修改表中的数据:update[DML]
语法格式:
update 表名 set 字段名1=值1,字段名2=值2,字段名3=值3......where 条件;
注意:没有条件限制会导致所有数据全部更新
举例:
- 将id号为10的学生的姓名改变为"jason",年龄改变为10岁,生日改变为2000-10-10
update student set name='jason',age=10,birth='2000-10-10' where id=10;
注意:日期的格式在输入时,必须按照MySQL默认的格式来写
删除数据:delete[DML]
语法格式:
delete from 表名 where 条件;
注意:如果没有条件限制,整张表的数据会全部被删除
举例:
-- 删除student表中id为2的这条记录
delete from student from id=2;
-- 删除student表中的所有数据
delete from student;
上述这种删除数据的方式:执行效率比较慢,表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放,因此它支持回滚,可以通过rollback;命令恢复删除的数据;
truncate语句:[DDL]
删除数据的效率比较高,表被一次截断,数据在硬盘上的真实存储空间也会得到释放,但是它并不支持回滚,数据一旦被删除就无法恢复
语法:
truncate table 表名;
上述所说的delete和truncate,都是删除表中的数据,而表结构并没有被删除
drop table 表名; //删除表,将表中的数据连同表结构一起删除
插入数据:insert[DML]
语法格式:
插入单条数据:
insert into 表名(字段1,字段2,字段3....)values(值1,值2,值3......);
插入多条数据:
语法格式:
insert into 表名(字段1,字段2,字段3....) values (值1,值2,值3......),(值1,值2,值3......),(值1,值2,值3......).....;
快速创建表:
语法格式:
-- 将as后的查询结果当做要创建的新表
create table 表名 as select.....;
这可以完成表的快速复制,表在创建的瞬间,表中的数据也存在了
将查询结果插入到一张表当中:
-- 将select语句的查询结果插入到student表中
