资源出处:初学者的 TensorFlow 2.0 教程 | TensorFlow Core (google.cn)
前言
对于新框架的学习,阅读官方文档是一种非常有效的方法。官方文档通常提供了关于框架的详细信息、使用方法和示例代码,可以帮助你快速了解和掌握框架的使用。
如果你提到的Jupyter笔记本格式的教程无法在国内运行,你可以尝试其他方式来学习框架。以下是一些建议:
一、针对新手的demo
初学者的 TensorFlow 2.0 教程 | TensorFlow Corehttps://tensorflow.google.cn/tutorials/quickstart/beginner?hl=zh_cn1. 下载并安装 TensorFlow 2.0 测试版包。将 TensorFlow 载入你的程序:
# 安装 TensorFlow
import tensorflow as tf2. 载入并准备好 Keras自带的MNIST 数据集。将样本从整数转换为浮点数:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.03. 将模型的各层堆叠起来,以搭建 tf.keras.Sequential 模型。为训练选择优化器和损失函数:
model = tf.keras.models.Sequential([ # 定义模型网络结构
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', # 定义模型优化器
loss='sparse_categorical_crossentropy', # 定义模型loss函数
metrics=['accuracy']) # 定义模型的指标4. 训练并验证模型:
model.fit(x_train, y_train, epochs=5) # 5轮
model.evaluate(x_test, y_test, verbose=2)5. 训练结果:

现在,这个照片分类器的准确度已经达到 0.9778!!!
二、进阶demo
针对专业人员的 TensorFlow 2.0 入门 | TensorFlow Corehttps://tensorflow.google.cn/tutorials/quickstart/advanced?hl=zh_cn
1. 注意在TensorFlow中,tensor的通道排序和pytorch有所不同。
1)TensorFlow tensor: [batch, height, width, channel]
2)Pytorch tensor: [batch,channel, height, width]
2. 这个demo分为model.py和train.py两个脚本。
3.使用mnist数据集,是一个识别人手写的数据集。
大概就是这样: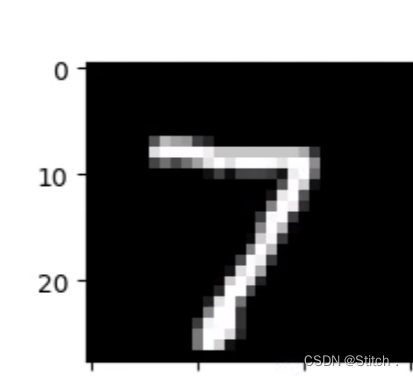
2.1 model.py
1. 模型的搭建风格
使用Model Subclassing API,类似于pytorch的一种风格。
2. 先看一下import
我们自己构造的MyModel继承了keras的Model类
