Ascend C Tilling计算
Tilling基本概念介绍
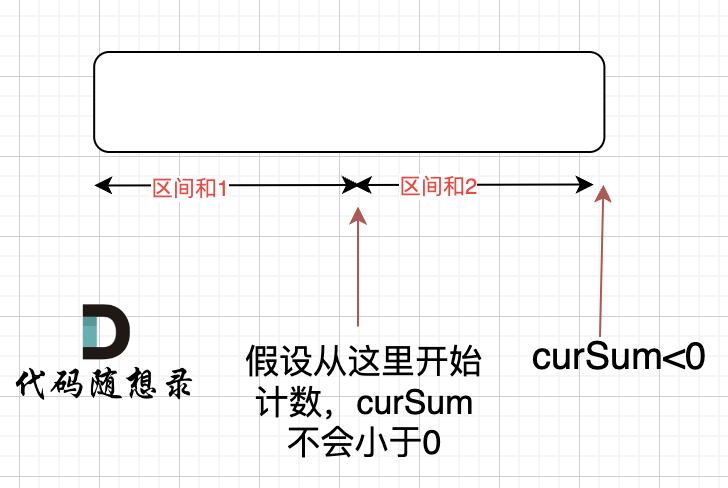
大多数情况下,Local Memory的存储,无法完全容纳算子的输入与输出的所有数据,需要每次搬运一部分输入数柜进行计算然后搬出,再敲运下一部分输入数据进行计算,直到得到完愁的最终结果,这个数据切分、分块计算的过程称之为Tiling过程
- 每次激运的那一部分数据块,叫做Tiling块
- 根据算子中不同输入形状确定搬入基本块大小的相关算法,叫做Tiling算法(或Tiing策略)
- 算子中实现Tiling算法的函数(一般定义在host侧的tiling头文件中),叫做Tiling函数 (或Tiling Function)
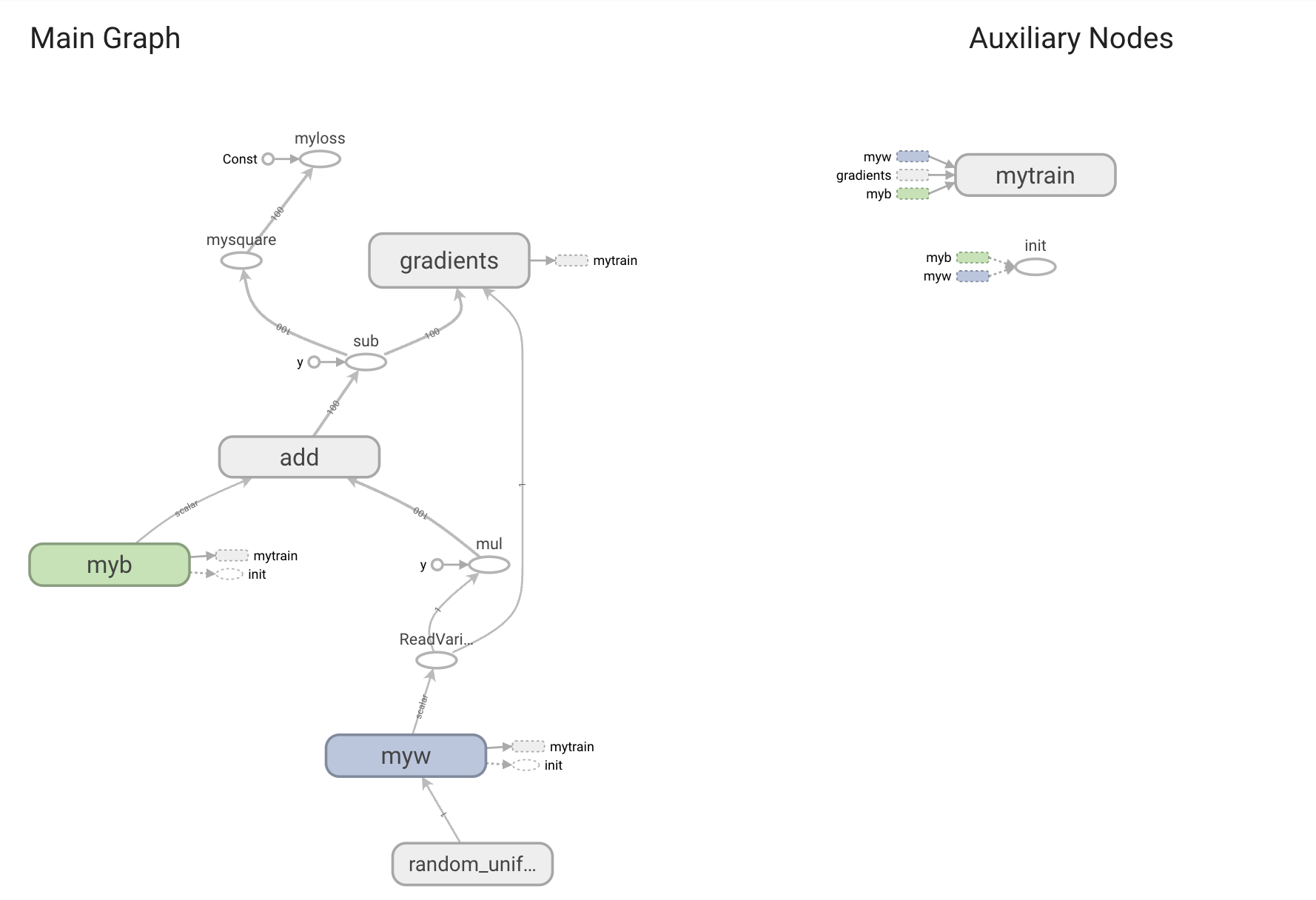
在Ascend c中,Tiling的直接表示形式就是结构体 (struct),简称Tiling结构体
Tiling结构体定义在Tiling头文件中,其中的每个结构体参数表示如何对输入数据进行切分,以及决定了计算过程的一些细节,结构体在host侧实例化,并通过指针传入kernel函数中
__global__aicore__void add_custom(GM_ADDR_X,GM_ADDR_Y,GM_ADDR_Z,GM_ADDR workspace,GM_ADDR tiling)
Tiling结构体中的值在host侧确定,根据具体入参的信息,完成各项结构体参数的计算,并实施搬运分别在host侧和device侧为Tiling结构体申请空间,将其从host侧搬运到device侧,H2D操作
- aclrtMallocHost((void**)(&tilingHost),tilingsize)
- acIrtMalloc((void**)&tilingDevice,tilingSize,ACL_MEM_MALLOC_HUGE_FIRST)
- aclrtMemcpy(tilingDevice, tilingsize, tilingHost, tilingsize, ACL_MEMCPY_HOST_TO_DEVICE)
固定Shape场景的tiling实现
固定shape输入回顾
由于输入的大小是已知的,每次搬运多少数据,总共搬运多少次均可以在编译时直接计算出来
当算子shape固定时,开发者使用不同shape时需要重新对算子进行编译,带来大量的算子二进制文件
动态shape的算子可以将形状通过核函数的入参传入核函数内,参与内部逻辑计算,从而符合不同shape下的使用场景

改装固定shape算子成功态shape
基于现有的固定shape算子,将其改装为动态shape的算子,将控制形状的BLOCK_DIM,TOTAL_LENGTH,TILE_NUM这些变量的来源变化为依靠外界输入得到,在核函数中额外传入一个tiling,它将指向控制核函数逻辑处理的至关重要的几个变量

动态shape场景的tiling结构体
主要操作流程:

Tiling结构体中的信息:
TOTAL_LENGTH: 总共需要计算的数据个数
TILE_NUM:每个核上计算数据分块的个数
