授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在亚马逊云科技开发者社区、 知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道。
目录
🚀一. Amazon SageMaker
🔎1.1 新功能发布:Amazon SageMaker Canvas
🔎1.2 Amazon SageMaker Canvas特点
🚀二.Amazon SageMaker Canvas无需代码生成准确的 ML 预测
🔎2.1 项目背景
🔎2.2 前期步骤
🦋2.3 导入数据集
🦋2.3 模型创建
🦋2.4 模型优化
🦋2.5 模型预测
🚀三.总结与心得
🔎3.1心得
🔎3.2 总结
🚀附录
亚马逊云科技2023 re:Invent全球大会是亚马逊云科技举办的一场技术盛会,旨在探讨云计算、大数据、人工智能等前沿技术趋势和应用场景。在大会上,亚马逊云科技将发布一系列新产品和新技术,以及针对不同行业和场景的解决方案,帮助客户更好地利用云计算和大数据技术,提升业务效率和创新能力。

各位读者大家好,我是一见已难忘。在本次大会中,亚马逊云科技发布 Amazon SageMaker 五项新功能,用于模型的扩展。今天我们就来深度体验学习一下Amazon SageMaker Canvas无需代码生成准确的 ML 预测,构建货物的交付状态检测模型,并且让其准确度在百分之80以上!
🚀一. Amazon SageMaker
Amazon SageMaker是亚马逊云科技提供的一项机器学习(ML)服务。它旨在帮助开发人员和数据科学家轻松构建、训练和部署机器学习模型。SageMaker提供了一个端到端的机器学习平台,涵盖了从数据准备和模型训练到模型部署和推理的整个机器学习工作流程。
Amazon SageMaker 官网:Amazon SageMaker 机器学习_机器学习模型构建训练部署-亚马逊云科技云服务
🔎1.1 新功能发布:Amazon SageMaker Canvas
Amazon SageMaker Canvas 是 Amazon SageMaker 的一项全新功能,让业务分析师能够使用可视化点击式界面创建准确的机器学习 (ML) 模型并生成预测。

Amazon SageMaker Canvas 提供直观的用户界面以快速连接与访问来自不同来源的数据,并准备数据以构建机器学习 (ML) 模型。
SageMaker Canvas 利用由 Amazon SageMaker 提供的功能强大的 AutoML 技术,该技术会根据数据集自动训练与构建模型。这使 SageMaker Canvas 能够根据数据集识别最佳模型,因此可以生成单个或批量预测。SageMaker Canvas 与 SageMaker Studio 集成,让业务分析师能够轻松地与数据科学家分享模型。 SageMaker Canvas 帮助企业内部的分析师(不管他们的技术技能如何)从不同的数据集创建准确的机器学习模型,并更高效地和数据科学家开展合作。
Amazon SageMaker Canvas 体验官网:Amazon SageMaker Canvas
🔎1.2 Amazon SageMaker Canvas特点
Amazon SageMaker Canvas 的无代码界面,可以访问现成的 FM 和预测模型或创建自定义模型,只需几分钟即可提取信息并生成 AI 输出。Canvas 支持 Amazon Bedrock 中的 FM(包括 Claude、Titan 和 Jurassic)以及 SageMaker JumpStart 中的公共模型(例如 Falcon 和 MPT)。在 SageMaker Canvas 中使用这些 FM 可以生成、提取和总结内容。
还可以使用现成的模型对内容进行分析和分类,以进行情绪分析、对象检测或文档分析。 要开始使用现成的模型,只需选择模型、上传数据,然后单击即可生成模型输出。
此外还可以构建自己的自定义模型来进行分类、回归、预测、文本分类或图像分类,无需编码。要开始使用自定义模型,可以导入来自不同来源的数据,选择要预测的值,自动准备和浏览数据,以及通过单击几下来创建 ML 模型。
Amazon SageMaker Canvas特点如下:
- 使用可视化点击界面为分类、回归、预测、自然语言处理(NLP)和计算机视觉(CV)生成准确的 ML 预测。
- 访问现成的基础或预测模型,或自动创建自定义 ML 模型,只需单击几下即可生成输出。
- 通过跨工具共享、审查和更新 ML 模型,促进业务分析师和数据科学团队之间的协作。
- 从任何地方导入 ML 模型并直接在 Amazon SageMaker Canvas 中生成预测。
🚀二.Amazon SageMaker Canvas无需代码生成准确的 ML 预测
🔎2.1 项目背景
在这个实验中,重点是构建和训练模型,通过利用所提供的数据集来提高预测准确性。同时,展示如何对模型进行分析并进行预测。
我们的任务是在Canvas中构建一个机器学习模型,该模型能够根据历史数据预测交付是否准时或延迟。我们的目标是建立一个模型,其准确率能够超过80%,从而有效地预测货物的交付状态。
数据集:(真实的交付样本)
- on-time-delivery-data 数据集
- On-time-delivery-data_extended 数据集
🔎2.2 前期步骤
本功能测试官网地址:SageMaker Canvas 演示
1.本文深度实验步骤为提示大家学习效果,部分页面截图使用了游览器自带的翻译功能,但在关键步骤依然采用原生英文页面,不用担心关键页面演示翻译不准确的问题。
2.目前无需亚马逊云科技账户,但需个人邮箱接收临时密码。
3.完成AI Package Tracker 演示。
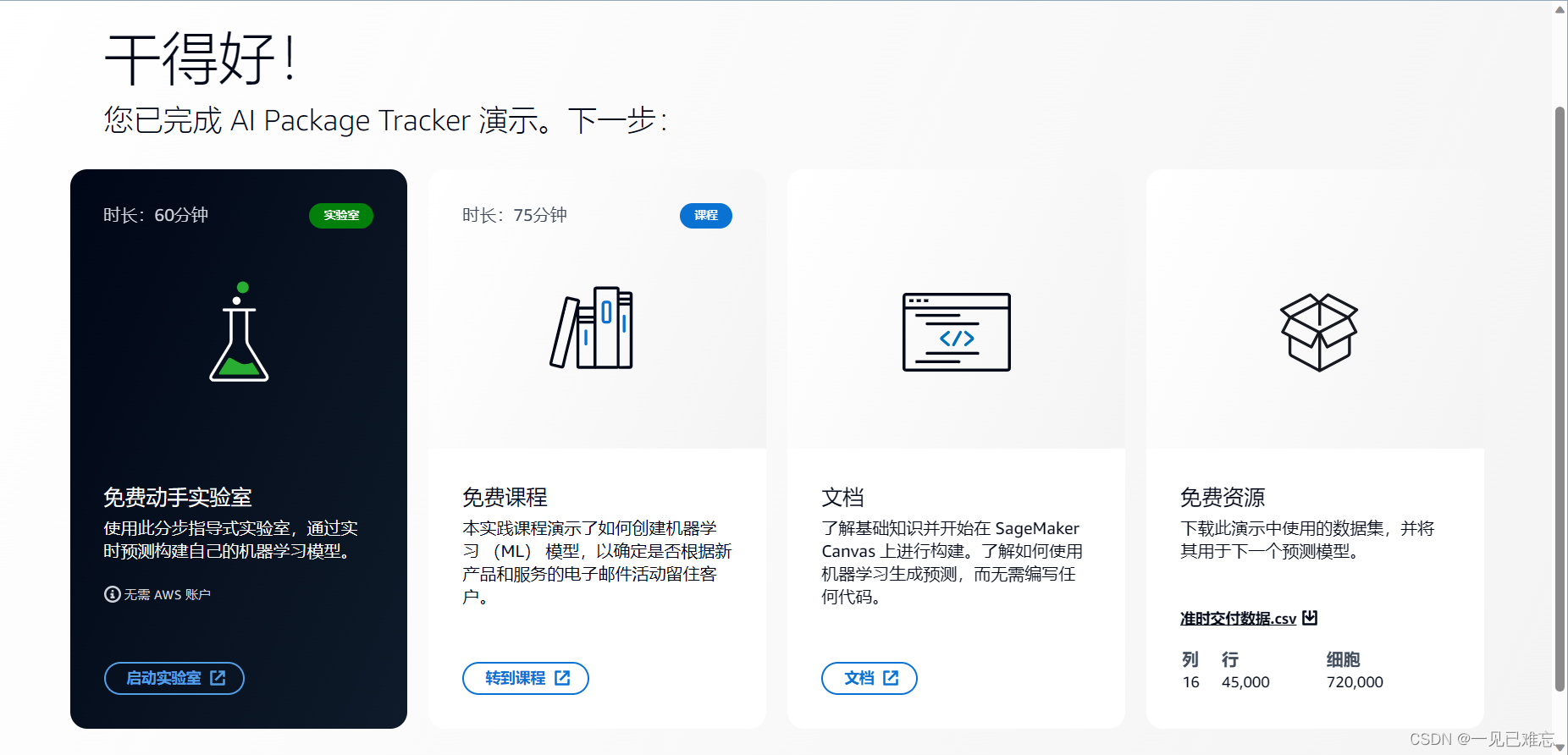
4.启动实验室,打开亚马逊云科技控制台,我们可以看到官网出明确的写了暂不需要额外开通的亚马逊云科技账号,作为新功能对于对新接触这个领域的用户是十分的关照,我们只需部署模型环境,即可开始体验。

