文章目录
- 前言
- 背景
- 朴素做法
- Redis方案
- 流量统计
- 接口演示
- 自定义注解
- 计数实现
- 防刷
- 加锁
- 完整代码
- 数据一致性
- 分析
- 自定义注解
- 返回值分析
- 解决方案
- 总结
前言
okey,我们来收尾一下,这公历纪年2022年12月31日。这是本年度的最后一篇博文。那么这篇博文主要是用来实现博文的一个访问记数用的。
背景
这个是我现在还在写的一个项目,没办法事情太多,加上最近状态很不好所以一直在做。那么这个的话就是这个:
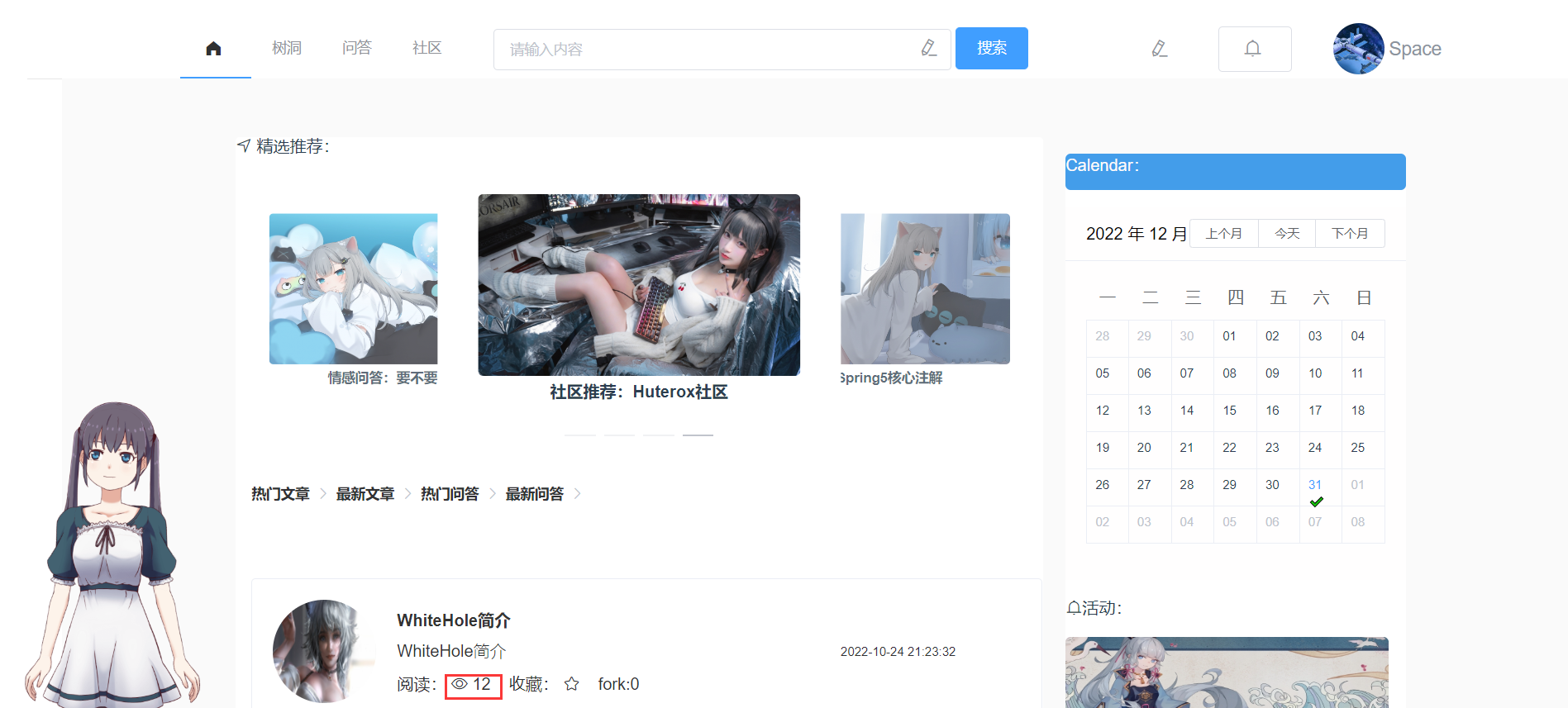
我们要对这个阅读做到一个实时的统计。
朴素做法
文章浏览量统计,最朴素的做法就是:用户每次浏览,前端会发送一个GET请求获取一篇文章详情时,会把这篇文章的浏览量+1,存进数据库里。
分析存在的问题:
在GET请求的业务逻辑里进行了数据的写操作!