搭建网络用的Dense、Flatten、Conv2D函数来自keras的layers类
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model3. 搭建
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu') # 卷积层
self.flatten = Flatten() # 展平
self.d1 = Dense(128, activation='relu') # 全连接层
self.d2 = Dense(10) # 全连接层
# 定义网络正向传播的过程
def call(self, x):
x = self.conv1(x) # input[batch,28,28,1] ouput[batch,26,26,32]
x = self.flatten(x) # output[batch,21632]
x = self.d1(x) # output[batch,128]
return self.d2(x) # output[batch,10]1)super函数:避免多继承带来的问题
2)Conv2D函数,我们来看一下它的参数
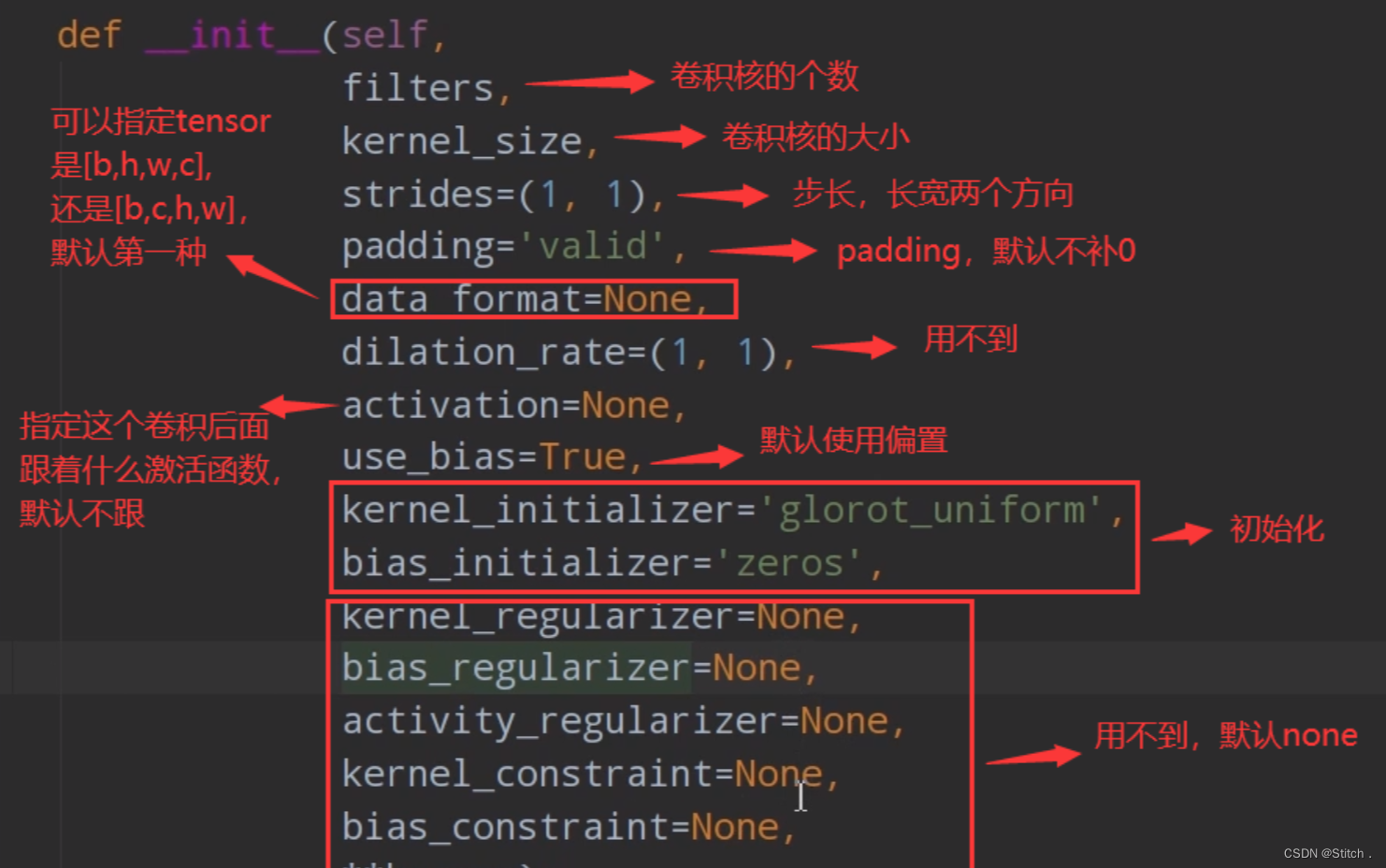
这里要注意padding的使用方式和pytorch不同。padding参数由两种值“valid”和“same”。默认“valid”。valid表示不需要补0,same表示需要补0.。输出图片大小的计算公式如下:

3)Faltten函数:展平。因为要和后面的全连接层进行连接,所以要展成一维向量的形式。
4)Dense函数的参数,比较重要的就是前两个参数 。还有一点需要注意,最后一个全连接层的节点数等于我们的分类数。因为mnist数据集的分类数是10,所以,规定最后一个全连接层的节点数为10。并且最后一个全连接层跟着的激活函数为“softmax”,最终softmax给出的就是属于每个类别的概率分布了。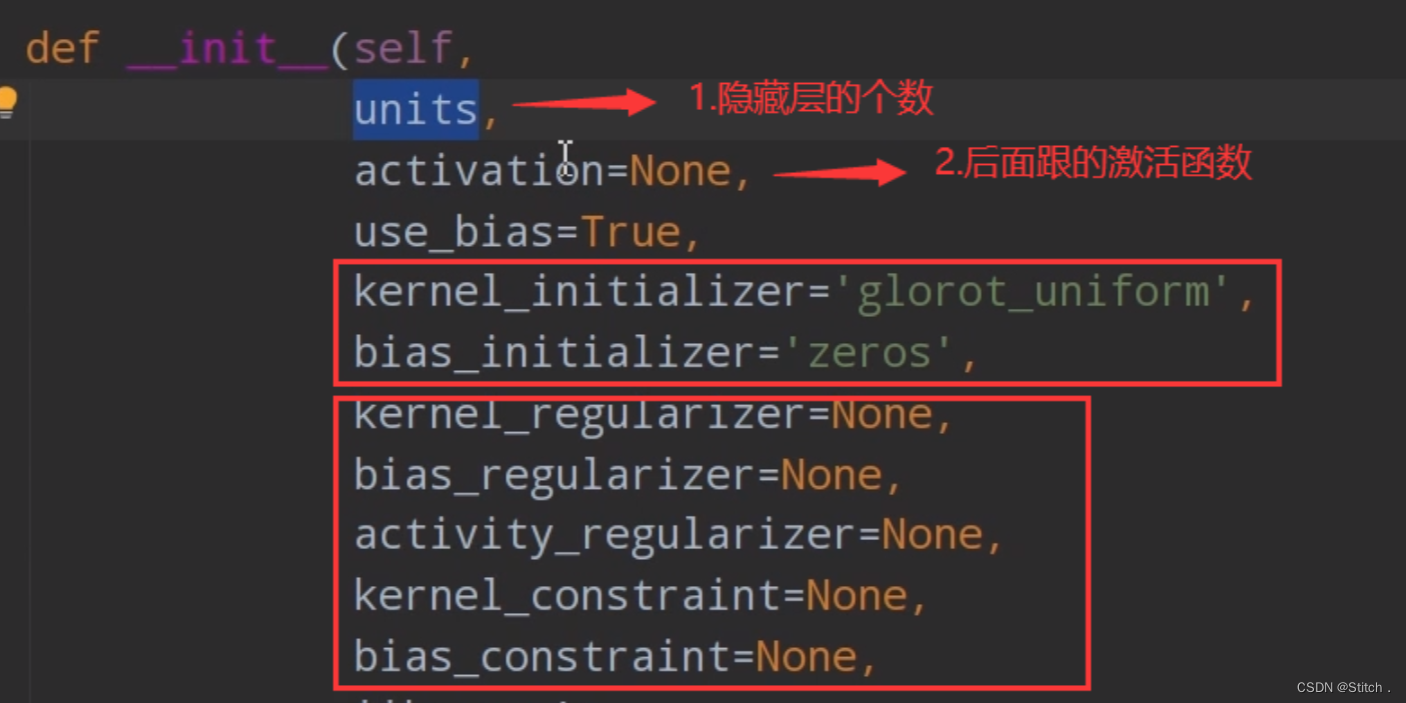
5)和pytorch的另一个区别:上面用到的Conv2D、Dense、Faltten函数的参数中没有指定input是什么。因为TensorFlow会自动进行推理,这也是TensorFlow的强大之处。
6)再来看张量在这个网络中的变化情况。首先,输入进去的图片大小是28×28×1的,经过卷积层后,用上面的padding公式去计算,输出是26×26×32(通道数32是我们指定的)的;然后经过展平操作,batch数不变,图片变成1维向量,26×26×32=21632个值;输入到结点个数为128的全连接层,得到128个值的一维向量;最后,输入到结点个数为10的全连接层,得到10个值的一维向量。
2.2 train.py