insert into student select......;
约束:
在创建表的时候,,我们可以给表中的字段增加一些约束,来保证这个表中数据完整性,有效性
非空约束:not null
举例:
当我们在创建表的时候,对于名字字段增加了约束条件不能为空,因此,当给该表插入数据时,名字部分的数据不能是空的
注:该约束只有列级约束,并没有表级约束
create table teacher(
id int,
name varchar(255) not null);
小tip:xxxx.sql这种文件被称为sql脚本文件
sql脚本文件中编写了大量的sql语句,当我们执行sql脚本文件时,该文件中所有的sql语句都会被执行,如果想要批量的执行sql脚本文件,那么在MySQL中可通过source D:\course\03-Mysql\document\xxx.sql命令
唯一性约束:unique
唯一性约束的字段不能重复,但是可以为null
举例:
当我们在创建表的时候,对于id字段增加了约束条件不能为空,因此,当给该表插入数据时,id字段的数据不能重复
create table person(
id int unique,
age int,
);
两个字段联合起来具有唯一性:
假设我们要求表中的name和email联合起来具有唯一性:
错误写法:
create table t_vip(
id int,
name varchar(255) unique, //约束添加到某个字段后面的约束属于列级约束
name varchar(255) unique,
);
上述这种创建表是不符合我们的需求的,因为这样创建出来的表的含义是:email具有唯一性,name具有唯一性。
那么对于下面将要插入表中的两组数据来说,并不能成功插入,原因是名字字段重复了。
但是我们的需求是email+name联合具有唯一性即可,也就是说下面的两组数据,虽然名字字段重复,但是email字段并不重复,所以它们联合起来也是不重复的,理论上应该是可以插入数据的,因此上述这种创建表的方式 是错误的。
insert into t_vip(id,name,email) values(1,'张三','zhangsan@123.com');
insert into t_vip(id,name,email) values(1,'张三','zhangsan@sina.com');
正确写法:
create table t_vip(