注:USE_CORE_NUM为参与并行计算使用的核数,有独立接口GetBlockNum()可以在核函数内获得
动态shape场景的tiling解析函数
核函数传入Tiling指针,与x,y,z的角色相同,添加获得tiling结构体的宏函数调用GET_TILING_DATA

CPU模式和NPU模式涉及到指针转化,用宏函数 CONVERT_TILING_DATA 将__ubuf_uint8 t* 转化为__ubuf__tilingstruct*
CPU模式和NPU模式之间逻辑的区别,用宏函数INIT_TILING_DATA区分tiling_data不同的初始化过程
为了方便而不失一般性,这里使用宏函数GET_TILING_DATA暴露给核函数进行调用
Ascend C算子调试
CPU和NPU孪生调试
通过Ascend C算子孪生调试技术,充分发挥CPU和NPU的调测优势,提升算子调试效率
1.传统开发方式面临的问题:
- 调试时间久:NPU环境下调试困难,编译器编译过程隐藏并行细节
- 问题定位难:并行执行时序、同步死锁问题、地址越界问题、数据计算精度、溢出问题
- 孪生调试的方案
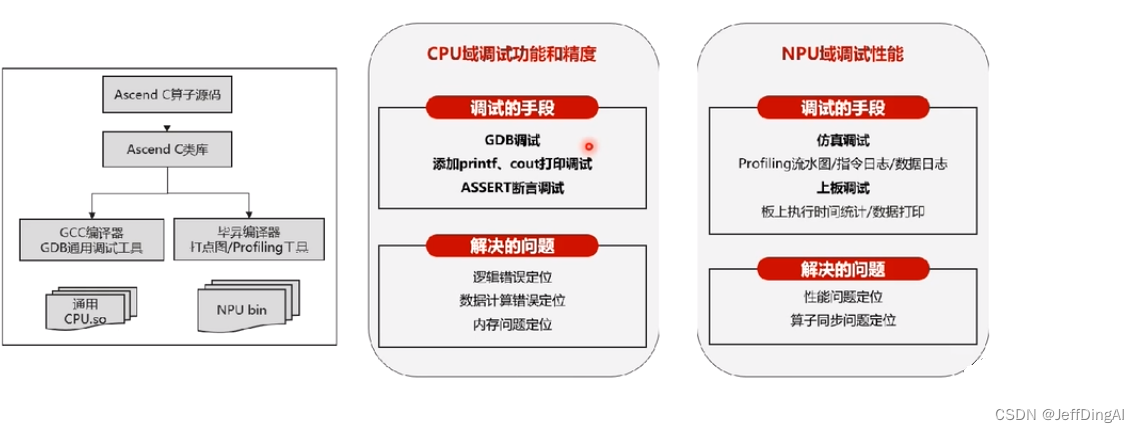
CPU模式下的算子功能调试
Ascend C提供孪生调试技术,即在CPU模式下进行运算实际上会创建一个NPU的模型并模拟它的计算行为,以此进行业务功能的调试.相同的算子代码可以在CPU模式下进行精度调试,并无缝切换到NPU模式下运行
1.使用GDB调试
source /usr/local/Ascend/latest/bin/setenv.bash
gdb --args add_custom_cpu
set follow-fork-mode child
break add_custom.cpp:45
run
list
backtrace
print i
break add_custom.cpp;56
continue
display xLocal
quit
NPU模式下的算子功能调试
NPU模式下的仿真调试,本质是使用Mode仿真器运行算子,得到数据的计算模拟和指令的时序仿真,运行后会得到一系列dump及vcd文件,用于进行算子运行过程的分析
- 每个AICore会生成一个core*_summary_log文本文件,例如core0_summary_log
- 每个AICore会生成一个vcd文件,例如core0_wave.vcd
使用Model仿真器实际上走的还是NPU运行的编译阶段,只是实际调用的动态库文件替换成了Model仿真器指定的库文件,从而达到了"真实上板“到”仿真上板的目的,运行model仿真不需要使用真实的NPU环境
自定义算子工程
介绍
自定义算子工程是一个包含用户编写的host侧和kernel侧算子实现文件的,用于编译和安装自定义算子run包的工程框架
- 通过编译自定义算子工程,可以生成算子的二进制文件,并将算子适配件,工程配置文件等一系列打到run包中
- 通过部署自定义算子run包,用户可以快速地把算子集成到安装好的CANN算子库中,从而在应用程序中调用

自定义算子工程创建