2.2 tensorflow2官方demo_哔哩哔哩_bilibiliTensorflow2官方demo,手写数字的识别, 视频播放量 57662、弹幕量 151、点赞数 661、投硬币枚数 619、收藏人数 352、转发人数 91, 视频作者 霹雳吧啦Wz, 作者简介 学习学习。。。,相关视频:深度学习在图像处理中的应用(tensorflow、pytorch分别实现),PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】,5.2 使用pytorch搭建GoogLeNet网络,4.2 使用pytorch搭建VGG网络,在Pytorch中使用Tensorboard可视化训练过程,6.1.2 ResNeXt网络结构,5.1 GoogLeNet网络详解,[双语字幕]吴恩达深度学习deeplearning.ai,1.2 卷积神经网络基础补充,15.1 MobileViT网络讲解https://www.bilibili.com/video/BV1n7411T7o6?spm_id_from=333.999.0.0模型的搭建步骤遵循这篇博客:Tensorflow1.0 和 Tensorflow2.0之间的区别-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/134923567?spm=1001.2014.3001.5501
2.2.1 准备输入数据
1. 导入输入模块和数据集
一共有60000张灰度图。
import tensorflow as tf
from model import MyModel
# ketas自带的数据集
mnist = tf.keras.datasets.mnist
# 下载数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0默认下载到了C盘用户文件夹下的.keras目录下。
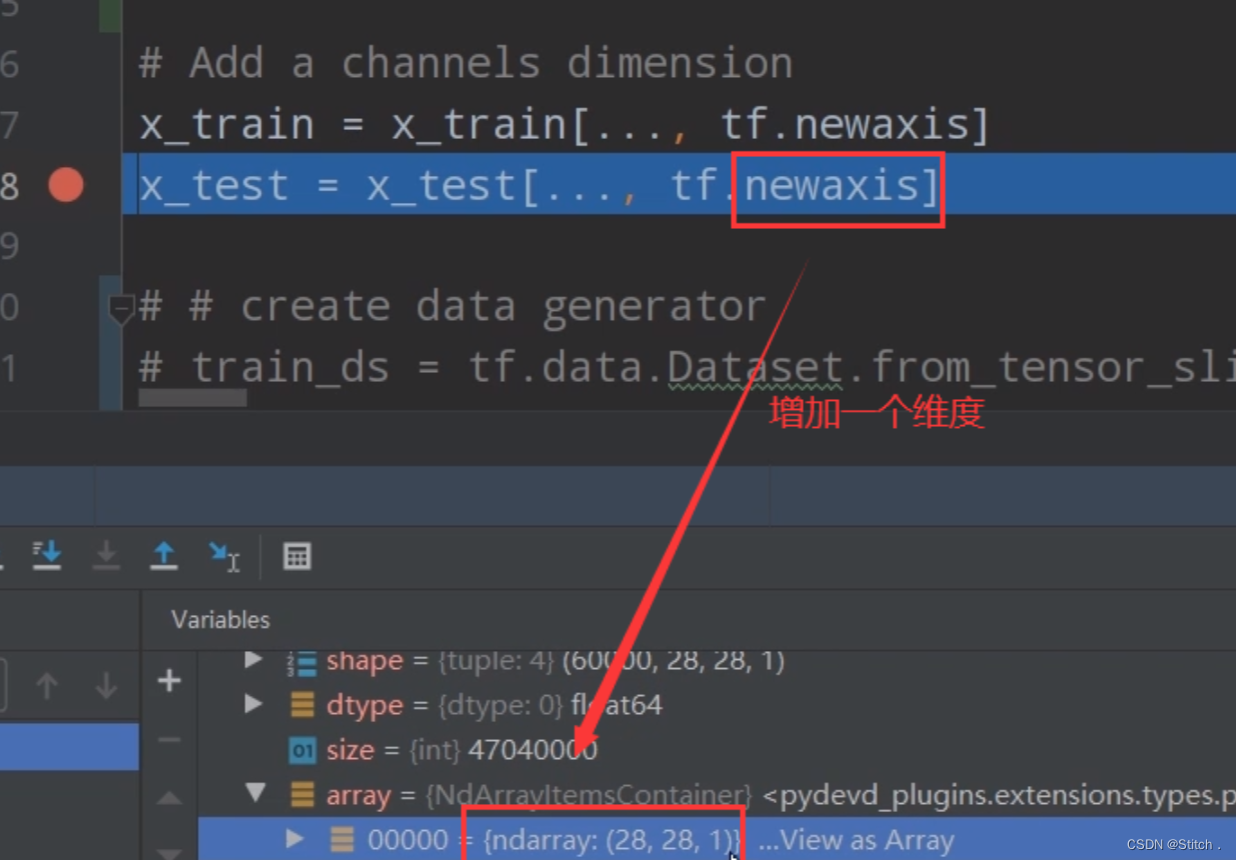
2. 加入通道数这一维度
# Add a channels dimension
x_train = x_train[..., tf.newaxis].astype("float32")
x_test = x_test[..., tf.newaxis].astype("float32")从mnist导入的数据集是28×28的灰度图,通过下图加断点的方式可以看到:
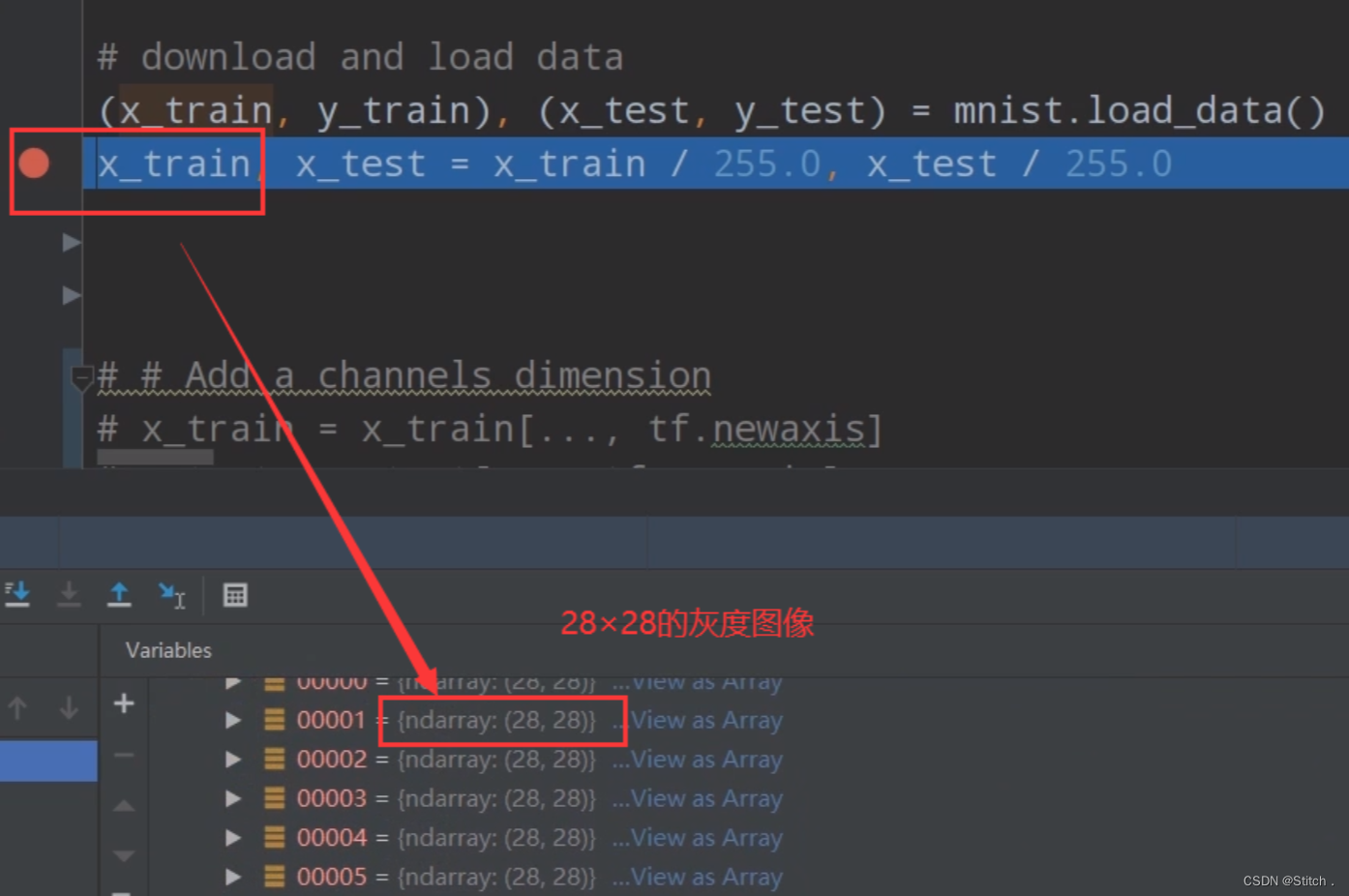
增加一个维度后,我们再通过加断点的方式来查看一下,数据集变成了28×28×1的格式
3. 构造数据生成器
构造训练集和测试集的数据生成器:
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)1)调用TensorFlow的from_tensor_slices函数:把数据x_train和标签y_train合并为元祖的方式作为输入。
2)shuffle函数:每次从硬盘中导入10000张图片到内存(训练集一共有60000张),进行随机洗牌打乱顺序,保证数据的随机性。理论上来说,括号内的取值越接近训练集的总数越贴近随机采样(越好),但是内存不允许。
3)batch函数:32张图作为一个batch。
2.2.2 搭建模型
实例化一个我们的模型
# Create an instance of the model
model = MyModel()2.2.3 定义损失函数及优化器
