的对象
name:告警接收名称,与route中的receiver一一对应,这里我们配置的是企业微信
corp_id: 企业微信唯一ID,我的企业 -> 企业信息
to_party: 告警需要发送的组
agent_id: 自己创建应用的ID,自己创建的应用详情页面查看
api_secret: 自己创建应用的密钥,自己创建的应用详情页面查看
send_resolved: 告警解决是否发送通知
- inhibit_rules:告警抑制规则
当新的告警匹配到target_match规则,而已发送告警满足source_match规则,并且新告警与已发送告警中equal定义的标签完全相同,则抑制这个新的告警。
根据以上配置文件,可以看到我们还需要一个模板文件/opt/alertmanager/alert.tmp:
from 是发件人,上面的配置文件配置了的,这个不更改,to是收件人,可以定义多个,例如,我这定义了1和2两个收件人,在上面的配置文件中更改对应的告警接收人即可。
cat >/opt/alertmanager/alert.tmp <<EOF
{{ define "email.from" }}12345671@qq.com{{ end }}
{{ define "email.to 1" }}12345671@qq.com{{ end }}
{{ define "email.to 2" }}12345672@qq.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }}<br>
故障主题: {{ .Annotations.summary }}<br>
告警详情: {{ .Annotations.description }}<br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}<br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