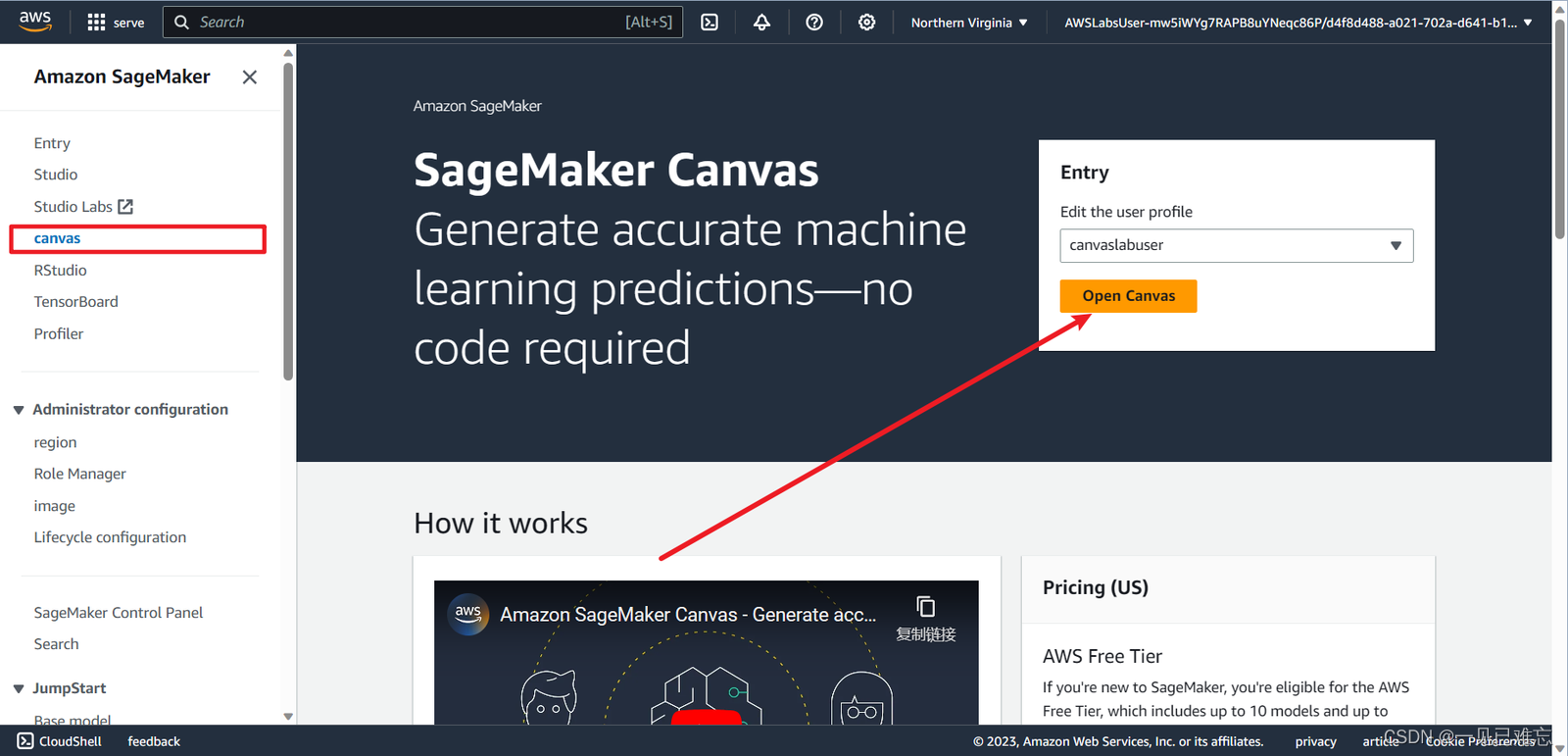
5.在控制台搜索Amazon SageMaker,点击进入。
Amazon SageMaker是一个全托管的机器学习平台,它可以帮助开发者、数据科学家和业务用户快速地构建、训练和部署机器学习模型。SageMaker提供了丰富的工具和功能,包括但不限于自动化机器学习、自然语言处理、计算机视觉等。
我以前使用过Amazon SageMaker来训练一些模型,当然都是高度需要代码,是传统的深度学习模型,但是这次的新产品Amazon SageMaker Canvas给我带来了极大的震撼,现在不用代码就可以继续模型训练,这是之前闻所未闻的!

6.点击左侧的Canvas,打开Canvas。操作简单,这块可以说是非常的照顾新用户了。
Canvas提供可视化工具,帮助客户直观地准备和分析数据。Canvas使用自动机器学习来构建和训练机器学习模型。接下来我们就要深度的体验的Canvas功能!
7.启动实验室,等待环境搭建完成(5-10min左右)。
为了使Amazon SageMaker Canvas应用程序运行顺利,系统为其分配了一些资源。这些资源用于执行数据分析、准备和修改数据集、查看数据见解和可视化效果、预览模型,以及运行假设分析或生成批量预测以获取更多见解。如果想释放这些专用资源,只需点击Canvas应用程序中的注销按钮即可。

8.部署过程后成功进入Amazon SageMaker Canvas页面,我们可以看到页面UI做的十分美观舒适,功能也十分的简洁清楚。
使用自然语言指令实现对机器学习(ML)数据的探索、可视化和转换。这项新功能加快简化了数据探索和数据准备流程,我觉得这是一个伟大的产品,是一个里程碑的创新。

本节心得:
对于本次亚马逊云科技发布的新产品:Amazon SageMaker Canvas ,无需额外开通亚马逊云科技账号,这对于初次接触这个领域的用户来说是一项重要的优势。这种关照新用户的态度有助于吸引更多人尝试新功能。只需部署模型环境即可开始体验,进一步降低了使用门槛。
我成功进入Amazon SageMaker Canvas页面,看到页面的UI设计十分美观舒适,功能简洁清楚。这种对用户体验的关注有助于建立对新功能的积极印象,同时也为读者提供了对功能界面的深度了解与快速学习。
🦋2.3 导入数据集
1.完成上文的准备步骤后,点击左侧导航面板中的Data Wrangler,效果页面如下:
我们可以看到Data Wrangler的页面,在创建虚拟环境时,可能会根据账号权限的不同会有一些自有的数据文件,我们现在开始就可以创建数据集了。