id int,
name varchar(255),
name varchar(255),
unique(name,email), //这种没有添加到某个列级后面的约束属于表级约束
);
此时才表示email+name唯一
当多个字段联合起来需要添加约束时,适用表级约束,单个字段需要添加约束,适用列级约束
not null和unique联合使用:
举例:
create table t_vip(
id int,
name varchar(255) not null unique //表示name字段既不能为空,也不能重复
);
我们查看t_vip表结构,发现name字段变成了主键。
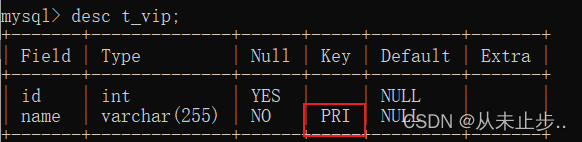
在MySQL中,如果一个字段同时被not null和unique约束的话,该字段自动变成主键字段(注:在Oracle中并非如此)
主键约束:primary key(简称PK)
主键值是每一行记录的唯一标识,相当于人类的“身份证号”
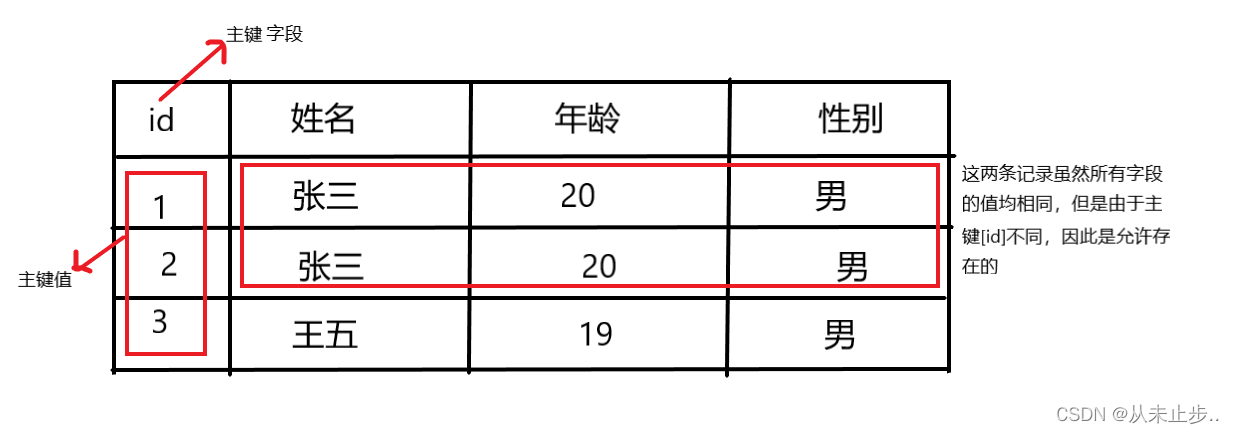
任何一张表都应该有主键,没有主键的表是无效的
主键的特征:not null+unique[主键值不能是null,同时也不能重复]
单一主键
给表添加主键约束:
使用列级添加主键约束:

使用表级添加主键约束:
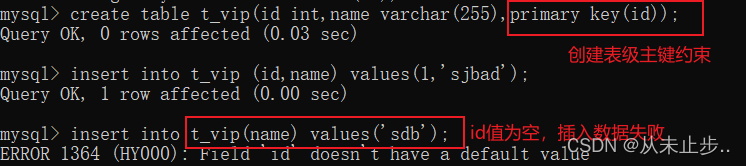
复合主键
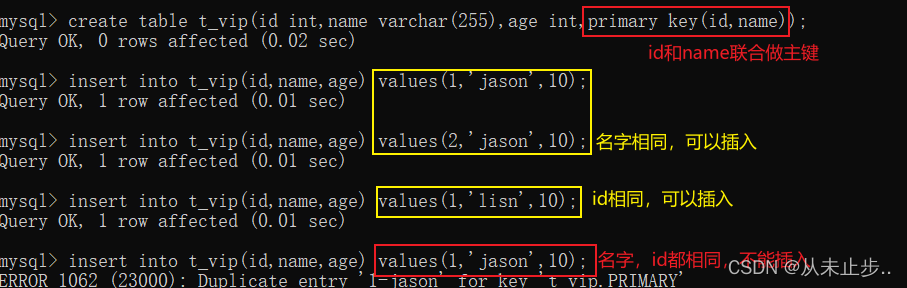
在实际开发中,不建议使用复合主键,因为本身主键存在的意义就是作为某条记录的唯一标识,单一主键能够达到该效果
列级主键约束只能添加一个:

主键值的类型建议使用:int,bigint,char等类型,不建议使用:varchar来做主键,主键值一般都是数字,是定长的。
对于主键的类型,除了我们上文提到的单一主键和复合主键之外,我们还可以将主键分为自然主键和业务主键。
自然主键:主键值是一个自然数,和业务没有关系
业务主键:主键值和业务密切相关,例如:拿银行卡账号做主键
在实际开发中,自然主键使用的会比较多一些,因为主键只要做到不重复就行,不需要有意义,业务主键不太好,因为主键一旦和业务挂钩,那么当业务发生变动时,可能会影响主键的值,所以业务主键不是我们所推荐的。
主键自增机制:
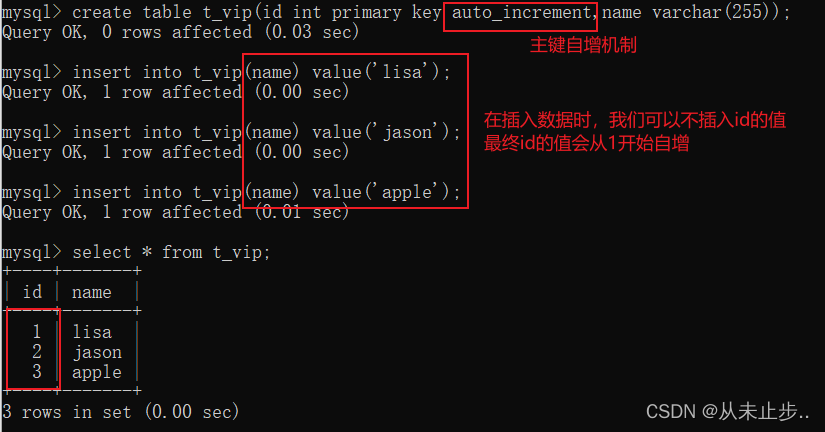