EOF7好了,配置文件什么的都准备好了,那么,就可以启动服务了:
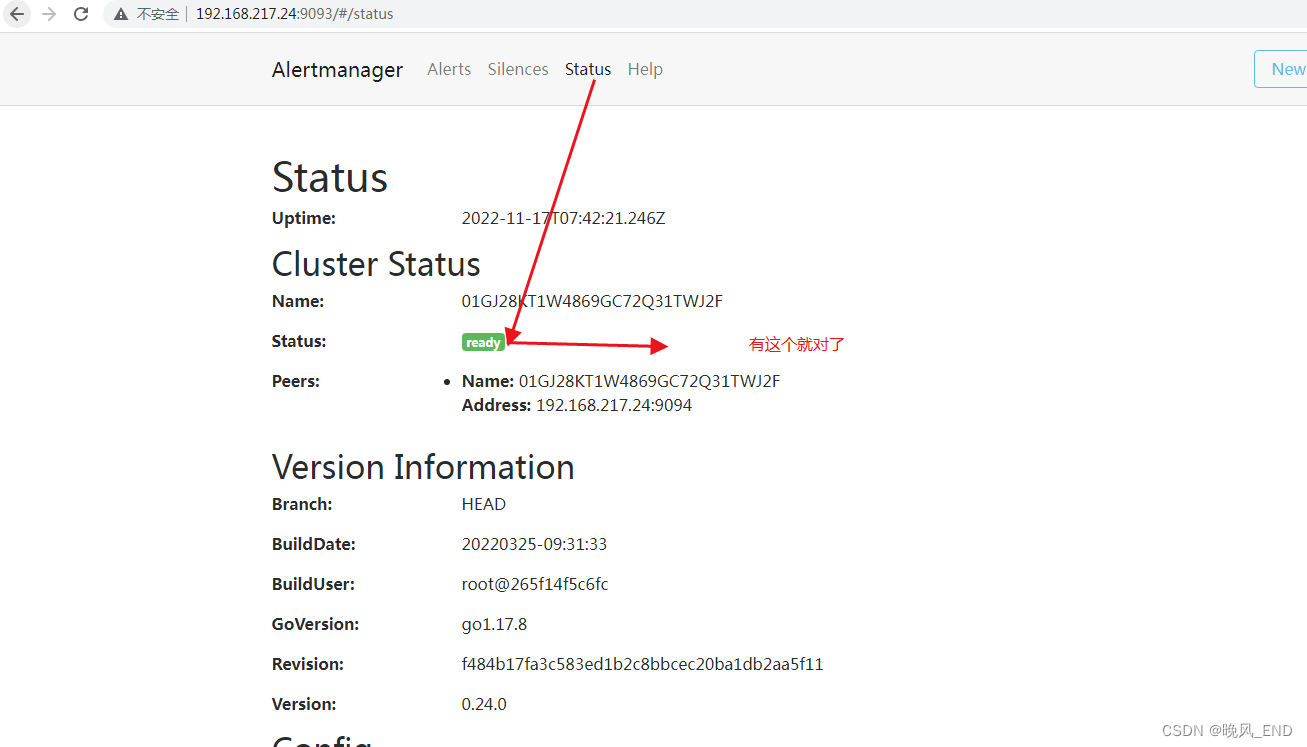
systemctl daemon-reload && systemclt start alertmanager && systemctl enable alertmanager打开浏览器,输入192.168.217.24:9093 即可进入alertmanager的简单管理页面:
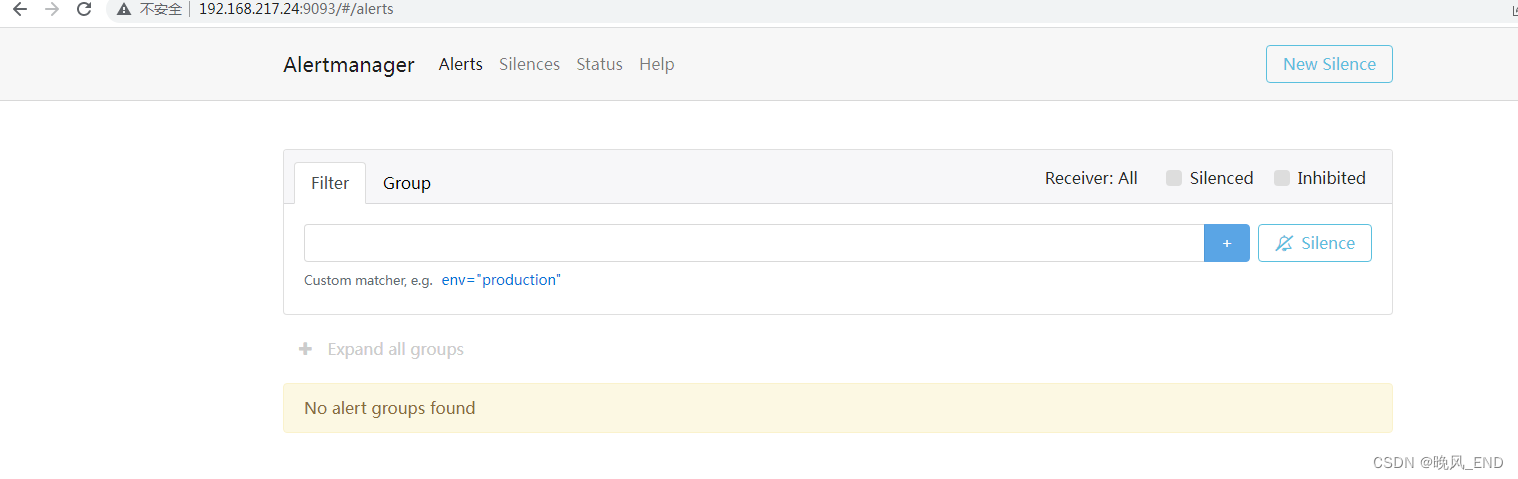
此时的alert是没有的,因为还没有和Prometheus关联,也没有配置报警规则:
四,
alertmanager和Prometheus关联:
cat >/usr/local/prometheus/prometheus.yml <<EOF
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.217.24:9093 #这一段是新增的
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/rules/*.yml" #这一段新增的,所有规则文件放一个目录下,便于管理
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.217.24:9090"]
- job_name: "server"
static_configs:
- targets: ["192.168.217.24:9100"]
- targets: ["192.168.217.23:9100"]
- job_name: "mysqld"
static_configs:
- targets: ["192.168.217.23:9104"]
