Flink批Hash Join递归超限问题
随着Flink流批一体能力的迅速发展以及Flink SQL易用性的提升,越来越多的厂商开始将Flink作为离线批处理引擎使用。在我们使用Flink进行大规模join操作时,也许会发生如下的异常,导致任务失败:
Hash join exceeded maximum number of recursions, without reducing partitions enough to be memory resident.字面意思即为Hash Join的递归次数超出限制。Flink批模式下的join算法有两种,即Hybrid Hash Join和Sort-Merge Join。顾名思义,Hybrid Hash Join就是Simple Hash Join和Grace Hash Join两种算法的结合(关于它们,看官可参考这篇文章)。引用一张Flink官方博客中的手绘图来说明。
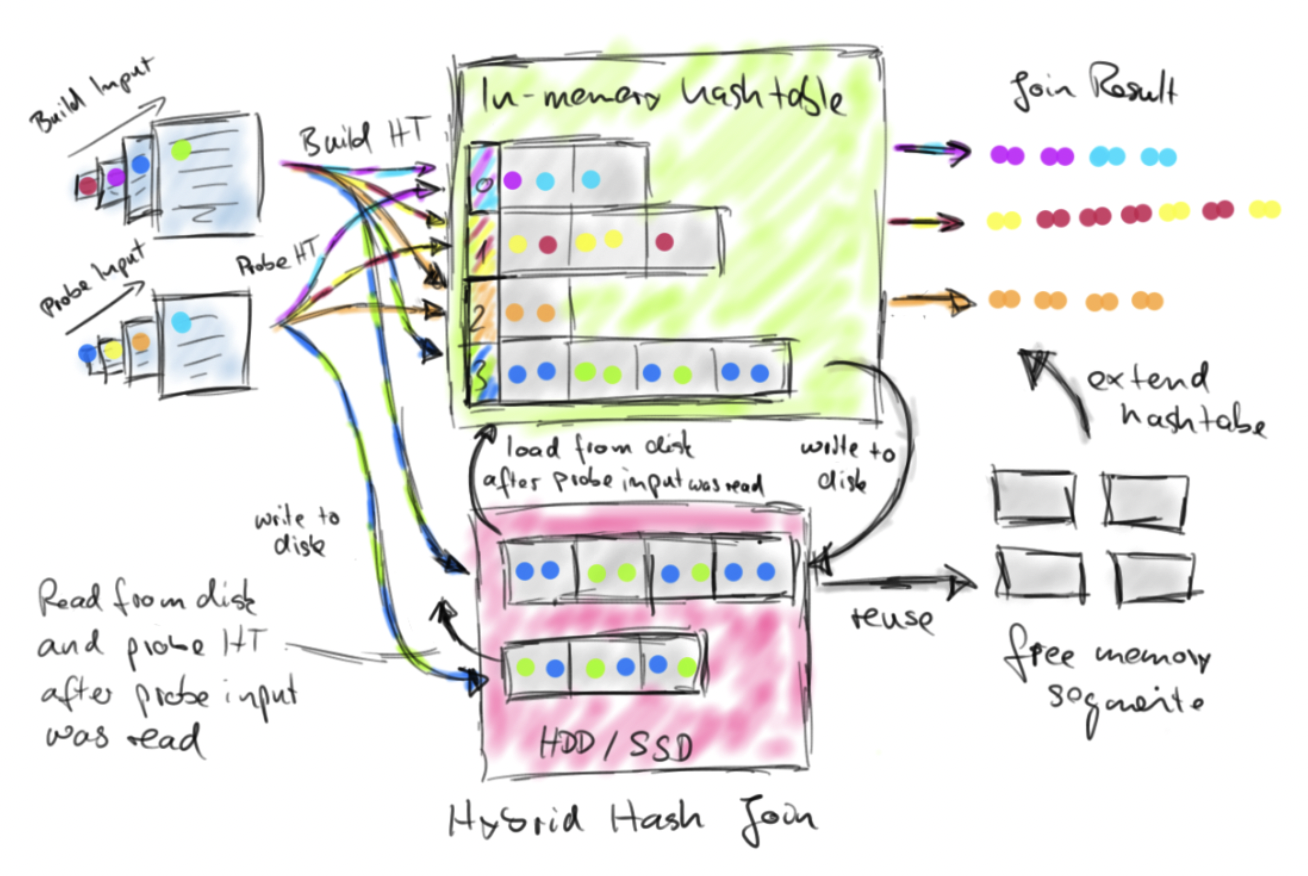