高并发,数据库压力太大,文章浏览量+1会存在线程不安全问题,加锁会很慢。
同时如果文章的一些数据做了缓存操作,没有及时更新缓存当中的数据,会导致数据不一致的情况。
Redis方案
常规一点的思路,或者基本一点的做法可以和redis进行一个结合。
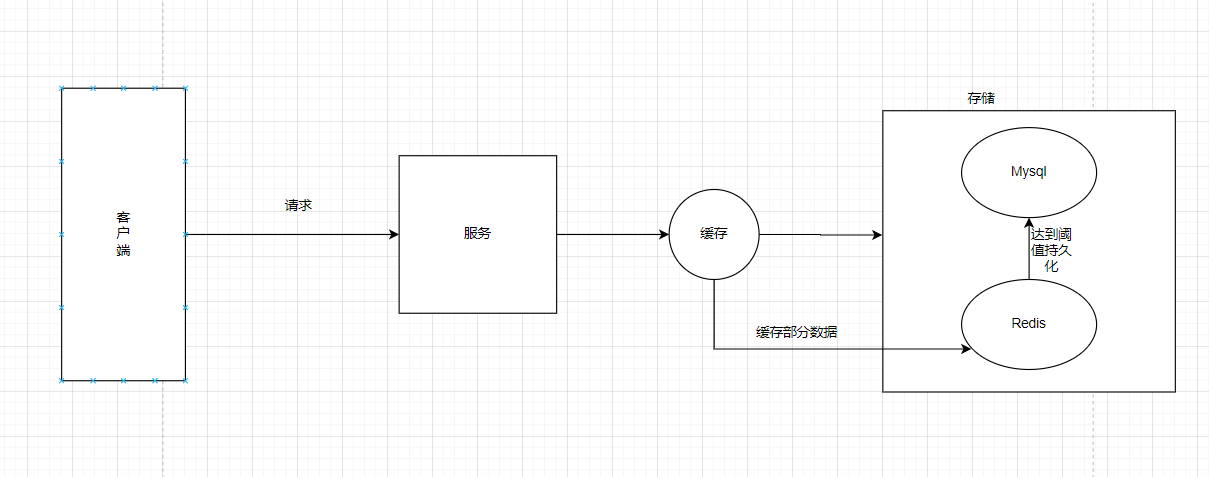
我们将访问的流量给缓存在Redis当中,当达到某一个阈值,例如流量为100或者别的数值的整数倍的时候,我们就刷新数据到数据库当中。这一来降低了对于写Mysql写的操作。同时按照我们的博文来说,博文的内容在短时间内是不太会发生变动的,因此这个东西也应该是做缓存处理的(实际上我也是这样处理的)。因此这里的话就有两个问题:
- 将访问量在redis当中进行存储,并且也需要做到持久化处理
- 保持数据一致性,对于一些历史缓存,必须保证里面的访问数据是最新的
同时由于涉及到的接口较多,对于代码级别的改动必须降低。
OK,那么接下来的话,咱们就针对这几个问题进行一个处理。
流量统计
okey,我们先来解决第一个问题,就是我们的一个流量的统计。
在这里的话我是这样设计的。
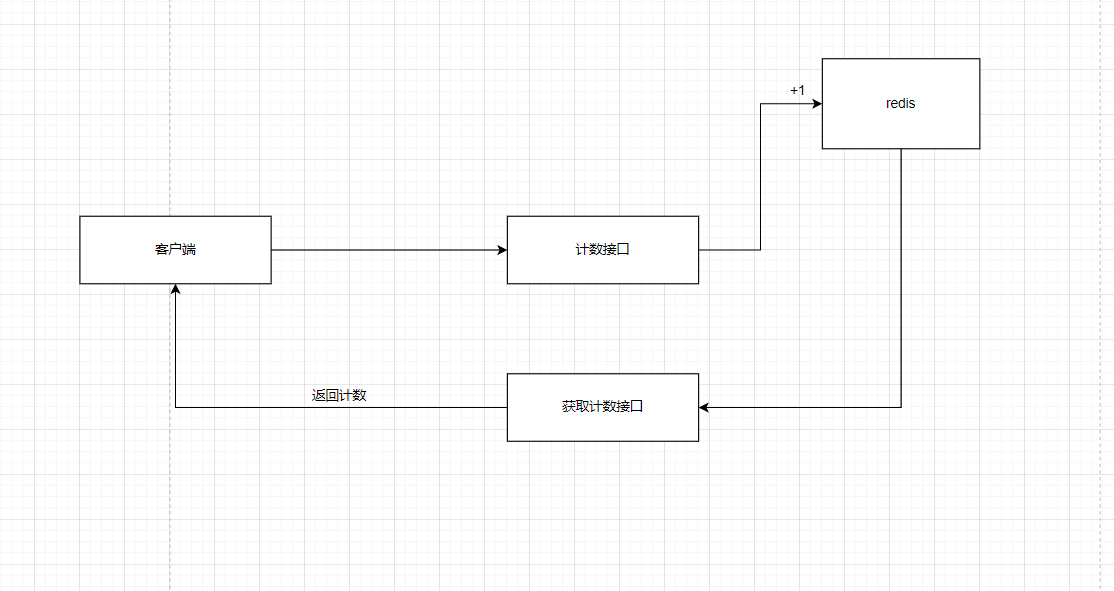
但是值得一提的是,在这里如果我们需要严格保证数据的一致性的话,那么我们的技术接口在访问的时候,必须要加上一个分布式锁,这个时候,你要考虑的就是值不值得了。如果说这个数据非常重要,那么我们就上锁,安全,如果你认为数据并不是很重要,并且幻读是可以被允许的话,那么就没有必要去加锁。
当然咱们这里还是加一把锁,同时咱们这里的实现的话也是要做到防止有人刷访问量,毕竟这活以前干过--
那么咱们的过程的话也是看到了,其实很简单就是你首先访问特定的接口,然后呢再去访问博文,或者其他的一些有显示这些数据的接口,然后就可以拿到最新的一个状态。
接口演示
okey,我们来看到我们的接口的一个演示:
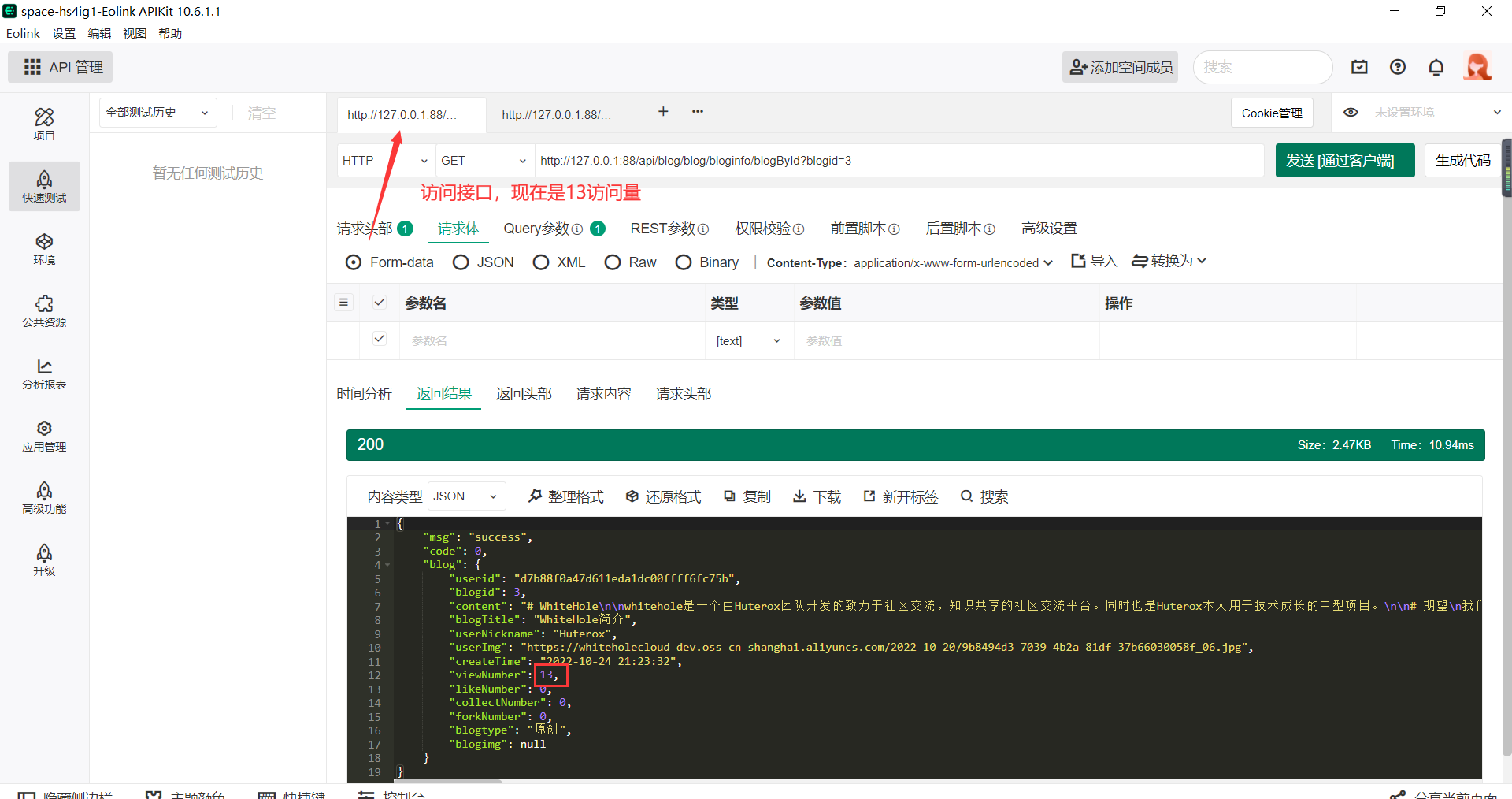
之后我们访问那个可以+1的接口
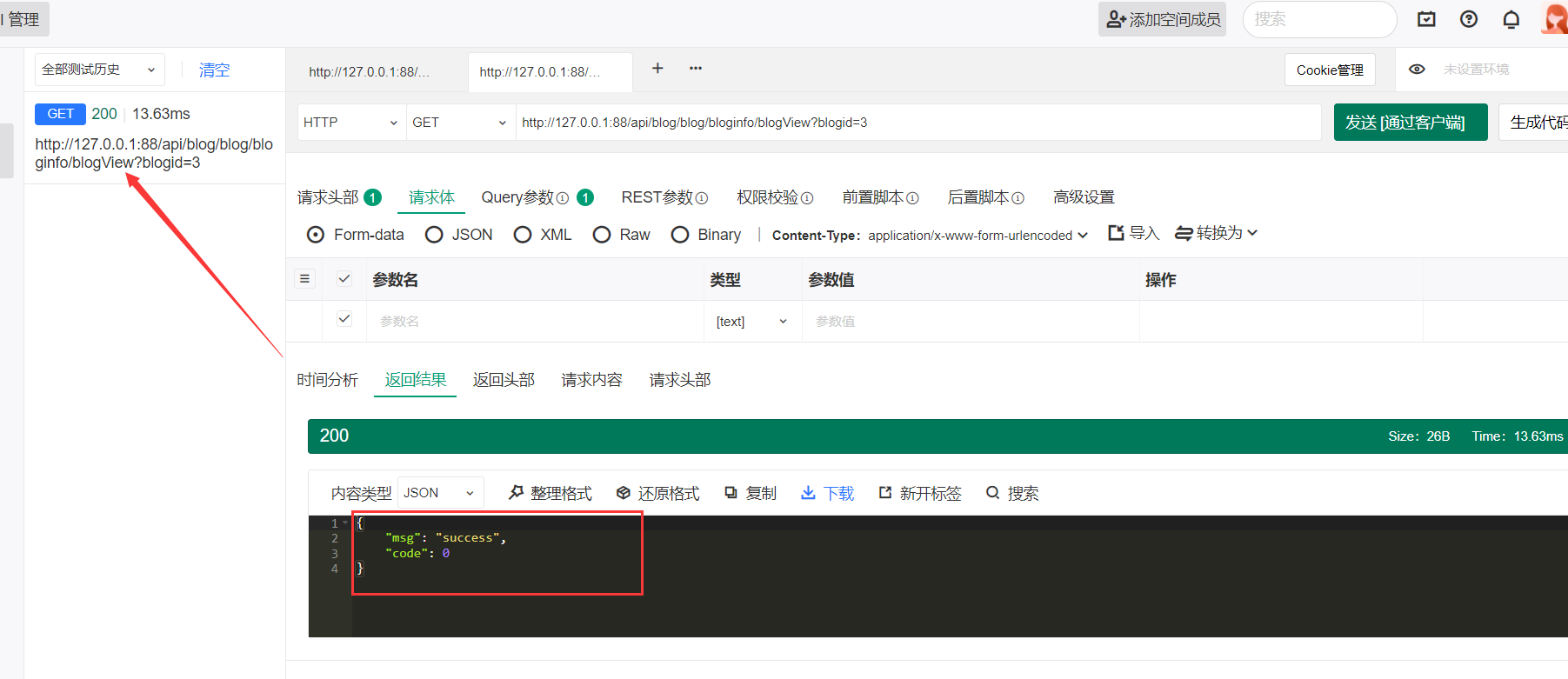
此时回到刚刚的接口,查看数据:
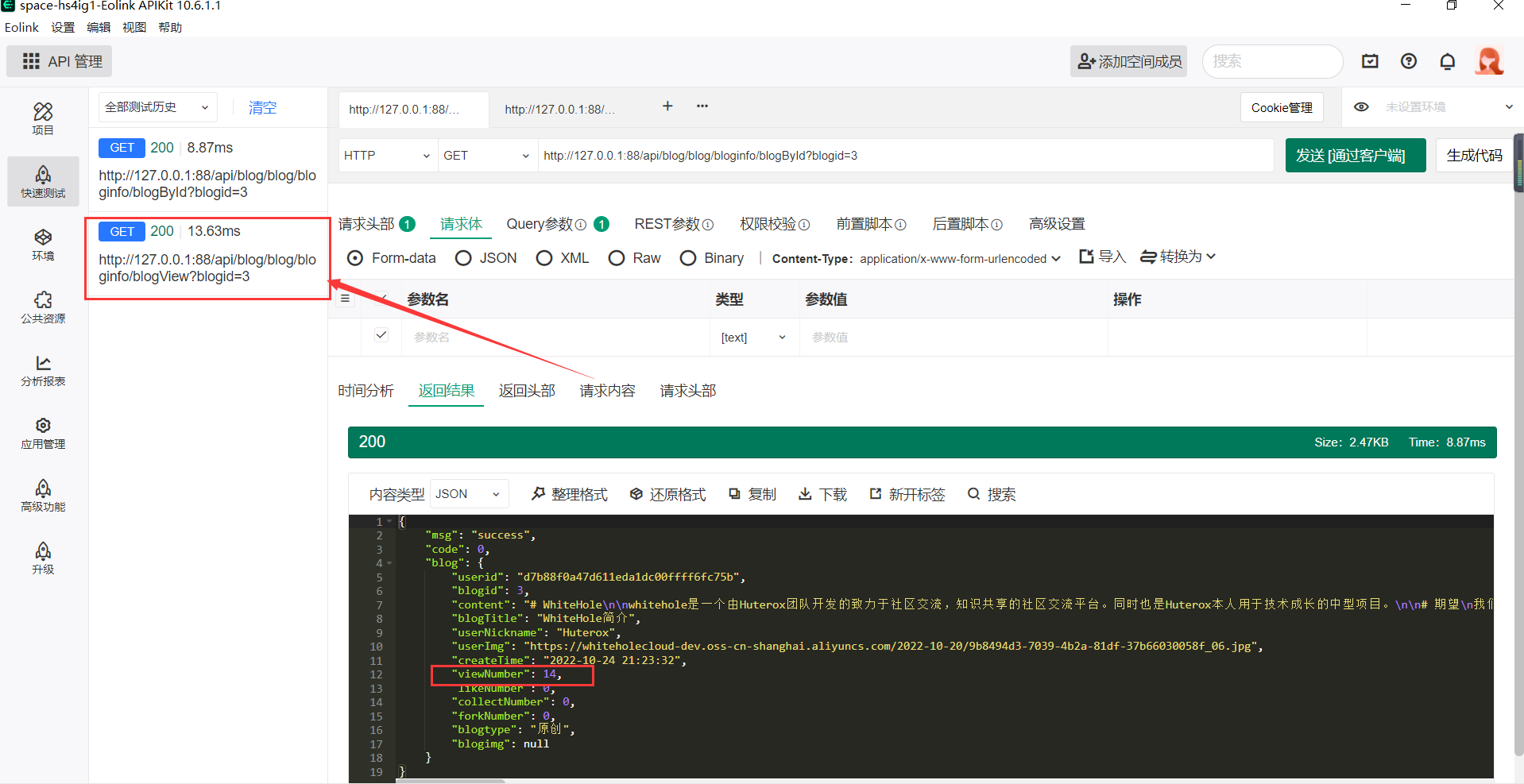
现在+1了。
这样一来我们的基本目标就算明确了。
那么接下来我们要做的就是实现这个东西。
自定义注解
刚刚我们说了需要把对代码的修改降底,那么我们就需要去使用到咱们的一个切面来做处理。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ViewNumberUp {
//传入模式
String mode() default "";
}
之后的话,我们还需要去定义一下这个数据结构,就是咱们的这个流量数据长啥样:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class BlogViewNumber {
private static final long serialVersionUID = 1L;
private Integer viewNumber=0;
private Integer likeNumber=0;
private Integer collectNumber=0;
private Integer forkNumber=0;
private String ip;
}
这里的话,我们这块有4个需要计量的数据,因此的话,我们刚刚的注解里面有一个出入模式的东西。
不过值得一提的是,处理访问量这种东西是不能撤回的,其他的其实都是可以撤回的,比如你收藏,你可以收藏,也可以取消收藏。这些东西的话我这里使用类似方法处理过,但是为了让这个东西看起来“更强大”因此我还是做了个保留。
计数实现
那么接下来的话就是实现我们的一个博文的计数了。
防刷
这里防刷的手段有很多,那么我这里的话选择了比较简单的方案,这个方案就是通过IP去判断。假设A访问了,那么我就几下A的IP,当B访问的时候,我对比一下当前的IP和A的是不是一样的,如果不是那么访问量+1,同时刷新IP为B的,如果B的和A的一样,那么不好意思不加1,我认为是同一个人。当然也可以按照你的用户的id来。游客可能没有id,那么你可以选择分配一个临时id,或者干脆就游客不算。
if (!blogViewNumber.getIp().equals(ipAddr)) {