2.选择“Create”下拉列表,然后选择“Tabular”。
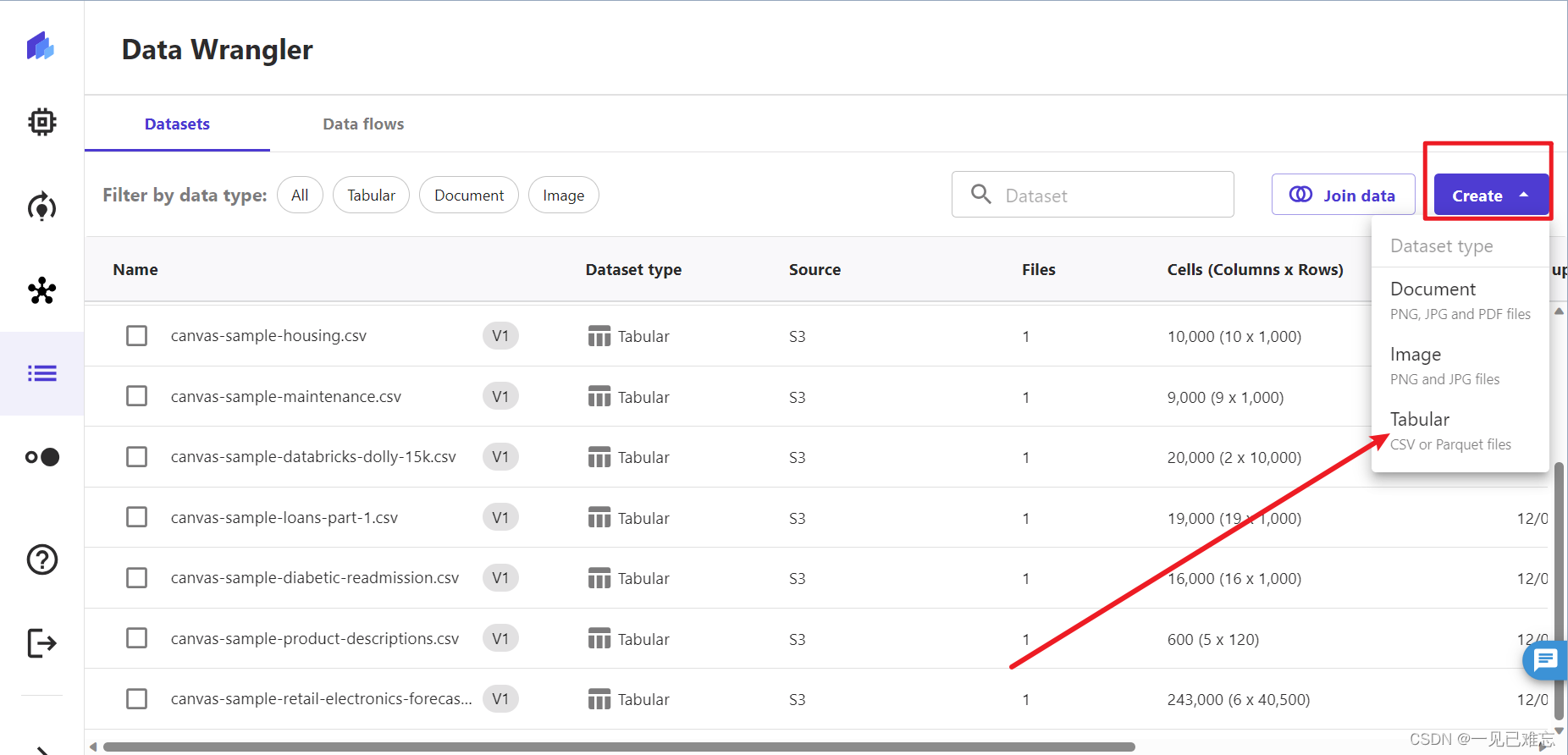
3.创建表格数据集,起名为on-time-delivery,名字可随意起,因为我们本次测评项目提供的on-time-delivery-data 数据集是一个真实的交付样本。
数据集分析,当我拿到案例给的数据集后,我对其进行了仔细的分析:
on-time-delivery-data.csv 这个数据集包含两列:zipcode和classification_ontime。每一行表示一个邮政编码(zipcode)和对应的按时交付分类(classification_ontime)。
根据给出的样本,"Delayed"分类和"On time"分类都有出现,说明数据集中包含了按时和延迟交付的样本。
我在初步查看数据得出初步情况:可以进一步分析延迟交付的趋势,可能与地理位置、季节性变化或其他因素相关。(后面就会由Amazon SageMaker Canvas模型训练来得出结果。)
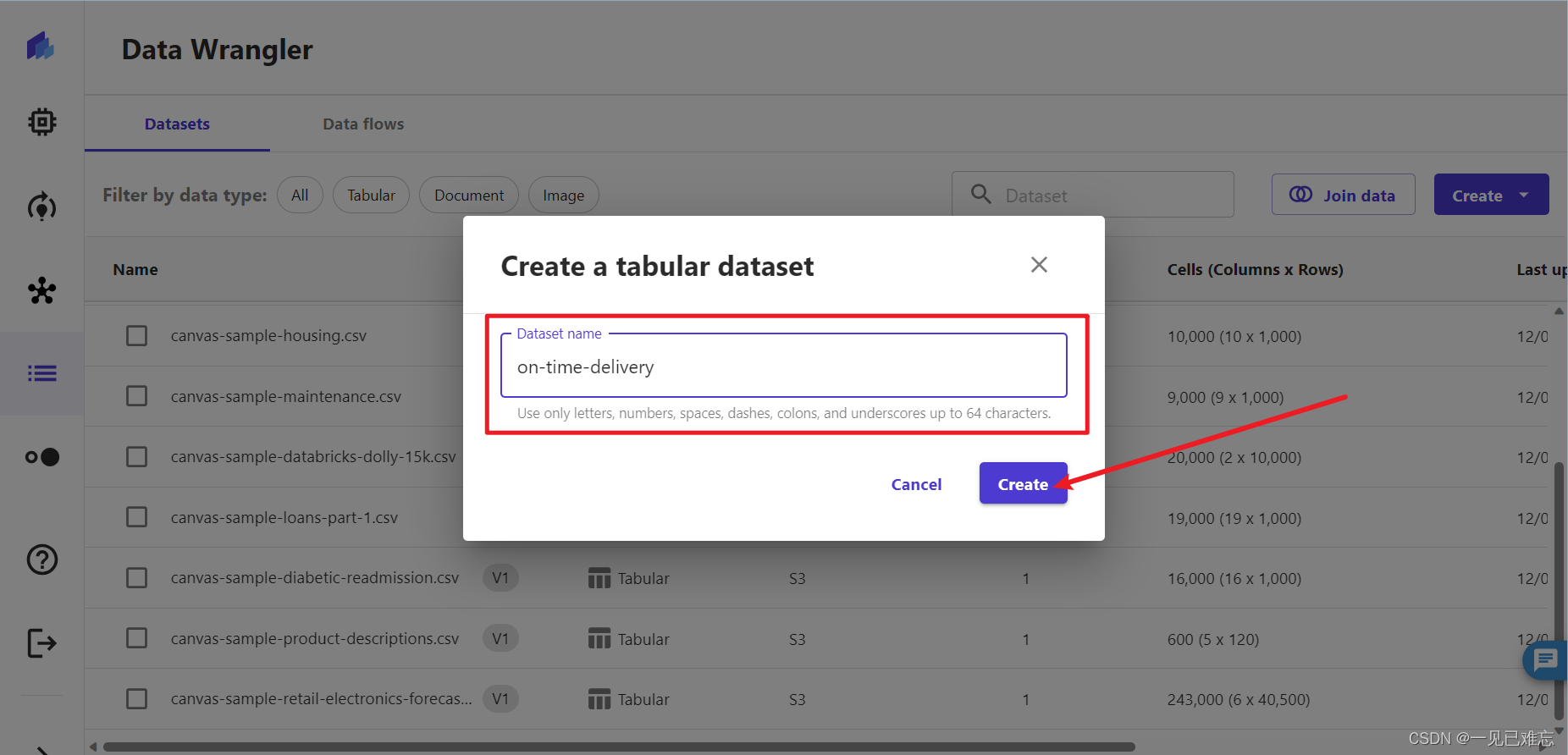
4.选择数据来源为:Amazon S3。
Amazon S3是亚马逊提供的一个存储服务,允许用户在云端存储数字资产,包括图片、视频、音乐和文档等。这个服务是公开的,Web应用程序开发人员可以使用它来存储和获取数据,以支持他们的应用程序。
S3提供了一个RESTful API,用户可以通过编程方式实现与该服务的交互。
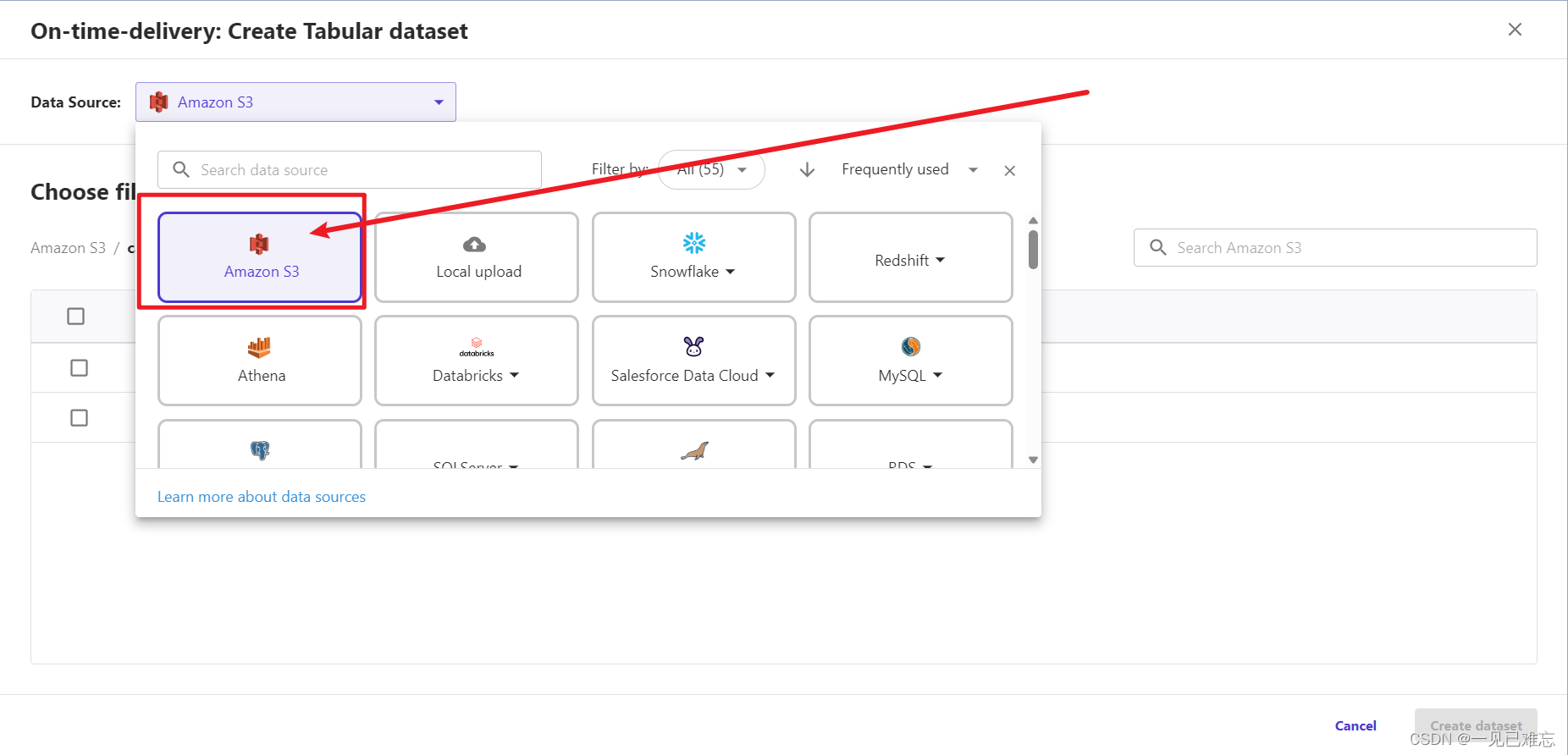
5.选择要导入的文件,如下图(保证是数据来源为:Amazon S3)
一般是:canvas-lab-data-us-east-1-用户名

6.选择on-time-delivery-data 数据集(创建环境时会自动的加载数据集,如果没有数据来源可以选择自行上传)
我们可以看到上传都是十分方便的,对用户十分的友好,方便快捷!

可以在实验页面自行下载on-time-delivery-data和On-time-delivery-data_extended 数据集。然后在上面第4步选择上传本地文件。
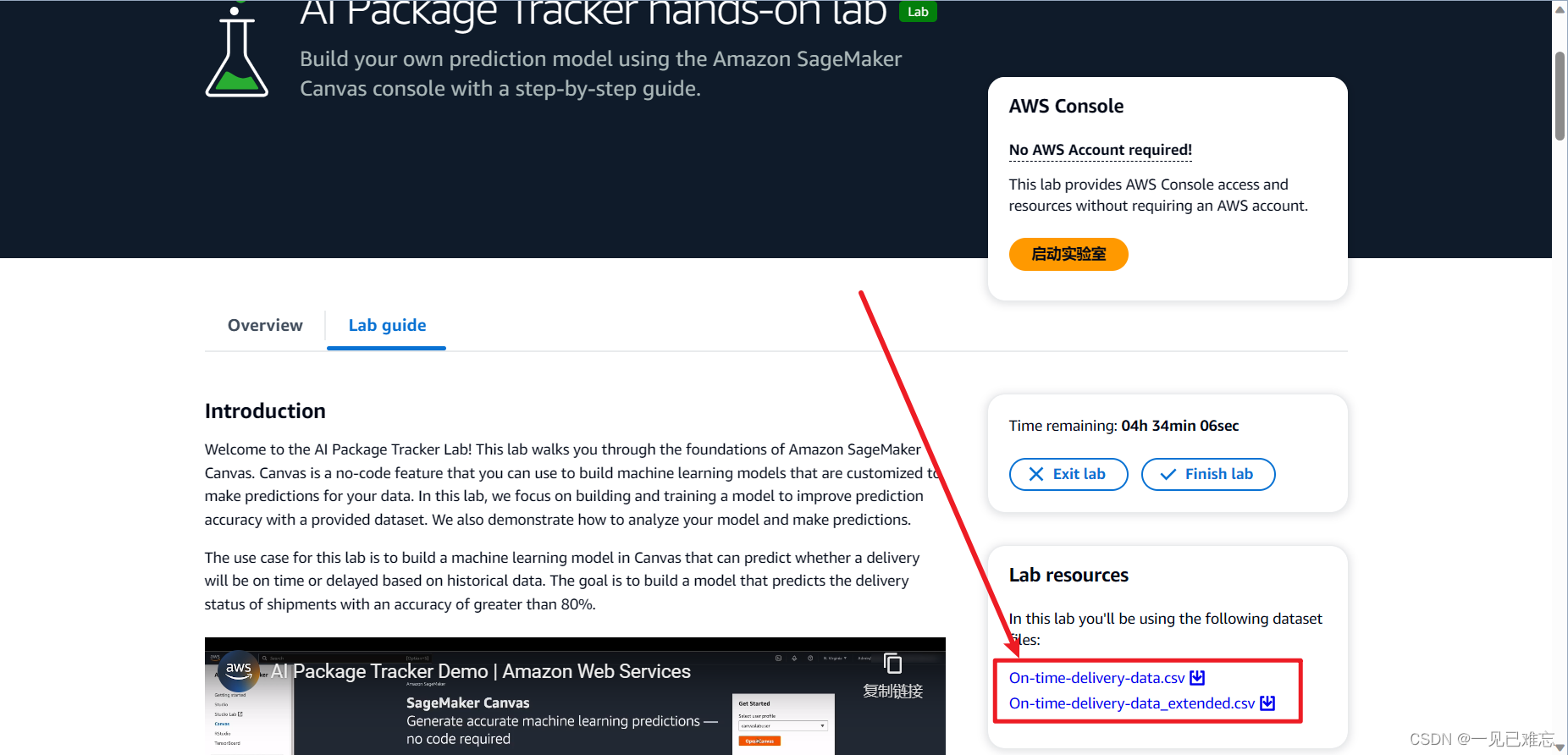
7.第一次点击创建数据集时会自动跳出预览,数据集的前100行,我们检查一下没有问题后继续点击创建数据集。