外键约束:foreign key(简称FK)
业务背景:请设计数据库表,来描述"班级和学生"的信息
第一种方案:班级和学生存储在一张表中
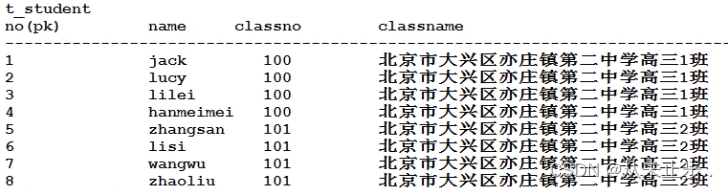
这种存储数据的缺点是:数据冗余,空间浪费
第二种方案:班级一张表,学生一张表
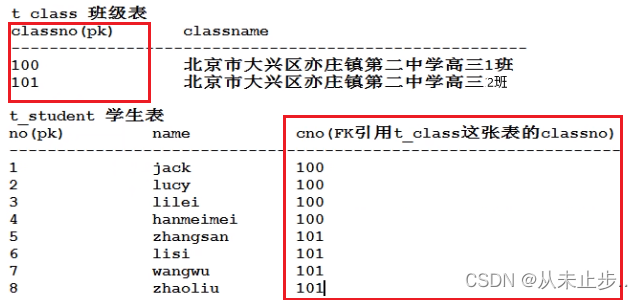
当t_student表中的cno字段没有任何约束的时候,可能会导致数据无效,会出现除了t_class表中,当前存在的100/101以外的其他数字,所以为了保证cno字段中的值都是100和101,需要给cno字段添加外键约束,那么cno字段就是外键字段,cno字段中的每一个值都是外键值。
t_class是父表,t_student是子表:
删除表的顺序:先删子表,再删父表
若先删除父表,那么子表将会受到影响,因为它参照了父表中的很多数据
创建表的顺序:先创建父表,再创建子表
父表中的某些数据是子表建立的基础,因此,需要先建立父表
删除数据的顺序:先删除子表,再删除父表
如果先删除父表,那么子表将会不完整,因为它还在使用父表的数据
插入数据的顺序:先插入父表,再插入子表
子表需要使用父表的数据,因此没有父表,子表中的数据就是不完整的
举例:

子表中的外键引用的父表中的某个字段,被引用的这个字段不要求必须是主键,但是必须具有唯一性
子表中的外键是可以为空的
检查约束:check(MySQL不支持,Oracle支持)
存储引擎的使用:
存储引擎是MySQL中特有的一个术语,其他数据库中没有(Oracle中有,但是并不叫存储引擎),它实际上是一个表存储/组织数据的方式,不同的存储引擎,表存储数据的方式不同
数据库中的各表均被[在创建表时]指定的存储引擎来处理,服务器可用的引擎依赖于以下因素:
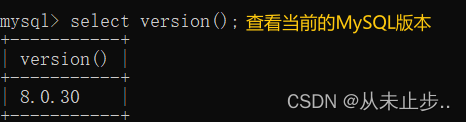
MySQL的版本
服务器在开发时如何被配置
启动选项
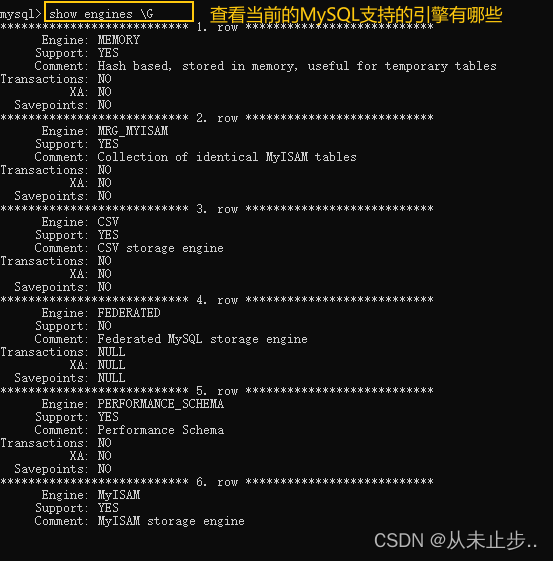
为了解当前服务器中有哪些存储引擎可用,可使用show engines命令
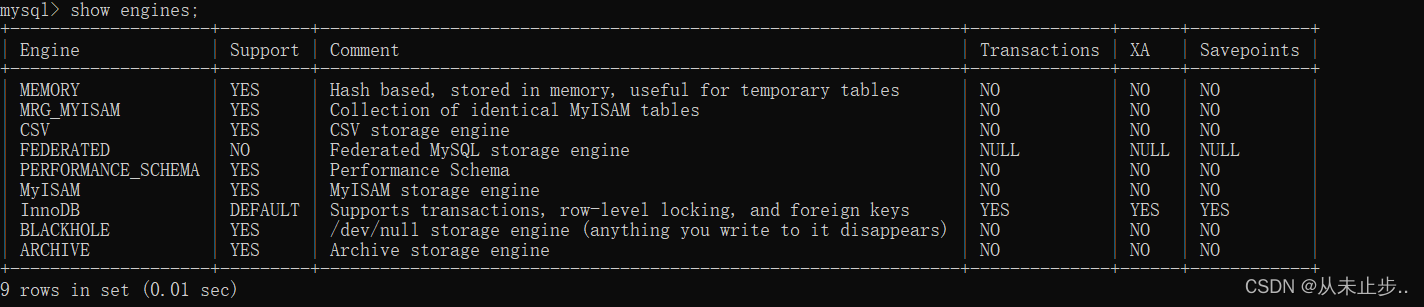
在建表时,指定引擎:
使用show create table 表名命令,可查看该表的结构数据:
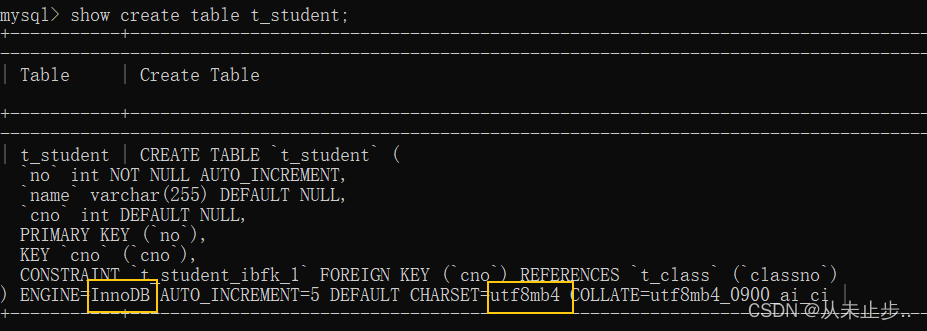