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam()2.2.4 传参计算model()
1. 定义历史平均loss和历史平均精确率。
他们在 每个epoch上累计值,然后打印出一个epoch累计的结果。便于一轮一轮地观察训练情况。
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')2. 训练模型函数
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
# training=True is only needed if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(images, training=True)
loss = loss_object(labels, predictions) # 一张图的loss
# 得到误差梯度(将loss反向传播到model.trainable_variables模型每一个可训练的参数中
gradients = tape.gradient(loss, model.trainable_variables)
# 使用误差梯度更新模型参数
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss) # 历史平均loss,全局变量(再次进入函数后在上一次结果的基础上变)
train_accuracy(labels, predictions) # 历史平均准确率1)tf.GradientTape:与pytorch不同,pytorch会自动跟踪每一个训练参数的误差梯度,而TensorFlow不会。 在这里使用tf.GradientTape函数去记,返回tape。
2)tape.gradient函数:将loss反向传播到模型每一个可训练的参数中(model.trainable_variables),最终得到误差梯度
3)优化器Adam的apply_gradients函数:将误差梯度和模型的所有可训练参数用Zip函数打包成元祖,作为函数的输入。使用误差梯度更新模型参数。
4)最后两行是用来计算历史平均loss和历史平均准确率。根据后面将要讲的“清零”代码,可以看出,计算的是一个epoch的历史平均loss和历史平均准确率。
5)tf.function修饰器:用来将修饰的函数转化成图结构,那么以后这个函数内就不能加断点了,但是会大大提升训练的效率。
3. 测试模型函数
@tf.function
def test_step(images, labels):
# training=False is only needed if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(images, training=False)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)4. 开始跑训练及测试
EPOCHS = 5
for epoch in range(EPOCHS):