成功创建的话,我们在Data Wrangler页面可以看到我们刚刚创建的。
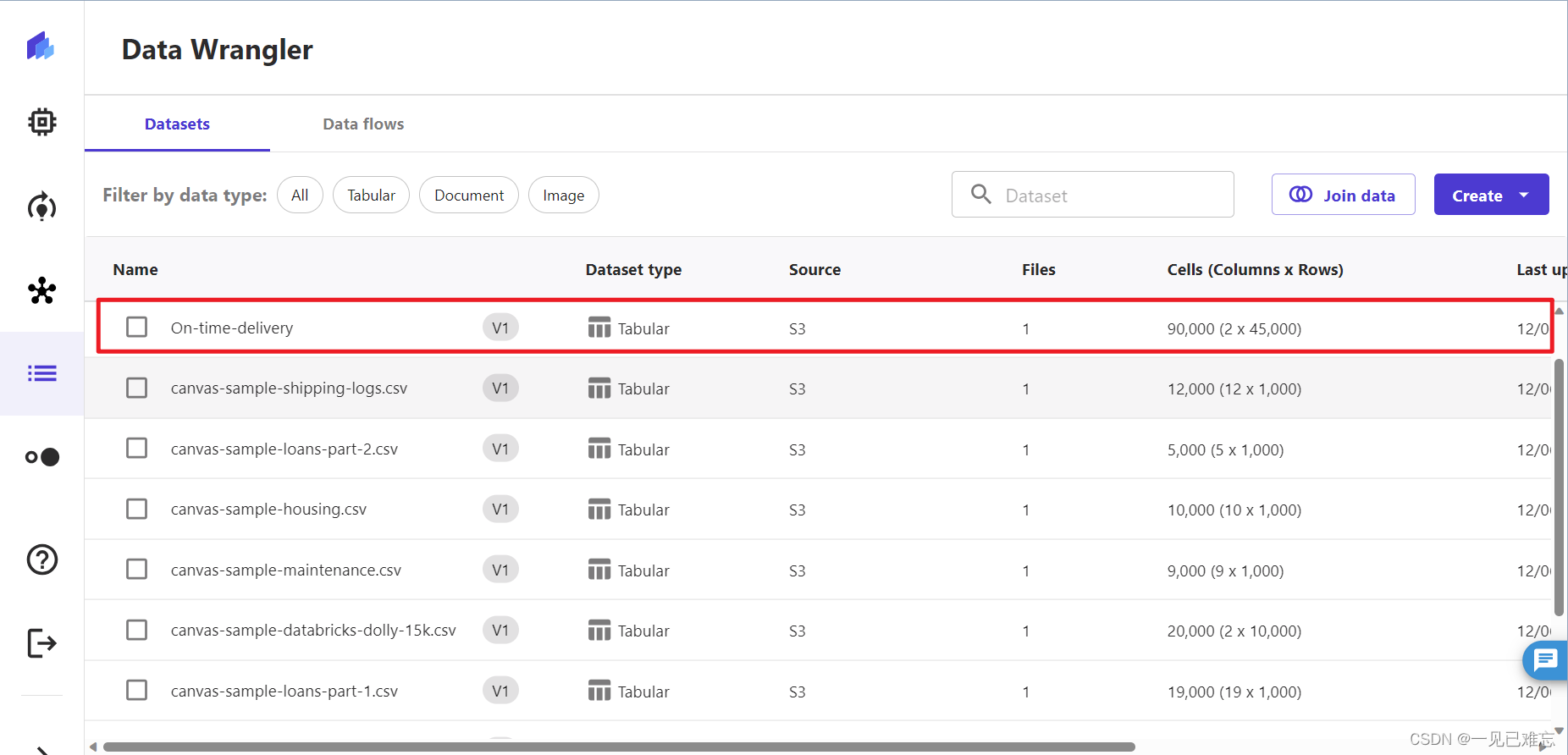
8.按照上面的步骤(1~7),如法炮制创建On-time-delivery-data_extended ,关键步骤截图如下。
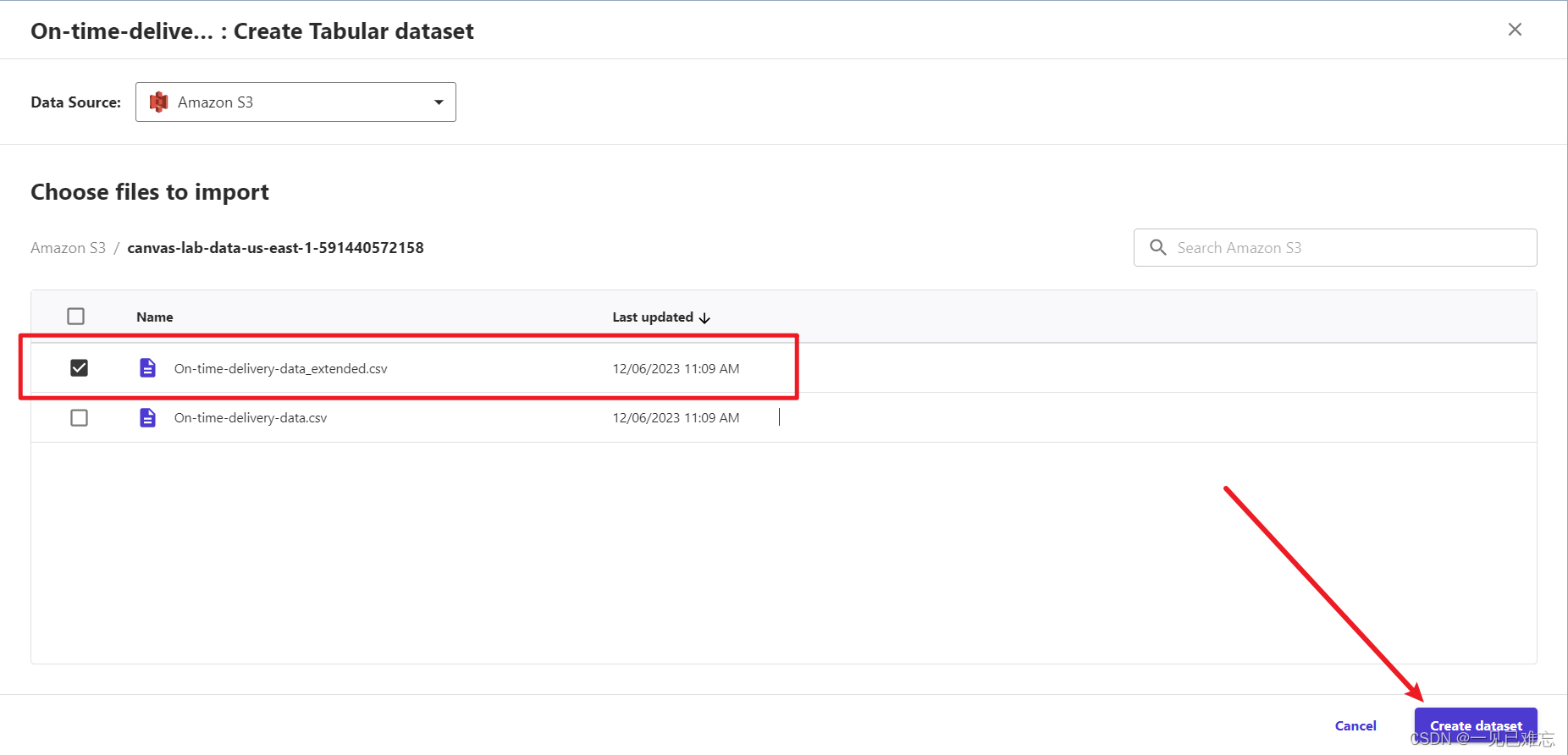
创建完成页面如下:(必须是俩个都成功创建)
本节心得:
在使用Data Wrangler导入数据集的过程中,首先要完成一系列准备步骤,然后通过左侧导航面板中的Data Wrangler进入相应的效果页面。整个导入数据集的过程需要重复执行,创建了两个数据集:on-time-delivery 和 On-time-delivery-data_extended。在整个过程中,截图的使用有助于记录关键步骤,以便用户可以参考和复制操作。
必须夸赞其直观友好的界面设计,用户能够轻松地完成数据集的创建工作。从选择数据类型到指定数据来源,一切操作都得心应手,使得即便是初学者也能够迅速上手!
还有一个优点不得不说:Data Wrangler提供的预览功能,能够在创建数据集之前,通过显示前100行数据,帮助用户检查数据的准确性,确保导入的数据是符合期望的。这对于数据分析和模型训练的准确性有着积极的影响。
🦋2.3 模型创建
我们的任务是在Canvas中构建一个机器学习模型,该模型能够根据历史数据预测交付是否准时或延迟。我们的目标是建立一个模型,其准确率能够超过80%,从而有效地预测货物的交付状态。
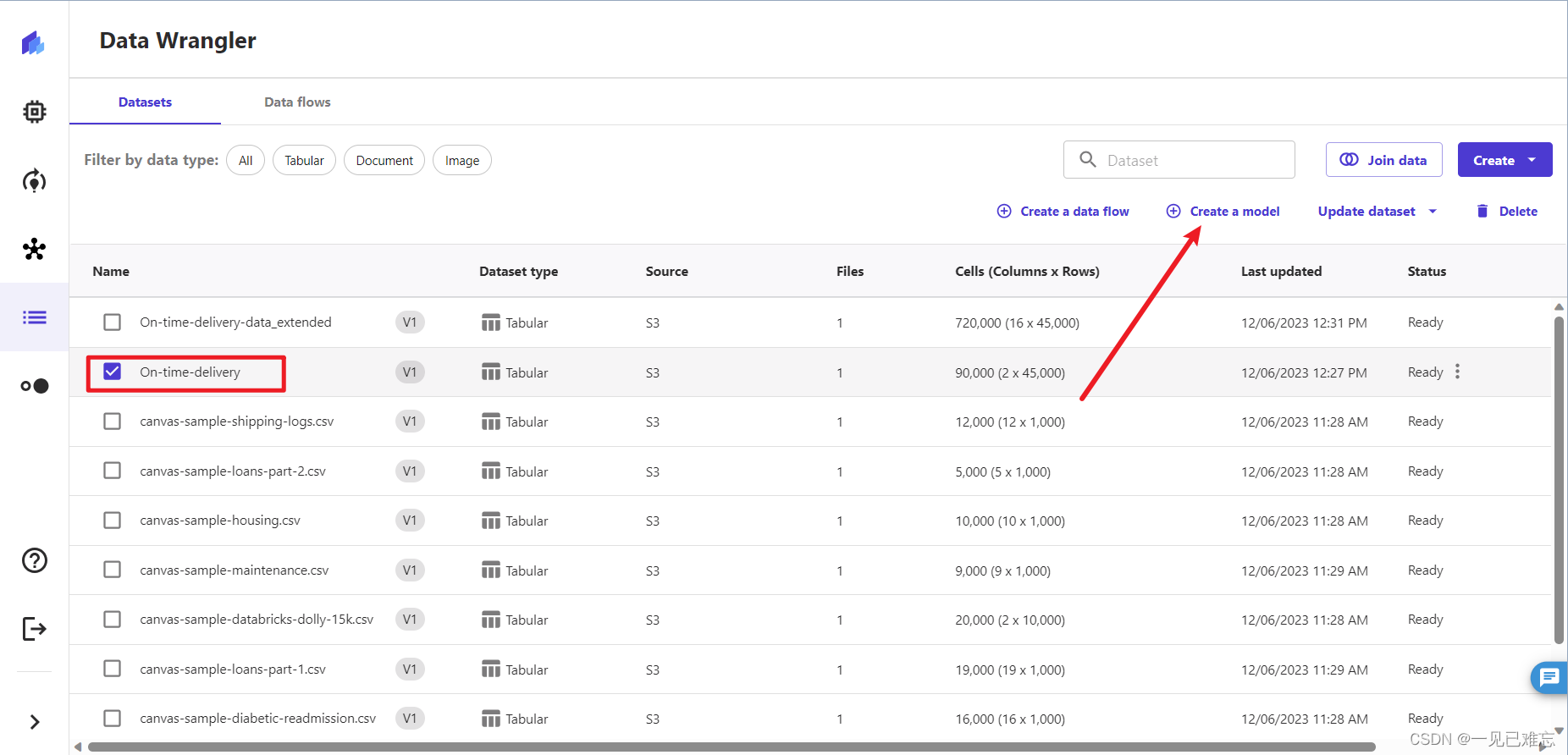