blogViewNumber.setViewNumber(blogViewNumber.getViewNumber() + 1);
blogViewNumber.setIp(ipAddr);
}
那么在这块我们需要使用到这个获取IP的工具类:
public class GetIPAddrUtils {
public static HttpServletRequest GetHttpServletRequest(){
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes) requestAttributes;
assert servletRequestAttributes != null;
return servletRequestAttributes.getRequest();
}
public static String GetIPAddr() {
HttpServletRequest request = GetHttpServletRequest();
return GetIPAddr(request);
}
public static String GetIPAddr(HttpServletRequest request) {
String ipAddress = null;
try {
ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
if (ipAddress.equals("127.0.0.1")) {
// 根据网卡取本机配置的IP
try {
ipAddress = InetAddress.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
// 通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null) {
if (ipAddress.contains(",")) {
return ipAddress.split(",")[0];
} else {
return ipAddress;
}
} else {
return "";
}
} catch (Exception e) {
e.printStackTrace();
return "";
}
}
}
加锁
之后的话,我们加锁,这个是没有办法的,包括我们刚刚判断这个刷访问量的时候也是这个问题,如果不加锁,举个例子,A,B,C三个人。A访问了,现在访问量是1,当B,和C同时访问的时候,B,和C读取到的访问量都是1,加上1之后为2,当B,C都写回去数据的时候,访问量就2.但是实际上有3个人访问了。这个就不准。因此得想办法,我们必须得加锁,但是还是那句话,如果你认为这个是可以接受的,那么就不加锁,这样的话会节省资源。
RLock lock = redissonClient.getLock(redisPrefix);
lock.lock(10, TimeUnit.SECONDS);
try {
if(redisUtils.hasKey(redisPrefix)){
this.addCache(redisPrefix,blogid,mode,false);
}else {
BlogViewNumber blogViewNumber = new BlogViewNumber();
//通过数据库拿到博文的流量数据,然后放到我们的redis当中
BlogEntity blogEntity = blogService.getById(blogid);
BeanUtils.copyProperties(blogEntity,blogViewNumber);
String ipAddr = GetIPAddrUtils.GetIPAddr();
blogViewNumber.setIp(ipAddr);
redisUtils.set(redisPrefix,blogViewNumber);
this.addCache(redisPrefix,blogid,"pv",true);
}
} finally {
lock.unlock();
}
完整代码
这个代码的话,只需要看到一个case为pv的情况就好了,其他的是其他的,关系不大。
@Component
@Aspect
@Slf4j
public class BlogViewNumberAspect {
