1.用户空间和内核空间
虚拟内存被操作系统划分成两块:内核空间和用户空间,内核空间是内核代码运行的地方,用户空间是用户程序代码运行的地方。当进程运行在内核空间时就处于内核态,当进程运行在用户空间时就处于用户态。
为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响
举例:
str = "my string " //用户空间
x=x+2
file.write(str)//切换到内核空间(用户程序不能直接写文件,必须通过内核安排)
y=x+2//切换回用户空间
2.PIO与DMA(i/o设备和内存之间的数据传输方式)
PIO:很早以前的方式,数据要通过CPU存储转发,需要占用大量的CPU时间来读取文件,不好用
DMA:取代了PIO,它可以不经过CPU而直接进行磁盘和内存(内核空间)的数据交换。CPU只需要给DMA控制器下达命令,让DMA控制器来处理数据的传输即可,传输完毕再通知CPU,大大节省了系统资源。
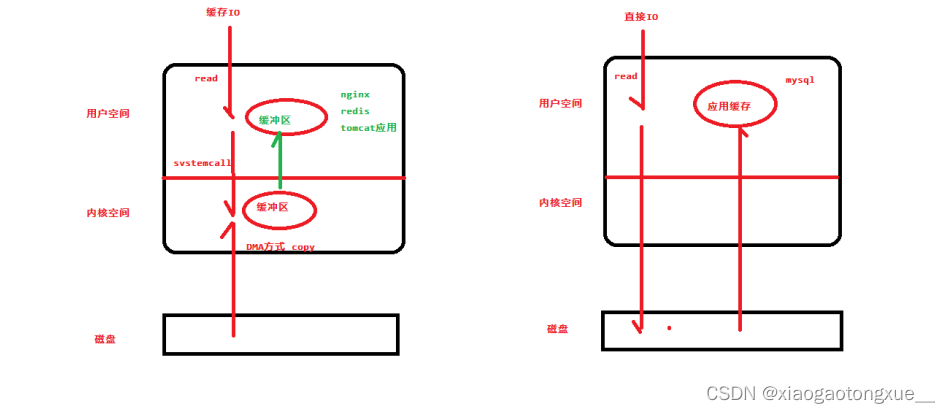
3.缓存IO和直接IO
缓存IO:数据从磁盘先通过DMA copy到内核空间,再从内核空间通过cpu copy到用户空间
直接IO:数据从磁盘通过DMA copy到用户空间
缓存I/O的优点:
1)在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
2)可以减少读盘的次数,从而提高性能。
缓存I/O的缺点:
在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序地址 空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存 开销是非常大的。
引入内核缓冲区的目的在于提高磁盘文件的访问性能,因为当进程需要读取磁盘文件时,如果文件内容已经在内核缓 冲区中,那么就不需要再次访问磁盘;而当进程需要向文件中写入数据时,实际上只是写到了内核缓冲区便告诉进程 已经写成功,而真正写入磁盘是通过一定的策略进行延迟的。
直接IO优点:
直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,也就是绕过内核缓冲区,自己管理I/O缓存区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。
(为了提高性能,和保证数据由数据库服务器来处理,mysql采用的就是直接IO)
直接IO缺点:
如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。通常直接I/O跟异步I/O结合使用会得到较好的性能
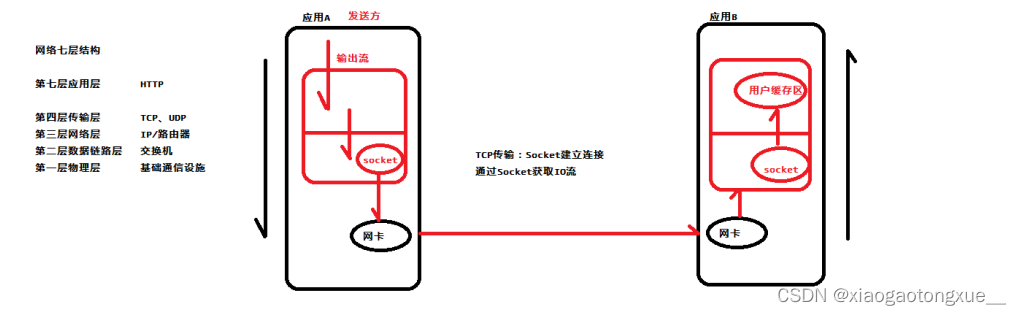
3.网络IO
1)操作系统将数据从磁盘复制到操作系统内核的页缓存中
2)应用将数据从内核缓存复制到应用的缓存中
3)应用将数据写回内核的Socket缓存中
4)操作系统将数据从Socket缓存区复制到网卡缓存,然后将其通过网络发出
(从流程可以看出来,它需要将数据复制好几次,每次复制都需要占用CPU资源)
图示:
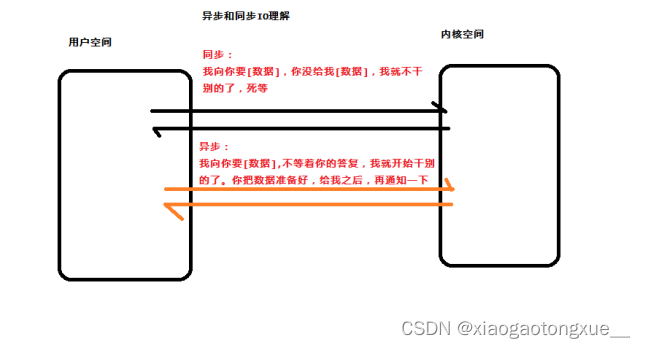
4.同步IO和异步IO
指的是用户空间和内核空间数据交互的方式
同步:用户空间要的数据,必须等到内核空间给它才做其他事情
异步:用户空间要的数据,不需要等到内核空间给它,才做其他事情。内核空间会异步通知用户进程,并把数据 直接给到用户空间。
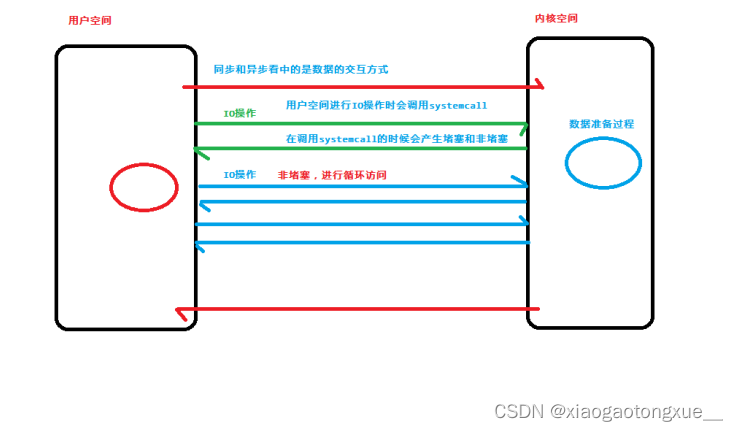
5.阻塞IO和非阻塞IO
堵塞:这是最常用的简单的IO模型。阻塞IO意味着当我们发起一次IO操作后一直等待成功或失败之后才返回,在这期间程序不能做其它的事情。阻塞IO操作只能对单个文件描述符进行操作,详见read或write。
非堵塞:我们在发起IO时,通过对文件描述符设置O_NONBLOCK flag来指定该文件描述符的IO操作为非阻塞。非阻塞IO通常发生在一个for循环当中,因为每次进行IO操作时要么IO操作成功,要么当IO操作会阻塞时返回错误EWOULDBLOCK/EAGAIN,然后再根据需要进行下一次的for循环操作,这种类似轮询的方式会浪费很多不必要的CPU资源,是一种糟糕的设计。和阻塞IO一样,非阻塞IO也是通过调用read或writewrite来进行操作的,也只能对单个描述符进行操作。