1.在完成2.2的导入数据集步骤后,就可以创建模型了。首先选择上面步骤创建的On-time-delivery,点击上面的创建模型,如下图:
2.创建模型有俩个重要的参数,应该是模型名字,我这里起名为On-time-delivery-data_nanwang(数据集名称+我的博客名:一见已难忘)。问题类型选择:预测分析。
预测分析是:使用表格数据集构建模型,预测单个或多个类别以及回归和时间序列预测问题。
在使用历史数据来构建模型,以便对未来事件或趋势进行预测。这可以涉及预测单个或多个类别,执行回归分析(用于预测数值),以及处理时间序列数据。
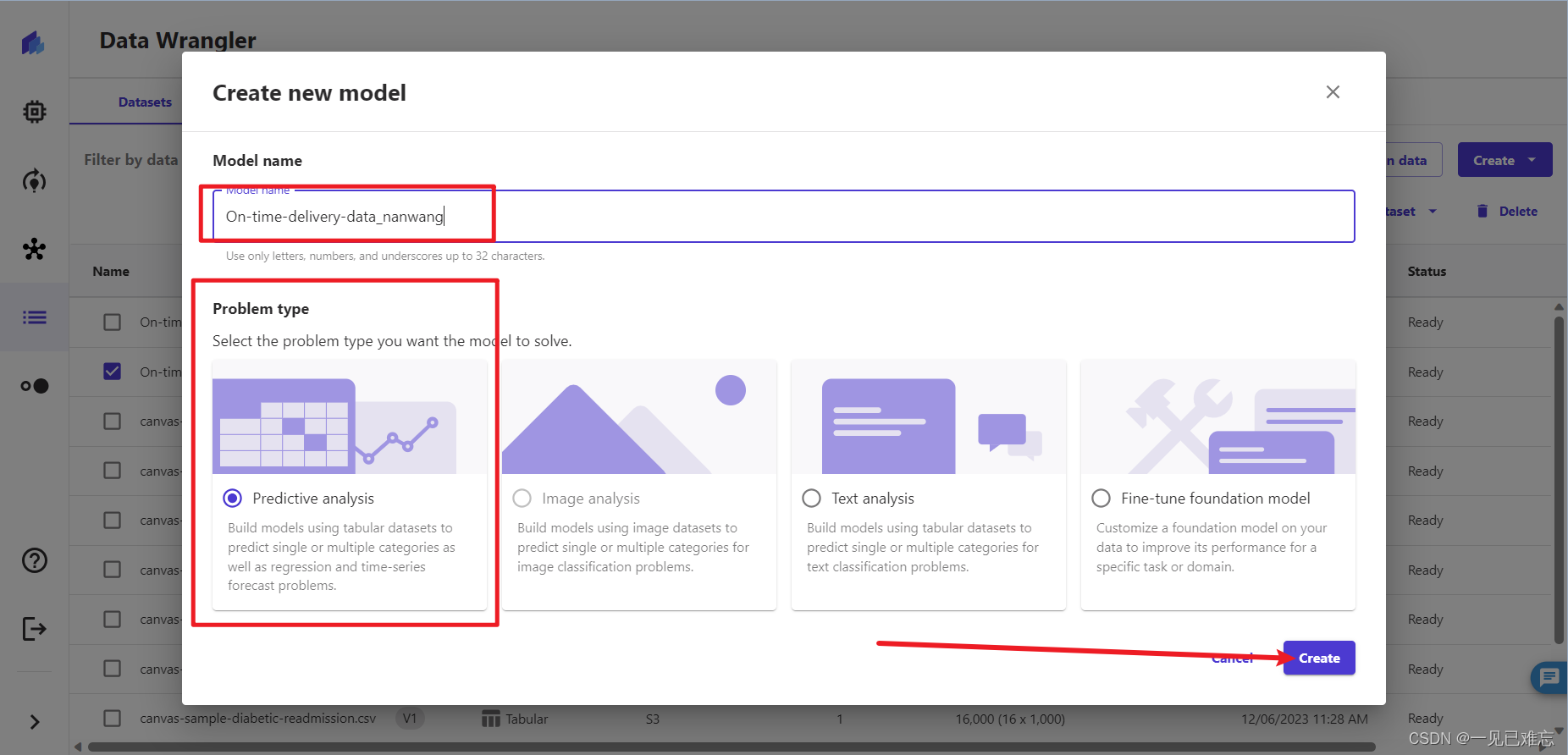
3.创建完成后来到Version1页面,点击Build,在target column里选择classification_ontime(此数据集中的目标有 2 个唯一值:准时值和延迟值,我们选择classification_ontime)
关于模型类型:Canvas 会自动检测此目标是否为 2 类预测模型类型,这块会自动配置不用我们调试。
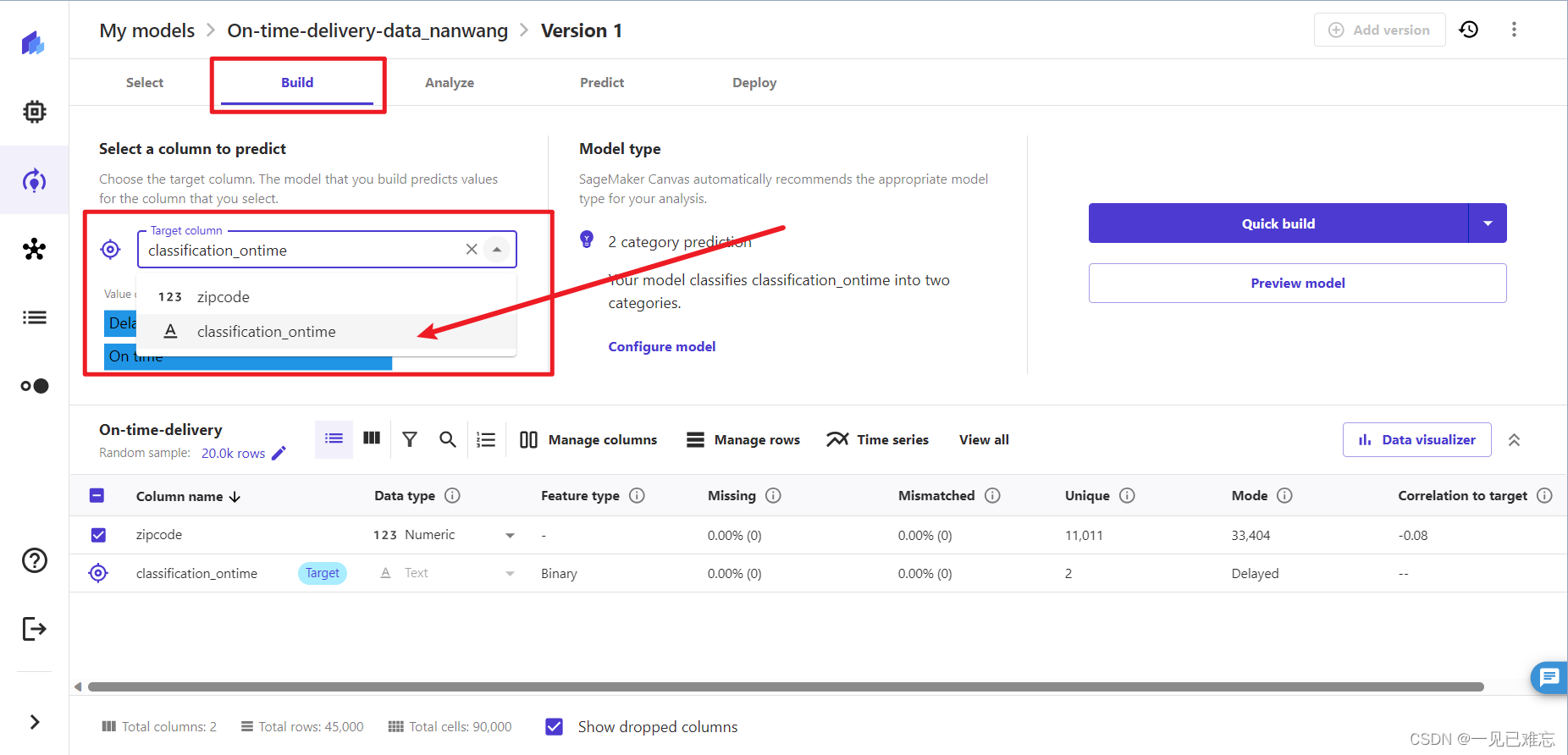
4.当选择完classification_ontime 点击预览模式等待其加载完毕(2min左右),我们可以看到预览模型的精度目前是66.889%,其原没有达到我们精度最低80%的要求
对于这个实验结果,我说一下我的个人猜测,当然真实情况还需后面的步骤进行完善。
我们一般在完成深度学习的相关任务时,是需要重新审视特征集,需要进行更多的特征工程。包括添加新的特征、删除不相关的特征或者对特征进行更复杂的变换等等来优化模型结果。