private static final String viewNumberPrefix = RedisTransKey.viewNumberPrefix;
@Autowired
private RedisUtils redisUtils;
@Autowired
BlogService blogService;
@Autowired
RedissonClient redissonClient;
@Value("${blog.pv}")
private Integer blogPv;
@Pointcut("@annotation(com.huterox.common.holeAnnotation.ViewNumberUp)")
public void pageViewAspect() {}
/**
* 这里负责处理我们的切面,主要是处理我们一些流量信息的记录
* 1. 初始化时将博文的数据写缓存当中
* 2. 初始化后,更新缓存当中的数据
* 3. 浏览量比较特殊,不需要每次都刷新数据库
* 此外二外开放一个专门获取博文流量信息的接口(这个接口上的数据将从redis当中获取)
*/
@AfterReturning(value = "pageViewAspect()&& @annotation(viewNumberUp)",
returning = "result")
public void around(JoinPoint joinPoint,ViewNumberUp viewNumberUp, R result) throws Exception {
int code = Integer.parseInt(result.get("code").toString());
if(code!=0){
return;
}
assert viewNumberUp!=null;
String mode = viewNumberUp.mode();
Map<String, Object> nameAndValue = getNameAndValue(joinPoint);
Long blogid = Long.valueOf(nameAndValue.get("blogid").toString());
String redisPrefix = viewNumberPrefix+":"+blogid;
RLock lock = redissonClient.getLock(redisPrefix);
lock.lock(10, TimeUnit.SECONDS);
try {
if(redisUtils.hasKey(redisPrefix)){
this.addCache(redisPrefix,blogid,mode,false);
}else {
BlogViewNumber blogViewNumber = new BlogViewNumber();
//通过数据库拿到博文的流量数据,然后放到我们的redis当中
BlogEntity blogEntity = blogService.getById(blogid);
BeanUtils.copyProperties(blogEntity,blogViewNumber);
String ipAddr = GetIPAddrUtils.GetIPAddr();
blogViewNumber.setIp(ipAddr);
redisUtils.set(redisPrefix,blogViewNumber);
this.addCache(redisPrefix,blogid,"pv",true);
}
} finally {
lock.unlock();
}
}
private void addCache(String redisPrefix,Long blogid,String mode,boolean first){
Object o = redisUtils.get(redisPrefix);
BlogViewNumber blogViewNumber = JSON.parseObject(o.toString(), BlogViewNumber.class);
switch (mode) {
case "pv":
Integer viewNumber = blogViewNumber.getViewNumber();
if (viewNumber % blogPv == 0) {
//这个时候更新数据库