CANN开发套件包中提供了自定义算子工程生成工具msopen,可基于算子原型定义输出算子工程:包括算子host侧代码实现文件、算子kernel侧实现文件、算子适配插件以及工程编译配置文件
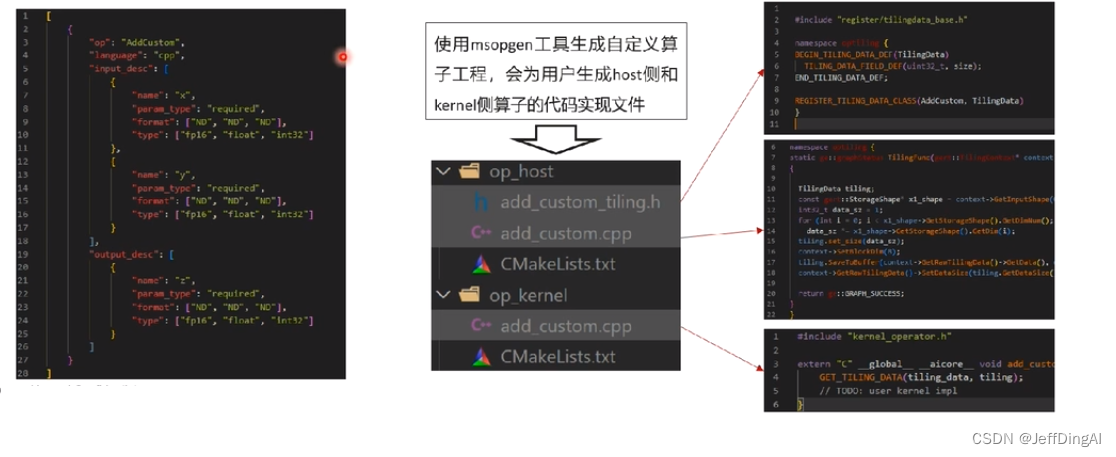
自定义算子工程编译部署
编译算子包
1.修改CMakePresets.json中ASCEND_CANN_PACKAGE为CANN软件包安装路径
2.执行算子工程编译脚本./build.sh
编译时,会在算子工程根目录下生成build_out目录,编译完成后,生成的算子run包会存放到build_out目录下
部署算子包
1.默认部署(推荐)
直接执行./custom_opp_xxx.run
执行完成后算子会部署在 < ASCEND CANN PACKAGE PATH>/opp/vendors目录下
2.指定算子包部署目录
执行./custom_opp_xxx.run --install-path=xxx
算子部署到指定目录下,此时需要将自定义安装目录添加到ACEND_CUSTOM_APP_PATH变量才能使算子得到生效
自定义算子工程样例
1.生成自定义算子工程
msopgen gen -i add_custom.json -c ai_core_Ascend910B1 -lan cpp -out ./custrom_op
2.编译自定义算子工程,生成自定义算子包
bash build.sh
3.部署自定义算子包
./custrom_opp_ubuntu_x86_x64.run
Ascend C算子调用
自定义算子调用方式
Ascend C算子快速调用方式:
- 需完成算子核函数的开发
- 基于内核调用符方式进行算子调用运行
Ascend C算子标准调用方式
- 需完成算子交付件的开发
- 需完成应用程序的开发
- 基于单算子API[ACL NN]/单算子模型(ACLOP)/Pytorch Adapter等方式进行算子调用运行

自定义算子调用方式区别
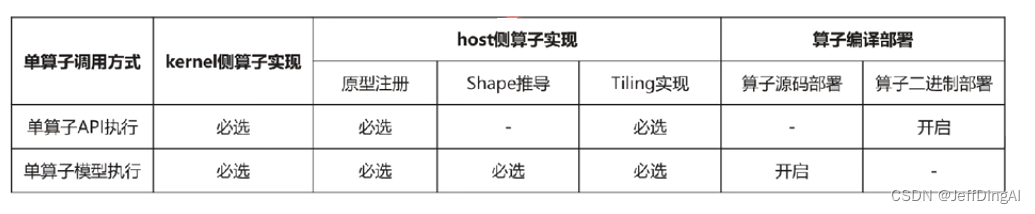
单算子调用有模型执行和API执行两种方式:
单算子API执行:基于C/C++定义的API执行算子,无需提供单算子描述文件进行离线模型转换,直接调用单算子API接口
单算子模型执行:基于图IR执行算子,先变异算子(使用ATC工具将Ascend IR定义的单算子描述文件编译成算子om模型文件。在线编译单算子,再调用AscendCL接口加载算子模型,最后调用AscendCL接口执行算子
单算子API执行
自定义算子编译后,会自动生成算子API(位于build_out/autogen目录下),可以直接在应用程序中调用,算子API的形式一般定义为“两段式结构”
使用第一段接口aclnnXXXGetWorkspaceSize,计算相关联的算子调用接口中需要workspace内存的大小
按照workspaceSize大小申请Device侧内存
使用第二段接口aclnnXXX,调用对应的单算子二进制执行计算
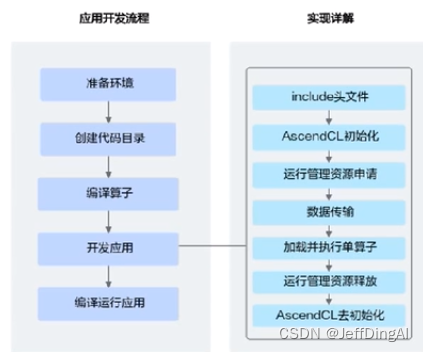
1.AscendCL初始化
调用aclInit接口实现初始化AscendCL
2.运行管理资源申请,依次申请运行管理资源: Device、Context、Stream
