文章目录
- 一、概念介绍
- 1.接近实时(NRT Near Real Time )
- 2.索引(index)
- 3.类型(type)
- 4.映射(mapping)
- 5.文档(document)
- 6.概念关系图
- 二、Kibana的基本操作
- 1.创建dangdang索引并创建product类型
- 2.删除dangdang索引
- 3.创建id为1的文档记录
- 4.查询id为1的文档记录
- 5.删除id为1的文档记录
- 6.创建一个id随机的文档记录(注意要用POST请求)
- 7.更新文档id为1的数据
- 8.批量插入数据(指定id)
- 9.批量插入数据(不指定id)
- 10.批量操作数据(添加、修改、删除)
- 11.查询某个索引某个类型下的所有文档记录
- 12.查看某个索引下的某个类型的结构:
- 13.根据某个字段降序排序查询文档数据
- 14.分页查询文档数据(from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果)
- 15.查询的文档数据返回指定字段
- 16.通过关键字查询文档记录
- 17.根据范围查询文档数据(gte: 大等于;lte :小等于;gt :大于;lt: 小于)
- 18.根据前缀查询文档数据
- 19.根据通配符匹配查询文档数据
- 20.根据多个id查询文档数据
- 21.模糊查询指定文档数据(用来模糊查询含有指定关键字的文档)
- 22. 布尔查询
- 23.高亮查询
- 24.多字段查询(只要查询的内容存在就会查出来!)
- 25.多字段分词查询(只要查询的内容存在就会查出来!)
一、概念介绍
1.接近实时(NRT Near Real Time )
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒内)
2.索引(index)
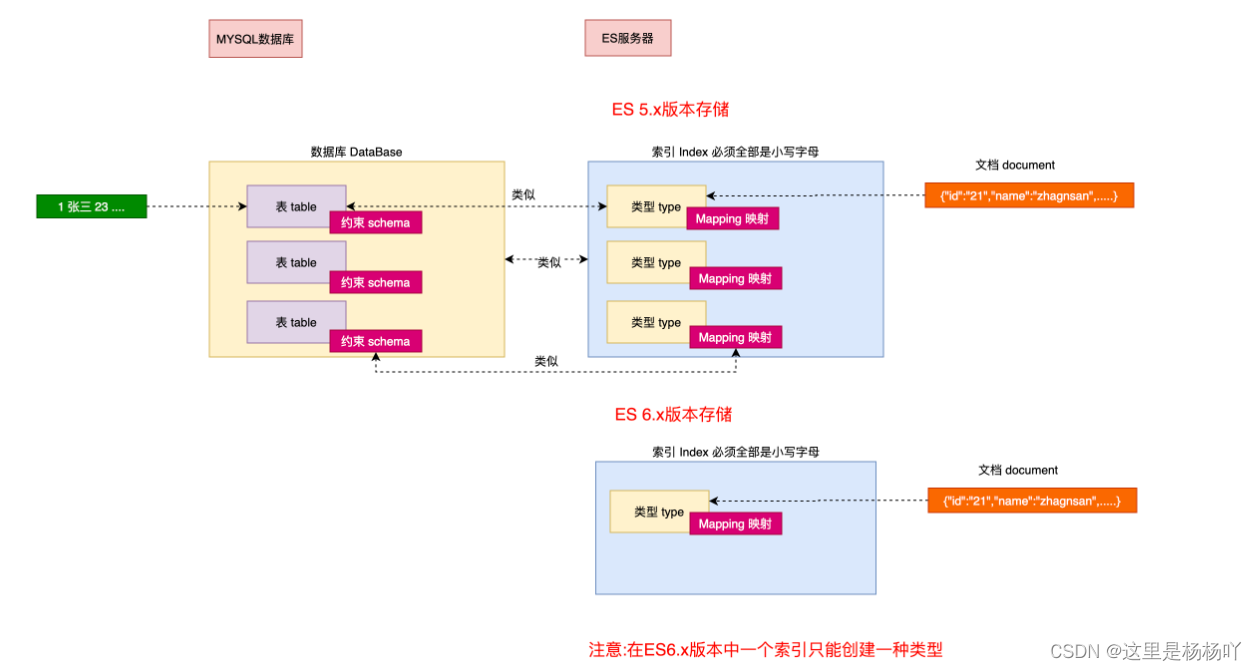
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database 的概念。在一个集群中,如果你想,可以定义任意多的索引。
3.类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数 据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可 以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
4.映射(mapping)
mapping是ES中的一个很重要的内容,它类似于传统关系型数据中table的schema,用于定义一个索引(index)中的类型(type)的数据的结构。 在ES中,我们可以手动创建type(相当于table)和mapping(相关与schema),也可以采用默认创建方式。在默认配置下,ES可以根据插入的数据自动地创建type及其mapping。 mapping中主要包括字段名、字段数据类型和字段索引类型
5.文档(document)
一个文档是一个可被索引的基础信息单元,类似于表中的一条记录。 比如,你可以拥有某一个员工的文档,也可以拥有某个商品的一个文档。文档以采用了轻量级的数据交换格式JSON(Javascript Object Notation)来表示。
6.概念关系图
二、Kibana的基本操作
注意:ElasticSearch6.x版本一个索引只能创建一种类型。
以下例子中的索引:dangdang、类型:product
1.创建dangdang索引并创建product类型
PS:这种方式创建类型要求索引不能存在
PUT /dangdang
{
"mappings": {
"product": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": { "type": "date" }
}
}
}
}
映射Mapping中包含的字段类型有:text , keyword , date ,integer, long , double , boolean or ip
2.删除dangdang索引
DELETE /dangdang
3.创建id为1的文档记录
PUT /dangdang/product/1
{
"title": "赵小六",
"age": 23,
"name": "这是名称",
"created": "2012-12-12"
}
4.查询id为1的文档记录
GET /dangdang/product/1
5.删除id为1的文档记录
DELETE /dangdang/product/1
6.创建一个id随机的文档记录(注意要用POST请求)
POST /dangdang/product
{
"title":"赵小六2",
"age":231,
"name": "这是名2称",
"created":"2012-12-12"
}
7.更新文档id为1的数据
POST /dangdang/product/1/_update
{
"doc":{
"title": "赵小六1",
"age": 231,
"name": "这是名1称",
"created": "2012-12-12"
}
}
批量操作:批量时不会因为一个失败而全部失败,而是继续执行后续操作。
8.批量插入数据(指定id)
PUT /dangdang/product/_bulk
{"index":{"_id":"1"}}
{"name": "John Doe", "title": "这是标题", "age":23,"created":"2012-12-12"}
{"index":{"_id":"2"}}
{"name": "Jane Doe", "title": "这是标题", "age":23,"created":"2012-12-12"}
9.批量插入数据(不指定id)
POST /dangdang/product/_bulk
{"index":{}}
{"name": "John Doe", "title": "这是标题", "age":23,"created":"2012-12-12"}
{"index":{}}
{"name": "Jane Doe", "title": "这是标题", "age":23,"created":"2012-12-12"}
10.批量操作数据(添加、修改、删除)
POST /dangdang/product/_bulk
{"update":{"_id":"1"}}
{"doc":{"name":"lisi"}}
{"delete":{"_id":"2"}}
{"index":{}}
{"name":"xxx", "title": "这是标题", "age":23,"created":"2012-12-12"}