5.点击Quick build ,使用快速构建功能,构建模型并做出快速预测,如下图,我的构建过程持续了10min左右。
个人评价:对于模型构建时间10多分钟的表现还是相当优秀的,我们习惯了普通的一个模型训练构建时间久长达几小时的。这个模型的构建速度是非常的快了,而且是在无代码的背景下。


6.模型预测结果如下,精度为70.714%,没有达到我们要求的80%以上。
看下面结果可知该模型预测正确的Classification_ontime的概率为70.714%。

模型精度得分:

可以看到目前精度太低,模型的性能通常受训练数据的质量影响,确保训练数据集的标签准确,样本代表性,并且涵盖了各种可能的情况。需要进一步处理数据、分析特征,以提高模型的泛化能力。进行模型改进和优化,直到满足80%以上的准确性要求。
下一步优化想法:
对模型错误的样本进行详细分析,了解为什么模型会犯错。查看特定特征的模式,识别模型在哪些情况下容易出现偏差。
本节心得:
任务目标是在Canvas中构建一个机器学习模型,其预测准确率要超过80%。
我使用了预览模式和快速构建功能,展示了模型的预测结果。但是模型的准确率未能达到80%的要求,仅为70.714%。对于这一点,我提出了个人猜测,在深度学习任务中需要审视特征集和进行更多特征工程的必要性,下文我会继续实验,来改善准确率。
在无代码的背景下,整个模型构建过程仅持续了10分钟左右,这是相当优秀的表现!还有必须强调的一点就是Canvas在无代码环境下模型训练的高效性,非常的nice!
🦋2.4 模型优化
我们需要进行准确性分析,考虑到恶劣天气可能导致包裹延迟,我决定将天气作为一个新的特征加入分析。由于当前数据集不包含与天气相关的信息,我通过引入一个新的数据集,对每个样本添加了13个额外的特征,包括温度、气压、相对湿度以及送货卡车上物品的总数。利用这个更新后的数据集创建一个新的模型版本,并评估其对预测准确性的影响。
1.在模型分析页面,点击上面的添加版本,如下图:
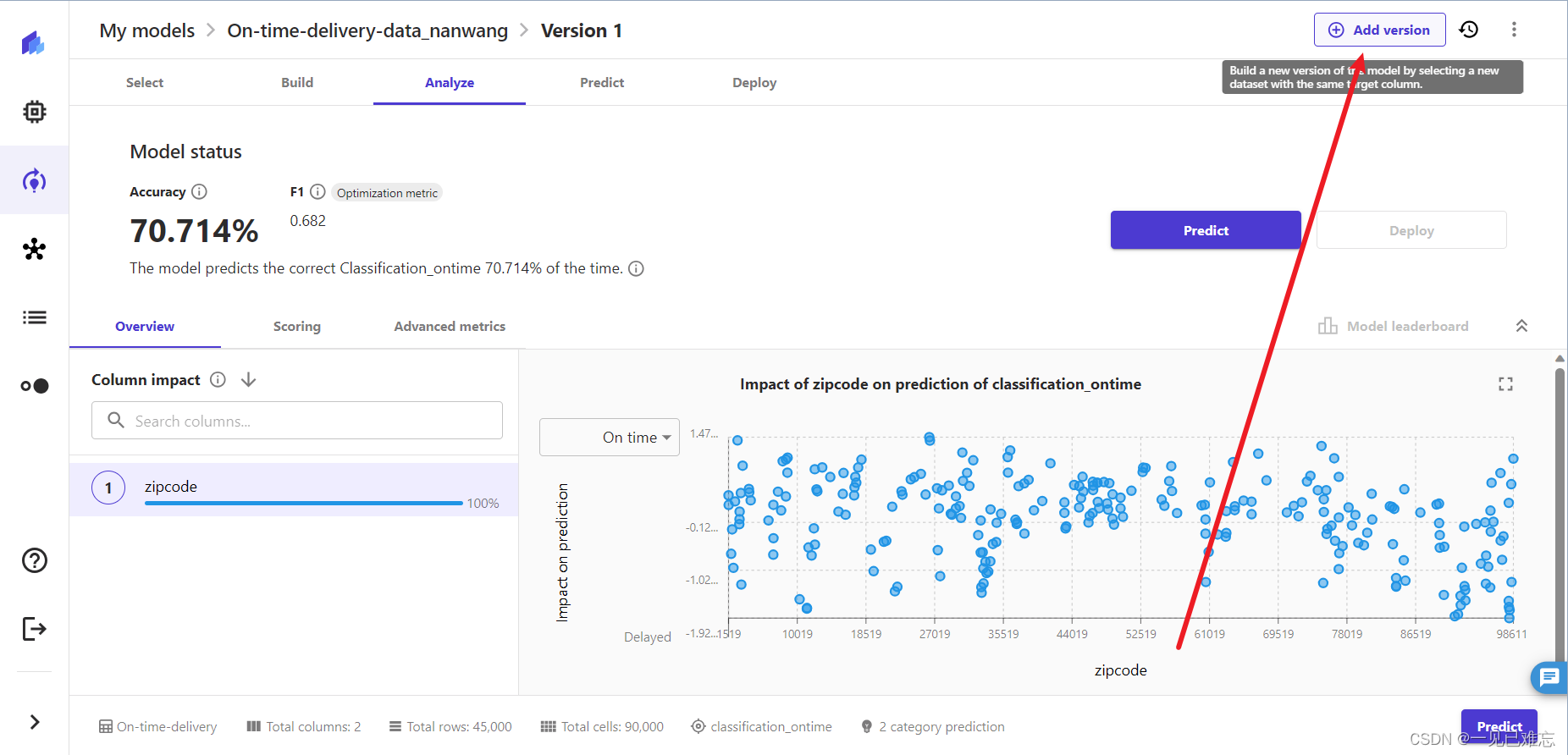
2.选择数据集:On-time-delivery-data_extended,点击Select dataset。
说明一下:我这里的版本是:Version3 是由于操作我迭代了2次,按照上文步骤这里是Version 2,但效果和操作步骤都完全相同,不会对我们的实验操作产生影响。
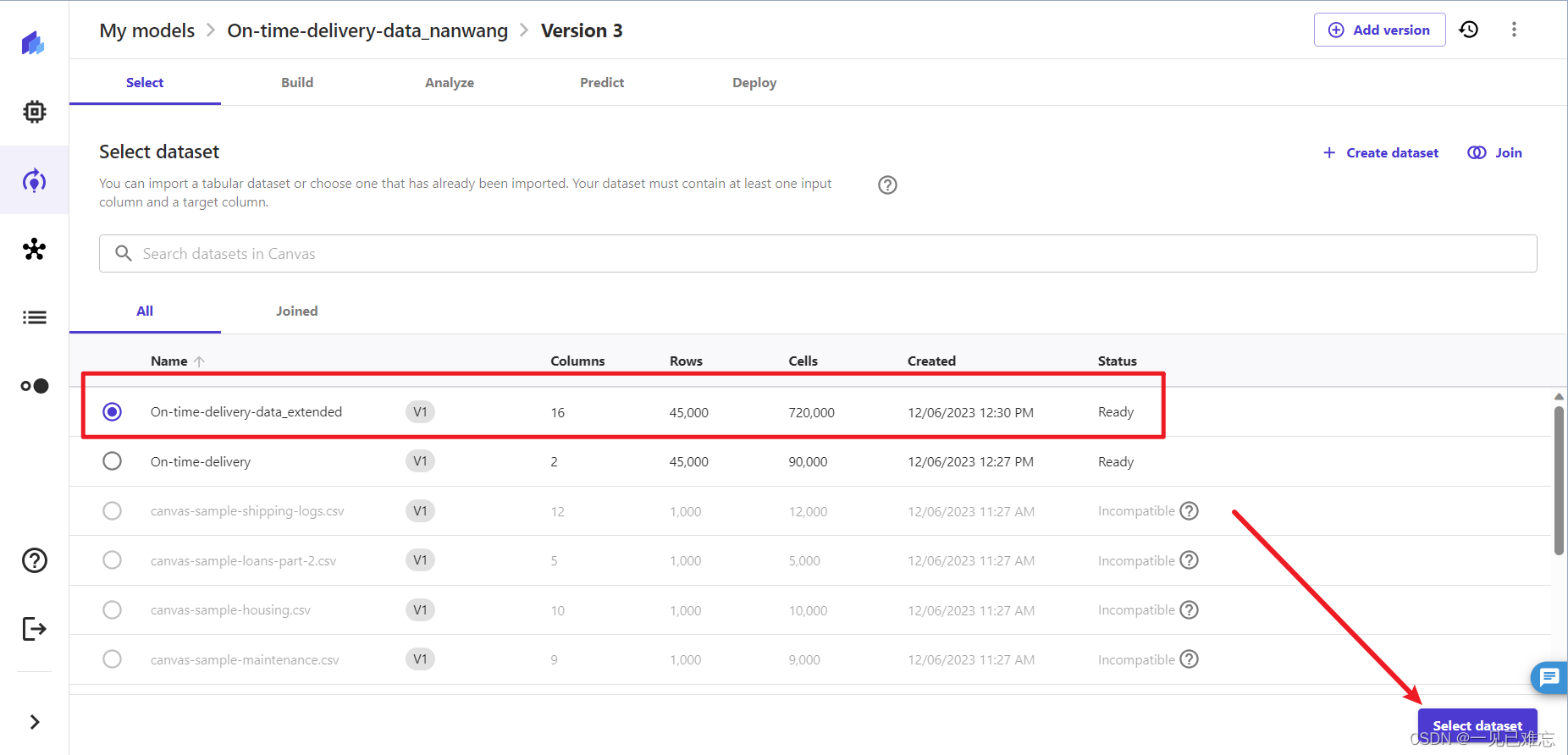
3.我们点击降雨量,该列的所有样本都具有相同的值 0,所以它不会对模型产生任何影响,所以我们将它从数据集里删除,从而更加有效的训练我们的模型。
这步可能有读者比较疑惑,我解读帮助大家理解一下:
点击"降雨量"列后发现所有样本的值都是0,因此这个特征对于训练模型来说是没有提供足够的信息。删除这样的特征可能有助于减少模型的复杂性,提高训练效率,并且通常不会对模型性能产生负面影响。如果大家有相关的基础是会明白这步操作的含义。删除对模型没有贡献的特征是数据预处理中的一种有效策略,是可以提高模型训练和预测的效率的。

