前言
内存泄漏问题,在C++程序中经常会被开发测试人员忽略,最终会在客户运行现场因为内存泄漏最后导致程序内存耗尽,最后崩溃,从而影响客户的生产环境,导致异常发生。因为内存泄漏是一个共性的问题,所有的C++程序都可能存在相同的问题,这篇文档就是总结之前所有遇到过的内存泄漏相关的缺陷,从问题排查角度,总结一下内存泄漏的检查办法;从测试角度,归纳一些针对内存泄漏的测试办法;从提前发现的问题角度,结合一些工具提供内存泄漏的监控办法;从程序设计开发角度,提供一些避免内存泄漏的方法;最后再列举一些之前出现过的内存泄漏的原因,为排查和解决问题提供一些参考。
1、排查程序内存泄漏
如何确定进程崩溃是由内存泄漏造成的,或者怎么定位程序是否存在内存泄漏,下面介绍一些内存泄漏判断方法。
1.1 定位程序是否存在内存泄漏
程序是否存在内存泄漏,最简单的办法就是查看进程对应的内存,在linux下可以使用命令“top –p 进程号”,关注界面输出的VIRT、RES两个字段的值;windows下就直接使用任务管理器查看对应的进程,查看内存列;AIX下可以使用“ps aux 进程号”,关注界面输出的RSS大小。定时查看进程占用的内存,可以确定内存是否一直在上涨,一般程序开始运行期间内存会上涨,但是最后会稳定在一个上限值,然后就在这个附近波动。如果程序内存一直上涨,32位系统下,达到3G以上的话,程序可能就会返回错误或者直接崩溃了,这时候进程内部应该已经申请不到内存了,这种情况我们就可以认定存在内存泄漏。Linux下如果程序产生了core文件,core文件大小在3G以上,那么也可以说明程序存在内存泄漏。
1.2 工具检查
一般公司大部分C++程序是运行在自己的平台之上,平台内部有自己的内存管理机制,业务操作需要使用的消息和业务打包器解包器等资源是统一管理的,需要统一从池中获取,用完归还入池,如果不归还就会造成内存泄漏。这个可以通过平台自身提供的管理功能来检查是否存在这个问题。
1.3 Valgrind memcheck工具
valgrind 是linux系统的一个工具集,可以检查对应的内存泄漏,使用的时候就是在自己运行的程序之前增加相应的命令,如下所示:
valgrind --track-fds=yes --leak-check=full --undef-value-errors=yes --tool=memcheck --log-file=cres.log server_s1 -start mainsvr -f fanli.xml -t bar -s0
tips:使用该命令时,红色部分为自己经常启动的完整参数
上面红色部分就是对应的程序运行命令,通过这种方式启动需要检测的程序,然后按照内存泄漏的用例,开始进行测试。然后查看--log-file参数对应的文件(cres.log),如果发现了有内存泄漏的时候,报告如下所示:
==20343== 80 bytes in 1 blocks are definitely lost in loss record 546 of 577
==20343== at 0x4A07E05: operator new(unsigned long) (vg_replace_malloc.c:324)
==20343== by 0x4C6C0BD: CPublisher::OnInit(char*, bool) (Publisher.cpp:346)
==20343== by 0x4C6314B: CMCClientAPI::GetPublisher(char*, int, bool, int) (MCClientAPI.cpp:2145)
==20343== by 0x40127E: main (in /home/XXX/StressTest/publisher_multi)
红色提示的就是内存泄漏,下面对应的就是函数堆栈,这样就方便排查。但是这个工具的提示的代码,不一定是真正的泄漏,可能是系统的缓存策略,申请内存之后,不会归还,会一直循环利用,这种场景就不应该认为是泄漏,所以通过工具检查出来的代码,需要人工进行判断。
如果内存泄漏是在windows下发生的,可以把进程运行在linux系统下再排查问题,一般内存泄漏都是应用程序代码写的有问题,所有平台应该都会泄漏,在linux上再通过valgrind去检查。
1.4 代码评审
通过以上步骤,确定了内存泄漏,或者定位到了可疑的模块,最后一步就需要通过代码排查,定位到最终内存泄漏的代码。在代码排查的地方重点关注内存申请释放代码, 主要包含下面几点:
- 程序运行中通过new申请的内存,最后都有相应的delete操作;同样程序运行中通过malloc申请的内存,都有相应的free操作。针对这些代码进行严格匹配检查。
- 基于平台的客户端开发包t2开发的代码,所有的接口对象在申请之后都需要调用AddRef接口增加引用计数,然后通过Release才能释放内存。在t2所有接口里面,IF2Packer接口需要注意,目前释放IF2Packer接口对应的内存,需要先调用FreeMem函数,然后再调用Release才可以完全释放内存。