# Reset the metrics at the start of the next epoch
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
# 从训练数据生成器中取数据,训练
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
print(
f'Epoch {epoch + 1}, '
f'Loss: {train_loss.result()}, '
f'Accuracy: {train_accuracy.result() * 100}, '
f'Test Loss: {test_loss.result()}, '
f'Test Accuracy: {test_accuracy.result() * 100}'
)1)reset_states函数:每一轮都把tf.keras.metrics(训练loss、训练准确率、测试loss、测试准确率)清零。这样才不影响下一轮的训练。
2)result函数:获取tf.keras.metrics(训练loss、训练准确率、测试loss、测试准确率)的结果
2.3 运行结果
Epoch 1, Loss: 0.13267311453819275, Accuracy: 96.02333068847656, Test Loss: 0.061965566128492355, Test Accuracy: 98.06999969482422
Epoch 2, Loss: 0.042059458792209625, Accuracy: 98.72000122070312, Test Loss: 0.048135414719581604, Test Accuracy: 98.3499984741211
Epoch 3, Loss: 0.023382706567645073, Accuracy: 99.24333190917969, Test Loss: 0.05048979073762894, Test Accuracy: 98.3499984741211
Epoch 4, Loss: 0.01350458711385727, Accuracy: 99.57333374023438, Test Loss: 0.0620846264064312, Test Accuracy: 98.25
Epoch 5, Loss: 0.009131859056651592, Accuracy: 99.69999694824219, Test Loss: 0.06238056719303131, Test Accuracy: 98.33999633789062官网原文:(仅供参考)
![]()
1、在 Google Colab 中运行https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/zh-cn/tutorials/quickstart/beginner.ipynb?hl=zh-cn
| 在 GitHub 查看源代码https://github.com/tensorflow/docs-l10n/blob/master/site/zh-cn/tutorials/quickstart/beginner.ipynb |