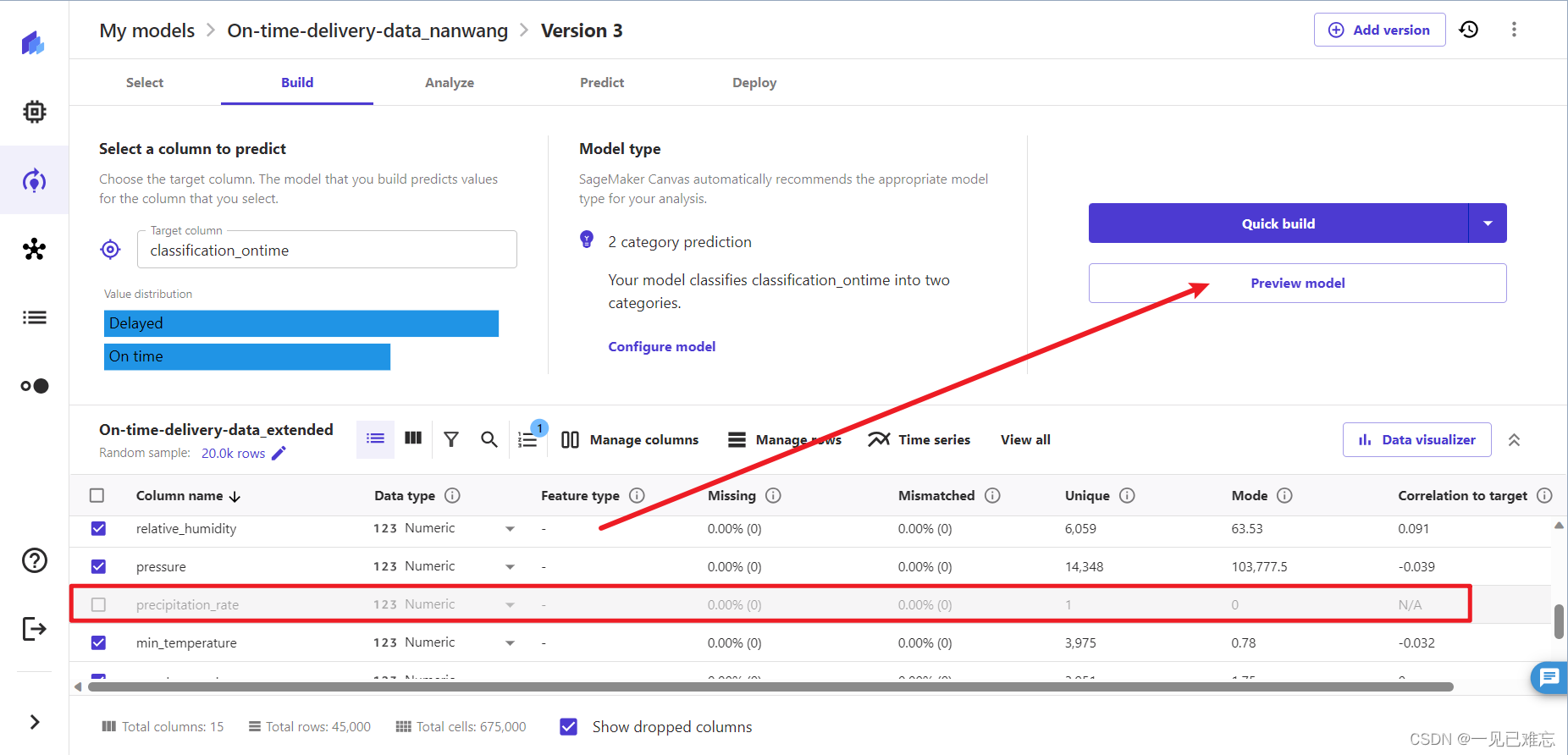
4.删除降雨量特征值后再预览模型,我们可以看到估计的准确值是83.389%,这次的精确度达到了我们要求的80%以上。

在构建页面可以看到每一特征值都进行了可视化操作,这一功能极大的增加了用户友好性。
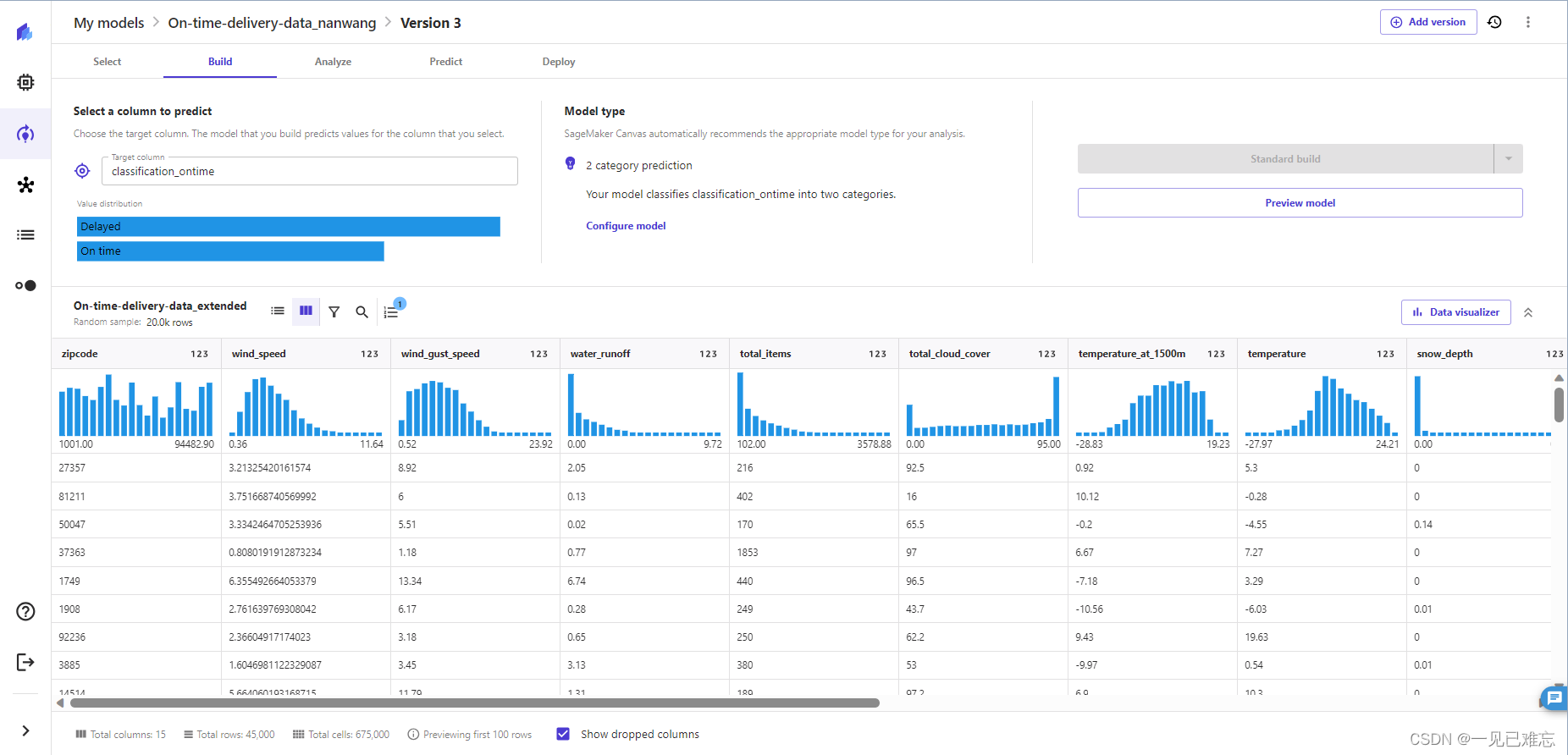
点评:删除降雨量特征值后,成功提高了模型的准确度,达到了80%以上的要求。删除不提供信息的特征是数据预处理中的一种有效策略,有时可以提高模型的性能,减少噪音的影响。
5.我们点击快速构建,这个构建过程大约需要 2-4 小时,我实测用了2个小时多一点就构建完毕了。
对应这个时间还是满意的,如此多的数据,(而且是在无代码的背景下)训练时间2个小时多一点表现十分优秀,已经超越了我们平时使用的个人pc训练速度了,这块还得对我们本次亚马逊云科技发布的产品点个赞,无代码+高性能训练模型给大家带来很大的好处和便利!
Model overview
Your model is being created. Standard build usually takes between 2–4 hours. You can now leave this view.


6.构建完成后,打开模型分析页面(如下图)可以看到准确性为83.413%满足模型准确度要求。

本次优化主要涉及模型优化的过程,特别关注了考虑恶劣天气对包裹延迟的影响,并通过引入新的特征来提高模型的准确性。
本节心得和总结:
- 考虑到天气因素可能影响包裹的准时送达,因此决定引入新的特征,包括温度、气压、相对湿度等,以及送货卡车上物品的总数。通过这种方式,通过更新数据集和创建新的模型版本,提高了对包裹准时送达的预测准确性。
- 删除了降雨量特征,因为在数据集中所有样本的值都是0,这表明这个特征对模型没有提供足够的信息。删除不提供信息的特征是数据预处理中的一种有效策略,能够提高模型的训练效率,减少模型的复杂性。成功提高了模型的准确度,达到了80%以上的要求。
- 在构建页面可以看到每个特征值都进行了可视化操作,这一功能极大地增加了用户友好性。这种可视化操作有助于用户更好地理解数据集的特征分布,从而更好地进行数据分析和模型优化。
- Amazon SageMaker Canvas 有高性能训练速度,在无代码的背景下,快速构建模型只需要2个多小时。亚马逊云科技发布的产品在训练效率上的优越性,为用户提供了便利和高效的模型构建体验。
- 本次优化模型通过引入新特征、数据预处理和高性能训练准确性达到83.413%,满足了模型准确度的要求。我认为亚马逊的新产品在模型建设方面取得了非常好的成绩。
🦋2.5 模型预测
1.我们在上文的模型分析页面点击Predict(模型预测)。
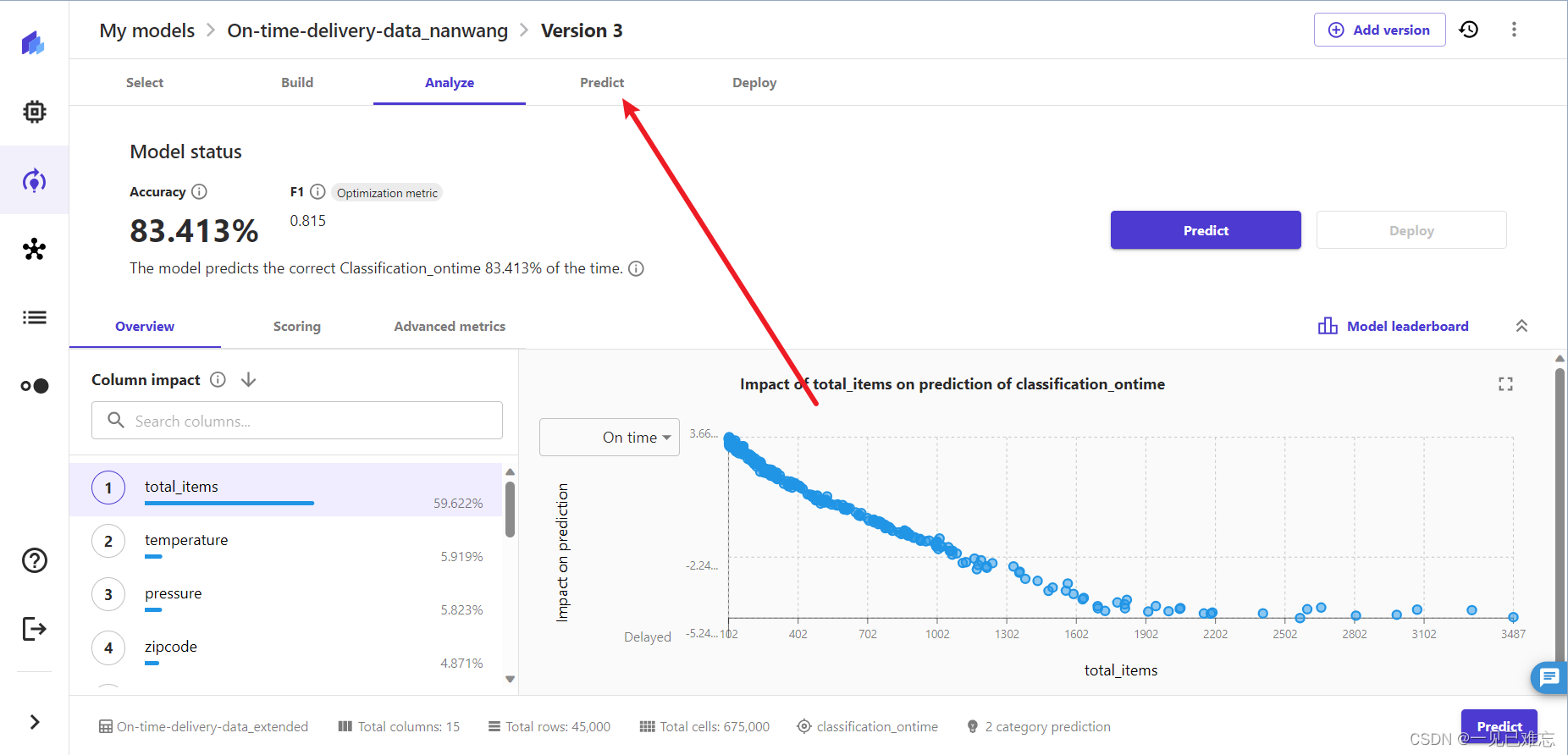
模型预测得分可视化效果图如下:可以直观的看到Amazon SageMaker Canvas给我们提供优秀的可视化效果,在这个页面可以直观的看到模型训练结果。