Flink的Hybrid Hash Join在build阶段会积极地利用TaskManager的托管内存,并将内存无法容纳的哈希分区spill到磁盘中。在probe阶段,当内存中的哈希分区处理完成后,会释放掉对应的MemorySegment,并将先前溢写到磁盘的分区读入,以提升probe效率。特别注意,如果溢写分区对空闲的托管内存而言仍然过大(特别是存在数据倾斜的情况时),就会将其递归拆分成更小的分区,原理如下图所示。
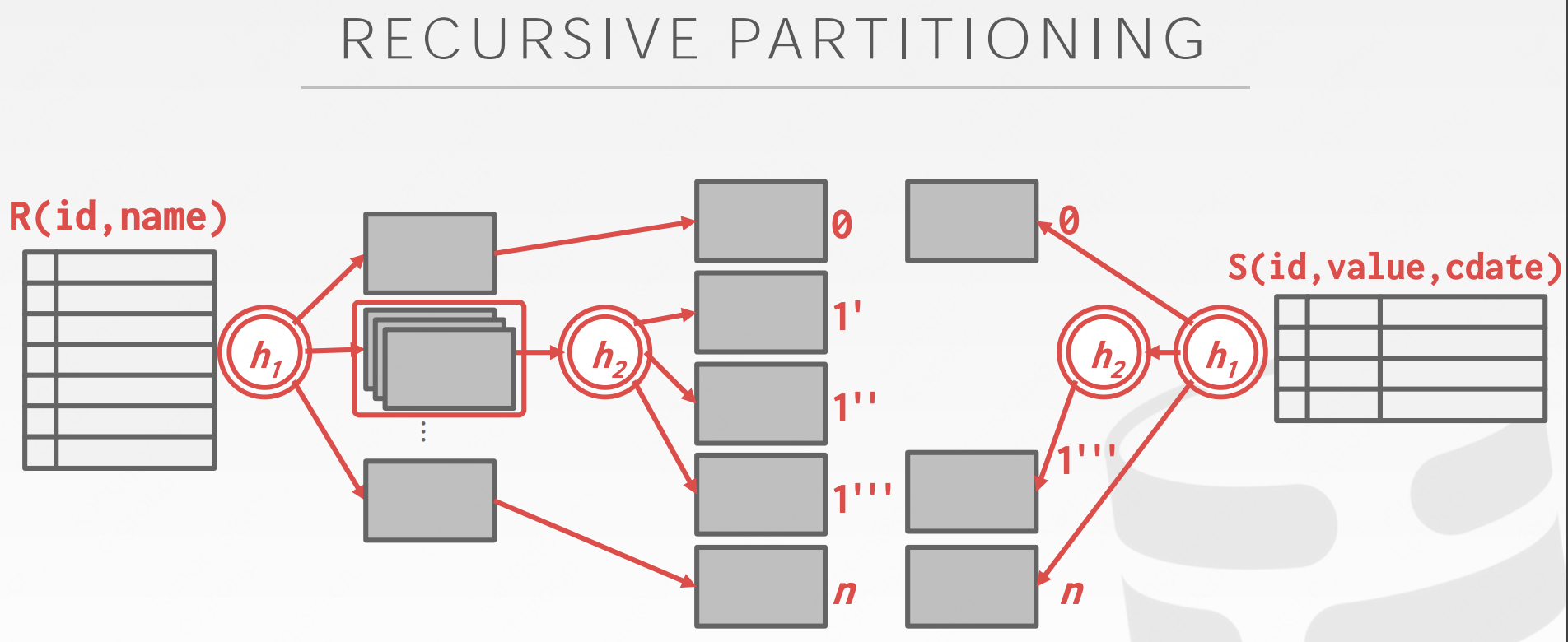
当然,递归拆分也不能是无限制的。在Blink Runtime中,如果递归拆分3次仍然不能满足内存需求,就会抛出前文所述的异常了。
笔者在今年7月ApacheCon Asia 2022流处理专场的分享内容里谈到了这个问题,并且将其归咎于Flink SQL的CBO优化器的代价模型不太科学,导致其十分偏向选择Hash Join。由于修改的难度很大,所以暂时的workaround就是在任务失败后,自动设置table.exec.disabled-operators参数来禁用掉ShuffleHashJoin算子,从而强制使用Sort-Merge Join。

