文章目录
- 前言
- tensorflow发展历程
- 基本概念
- 张量
- 神经网络、层
- 模型
- 超参数
- 损失函数
- 交叉熵函数
- 激活函数
- 梯度和自动微分
- 优化器
- tensorflow 2.x 和 tensorflow 1.x
- tensorflow开发流程
- tensorflow API
- 张量的定义和运算
- 示例
- 张量的初始化方式
- 梯度计算
- 模型的搭建
- 示例:MINST手写数字识别神经网络定义
- 图计算
- tensorflow常见模块介绍
- 常用函数和方法
- tf.nn
- tf.train
- tf.summary
- tf.keras
- 参考链接
前言
学习tensorflow的基本方法:概念和API。先要理解基本概念,再掌握围绕这些概念的API。通过API进一步了解基本概念所对应的对象的运算和转化。
tensorflow发展历程
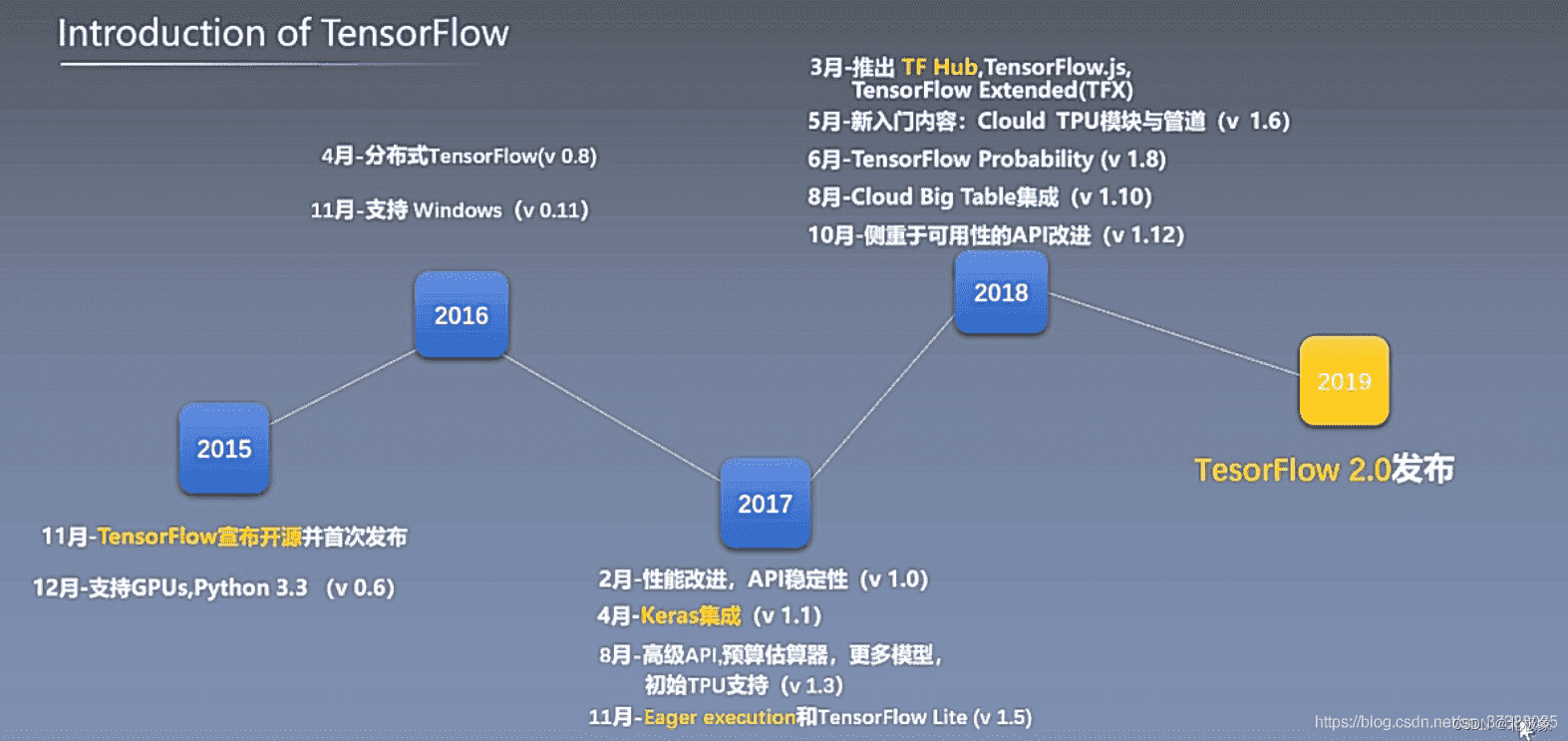
TensorFlow 2.0 推荐使用tf.keras、tf.data等高级库;
- 用Eager模式搭建原型;
- 用tf.data处理数据;
- 用tf.feature_column提取特征;
- 用tf.keras搭建模型;
- 用tf.saved_model打包模型;
基本概念
张量
张量就是多维数组,具有(维度,形状)特性。
- 标量(scalar):即一个数值,它是计算的最小单元,如“1”或“3.2”等
- 向量(vector):由一些标量构成的一维数组,如[1, 3.2, 4.6]等
- 矩阵(matrix):是由标量构成的二维数组
- 张量(tensor):由多维(通常)数组构成的数据集合,可理解为高维矩阵
神经网络、层
神经网络可以视为一个复杂的函数,以张量作为输入,以张量作为输出。
例如通常将(batch_size, height, width, depth)的4D数组输入CNN,其输出也是(batch_size, height, width, depth)的4D数组。
神经网络可以表示为简单层的组合与堆叠。包含 Dense(全连接层)、Conv2D、LSTM、BatchNormalization、Dropout 等各种层。
神经网络每一层提取上一层的特征,作为下一层的输入。
模型
训练好的、保存下来的数据叫模型,包含权重。模型可以用于推理。
超参数
超参数则不需要数据来驱动,而是在训练前或者训练中人为的进行调整的参数。如epoch,学习率。
超参数分为三类:网络参数、优化参数、正则化参数。
- 网络参数:可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
- 优化参数:一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数。
- 正则化:权重衰减系数,丢弃法比率(dropout)
损失函数
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。 在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
