1、数组
1.1 简介
什么是数组? 他优缺点是什么?具体应用有哪些?
-
「数组 array」是一种基于顺序存储的线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的「索引 index」。
- 如图:
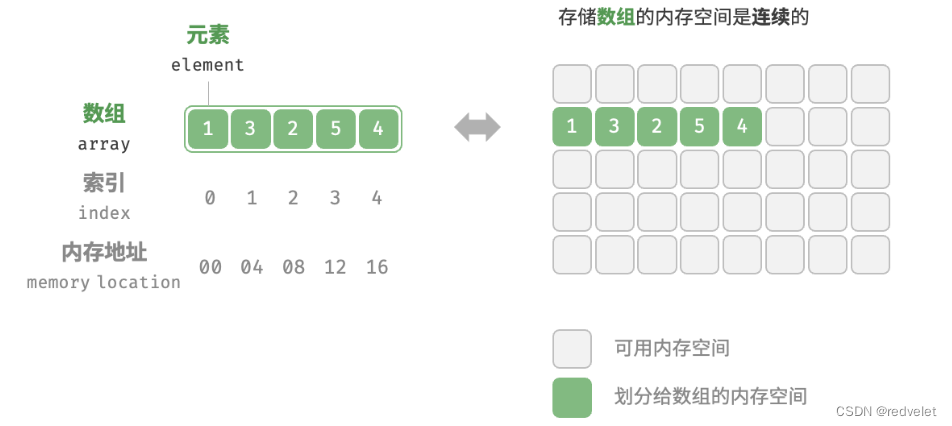
- 如图:
-
由于数组的存放相同类型的元素集合,且是顺序存储。
- 优点:
- 通过索引访问,支持顺序查找,访问速度快:我们只需要知道第一个元素的内存位置和元素类型(数据类型)的大小,就可以通过数学公式计算下一个的位置,这也是通过索引访问的本质。
- 例如:第一个元素的位置为0x11,数据类型为4个字节,则第二个元素的位置就当前元素+1一个4字节,这不就是array[1] –> 第二个元素
- 同理array[5] –> 第六个元素,第六个元素的位置就首元素+6个4字节长度
- 元素位置 = 首元素内存位置 + 需要访问元素第几个 * 数据类型字节
- 每次访问元素,无论访问哪个,计算出来的花费的次数都是一次,访问速度:O(1)
- 通过索引访问,支持顺序查找,访问速度快:我们只需要知道第一个元素的内存位置和元素类型(数据类型)的大小,就可以通过数学公式计算下一个的位置,这也是通过索引访问的本质。
- 缺点:
- 由于数组分配的是固定的内存,每次不够用要扩容,需要重新进行排列和分配,需要消耗时间
- 如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次复制到新数组,假如数组长度为n,则需要复制n次,扩容/缩容:时间复杂度为:O(n)
- 数组一次分配大片空间,可能有部分没有使用,会造成浪费
- 由于数组分配的是固定的内存,每次不够用要扩容,需要重新进行排列和分配,需要消耗时间
- 优点:
-
具体应用:所有的数据结构都是基于数组 / 链表实现的。
- 数组具体的应用有基于数组的集合(动态数组)
- 用于hash表存储,每个位置是一个hash槽
- 具体实现:array list、hashmap、stack等等
1.2 常用操作
初始化数组和访问:
/* 初始化数组 */
int[] arr = new int[5]; // { 0, 0, 0, 0, 0 }
int[] nums = { 1, 3, 2, 5, 4 };
/* 访问数组:数组名[索引下标] */
int arr1 = arr[0];
int arr2 = arr[1];
arr[2] = 1;
遍历:
/* 遍历数组 */
void traverse(int[] nums) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < nums.length; i++) {
count += nums[i];
}
// 直接遍历数组元素
for (int num : nums) {
count += num;
}
}
扩容:缩容同理
/* 扩展数组长度 */
int[] extend(int[] nums, int enlarge) {
// 初始化一个扩展长度后的数组
int[] res = new int[nums.length + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < nums.length; i++) {
res[i] = nums[i];
}
// 返回扩展后的新数组
return res;
}

![[GWCTF 2019]我有一个数据库1](https://img-blog.csdnimg.cn/direct/9f25e89dde5847a4a4b8d92d58a1bd55.png)