一、背景
大模型的概念已经经过了一年的发酵,大家也渐渐的冷静下来了。一开始大家很兴奋,感觉新的时代要来了,然后就是疯狂,再就是都各自找各自公司的东西怎么与大模型沾点边,要不然今年玩不下去了,就要落伍了。今年年初到年中是个人都在说大模型,AIGC ,chatgpt。现在也有很多模型出来了,特别是那几个大厂的。
二、国内大模型
1. 华为盘古大模型
华为的盘古大模型是一款主打算力模型。这一模型由龙头拓维信息(主营云计算)支持,华为还入股拓维信息旗下的服务器子公司,持股比例达到5%。华为凭借其在云计算领域的领先优势,确保了盘古大模型在算力方面的高性能。
2. 阿里通义大模型
阿里巴巴的通义大模型则主打消费模型。其龙头三江购物(主营消费)是阿里巴巴持股比例最高的A股上市公司,持股32%。通义大模型凭借阿里的零售和消费领域的庞大数据库,为消费市场提供了精准的数据支撑。
3. 腾讯混元大模型
混元大模型由腾讯推出,主打社交模型。腾讯作为世纪华通(主营社交娱乐)的第二大股东,持有10%的股份,确保了混元大模型在社交和娱乐领域的高水平应用。
4. 百度文心大模型
百度文心大模型主打搜索模型,与汉得信息(主营软件服务)合作,百度持有汉得信息股份比例5.26%。文心大模型继承了百度在搜索领域的核心技术,提供了高效、准确的搜索服务。
5. 字节跳动大模型
字节跳动大模型主打文娱模型,与掌阅科技(主营阅读产品)紧密合作,持股比例9.24%。这一模型充分利用了字节跳动在内容分发方面的优势,为文娱产业提供了强有力的支持。
6. 小米AIoT大模型
小米的AIoT大模型与趣睡科技(主营AI家居)合作,小米持有趣睡科技股权比例7.65%。趣睡科技的市值22亿,流通市值仅5亿。小米的AI大模型将首个落地趣睡科技的AI家居场景。
三、文心大模型
文心一言大模型例子

我们来问一下文心大模型的架构

通过大模型我们知道文心大模型的架构如下:
文心大模型是百度自主研发的产业级知识增强大模型,架构包括三层:
- 基础模型层:基于飞桨深度学习平台和文心知识增强大模型,持续从海量数据和大规模知识中融合学习,具备知识增强、检索增强和对话增强的技术特色。
- 工具平台层:提供便捷、高效、安全、易用的工具平台,使得大模型的应用触手可及。
- 生态应用层:文心大模型与飞桨深度学习平台、文心知识增强大模型家族、文心社区一同构成产业级知识增强大模型体系。
此外,文心大模型还包含多个模型家族,每个家族都有多个成员。这些家族在知识、任务、语义三个维度上各有所长,形成互补。同时,家族间也相互借鉴,形成有机整体。
接下来使用大模型完成后面章节的创作
四、如何开发大模型

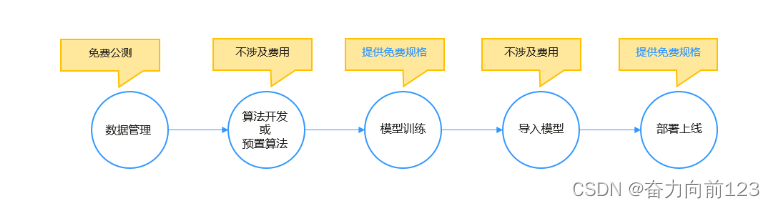
在AI大模型时代,正确地开发和使用AI模型需要遵循以下步骤:
- 明确需求和目标:在开始开发和使用AI模型之前,需要明确具体的需求和目标。这有助于确定所需的数据、模型类型、训练方法等。
- 数据收集和处理:AI模型需要大量的数据进行训练和优化。因此,需要收集与需求相关的数据,并进行适当的预处理和清洗,以确保数据的准确性和可靠性。
- 选择合适的模型:根据需求和目标,选择合适的AI模型。例如,对于图像识别任务,可以选择卷积神经网络(CNN);对于自然语言处理任务,可以选择循环神经网络(RNN)或Transformer模型等。
- 模型训练和优化:使用选定的模型对数据进行训练,并通过调整超参数、优化算法等手段进行优化,以提高模型的性能和准确性。
- 模型评估和测试:在模型训练完成后,需要进行评估和测试,以确定模型的性能和准确性。这可以通过使用验证集、测试集或交叉验证等方法进行。
- 部署和使用:将训练好的模型部署到实际应用场景中,并进行必要的调整和优化,以确保其在实际应用中的性能和稳定性。
在开发和使用AI模型的过程中,还需要注意以下几点:
- 数据安全和隐私保护:在收集和使用数据时,需要遵守相关法律法规和伦理规范,确保数据的安全性和隐私保护。
- 模型的解释性和透明度:AI模型应该具有较高的解释性和透明度,以便用户能够理解模型的决策过程和结果。
- 模型的鲁棒性和泛化能力:AI模型应该具有较高的鲁棒性和泛化能力,以应对不同的场景和数据分布。
- 持续学习和更新:随着技术和数据的不断发展和变化,AI模型也需要持续学习和更新,以保持其性能和准确性。
总之,正确地开发和使用AI模型需要综合考虑多个方面,包括需求、数据、模型、评估、部署等。同时,也需要遵守相关法律法规和伦理规范,确保AI技术的可持续发展和应用。
可以看出开发ai模型的步骤大概如此:

![[GWCTF 2019]我有一个数据库1](https://img-blog.csdnimg.cn/direct/9f25e89dde5847a4a4b8d92d58a1bd55.png)