BlogEntity blogEntity = blogService.getById(blogid);
blogEntity.setViewNumber(viewNumber);
blogService.updateById(blogEntity);
}
blogViewNumber.setViewNumber(blogViewNumber.getViewNumber() + 1);
if(first) {
blogViewNumber.setViewNumber(blogViewNumber.getViewNumber() + 1);
}else {
String ipAddr = GetIPAddrUtils.GetIPAddr();
blogViewNumber.setViewNumber(blogViewNumber.getViewNumber() + 1);
if (!blogViewNumber.getIp().equals(ipAddr)) {
blogViewNumber.setViewNumber(blogViewNumber.getViewNumber() + 1);
blogViewNumber.setIp(ipAddr);
}
}
break;
case "cv": {
BlogEntity blogEntity = blogService.getById(blogid);
blogViewNumber.setCollectNumber(blogViewNumber.getCollectNumber() + 1);
blogEntity.setCollectNumber(blogViewNumber.getCollectNumber());
blogService.updateById(blogEntity);
break;
}
case "fv": {
BlogEntity blogEntity = blogService.getById(blogid);
blogViewNumber.setForkNumber(blogViewNumber.getForkNumber() + 1);
blogEntity.setForkNumber(blogViewNumber.getForkNumber());
blogService.updateById(blogEntity);
break;
}
default: {
BlogEntity blogEntity = blogService.getById(blogid);
blogViewNumber.setLikeNumber(blogViewNumber.getLikeNumber() + 1);
blogEntity.setLikeNumber(blogViewNumber.getLikeNumber());
blogService.updateById(blogEntity);
break;
}
}
redisUtils.set(redisPrefix,blogViewNumber);
}
/**
* 获取某个Method的参数名称及对应的值
* @return Map<参数名称, 参数值></参数名称,参数值>
*/
public static Map<String, Object> getNameAndValue(JoinPoint joinPoint) {
Map<String, Object> param = new HashMap<>();
Object[] paramValues = joinPoint.getArgs();
String[] paramNames = ((CodeSignature) joinPoint.getSignature()).getParameterNames();
for (int i = 0; i < paramNames.length; i++) {
param.put(paramNames[i], paramValues[i]);
}
return param;
}
}
数据一致性
之后的话就是咱们的另一个重点,数据的一致性。
同样的我们也需要使用到切面来完成操作。
分析
首先的话,刚刚已经说了有些东西,是存放在缓存里面的,必须保证这里面的刚刚我们做的流量统计是最新的,不然当用户访问到这个缓存的时候,得到数据就不一致了。这样做的话,虽然没什么,但是实在是太难看了。
那么解决这个我们当然其实有三个方案嘛。
- 解决看数据的人
- 解决缓存的数据