此简短介
此简短介绍使用 Keras 进行以下操作:
- 加载一个预构建的数据集。
- 构建对图像进行分类的神经网络机器学习模型。
- 训练此神经网络。
- 评估模型的准确率。
这是一个 Google Colaboratory 笔记本文件。 Python程序可以直接在浏览器中运行,这是学习 Tensorflow 的绝佳方式。想要学习该教程,请点击此页面顶部的按钮,在Google Colab中运行笔记本。
- 在 Colab中, 连接到Python运行环境: 在菜单条的右上方, 选择 CONNECT。
- 运行所有的代码块: 选择 Runtime > Run all。
设置 TensorFlow
首先将 TensorFlow 导入到您的程序:
import tensorflow as tf2023-11-01 06:25:27.904924: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2023-11-01 06:25:28.630454: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvrtc.so.11.1: cannot open shared object file: No such file or directory 2023-11-01 06:25:28.630689: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvrtc.so.11.1: cannot open shared object file: No such file or directory 2023-11-01 06:25:28.630701: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
如果您在自己的开发环境而不是 Colab 中操作,请参阅设置 TensorFlow 以进行开发的安装指南。
注:如果您使用自己的开发环境,请确保您已升级到最新的 pip 以安装 TensorFlow 2 软件包。有关详情,请参阅安装指南。
加载数据集
加载并准备 MNIST 数据集。将样本数据从整数转换为浮点数:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0构建机器学习模型
通过堆叠层来构建 tf.keras.Sequential 模型。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])对于每个样本,模型都会返回一个包含 logits 或 log-odds 分数的向量,每个类一个。
predictions = model(x_train[:1]).numpy()
predictionsarray([[-0.5549733 , -0.178904 , 0.2521443 , -0.20637012, 0.24012126,
-0.09939454, -0.43023387, 0.45244563, 0.37959167, -0.43027684]],
dtype=float32)