MySQL默认的存储引擎是:InnoDB
MySQL默认的字符编码方式是:utf8
在建表时,设置存储引擎和字符编码方式:

查看当前MySQL支持的引擎有哪些:
查看当前的MySQL版本:
MyISAM存储引擎是MySQL最常用的引擎:
它管理的表具有以下特征:
使用三个文件表示每个表:
格式文件-存储表结构的定义(mytable.fm)
数据文件-存储表行的内容(mytable.MYD)
索引文件-存储表上索引(mytable.MYI):相当于目录---缩小扫描范围,提升查询效率
灵活的AUTO_INCREMENT字段处理
MyISAM存储引擎的存储优势:可被转换为压缩,只读表来节省空间
MyISAM存储引擎的存储劣势:不支持事务,安全性较低
InnoDB存储引擎:
这是MySQL默认的存储引擎, InnoDB支持事务,支持数据库崩溃后自动恢复机制,非常安全是它最大的一个特点。
它管理的表具有下列主要特征:
每个 InnoDB表在数据库目录中以.frm格式文件表示
InnoDB表空间tablespace被用于存储表的内容(表空间是一个逻辑名称,表空间存储数据+索引)
提供一组用来记录事务性活动的日志文件
用commit(提交),savepoint及rollback(回滚)支持事务处理
提供全acid兼容
在MySQL服务器崩溃后提供自动恢复
多版本(MVCC)和行级锁定
支持外键及引用的完整性,包括联级删除和更新
InnoDB最大的特点就是支持事务:以保证数据的安全,效率不是很高,并且也不能压缩,不能转换为只读,不能很好地节省存储空间
MEMORY存储引擎:
使用MEMORY存储引擎的表,其数据存储在内存中,且行的长度固定,这两个特点使得MEMORY存储引擎非常快
MEMORY存储引擎管理的表具有以下特征:
在数据库目录内,每个表均以.frm格式的文件表示
表数据及索引被存储在内存中
表级锁机制
不能包含TEXT或BLOB字段
MEMORY存储引擎之前被称为HEAP引擎
MEMORY存储引擎优点:查询效率是最高的
MEMORY存储引擎缺点:不安全,关机之后数据消失,因为数据和索引都是在内存当中






![移动Web【空间转换[空间位移、透视、空间旋转、立体呈现、3D导航、空间缩放]、动画、综合案例】](https://img-blog.csdnimg.cn/801a522e3c5c46b996b659934d9665af.png)