- 解决返回的数据
第一点行不通。
第二点,可以但是修改数据的时候需要不断更新redis里面的缓存,对redis的写入比较繁琐。
第三点,也可以,但是需要不断对返回数据进行处理,对redis的度比较繁琐。
综合来看的话,返回的数据量不是很大,而且天知道缓存里面还有别的东西没有,我很难保证全部有更新。因此我选择了第三点,实现也比较简单。
自定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface RefreshFlew {
String type() default "";
String key() default "";
}
我在这里定义了两个值,一个是type,还有一个是key。
原因的话是这样的,我们这边是有一个统一的返回类的。
public class R extends HashMap<String, Object> {
private static final long serialVersionUID = 1L;
public R() {
put("code", 0);
put("msg", "success");
}
public static R error() {
return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员");
}
public static R error(String msg) {
return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);
}
public static R error(int code, String msg) {
R r = new R();
r.put("code", code);
r.put("msg", msg);
return r;
}
public static R warn() {
R r = new R();
r.put("code", 1);
r.put("msg", "warning");
return r;
}
public static R ok(String msg) {
R r = new R();
r.put("msg", msg);
return r;
}
public static R ok(Map<String, Object> map) {
R r = new R();
r.putAll(map);
return r;
}
public static R ok() {
return new R();
}
public R put(String key, Object value) {
super.put(key, value);
return this;
}
}
所以的话我们有两个东西。
返回值分析
刚刚说了返回的东西是R这个返回类,但是R是个MAP,然后这里面应该是啥呢。这里的话在我的这个设计当中呢,是这两个类的东西。
第一个是返回的是PageUtils。这个呢是MP分页一个东西,也是自定义的一个东西。
/**
* 分页工具类
*/
public class PageUtils implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 总记录数
*/
private int totalCount;
/**
* 每页记录数
*/
private int pageSize;
/**
* 总页数
*/
private int totalPage;
/**
* 当前页数
*/
private int currPage;
/**
* 列表数据
*/
private List<?> list;
/**
* 分页
* @param list 列表数据
* @param totalCount 总记录数
* @param pageSize 每页记录数
* @param currPage 当前页数
*/
public PageUtils(List<?> list, int totalCount, int pageSize, int currPage) {
this.list = list;
this.totalCount = totalCount;
this.pageSize = pageSize;
this.currPage = currPage;
this.totalPage = (int)Math.ceil((double)totalCount/pageSize);