tf.nn.softmax 函数将这些 logits 转换为每个类的概率:
tf.nn.softmax(predictions).numpy()
array([[0.0572833 , 0.08343588, 0.12839696, 0.0811754 , 0.12686247,
0.09034067, 0.06489357, 0.15687165, 0.1458493 , 0.06489078]],
dtype=float32)
注:可以将 tf.nn.softmax 烘焙到网络最后一层的激活函数中。虽然这可以使模型输出更易解释,但不建议使用这种方式,因为在使用 softmax 输出时不可能为所有模型提供精确且数值稳定的损失计算。
使用 losses.SparseCategoricalCrossentropy 为训练定义损失函数,它会接受 logits 向量和 True 索引,并为每个样本返回一个标量损失。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
此损失等于 true 类的负对数概率:如果模型确定类正确,则损失为零。
这个未经训练的模型给出的概率接近随机(每个类为 1/10),因此初始损失应该接近 -tf.math.log(1/10) ~= 2.3。
loss_fn(y_train[:1], predictions).numpy()
2.4041677
在开始训练之前,使用 Keras Model.compile 配置和编译模型。将 optimizer 类设置为 adam,将 loss 设置为您之前定义的 loss_fn 函数,并通过将 metrics 参数设置为 accuracy 来指定要为模型评估的指标。
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
训练并评估模型
使用 Model.fit 方法调整您的模型参数并最小化损失:
model.fit(x_train, y_train, epochs=5)
Epoch 1/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2982 - accuracy: 0.9140 Epoch 2/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.1422 - accuracy: 0.9573 Epoch 3/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.1080 - accuracy: 0.9668 Epoch 4/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0857 - accuracy: 0.9732 Epoch 5/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0754 - accuracy: 0.9759 <keras.callbacks.History at 0x7fcad46da820>
Model.evaluate 方法通常在 "Validation-set" 或 "Test-set" 上检查模型性能。