交叉熵函数
分类问题中常常使用交叉熵作为loss函数。
交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
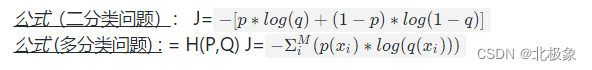
激活函数
一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出,即指示哪些信息可以传播到下一层。激活函数是确定神经网络输出的数学函数。
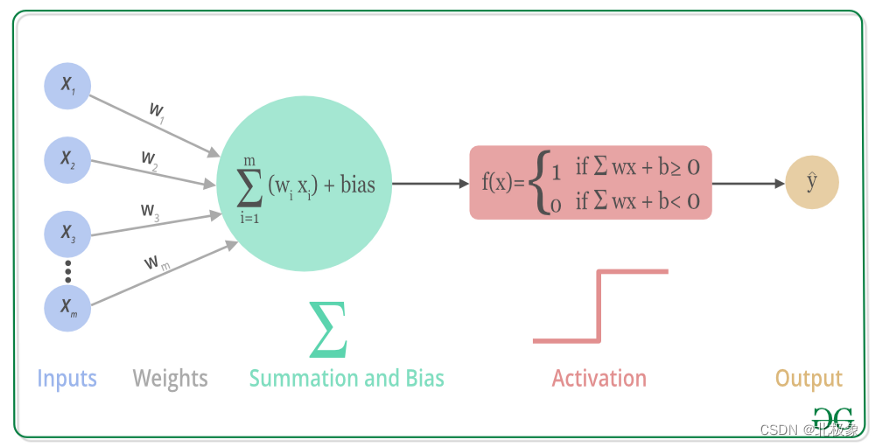
常见的激活函数有:sigmoid(), tanh(), ReLU(), 以及用于多类分类问题的激活函数softmax()等。
梯度和自动微分
梯度就是多元函数对某个自变量的偏导。自动微分就是深度学习框架帮我们自动运算梯度,人工计算就会非常复杂。
优化器
优化器是tensorflow中梯度下降的策略,用于更新神经网络中数以百万的参数。用dir(tf.train)列举出所有的和优化器相关的指令。
tf提供了一共有11个优化器,以及1个tf.train.Optimizer的基类。这11个优化器分别是:
- Tf.train.AdadeltaOptimizer
- Tf.train.AdagradDAOptimizer
- Tf.train.AdagradOptimizer
- Tf.train.AdamOptimizer
- Tf.train.FtrlOptimizer
- Tf.train.GradientDescentOptimizer
- Tf.train.MomentumOptimizer
- Tf.train.ProximalAdagradOptimizer
- Tf.train.ProximalGradientDescentOptimizer
- Tf.train.RMSPropOptimizer
- Tf.train.SyncReplicasOptimizer
对于通常的网络模型来说,SGD和AdamOptimizer就满足需求了,只要能保证收敛就可以了。
tensorflow 2.x 和 tensorflow 1.x
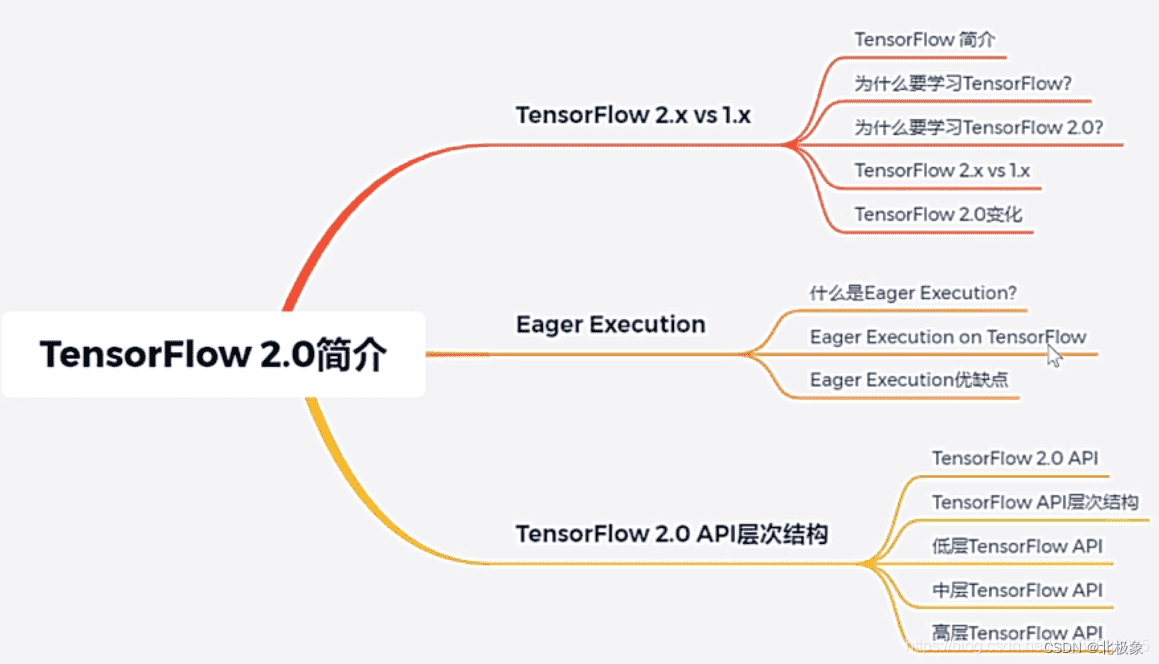
和1.x相比的主要变化:


TF2.x提倡函数优先于会话,也就是不用session.run()这种方式了。
tensorflow开发流程
- 定义输入,变量占位符
- 定义网络结构,根据数学原理写方程
- 定义训练目标:损失函数cost
- 不断优化梯度下降 GradientDescentOptimizer
- 模型训练,利用session 进行训练,for循环
- 模型保存,保存saver
当然推理过程就比较单一了。
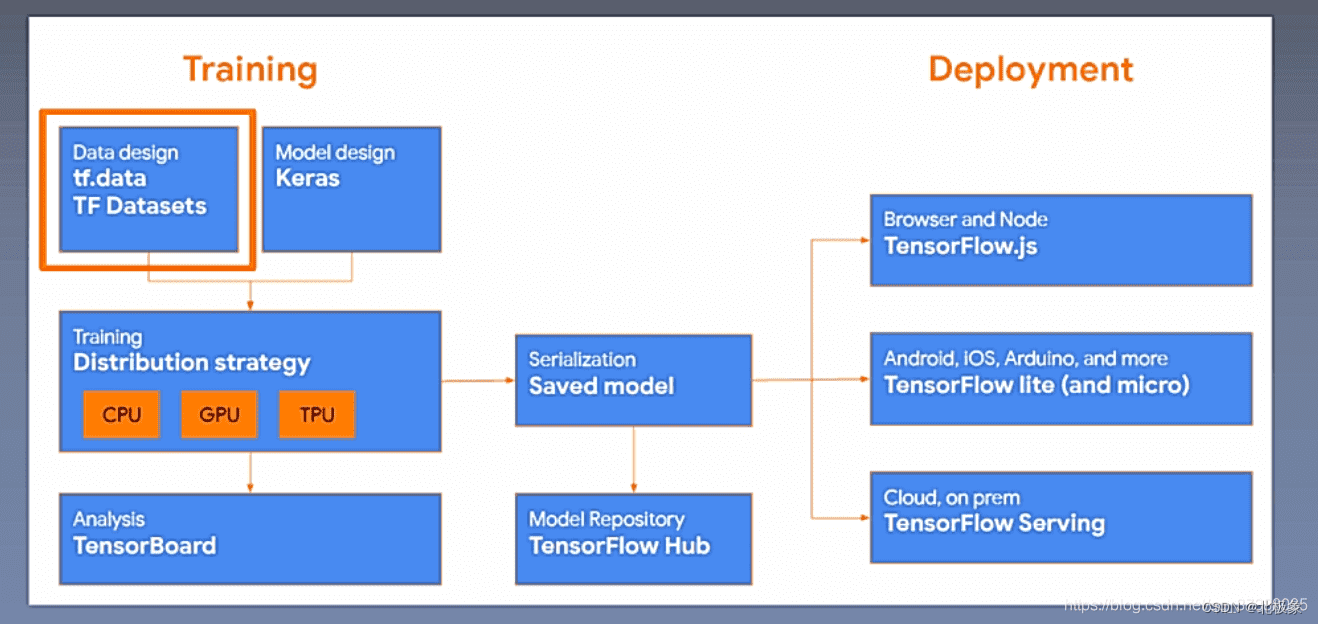
tensorflow API
TensorFlow API一共可以分为三个层次,即低阶API、中阶API、高阶API:
- 第一层为Python实现的操作符,主要包括各种张量操作算子、计算图、自动微分;