}
/**
* 分页
*/
public PageUtils(IPage<?> page) {
this.list = page.getRecords();
this.totalCount = (int)page.getTotal();
this.pageSize = (int)page.getSize();
this.currPage = (int)page.getCurrent();
this.totalPage = (int)page.getPages();
}
public int getTotalCount() {
return totalCount;
}
public void setTotalCount(int totalCount) {
this.totalCount = totalCount;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getTotalPage() {
return totalPage;
}
public void setTotalPage(int totalPage) {
this.totalPage = totalPage;
}
public int getCurrPage() {
return currPage;
}
public void setCurrPage(int currPage) {
this.currPage = currPage;
}
public List<?> getList() {
return list;
}
public void setList(List<?> list) {
this.list = list;
}
}
还有一个东西就是我们的这个博文的一个实体类,或者是具备相同字段的实体类。
比如这个就是有相同字段的一个实体了。返回的是这个,或者就是博文实体类。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class BlogBody implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 这边的话userid啥的都是指文章的作者
* */
private String userid;
private Long blogid;
private String content;
private String blogTitle;
private String userNickname;
private String userImg;
private String createTime;
private Integer viewNumber;
private Integer likeNumber;
private Integer collectNumber;
private Integer forkNumber;
private String blogtype;
private String blogimg;
}
同时部分的接口,还是用了缓存的,这里使用的是SpringCache作为缓存技术。(确切的说是大部分接口,尤有钱就上ES(艹皿艹 ))
解决方案
那么这个时候我们就需要对这些接口的返回值进行处理了,这里值得庆幸的就是咱们有统一返回类。因此的话不管怎么样,方法返回的一定是R类的东西。我们要做的就是分别处理刚刚提到的两种类型的数据。这个的话我们就直接看到代码了,思路还是简单的。
@Component
@Aspect
@Slf4j
public class ReFreshFlewAspect {
private static final String viewNumberPrefix = RedisTransKey.viewNumberPrefix;
@Autowired
private RedisUtils redisUtils;
@Autowired
BlogService blogService;
@Pointcut("@annotation(com.huterox.common.holeAnnotation.RefreshFlew)")
public void refreshAspect() {}
@Around("refreshAspect() && @annotation(annotation)")