3.申请内存和传输数据
- 调用aclrtMalloc接口申请Device上的内存,存放待执行算子的输入、输出数据
- 调用aclCreateTensor、aclCreatelntArray等接口构造算子的输入、输出,如aclTensor.aclIntArray等
- 如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口 (同步接口)或aclrtMemcpyAsync接口 (异步接口)通过内存复制的方式实现数据传输
4.计算workspace并执行算子
- 调用acinnXxxGetWorkspaceSize接口获取算子入参和算子执行流程需要的workspace大小
- 调用aclrtMalloc接口,根据workspaceSize大小申请Device侧内存
- 调用acInnXxx接口执行计算并得到结果
5.调用acitSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任务都完成如果需要将Device上算子执行结果数据传输到Host,则需要调用aclrtMemcpy接口 (同步接口)或aclrtMemcpyAsync接口 (异步接口)通过内存复制的方式实现数据传输
6.运行管理资源释放
- 调用aclDestroyTensor、aclDestroylntArray等接口释放算子的输入、输出对象
- 调用aclrtFree接口释放Device侧内存
- 所有数据处理都结束后,需要依次释放运行管理资源: Stream、Context、Device
7.AscendCL去初始化
调用aclFinalize接口实现AscendCL去初始化
单算子模型执行
1.编译算子
根据算子编译的方式,分为离线编译(ofine)和在线编译(online):
- 编译算子后,算子相关数据保存在”.om模型文件中,需使用ATC工具,将单算子定义文件(*json)编译成离线模型 (.om文件)
- 编译算子后,算子相关数据保存在内存中,对于同一个算子,编译一次,多.次执行的场景,调用aclopCompile接口编译算子
2.加载算子模型文件
调用aclopSetModelDir接口,设置加载模型文件的目录,目录下存放单算子模型文件(*.om文件)
3.调用aclrtMalloc接口申请Device上的内存,存放执行算子的输入、输出数据如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口 (同步接)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输
4.执行算子
调用aclopExecuteV2接口执行算子。每次执行算子时,系统内部都会根据算子描述信息匹配内存中的模型
5.调用aclrtSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任
务都完成
6.调用aclrtFree接口释放内存
如果需要将Device上的算子执行结果数据传输到Host,则需要调用acirtMemcpy接口(同步接口)或aclrtMemcpyAsync接口 (异步接口)通过内存复制的方式