model.evaluate(x_test, y_test, verbose=2)
313/313 - 1s - loss: 0.0674 - accuracy: 0.9791 - 588ms/epoch - 2ms/step [0.06739047914743423, 0.9790999889373779]
现在,这个照片分类器的准确度已经达到 98%。想要了解更多,请阅读 TensorFlow 教程。
如果您想让模型返回概率,可以封装经过训练的模型,并将 softmax 附加到该模型:
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])
probability_model(x_test[:5])
<tf.Tensor: shape=(5, 10), dtype=float32, numpy=
array([[5.22209795e-08, 2.41216696e-07, 1.94858385e-05, 6.03494642e-04,
3.63586158e-12, 1.27487894e-07, 2.75295411e-12, 9.99375284e-01,
3.34941291e-07, 1.01254307e-06],
[1.27781030e-09, 5.08851197e-04, 9.99486089e-01, 1.27736268e-06,
1.16675265e-17, 2.87630655e-06, 3.99693533e-07, 1.31204751e-14,
4.28570189e-07, 8.51850329e-13],
[8.57534303e-07, 9.99213696e-01, 5.82170615e-05, 2.93258381e-06,
2.00496142e-05, 8.48563104e-06, 1.34474585e-05, 5.36364911e-04,
1.44018544e-04, 2.03336299e-06],
[9.97936487e-01, 3.06930929e-07, 9.99198644e-04, 2.78684138e-06,
4.31515036e-06, 3.91961257e-05, 8.49796401e-04, 1.12621237e-04,
4.11850197e-05, 1.40180309e-05],
[4.24850878e-05, 1.55146904e-06, 2.20226084e-05, 7.31444686e-07,
9.98439252e-01, 7.06452113e-07, 8.66830524e-05, 1.98422102e-04,
2.75226976e-05, 1.18070992e-03]], dtype=float32)>
结论
恭喜!您已经利用 Keras API 借助预构建数据集训练了一个机器学习模型。
有关使用 Keras 的更多示例,请查阅教程。要详细了解如何使用 Keras 构建模型,请阅读指南。如果您想详细了解如何加载和准备数据,请参阅有关图像数据加载或 CSV 数据加载的教程。