- 第二层为Python实现的模型组件,对低级API进行了函数封装,主要包括各种模型层,损失函数,优化器,数据管道,特征列等等;

- 第三层为Python实现的模型成品,一般为按照OOP方式封装的高级API,主要为tf.keras.models提供的模型的类接口;
tensorflow.keras.models 建模方式有三种:- Sequential办法;
- 函数式API方法;
- Model子类化自定义模型
张量的定义和运算
- tf.Variable(): 定义一个张量,对它执行运算可以改变其值。利用特定运算可以读取和修改此张量的值。可以用来存储模型参数。
- tf.constant(): 定义一个值为常量的张量。
- tf.placeholder(): placeholder相当于定义了一个位置,这个位置中的数据在程序运行时再指定。这样在程序中就不需要生成大量常量来提供输入数据,而只需要将数据通过placeholder传入TensorFlow 计算图。在placeholder定义时,这个位置上的数据类型是需要指定的。
示例
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) ## 定义shape=(2,3)的变量,值为随机数
x = tf.constant([1, 2, 3, 4, 5, 6]) # 通过python list定义了一个一维的常量
a = np.array([[1, 2, 3], [4, 5, 6]])
x = tf.constant(a) # 定义了一个二维常量, shape=(2,3)
x = tf.placeholder(tf.float32, shape=(1, 2), name="input") # 定义了一个占位符
张量的初始化方式
| 用法 | 说明 |
|---|---|
| tf.zeros(shape, dtype=tf.float32, name=None) | 创建所有元素设置为零的张量 |
| tf.zeros_like(tensor, dtype=None, name=None) | 返回tensor与所有元素设置为零相同的类型和形状的张量 |
| tf.ones(shape, dtype=tf.float32, name=None) | 创建一个所有元素设置为1的张量。 |
| tf.ones_like(tensor, dtype=None, name=None) | 返回tensor与所有元素设置为1相同的类型和形状的张量 |
| tf.fill(dims, value, name=None) | 创建一个填充了标量值的张量 |
| tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) | 从截断的正态分布中输出随机值 |
| tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) | 从正态分布中输出随机值 |
| tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None) | 从均匀分布输出随机值 |