必适步街
实现数据传输,然后再释放内存
调用方式
1.编译并运行在线编译的算子API
cd aclnn_online_model
bash run.sh
2.编译并运行离线编译的单算子模型样例
cd acl_offline_model
bash run.sh --is-dynamic 0
3.编译并运行在线编译的单算子模型样例
cd acl_online_model
bash run.sh --is-dynamic 0
UT/ST测试介绍
当完成自定义算子开发后,可进行UT和ST测试验证算子是否正常运行
UT(Unit Test:单元测试)是开发人员进行单算子运行验证的手段之一
- 测试算子代码的正确性,验证输入输出结果与设计的一致性
- UT侧重于保证算子程序能够正常运行,选取的场景组合应能覆盖算子代码的所有分支.(一般情况下覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率
ST(System Test:系统测试)是在真实的硬件环境中,验证算子功能的正确性
ST测试的主要功能是:基于算子测试用例定义文件*sn生成单算子的om文件,使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性
注:ST测试前,需要将要测试的算子部署到当前环境中
自定义算子UT测试
Ascend C算子UT的本质是通过Model仿真器校验Ascend C算子的运行结果,不依赖Device设备
- 导入UT测试类AscendcOpUt
- 实例化测试用例AscendcOpUt(‘add_custom’)
- 使用add_precision_case接口,配置caic_expect_func真值生成函数,与期望数据进行结果的比对
- 添加测试用例
自定义算子ST测试
Ascend C算子ST测试的本质是通过生成om离线模型和单算子模式应用程序,使用Device执行校验Ascend C算子的运行结果,依赖Device设备CANN开发者套件包中提供了ST测试工具:msopst,支持生成算子的ST测试用例并在硬件环境中执行
- 【数据生成】根据算子测试用例定义文件生成ST测试数据集测试用例执行代码,在硬件环境上执行算子测试用例
- 【报表呈现】自动生成运行报表(st_report.json)功能,报表记录了测试用例信息及各阶段运行情况
- 【数据比对】根据定义的算子期望数据生成函数回显期望蒜子输出和实际算子输出的对比测试结果
Pytorch算子调用
PTA适配框架
通过PyTorch框架进行模型的训练、推理时,会调用到很多算子进行计算目前PyTorch提供了常用的算子接口和接口的注册分发机制,可以将算子映射到不同的底层硬件设备
适配PyTorch的框架,称为PyTorch Adapter (PTA)
Ascend c适配了这套PyTorch算子接口和分发接口的机制,具备从PyTorch调用异腾AI处理器的能力。通过切换device实例能够快速迁移跑在其他设备(GPU等)上的PyTorch网络
码云: https://gitee.com/ascend/pytorch/tree/v1.11.0