2.在预测页面中,选择单一预测,如下图:
说明解释:
用户可以通过模型对特定样本或输入进行个别预测,而不仅仅是上面的对整个数据集的预测。这对于了解模型对于特定情况的表现是很有用处的。
3.将total_items的数值改为525,temperature的数值改为 -5.83 。
将temperature_at_1500m的数值改为-7,min_temperature的数值改为-6.5, max_temperature的数值改为-2.
将tlew_point temperature的数值改为-8

个人见解:
将total_items的数值从原先的值改为525,为了在模型中使用一个更适当的货物总数。
温度相关的参数调整是为了更好地匹配实际气象数据。这是基于对环境温度影响的分析,以提高模型的准确性的。
露点温度是相对湿度饱和时空气冷却至饱和状态所需的温度。将dew_point_temperature的数值改为-8是为了更好地反映湿度对系统的影响。
这样做的目标是优化模型的性能,使其能够更准确地拟合实际数据。
4.点击更新,等待5min左右

5.可以看到分类实时预测的预测值已改为延迟,百分百非常高。可以看到特征重要性也发生了变化,压力,温度对预测的影响最大。
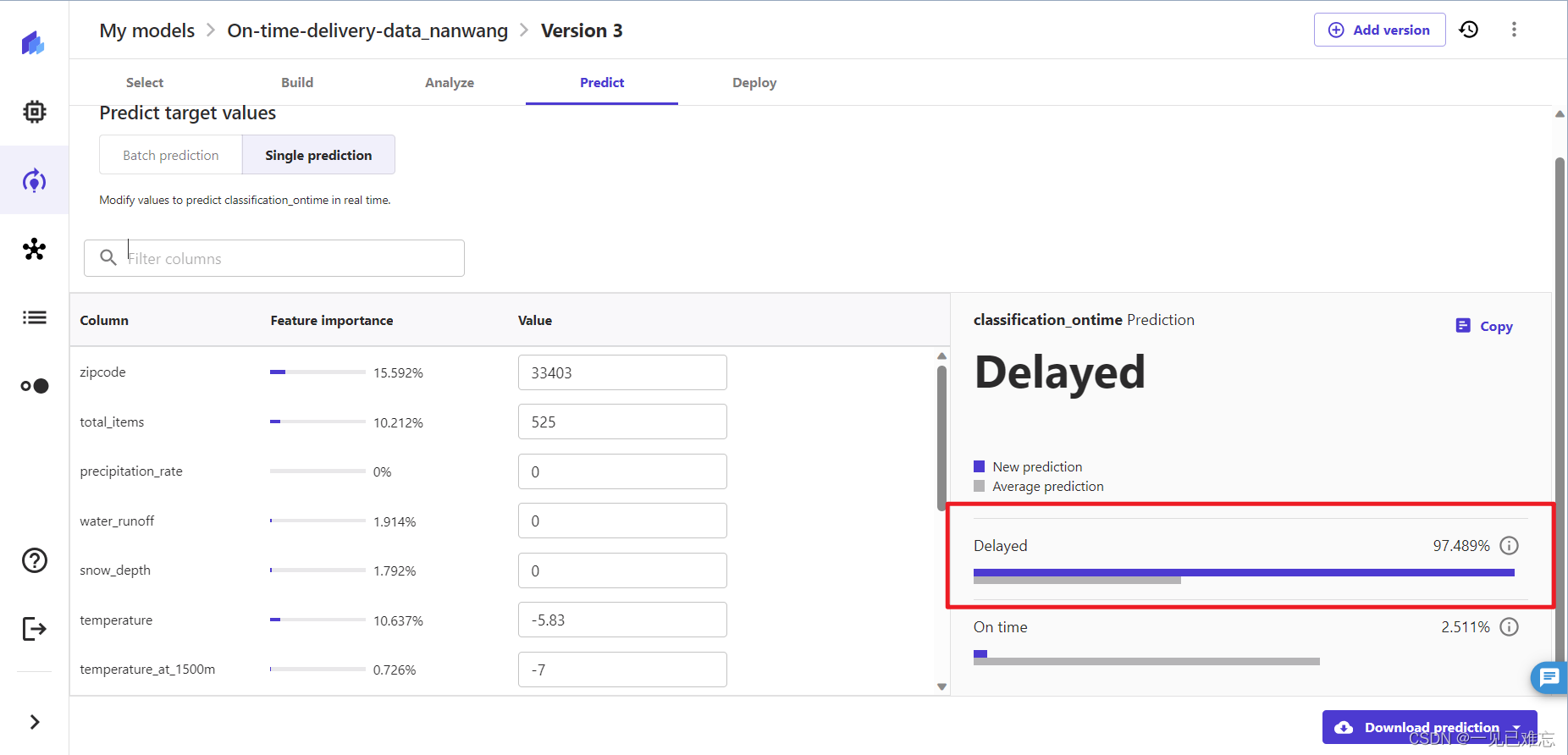
到这里就成功构建了一个模型,来预测货物的交付状态,精确率也达到了80%以上。
本节心得和总结:
- Amazon SageMaker Canvas在模型预测中可以提供的优秀的可视化效果。通过图表和视觉化工具,我们可以直观地了解模型训练的结果。这有助于我们更好地理解模型的性能和预测结果。
- 通过更新参数并观察实时预测结果,调整后的模型在预测值的准确性上取得了显著提升,可以看到特征的重要性。可以学习到模型的可调性和灵活性,是能够更好地适应不同的应用场景的。
- 成功在Canvas中构建一个机器学习模型,该模型能够根据历史数据预测交付是否准时或延迟。其准确率超过了80%,从而有效地预测货物的交付状态,完成任务目标。
🚀三.总结与心得
🔎3.1心得
到了这里我们也就完成了模型的建立,全程的无代码体验过程是相当的nice!,模型的准确率也超过了任务要求的80%以上。
Canvas的可视化点击式界面提供了一个直观、易用的操作平台,可以轻松创建和优化机器学习模型。这种用户友好性大大降低了学习门槛,让机器学习在更广泛的领域中得以应用,让刚入门的小白也可以快速的了解机器学习,深度学习的内容,我觉得亚马逊这次的新产品Amazon SageMaker Canvas的意义十分巨大,我给予这块产品一个好评,期待以后会迭代的更好!
在实验的初期,可以看到我导入数据集和创建模型的步骤都相当直观,而且Canvas的快速构建功能极大地加速了模型的训练过程。在进行模型分析时,我们也能够清晰地看到模型的准确性和相关特征的重要性,这有助于更好地理解模型的性能和优劣。
还有一个亮点就是,在模型准确率未达到要求时,通过引入新的特征进行模型优化的过程。我们可以看到Canvas的灵活性,能够适应不断变化的业务需求。通过不断迭代和改进,最终成功构建了一个高准确率的模型,实现了项目的预期目标。
🔎3.2 总结
在本文中,我们深入学习了亚马逊云科技在2023年 re:Invent 全球大会上发布的 Amazon SageMaker 的新功能——Amazon SageMaker Canvas。
该功能可以通过使用可视化点击界面为分类、回归、预测、自然语言处理(NLP)和计算机视觉(CV)生成准确的 ML 预测。我们通过一个实验项目,我们详细了解了使用该功能构建、训练和优化模型的步骤,以及如何通过引入新特征进行模型的改进,最终成功构建了一个模型来预测货物的交付状态,并且精确度达到80%以上。
Amazon SageMaker Canvas的强大之处在于其直观的用户界面和与SageMaker Studio的集成,使得不具备深度技术背景的业务分析师能够快速创建高效的机器学习模型。通过对实验中的模型优化过程的详细探讨,我们了解到了在构建准确模型的道路上需要不断调整和改进,以适应不同的数据和特征。
Amazon SageMaker Canvas为机器学习领域的从业者提供了一个强大的工具,使其能够更加便捷地应对现实业务场景中的挑战,提升模型的预测准确性。这一新功能的推出无疑为机器学习的应用和普及提供了更为广阔的可能性,进一步推动了云计算、大数据和人工智能等领域的发展。
🚀附录
本文涉及产品官网入口:
亚马逊云科技控制台:amazon控制台入口
Amazon SageMaker:Amazon SageMaker
Amazon SageMaker Canvas:无代码机器学习 – Amazon Web Services
Amazon SageMaker Canvas实验室入口:Amazon SageMaker Canvas | Hands-on lab



![[GWCTF 2019]我有一个数据库1](https://img-blog.csdnimg.cn/direct/9f25e89dde5847a4a4b8d92d58a1bd55.png)