- job_name: "alertmanager_test" # 同时添加对alertmanager的监控
static_configs:
- targets: ["192.168.217.24:9093"] #这一段新增的
EOF
根据以上配置文件,我们需要编写一个规则文件,因此,执行如下命令:
mkdir /usr/local/prometheus/rules/cat >/usr/local/prometheus/rules/node_alerts.yml<<EOF
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警 # 告警规则的名称(alertname)
expr: up == 0 # expr 是计算公式,up指标可以获取到当前所有运行的Exporter实例以及其状态,即告警阈值为up==0
for: 30s # for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。(for 表示告警持续的时长,若持续时长小于该时间就不发给alertmanager了,大于该时间再发。for的值不要小于prometheus中的scrape_interval,例如scrape_interval为30s,for为15s,如果触发告警规则,则再经过for时长后也一定会告警,这是因为最新的度量指标还没有拉取,在15s时仍会用原来值进行计算。另外,要注意的是只有在第一次触发告警时才会等待(for)时长。)
labels: # labels语句允许指定额外的标签列表,把它们附加在告警上。
severity: Disaster #告警级别,这个标签alertmanager要读取的。决定了告警的处理方式
annotations: # annotations语句指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
summary: "节点失联" #注解,也算是一种说明,解释说明规则用的
description: "节点断联已超过1分钟!"#注解,也算是一种说明,解释说明规则用的
- name: 内存告警规则
rules:
- alert: "内存使用率告警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 75 # 告警阈值为当内存使用率大于75%,这个是promsql语句
for: 30s
labels:
severity: warning#告警级别,这个标签alertmanager要读取的。决定了告警的处理方式
annotations:
summary: "服务器内存报警"
description: "内存资源利用率大于75%!(当前值: {{ $value }}%)"
- name: 磁盘报警规则
rules:
- alert: 磁盘使用率告警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80 # 告警阈值为某个挂载点使用大于80%,这个是promsql语句
for: 1m
labels:
severity: warning #告警级别,这个标签alertmanager要读取的。决定了告警的处理方式
annotations:
summary: "服务器 磁盘报警"
description: "服务器磁盘设备使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
EOF重启Prometheus server:
systemctl restart prometheus打开Prometheus的管理界面,点击Alerts,正常的话应该可以看到如下界面:
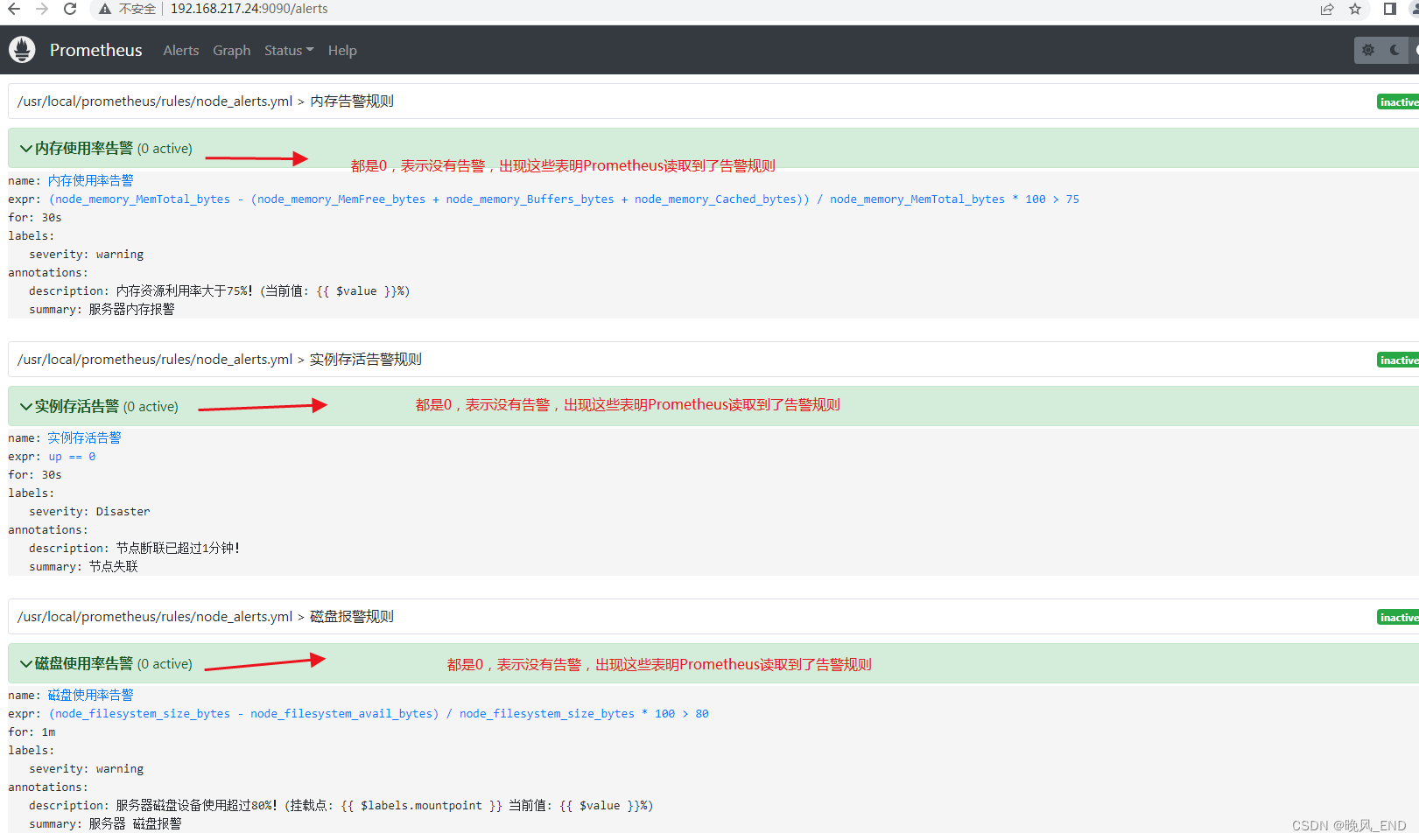