| tf.eye(num_rows, num_columns=None, batch_shape=None, dtype=tf.float32, name=None) | 构建一个单位矩阵, 或者 batch 个矩阵,batch_shape 以 list 的形式传入 |
| tf.diag(diagonal, name=None) | 构建一个对角矩阵 |
| tf.global_variables_initializer() | 初始化全部变量 |
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
梯度计算
- GradientTape.gradient(target, sources) 计算某个目标(通常是损失)相对于某个源(通常是模型变量)的梯度。
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
模型的搭建
在 TensorFlow 中,推荐使用 Keras( tf.keras )构建模型。Keras 是一个广为流行的高级神经网络 API,简单、快速而不失灵活性,现已得到 TensorFlow 的官方内置和全面支持。
Keras 有两个重要的概念: 模型(Model) 和 层(Layer) 。层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等),而模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出。在需要模型调用的时候,使用 y_pred = model(X) 的形式即可。Keras 在 tf.keras.layers 下内置了深度学习中大量常用的的预定义层,同时也允许我们自定义层。
最简单的层定义:
layer(tf.zeros([10, 5]))
也可以自定义层:
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self, num_outputs):
super(MyDenseLayer, self).__init__()
self.num_outputs = num_outputs
def build(self, input_shape):
self.kernel = self.add_weight("kernel",
shape=[int(input_shape[-1]),
self.num_outputs])
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
layer = MyDenseLayer(10)
示例:MINST手写数字识别神经网络定义
MINST是学习神经网络的入门经典案例,一般教科书中都会介绍。
import os
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
class CNN(object):
def __init__(self):
model = models.Sequential()