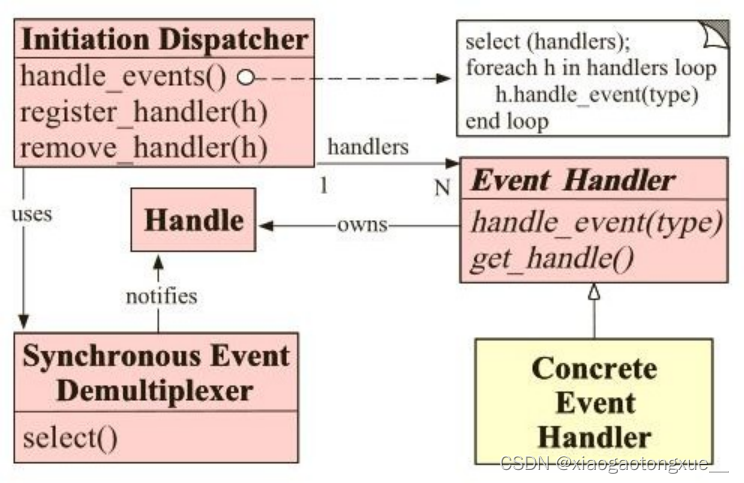
6.IO设计模式之Reactor
概述:
反应器设计模式(Reactor pattern)是一种为处理并发服务请求,并将请求提交到一个或者多个服务处理程序的事件设计模式。当客户端请求抵达后,服务处理程序使用多路分配策略,由一个非阻塞的线程来接收所有的请求,然后派发这些请求至相关的工作线程进行处理。
Reactor模式主要包含下面几部分内容:
初始事件分发器(Initialization Dispatcher):用于管理Event Handler,定义注册、移除EventHandler等。它还作为Reactor模式的入口调用Synchronous EventDemultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle将其分发给对应的Event Handler处理,即回调EventHandler中的handle_event()方法
同步(多路)事件分离器(Synchronous Event Demultiplexer):无限循环等待新事件的到来,一旦发现有新的事件到来,就会通知初始事件分发器去调取特定的事件处理器。
系统处理程序(Handles):操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文
件、一个连接(Socket)、Timer等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket
Handle,即一个网络连接(Connection,在Java NIO中的Channel)。这个Channel注册到Synchronous
EventDemultiplexer中,以监听Handle中发生的事件,对ServerSocketChannnel可以是CONNECT事件,对SocketChannel可以是READ、WRITE、CLOSE事件等。