为了Ascend c自定义算子能够在PyTorch深度学习框架中使能在安装好自定义算子包的基础上,用户需要额外提供如下文件(以v1.11.0为例)用于编译torch npu的whl包:
- 注册PTA自定义算子接口
- 编写PTA自定义算子适配文件

算子注册开发
在npu native functions,yaml文件中给出定义,路经为torch npu/csrc/aten/npu native functions.yaml该文件对算子进行结构化解析从而实现自动化注册和Python接口绑定
custom: # 自定义算子,需要提供算子格式定义
- func: npu_dtype cast(Tensor self, ScalarType dtype) -> Tensor
variants: function, method
- func: npu_dtype_cast_(Tensor(a!) self, Tensor src) -> Tensor(a!)
variants: method
-func:lloc float_status(Tensor self) -> Tensor
variants: function, method
- func: npu get fioat status(Tensor self) -> Tensor
variants: function, method
custom_autograd: # 自定义继承自Function的自定义算子
-func: npu convolution(Tensor input Tensor weight, Tensor? bias. ..) -> Tensoi
适配插件开发
用户通过开发算子适配插件,实现PyTorch原生算子的输入参数、输出参数和属性的格式转换,使转换后的格式与自定义算子的输入参数、输出参数和属性的格式相同
-
创建适配插件文件: Ascend C算子适配文件保存在torch npu/csrc/aten/ops/op_api目录下,大驼峰命名风格,命名格式:<算子名>+.cpp如: AddCustomKernelNpu.cpp
-
引入依赖头文件:适配异腾AI处理器的PyTorch源代码在torch npu/csrc/framework/utils中提供了适配常用的工具
-
定义实现算子适配主体函数:实现算子适配主体函数,根据Ascend C算子原型构造得到对应的input、output、 attr
-
重编译PvTorch框架或插件:请重新编译生成
测试文件开发
完成算子注册分发和适配插件开发的操作后,需要重新编译PTA源码,获得torch_npu插件的whi安装包,安装完成后可以通过PyTorch框架调用到底层Ascend c自定义算子
使用PyTorch调用Ascend c自定义算子的关键步骤:
- 安装开发调试环境(CANN软件包)
- 完成算子注册分发和适配插件开发
- 编译安装插件包,得到whl包torch_npu
- 安装Python whl包torch、torch npu4
- 导入torch npu调用注册的接口API完成自定义算子调用
注:若要调用异腾提供的算子库API,需要额外安装opp kernels包