# 第1层卷积,卷积核大小为3*3,32个,28*28为待训练图片的大小
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
# 第2层卷积,卷积核大小为3*3,64个
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第3层卷积,卷积核大小为3*3,64个
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary() # 用来打印我们定义的模型的结构
self.model = model
每一个Conv2D和MaxPooling2D层的输出都是一个三维的张量(height, width, channels)。height和width会逐渐地变小。输出的channel的个数,是由第一个参数(例如,32或64)控制。
模型的后半部分,是定义输出张量的。layers.Flatten会将三维的张量转为一维的向量。展开前张量的维度是(3, 3, 64) ,转为一维(576)的向量后,紧接着使用layers.Dense层,构造了2层全连接层,逐步地将一维向量的位数从576变为64,再变为10。
后半部分相当于是构建了一个隐藏层为64,输入层为576,输出层为10的普通的神经网络。最后一层的激活函数是softmax,10位恰好可以表达0-9十个数字。
图计算
计算图极为有用,它可以使 TensorFlow 快速运行、并行运行以及在多个设备上高效运行。每生成一个常量/占位符/张量,TensorFlow都会在计算图中增加一个节点。
# Define a Python function.
def a_regular_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# `a_function_that_uses_a_graph` is a TensorFlow `Function`.
a_function_that_uses_a_graph = tf.function(a_regular_function)
# Make some tensors.
x1 = tf.constant([[1.0, 2.0]])
y1 = tf.constant([[2.0], [3.0]])
b1 = tf.constant(4.0)
orig_value = a_regular_function(x1, y1, b1).numpy()
# Call a `Function` like a Python function.
tf_function_value = a_function_that_uses_a_graph(x1, y1, b1).numpy()
assert(orig_value == tf_function_value)
将普通python函数转为Tensorflow函数,则背后会利用tensorflow的图计算功能。
采用装饰器@tf.function可以将普通的python函数转为tensorflow函数。
def simple_relu(x):
if tf.greater(x, 0):
return x
else:
return 0
# `tf_simple_relu` is a TensorFlow `Function` that wraps `simple_relu`.
tf_simple_relu = tf.function(simple_relu)
print("First branch, with graph:", tf_simple_relu(tf.constant(1)).numpy())
print("Second branch, with graph:", tf_simple_relu(tf.constant(-1)).numpy())
tensorflow常见模块介绍
常用函数和方法
TensorFlow 还把那些经常使用的 Tensor 操作功能直接放在了 tf 下面,包括了:
Maths、Array、Matrix 相关的操作,也就是例如算术操作、张量(矩阵)操作、数据类型转换、矩阵的变形、切片、合并、规约、分割、序列比较与索引提取等常用功能。
tf.nn
神经网络的功能支持模块,这是最常用到的一个模块,用于构建经典的卷积网络,它下面还包含了 rnn_cell 的子模块,用于构建循环神经网络;下面是几个常用函数:
- avg_pool(…): 平均池化
- batch_normalization(…): 批标准化
- bias_add(…): 添加偏置
- conv2d(…): 2维卷积
- dropout(…): 随机丢弃神经网络单元
- relu(…): relu 激活层
- sigmoid_cross_entropy_with_logits(…): sigmoid 激活后的交叉熵
- softmax(…): softmax 激活层
可以看到,基本所有经典神经网络的操作都放在了这个模块。
tf.train
这个模块主要是用来支持训练模型的,几个它下面包含的常用类和函数:
| 类和函数 | 作用 |
|---|---|
| class AdadeltaOptimizer | Adadelta 优化器 |
| class AdamOptimizer | Adam 优化器 |
| class Coordinator | 线程管理器 |
| class Example | tfrecord 的生成模板 |
| class ExponentialMovingAverage | 指数移动平均 |
| class GradientDescentOptimizer | 梯度下降优化器 |
| class MomentumOptimizer | 动量优化器 |
| class NanTensorHook | loss 是否为 NaN 的捕获器 |
| class QueueRunner | 入队队列启动 |
| class RMSPropOptimizer | RMSProp 优化器 |
| class Saver | 保存模型和变量类 |
| NewCheckpointReader(…) | checkpoint 文件读取 |
| batch(…) | 生成tensorsbatch |
| create_global_step(…) | 创建 global step |
| get_checkpoint_state(…) | 从 “checkpoint” 文件返回模型状态 |
| init_from_checkpoint(…) | 从 checkpoint 文件初始化变量 |
| latest_checkpoint(…) | 寻找最后一次的 checkpoint 文件 |
| list_variables(…) | 返回 checkpoint 文件变量为列表 |
| load_variable(…) | 返回 checkpoint 文件某个变量的值 |
| match_filenames_once(…) | 寻找符合规则的文件名称 |
| shuffle_batch(…) | 创建随机的 Tensor batch |
| start_queue_runners(…) | 启动计算图中所有的队列 |
tf.summary
主要用来配合 tensorboard 展示模型的信息,在训练过程中记录数据的利器。
数据可视化:而tensorboard可以将tf.summary()记录下来的日志可视化,根据记录的数据格式,生成折线图、统计直方图、图片列表等多种图。几个常用类和函数如下:
| 类和函数 | 作用 |
|---|---|
| class FileWriter | Summary文件生成类 |
| class Summary | Summary 类,tf.summary()提供了各类方法(支持各种多种格式)用于保存训练过程中产生的数据(比如loss_value、accuracy、整个variable),这些数据以日志文件的形式保存到指定的文件夹中 |
| get_summary_description(…) | 获取计算节点信息 |
| histogram(…) | 展示变量分布信息 |
| image(…) | 展示图片信息 |
| merge(…) | 合并某个 Summary 信息 |
| merge_all(…) | 合并所有的各处分散的 Summary 信息到默认的计算图 |
| scalar(…) | 展示某个标量的值 |
| text(…) | 展示文本信息 |
| tf.summary() | 通过递增的方式更新日志,这让我们可以边训练边使用tensorboard读取日志进行可视化,从而实时监控训练过程。 |
tf.keras
这个模块是对Keras API的实现,是TensorFlow高级API。
| 模块 | 概述 |
|---|---|
| activations | 内置的激活函数 |
| applications | 预先训练权重的罐装架构Keras应用程序 |
| backend | Keras后端API |
| Callbacks | 在模型训练期间的某些时刻被调用的实用程序 |
| Constraints | 约束模块,对权重施加约束的函数 |
| datasets | tf.keras数据集模块,包括boston_housing,cifar10,fashion_mnist,imdb ,mnist,reuters |
| estimator | Keras估计量API |
| experimental | tf.keras.experimental 名称空间的公共API |
| initializers | 初始序列化/反序列化模块 |
| layers | Keras层API |
| losses | 内置损失函数 |
| metircs | 内置度量函数 |
| mixed_precision | 混合精度模块 |
| models | 模型克隆的代码,以及与模型相关的API |
| optimizers | 内置的优化器模块 |
| preprocessing | Keras数据的预处理模块 |
| regularizers | 内置的正则模块 |
| utils | Public API for tf.keras.utils namespace\ |
| wrappers | 在Keras模型中使用Scikit-Learn API的包装器。 |
还有两个最重要的类
class Model: 将layers分组为用来训练和预测的对象。
class Sequential: 有序地将layers分组到 tf.keras.Model中。
以及一个函数Input( ), 可以用来实例化一个Keras张量。
参考链接
- Tensorflow官方文档
- tensorflow中文社区
- 智能后端和架构




![[阿里云] 10分钟带你玩转阿里云ECS和云盘 (大数据上云必备)](https://img-blog.csdnimg.cn/fcb82890e5204b3aaf42942643d1ea2d.png)