OK,现在报警监控模块就部署完成了,下面将就以上配置文件做一个系统的说明,接着测试以上告警设置,看看能不能正常的告警。
五,
配置文件说明:
告警流程:
Prometheus发出告警时分为两个部分。Prometheus服务器按告警规则(rule_files配置块)将警报发送到Alertmanager(即告警规则是在Prometheus上定义的)。然后,由Alertmanager 来管理这些警报,包括去重(Deduplicating)、分组(Grouping)、沉默(silencing),抑制(inhibition),聚合(aggregation),最终通过电子邮件发出通知,对呼叫通知系统,以及即时通讯平台,将告警通知路由(route)给对应的联系人。
设置警报和通知的主要步骤是:
- 设置和配置 Alertmanager
- 配置Prometheus与Alertmanager对话
- 在Prometheus中创建警报规则
从以上流程可以得出,alertmanager的配置文件主要是邮件配置,告警路由,抑制策略这些作用和一个告警模板文件。解决的问题是:什么样的警告需要报告(有点严重的警告需要报告吗?非常严重的警告类型报告吗?等等此类问题),向谁报告(发邮件还是微信,钉钉?通知谁?同事A还是同事B),报告什么(模板文件就是内容),怎么报告(出现警报就报还是稍等,重复类型的警报是否抑制扩散,广播等等类似的问题)
Prometheus的告警相关配置文件主要是一个告警规则文件。解决的问题是:如何判断警告的等级。
总结一下,告警系统主要是需要配置四个文件,每个配置文件的作用是不一样的同时又有紧密的联系。
六,
测试环节
打开Prometheus的管理界面,进入图表界面:

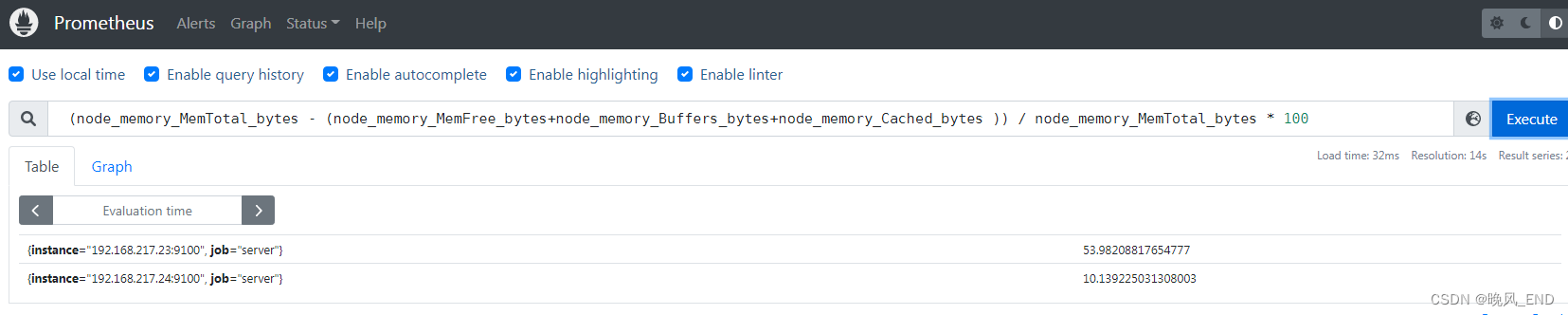
下面这个图表示该规则的作用范围,192.168.217.23和24都匹配了,并且显示了实时的内存使用率:
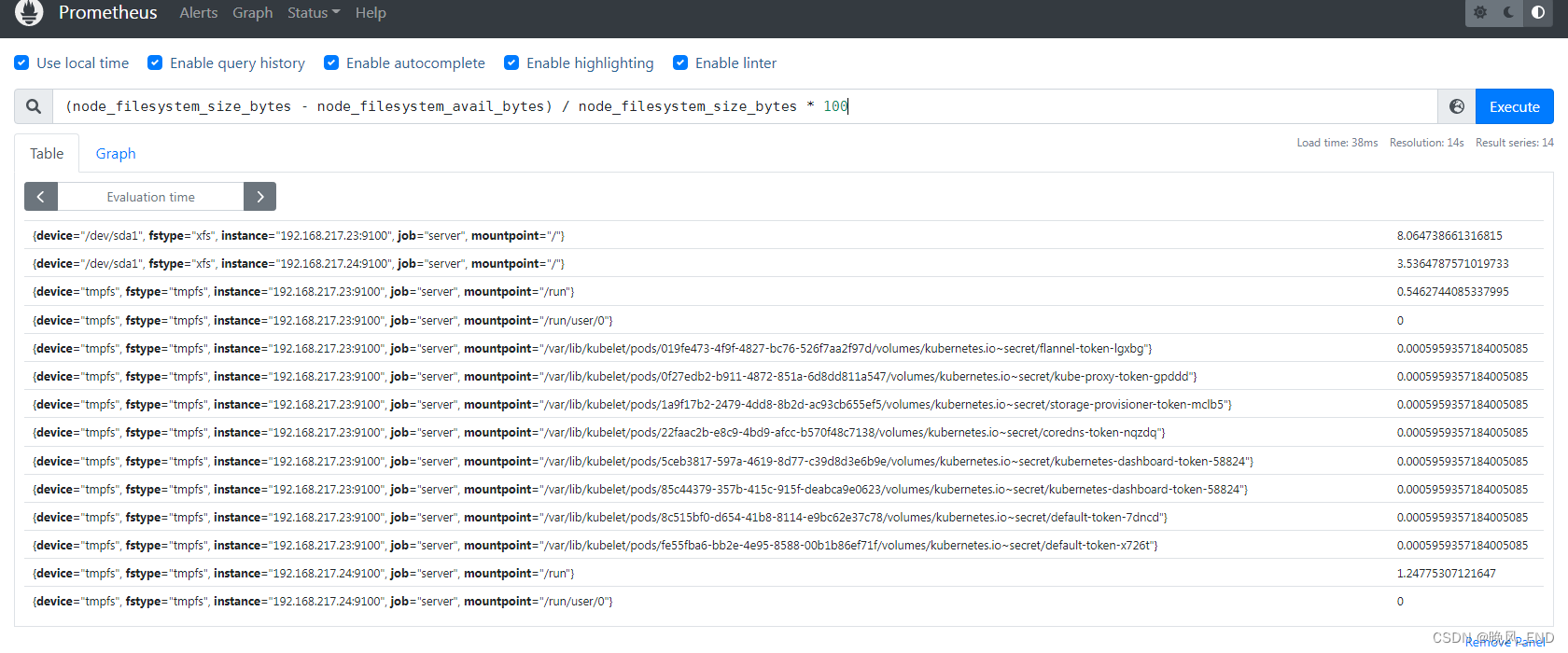
 下图显示了23和24的所有分区的磁盘使用率,规则匹配的范围是符合预期的:
下图显示了23和24的所有分区的磁盘使用率,规则匹配的范围是符合预期的:
以上查询出的23服务器的内存使用率是百分之54左右,而规则指定的告警阈值是百分之75,因此,我们使用压测工具暂时提升内存使用率到百分之85左右:
3个400M的内存占用(stress安装命令为:yum install stress -y)
root@node3 ~]# stress --vm 3 --vm-bytes 400M --vm-keep
stress: info: [22598] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd
浏览器打开Prometheus的管理界面,选择Alerts标签,可以看到有一个pengding的告警,内存使用率达到了83.24419137066073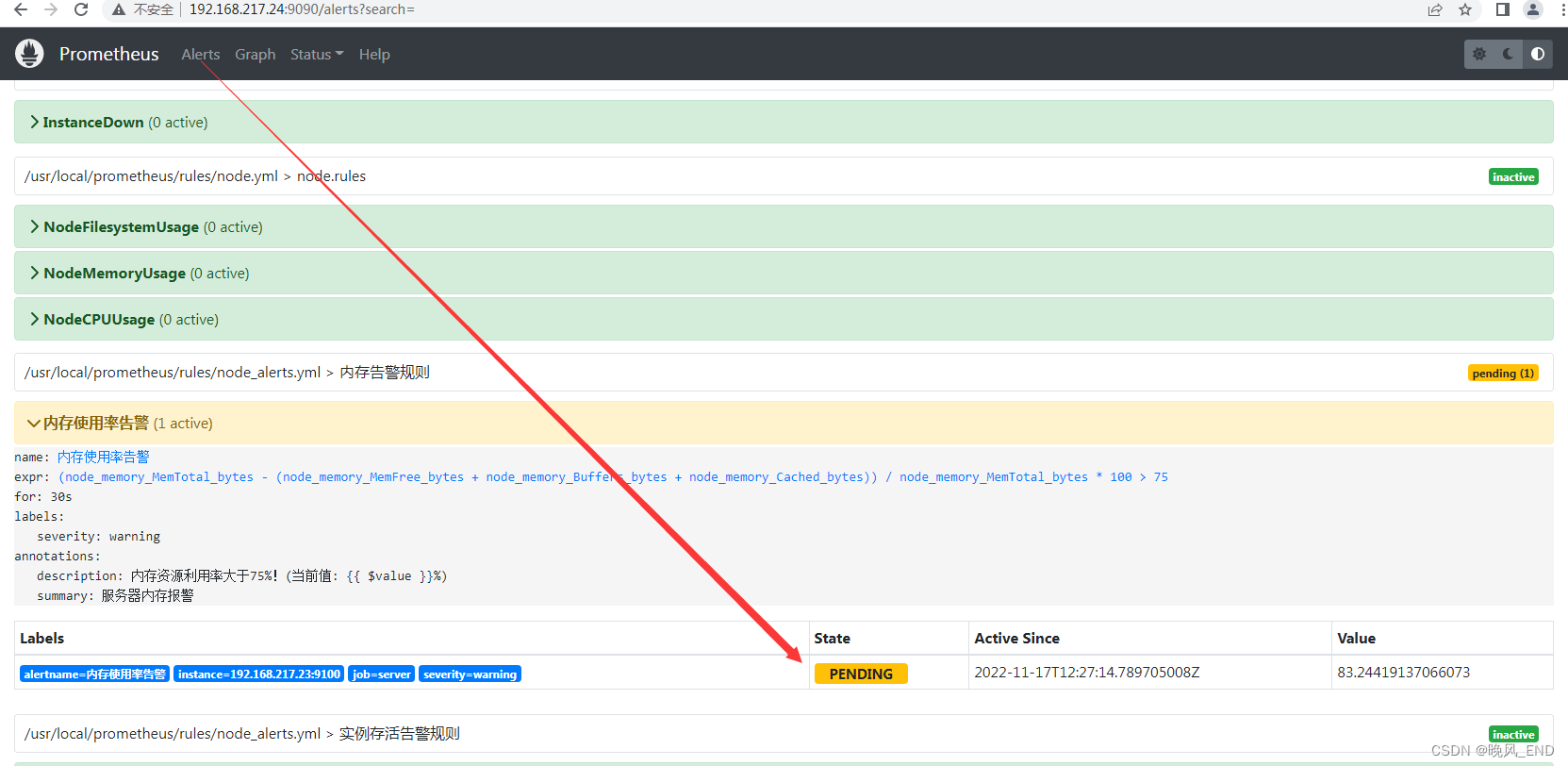
稍等一会,大概30秒左右此告警状态就变为了firing(开火),在查看QQ邮箱,可以看到收到了告警邮件:

停止压测工具stress后,又会收到一个恢复的邮件。这里注意一点,不要用Prometheus server所在的服务器做压测,要不管理界面都会打不开的哦,因此,压测工作是在23服务器做的哦。
磁盘占用率这些测试使用dd命令就可以了,这里我就不演示了,前面的PromQL语句已经验证是没有问题的了。
当然了,微信这些如果填写准确,也是肯定可以接收到告警的,也不在此演示了。




![[搞点好玩的] JETSONNANO 受苦记 -- 001 (布置环境,未完待续)](https://img-blog.csdnimg.cn/747b2a70c9db481e91fa7d01e1cf7b37.png)