以下例子中的索引:online_house_achieve、类型:house
11.查询某个索引某个类型下的所有文档记录
GET /online_house_achieve/house/_search
{
"query": {"match_all": {}}
}
12.查看某个索引下的某个类型的结构:
GET /online_house_achieve/_mapping/house
13.根据某个字段降序排序查询文档数据
GET /online_house_achieve/house/_search
{
"query": {"match_all": {}},
"sort": [
{
"id": {
"order": "desc"
}
}
]
}
14.分页查询文档数据(from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果)
GET /online_house_achieve/house/_search
{
"query": {"match_all": {}},
"from": 1,
"size": 3
}
查询前10条文档数据:
GET /online_house_achieve/house/_search
{
"query": {"match_all": {}},
"size": 10
}
15.查询的文档数据返回指定字段
GET /online_house_achieve/house/_search
{
"query": {"match_all": {}},
"_source": ["houseType", "area"]
}
16.通过关键字查询文档记录
GET /online_house_achieve/house/_search
{
"query": {
"term": {
"orientation": {
"value": "东南"
}
}
}
}
通过使用term关键字查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词
通过使用term关键字查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
17.根据范围查询文档数据(gte: 大等于;lte :小等于;gt :大于;lt: 小于)
GET /online_house_achieve/house/_search
{
"query": {
"range": {
"id": {
"gte": 5,
"lte": 8
}
}
}
}
18.根据前缀查询文档数据
GET /online_house_achieve/house/_search
{
"query": {
"prefix": {
"houseType": {
"value": "两"
}
}
}
}
19.根据通配符匹配查询文档数据
GET /online_house_achieve/house/_search
{
"query": {
"wildcard": {
"info": {
"value": "风*"
}
}
}
}
? 用来匹配一个任意字符 * 用来匹配多个任意字符
20.根据多个id查询文档数据
GET /online_house_achieve/house/_search
{
"query": {
"ids": {
"values": ["5","8"]
}
}
}
21.模糊查询指定文档数据(用来模糊查询含有指定关键字的文档)
GET /online_house_achieve/house/_search
{
"query": {
"fuzzy": {
"ownerShip":"com8pn"
}
}
}
fuzzy 模糊查询 最大模糊错误 必须在0-2之间
- 搜索关键词长度为 2 不允许存在模糊 0
- 搜索关键词长度为3-5 允许一次模糊 0 1
- 搜索关键词长度大于5 允许最大2模糊
22. 布尔查询
must: 相当于&& 同时成立
should: 相当于|| 成立一个就行
must_not: 相当于! 不能满足任何一个
GET /online_house_achieve/house/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"id": {
"gte": 5,
"lte": 8
}
}
},
{
"wildcard": {
"renovation": {
"value": "精*"
}
}
}
],
"must_not": [
{
"wildcard": {
"ownerShip": {
"value": "comm?"
}
}
}
]
}
}
}
23.高亮查询
GET /online_house_achieve/house/_search
{
"query": {
"term": {
"ownerShip": {
"value": "common"
}
}
},
"highlight": {
"fields": {
"*": {}
}
}
}
自定义高亮html标签: 可以在highlight中使用pre_tags和post_tags
GET /online_house_achieve/house/_search
{
"query": {
"term": {
"ownerShip": {
"value": "common"
}
}
},
"highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields": {
"*": {}
}
}
}
多字段高亮 使用require_field_match开启多个字段高亮:
GET /online_house_achieve/house/_search
{
"query": {
"term": {
"info": {
"value": "房"
}
}
},
"highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"require_field_match":false,
"fields": {
"*": {}
}
}
}
24.多字段查询(只要查询的内容存在就会查出来!)
GET /online_house_achieve/house/_search
{
"query": {
"multi_match": {
"query": "你好",
"fields": ["info","details"]
}
}
}
25.多字段分词查询(只要查询的内容存在就会查出来!)
GET /online_house_achieve/house/_search
{
"query": {
"query_string": {
"query": "整个",
"analyzer": "ik_max_word",
"fields": ["info","details"]
}
}
}