public R verification(ProceedingJoinPoint joinPoint,RefreshFlew annotation) throws Throwable{
assert annotation != null;
String type = annotation.type();
String key = annotation.key();
Object pro = joinPoint.proceed();
//我们这里最后一个依靠的是SpringCache的返回值,这个时候人家已经帮我们重新序列化为了一个R对象
R proceed = (R) pro;
if(type.equals("page")){
PageUtils page = (PageUtils) proceed.get(key);
List<BlogEntity> blogEntityList = (List<BlogEntity>) page.getList();
List<BlogEntity> result = new ArrayList<>();
for(BlogEntity blogEntity:blogEntityList){
String redisPrefix = viewNumberPrefix+":"+blogEntity.getBlogid();
if(redisUtils.hasKey(redisPrefix)){
Object red = redisUtils.get(redisPrefix);
BlogViewNumber blogViewNumber = JSON.parseObject(red.toString(), BlogViewNumber.class);
BeanUtils.copyProperties(blogViewNumber,blogEntity);
result.add(blogEntity);
}else {
this.createCache(blogEntity,redisPrefix);
result.add(blogEntity);
}
}
page.setList(result);
proceed.put(key,page);
}else if(type.equals("blog")){
Object o = proceed.get(key);
BlogEntity ob = new BlogEntity();
BeanUtils.copyProperties(o,ob);
String redisPrefix = viewNumberPrefix+":"+ob.getBlogid();
if(redisUtils.hasKey(redisPrefix)){
Object red = redisUtils.get(redisPrefix);
BlogViewNumber blogViewNumber = JSON.parseObject(red.toString(), BlogViewNumber.class);
BeanUtils.copyProperties(blogViewNumber,o);
proceed.put(key,o);
}else {
this.createCache(ob,redisPrefix);
}
}
return proceed;
}
private void createCache(BlogEntity o,String redisPrefix){
BlogViewNumber blogViewNumber = new BlogViewNumber();
BeanUtils.copyProperties(o,blogViewNumber);
blogViewNumber.setIp("Hello 2023");
redisUtils.set(redisPrefix,blogViewNumber);
}
}
这里的话就没必要上锁了,不然我就用读写锁了,为啥呢,因为本身有网络的延迟,在你获取数据的过程当中,可能又有人访问了,这个时候访问数据得到的也不是那么准了。所以这个也是为什么一开始我就是你能不能忍受,因为这个数据本身不会准(如果访问人多了)但是可以保证记录的准确性。这个如果是商品之类的东西的话,那么就非常有必要了。
总结
最后祝大家新年快乐~ 不说了,嗓子要废了。
](https://img-blog.csdnimg.cn/img_convert/3dc62dc06b9e9b0e1395345306629f1d.jpeg)