当然这仍然不算优雅的解决方法,接下来简要看看Flink 1.16版本中提出的更好一点的方案:Adaptive Hash Join。
Adaptive Hash Join的实现
所谓adaptive(自适应),就是指Hash Join递归超限时,不必让任务失败,而是将这些大分区自动转为Sort-Merge Join来处理。
Blink Runtime中的哈希表有两种,即BinaryHashTable(key的类型为BinaryRowData)和LongHybridHashTable(key的类型为Long)。以前者为例,查看其prepareNextPartition()方法,该方法负责递归地取得下一个要处理的哈希分区。
private boolean prepareNextPartition() throws IOException {
// finalize and cleanup the partitions of the current table
// ......
// there are pending partitions
final BinaryHashPartition p = this.partitionsPending.get(0);
// ......
final int nextRecursionLevel = p.getRecursionLevel() + 1;
if (nextRecursionLevel == 2) {
LOG.info("Recursive hash join: partition number is " + p.getPartitionNumber());
} else if (nextRecursionLevel > MAX_RECURSION_DEPTH) {
LOG.info(
"Partition number [{}] recursive level more than {}, process the partition using SortMergeJoin later.",
p.getPartitionNumber(),
MAX_RECURSION_DEPTH);
// if the partition has spilled to disk more than three times, process it by sort merge
// join later
this.partitionsPendingForSMJ.add(p);
// also need to remove it from pending list
this.partitionsPending.remove(0);
// recursively get the next partition
return prepareNextPartition();
}
// build the next table; memory must be allocated after this call
buildTableFromSpilledPartition(p, nextRecursionLevel);
// set the probe side
setPartitionProbeReader(p);
// unregister the pending partition
this.partitionsPending.remove(0);
this.currentRecursionDepth = p.getRecursionLevel() + 1;
// recursively get the next
return nextMatching();
}注意当递归深度超过MAX_RECURSION_DEPTH(常量定义即为3)时,会将分区直接放入一个名为partitionsPendingForSMJ的容器中,等待做Sort-Merge Join。另外,在该方法调用的buildTableFromSpilledPartition()方法(对溢写分区执行build操作)开头,去掉了对递归超限的判断,也就是说Hash join exceeded maximum number of recursions异常已经成为历史。
那么等待做Sort-Merge Join的分区是如何被处理的?查看Blink Runtime中的HashJoinOperator算子,在构造该算子时,需要比原来多传入一个SortMergeJoinFunction的实例:
private final SortMergeJoinFunction sortMergeJoinFunction;SortMergeJoinFunction实际上是将旧版的SortMergeJoinOperator处理逻辑抽离出来的类,算法本身没有任何变化。然后从哈希表中读取前述的partitionsPendingForSMJ容器,对每个分区的build侧和probe侧分别执行Sort-Merge Join操作即可。
/**
* If here also exists partitions which spilled to disk more than three time when hash join end,
* means that the key in these partitions is very skewed, so fallback to sort merge join
* algorithm to process it.
*/
private void fallbackSMJProcessPartition() throws Exception {
if (!table.getPartitionsPendingForSMJ().isEmpty()) {
// release memory to MemoryManager first that is used to sort merge join operator
table.releaseMemoryCacheForSMJ();
// initialize sort merge join operator
LOG.info("Fallback to sort merge join to process spilled partitions.");
initialSortMergeJoinFunction();
fallbackSMJ = true;
for (BinaryHashPartition p : table.getPartitionsPendingForSMJ()) {
// process build side
RowIterator<BinaryRowData> buildSideIter =
table.getSpilledPartitionBuildSideIter(p);
while (buildSideIter.advanceNext()) {
processSortMergeJoinElement1(buildSideIter.getRow());
}
// process probe side
ProbeIterator probeIter = table.getSpilledPartitionProbeSideIter(p);
BinaryRowData probeNext;
while ((probeNext = probeIter.next()) != null) {
processSortMergeJoinElement2(probeNext);
}
}
// close the HashTable
closeHashTable();
// finish build and probe
sortMergeJoinFunction.endInput(1);
sortMergeJoinFunction.endInput(2);
LOG.info("Finish sort merge join for spilled partitions.");
}
}
private void initialSortMergeJoinFunction() throws Exception {
sortMergeJoinFunction.open(
true,
this.getContainingTask(),
this.getOperatorConfig(),
(StreamRecordCollector) this.collector,
this.computeMemorySize(),
this.getRuntimeContext(),
this.getMetricGroup());
}
private void processSortMergeJoinElement1(RowData rowData) throws Exception {
if (leftIsBuild) {
sortMergeJoinFunction.processElement1(rowData);
} else {
sortMergeJoinFunction.processElement2(rowData);
}
}
private void processSortMergeJoinElement2(RowData rowData) throws Exception {
if (leftIsBuild) {
sortMergeJoinFunction.processElement2(rowData);
} else {
sortMergeJoinFunction.processElement1(rowData);
}
}与BinaryHashTable不同,LongHybridHashTable的join逻辑全部是代码生成的,在对应的生成器LongHashJoinGenerator中,可以看到与上文类似的代码,看官可以自行找来读读。
The End
民那晚安晚安。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/130899.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

基于华为eNSP的中小企业办公园区网络规划与设计

人工智能--你需要知道的一切

java开发的美妆化妆品电商商城系统

2023年留学基金委(CSC)公派访问学者博士后项目选派办法及解读


当我们身边没有示波器就无法测量频率与占空比了?一招教你解决身边没有示波器时如何测量STM32定时器产生PWM的频率与占空比

Redis(Ⅰ)【学习笔记】

charAt()方法的使用
基于思维进化算法优化BP神经网络(Matlab代码实现)

Kubernetes之PV与PVC

linux系统中利用设备树完成对LED的控制
MATLAB演示梯度上升寻找极值
dubbo源码解析-SPI机制
剑指offer(简单)

一文读懂tensorflow: 基本概念和API

Casting out Primes: Bignum Arithmetic for Zero-Knowledge Proofs学习笔记
RocketMQ 的存储模型