事件处理器(Event Handler): 定义事件处理方法,以供Initialization Dispatcher回调使用。
图示:
IO模型
同步阻塞IO
同步阻塞IO模型是最简单的IO模型,用户线程在内核进行IO操作时被阻塞
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ihHkLpIQ-1672454474287)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20221229004036129.png)]](https://img-blog.csdnimg.cn/605e4e6a23d649d8b1cc6a84ef33c982.png)
整个IO请求的过程中,用户线程
是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
同步非阻塞IO
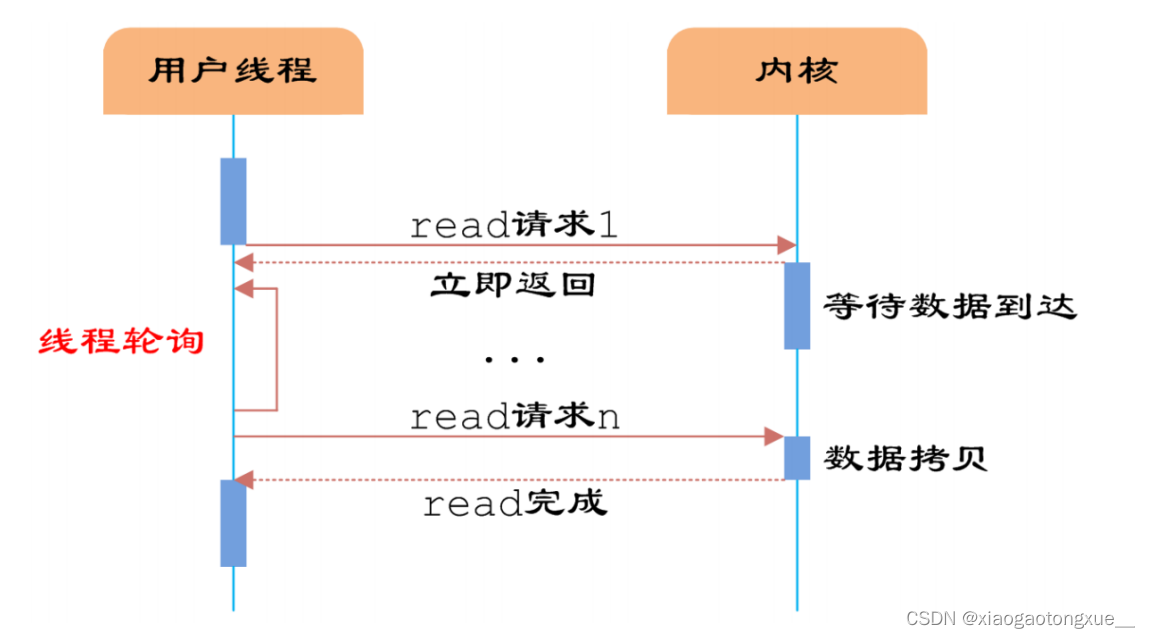
即用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的
过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了
大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性
IO多路复用
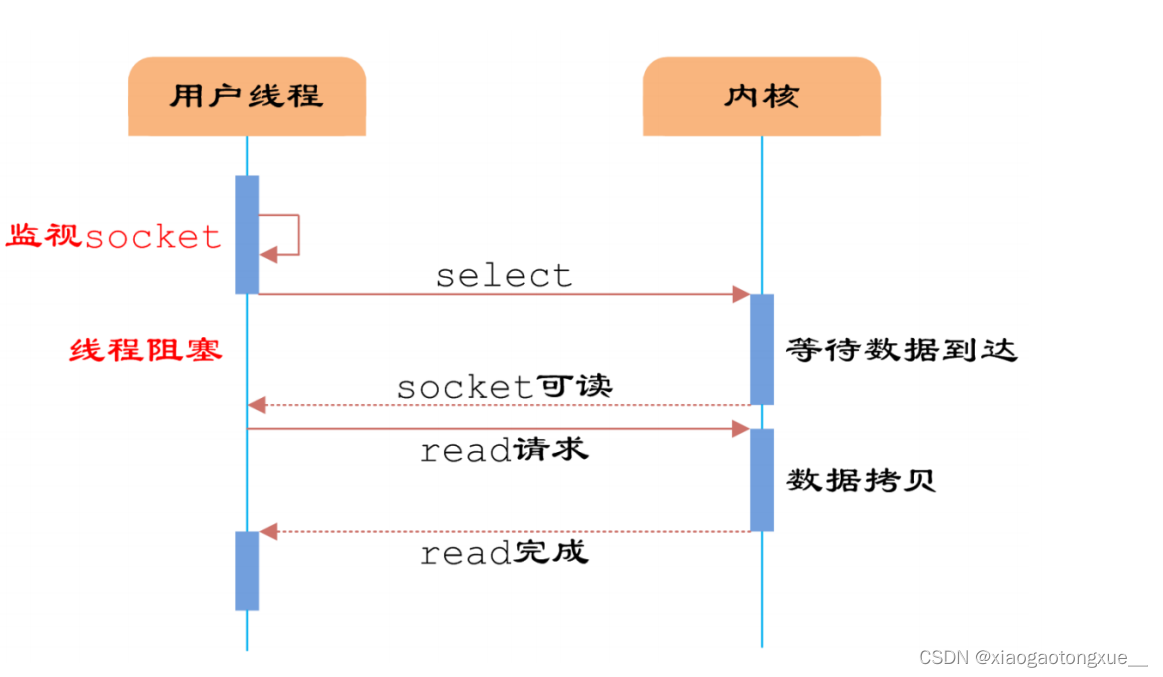
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
如果用户线程只注册自己
感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,
则可以提高CPU的利用率。
IO多路复用模型使用了Reactor设计模式实现了这一机制。
Reactor模式
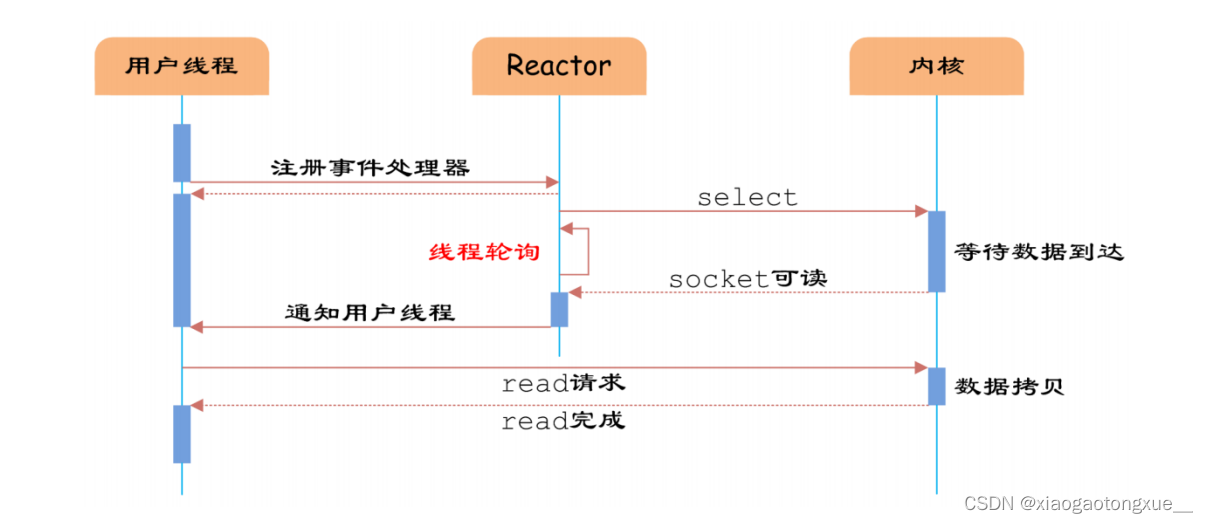
如图5所示,通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的操作