- 基于平台的服务端开发,业务组件以及插件开发的时候,所有的接口对象在申请之后,无需调用AddRef接口,后续通过Release就能释放内存。如果调用了AddRef之后,内存可能就会被泄漏了。不过同样的IF2Packer接口,也是需要先调用FreeMem函数,然后再调用Release才可以完全释放内存。
- 其他第三方的开发包接口调用,需要关注对应的接口说明,在接口对象申请释放的时候,相应的步骤是怎样的,代码是否按照标准步骤调用。
1.5 代码裁剪还原
如果通过以上种种步骤还是不可以定位内存泄漏的代码,那么可以采用最后的办法,就是代码裁剪,也就是说,让程序运行的代码简单化,先删除所有的业务逻辑代码,按照最简单的代码运行,通过压力测试看看是否还有泄漏,一直把代码删减到没有泄漏为止,后续通过代码一点点还原,一点点测试,通过这个方式把最后泄漏的代码定位到。
2、测试程序内存泄漏
为什么内存泄漏总是在客户现场才被发现,公司内部测试的时候为什么无法发现?内部的测试可能更注重的是功能测试,而且测试环境会不停重启,内存泄漏就会被忽略。下面介绍两种针对内存泄漏的测试方法:
2.1 GCOV的覆盖性测试
一般正常的分支,功能测试用例都会覆盖,但是大部分的异常分支可能就会漏掉,那么怎么检测测试用例的覆盖度,Linux下的C++程序,可以使用GCOV来验证测试用例覆盖度。下面详细介绍一下这个工具使用方法:
下载安装
- LCOV可以采用html的格式显示GCOV的结果,LCOV的源码下载地址如下:http://ltp.sourceforge.net/coverage/lcov.php,下载文件名为lcov-1.9.tar
- 用Root帐号登录,直接tar –xvf lcov-1.9.tar,然后make install,安装到系统的执行目录即可,任何用户登录都可以执行LCOV工具的命令。
- Gcov不需要安装,和GCC、Linux一起发行。
程序配置编译
要让LCOV收集代码覆盖率数据,必须在被测程序编译时加入gcov的编译选项和链接选项,编译选项为“-fprofile-arcs -ftest-coverage”,链接选项为“-lgcov”(说明:-ftest-coverage选项会让GCC为每个源文件生成同名的.gcno文件,gcno文件为覆盖率统计的路径弧长文件,gcov程序读取.gcno文件,重组每一个可执行程序的流图。-fprofile-arcs选项会让GCC为每个源文件生成同名的.gcda文件,该文件包含每一个指令分支的执行次数信息),以im模块为例,修改im模块源码目录中的makefile.gcc文件,增加如下参数,参见红色框:
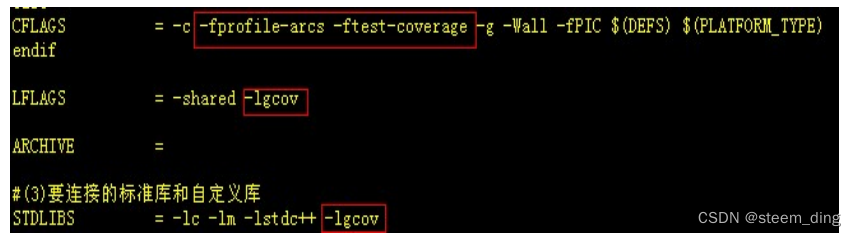
保存makefile.gcc后。执行make –f makefile.gcc all,将新编译生成的libmc2_hsim.so拷贝到运行目录/linux.i386/lib,同时在im模块源码目录下生成大量.gcno文件。
初始化覆盖率数据
每次在做代码覆盖率统计之前,必须清除源码目录下已有的覆盖率文件,才可以重新统计新版本的数据。比如在im模块的源码目录下执行命令:lcov -d ./ -z,清除gcda覆盖率文件。
执行测试
按照之前设计好的测试用例,全部执行一遍,然后去分析测试用例的代码覆盖率。
统计代码覆盖率生成报表
测试执行完成后,收集代码覆盖率数据(假设在im模块源码目录下进行覆盖率数据统计,并在lcvoutput_0313目录下生成汇总结果):
lcov -b ./ -d ./ -c -o ./lcvoutput_0313/imfile.info
生成html报表:将汇总生成的数据生成网页格式:genhtml imfile.info
双击生成的index.html文件,显示im模块总的行覆盖率、函数覆盖率、分支覆盖率。

最后总结一下,lcov适合于Linux环境下的c/c++代码覆盖率统计,只要对被测开发代码打桩,所以无论黑盒测试还是白盒测试,只要开发代码被打桩并且被执行就能够统计到代码测试的覆盖率。(这里分两种测试情况:一是黑盒情况:测试工具与被测对象代码没有关系,那就直接修改被测对象原来的编译参数,直接编译生成可执行文件,再利用测试工具执行即可,被测可执行文件运行完毕后就有测试覆盖率了;二是白盒情况下:因为测试框架本身也是c/c++代码,以库依赖的方式添加到你的被测对象的c/c++工程内,编译测试代码的时候加入编译参数即可,运行白盒测试程序后即可生成代码覆盖率。)但是需注意的是,对于服务端程序,lcov的桩代码会带来比较大的性能影响,因此对于复杂的服务端集成测试不太适合lcov统计覆盖率。
通过覆盖性的测试,设计自己的用例,让代码分支尽量走到100%,这样就可以保证测试不要有遗漏的场景。
2.2 针对性的压力测试
有了上面的覆盖性的测试用例之后,后续就可以针对所有用例,进行相对应的压力测试,如果用例确实太多,针对每天经常被调用的功能号,一定要进行压力测试,测试时间建议在两个小时以上,可以在晚上下班之后一直进行压力测试,第二天早上查看对应的内存情况。后续发现怀疑哪个分支有问题,就可以使用上面已有的测试用例进行针对性的压力测试,这样可以通过测试尽快定位程序的泄漏逻辑,方便开发人员排查对应的代码,可以尽快解决问题。
3、监控程序内存泄漏
3.1 自有软件监控
上面介绍的是内存泄漏排查和测试的办法,但是其实内存泄漏是可以提前预知的,不需要等到内存不够,最后程序异常,才被发现。所以内存泄漏需要被监控,需要实时发现内存有泄漏,方便运维人员尽快处理,一般公司会提供专门监控自己平台内存的工具,这里就不展开了。
3.2 脚本监控
上面平台软件如果客户现场没有安装,我们每个自己的业务系统可以通过脚本检测自己的进程内存使用情况。下面提供一个linux的样例,给大家借鉴,其他平台的大家可以参考修改对应平台的脚本。
while true
do
date "+%Y-%m-%d %H:%M:%S" >> log1.log
ps aux|head -1 >> log1.log
ps aux |grep "server1 -start mainsvr -f st.xml -t ar -s 1"|head -1 >> log1.log
echo " " >> log1.log
sleep 1
done
上面红色部分就是我们对应程序的运行命令行参数,根据自己需要监控的程序来调整,最后输出的文件, log1.log如下:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
test 19232 0.7 0.4 1662832 16172 ? xxx时间 server1 -start mainsvr -f st.xml -t ar -s 1
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
test 19232 0.7 0.4 1662832 16172 ? Ssl xxx时间 server1 -start mainsvr -f st.xml -t ar -s 1
关注输出文件中VSZ ,RSS两个字段,他们的单位为K,通过这种定时脚本,可以最后汇总显示内存的增长情况,从而达到监控内存的目的。
4、避免程序内存泄漏
前面描述了都是事后如何解决和发现内存泄漏问题,其实应该在更早之前就要有防止内存泄漏的思想,那么就需要在设计和开发阶段来预防后续内存泄漏的问题。下面提供一些预防内存泄漏的措施。
4.1 程序设计阶段
- 在程序设计的时候,每个模块内部内存占用情况,最好可以通过接口访问的模式获取到,这样可以判断,内存占用量是否是合理的值,从而确定到底是内存泄漏还是程序的正常内存增长。
- 如果程序在设计的时候,需要使用内存缓存,用于重复利用,提高性能。这样缓存需要考虑内存的回收,防止因为量增大,最后导致内存撑爆,虽然这不属于内存泄漏,但是程序也会因此崩溃。举例来说,针对每个TCP里面都有一个发送缓存空间,这个空间随着发送量增大而增大,而且不会回收,后来在业务场景下,发送报文达到了8M,每个连接就会占用8M空间,然后连接数达到400多个之后,程序内存不够用,就退出了,后来改造成。连接归还的时候,缓存空间回收到1K。
4.2 代码编写阶段
所有的内存泄漏都是编码阶段引入的,如何避免程序编写出现内存泄漏,一般可以通过编码规范来提醒开发人员,列出他们需要注意的点。下面列出一些开发人员在内存泄漏方面关注的点:
- 用malloc申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
- 不要忘记为数组和动态内存赋初值。
- 避免数组或指针的下标越界,特别要当心发生“多1”或者“少1”操作。
- 动态内存的申请与释放必须配对(new和delete,free和malloc),防止内存泄漏。要特别注意在循环体中的指针,在break以前一定要进行内存释放动作,否则会出现内存泄漏。
- 用free 释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。
- 在使用数组或结构体取批量结果时,对于oracle的varchar类型,proc不会自动按数据库实际长度来取,而是变量长度定义来赋值,除最后一位填\0外,其余除实际数值外的部分会填空格,因此在copy以及比较、使用时要注意trim。
- strcpy,memcpy等系统底层提供的内存拷贝函数,容易造成内存的越界和非法操作,建议项目组统一封装成安全的函数调用,从而达到所有使用一致的目的,方便后续问题排查。
- 在使用第三方开源的开发包(sqllite,openssl等)的时候,需要看清楚调用说明,接口使用一定要匹配,防止造成资源泄漏。
- 一般在申请成功之后,都需要调用AddRef增加引用计数,在释放的时候,再调用Release才可以真正释放掉,否则就会造成内存泄漏。
- 特殊情况的,在申请之后,调用AddRef增加引用计数,在释放调用Release之前,必须先调用FreeMem来释放内部空间。