一、背景与简介
为了服务的高可用性,避免单点故障问题,通常我们使用"冗余设计思想"进行架构设计。冗余设计思想,本质就是将同一个应用或者服务放置在多台不同的服务器上[鸡蛋不放在同一个篮子里],这样减少整体服务宕机的可能性。我们通过概率学就能简单知道,例如一台服务器宕机的概率为1%,那么2台一样的机器同时宕机的概率就是0.01x0.01=0.01%, 依次类推,冗余的服务器越多,那么整体服务宕机的可能性就越小。 但是高可用和成本成正比关系,一个服务的可用性越高,付出的成本越高。
通常在应用的业务部署中间件中,Nginx扮演着反向代理与流量分发的角色。 例如之前我所在的公司将服务部署在本地IDC机房,整体对外、对内的流量都是经过Nginx作为网关入口。 如果Nginx存在单点问题,所在的服务器一旦发生宕机或者整个Nginx服务不可用,那么对业务的影响是致命的。
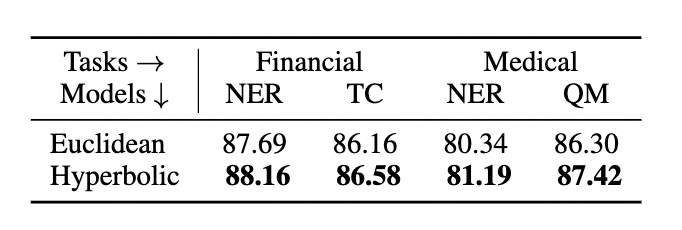
所以我们需要保证Nginx入口网关的高可用性。 我们学过一种编程思想: 面向抽象编程。 在这里,我们可以将要暴露Nginx网关服务的IP给到客户端的是VIP(Virtual IP)而非实际代理的物理IP。 我们将多个提供服务的物理IP形成一个逻辑IP组。VIP是一个虚拟IP(抽象层), VIP会时刻只对应一个物理IP, 一旦对应的物理IP发生故障,则可以漂移到这个逻辑IP组内健康的物理IP, 从而实现客户端无感故障迁移(客户端无效更改VIP地址,同时这个过程对于客户端而言是无感知的、透明的),实现服务的高可用。
架构图如下:
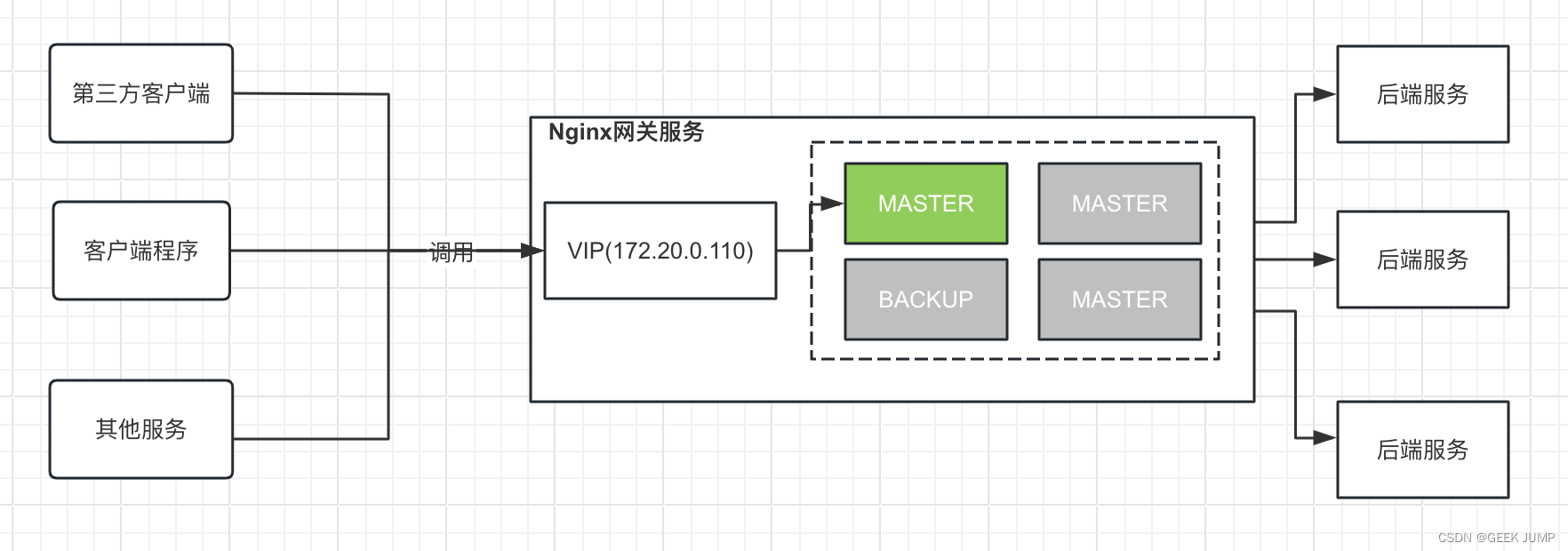 DNS服务器直接将域名绑定A记录指向VIP地址: 172.20.0.110, 客户端通过域名进行访问Nginx网关服务即可,后面Nginx网关服务无论是升级、故障转移等等,客户端无须修改域名或者代码,实现Nginx网关服务高可用以及无感故障转移。
DNS服务器直接将域名绑定A记录指向VIP地址: 172.20.0.110, 客户端通过域名进行访问Nginx网关服务即可,后面Nginx网关服务无论是升级、故障转移等等,客户端无须修改域名或者代码,实现Nginx网关服务高可用以及无感故障转移。
二、开源组件Keepalived
1、基本介绍
很幸运的是要实现上述的Nginx网关服务高可用问题,开源界有一个成熟的、可靠的中间件就是keepalived。
网上资料是这么介绍keepalived:
Keepalived 软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能。因此,Keepalived除了能够管理LVS软件外,还可以作为其他服务(例如:Nginx、Haproxy、MySQL等)的高可用解决方案软件。
Keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
所以,Keepalived 一方面具有配置管理LVS的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。
2、总结概括
Keepalived是一个通过VRRP网络协议、提供VIP漂移技术来实现冗余高可用设计的一个开源中间件。
通过合理的配置Keepalived我们就可以实现服务的高可用。
三、案例实验
1、实验的目标以及实验环境
本次实验都是基于docker-compose实现.
设计有2个容器(2台服务器),分别是172.20.0.2作为主服务器、172.20.0.3作为备用服务器, 服务器上都部署了Nginx服务, 我们需要要暴露这个服务给到其他客户端提供一个VIP。 后面测试主服务器宕机的时候,访问VIP是否访问到了172.20.0.3的页面。等主服务器又恢复正常的时候,访问VIP是否访问到的是172.20.0.2的页面。
Dockerfile内容如下:
FROM centos:7
RUN yum update -y
USER root
RUN yum install epel-release -y
RUN yum update -y
RUN yum install nginx keepalived -y
RUN yum install vim net-tools iproute -y
运行的目录结构如下:
docker-compose.yaml内容如下:
version: "3"
services:
nginx-master: # 172.20.0.2
build:
context: ./docker/
working_dir: "/root/"
privileged: true
hostname: "nginx-master"
expose:
- 80
entrypoint: ["tail", "-f", "/dev/null"]
nginx-backup: # 172.20.0.3
build:
context: ./docker/
working_dir: "/root/"
privileged: true
hostname: "nginx-backup"
expose:
- 80
entrypoint: [ "tail", "-f", "/dev/null" ]
运行着2个容器, 执行docker-compose up -d --build
2、测试两个容器显示的页面内容
在宿主机上执行curl命令,分别curl 2个IP查看返回Nginx提供的页面内容:

3、配置nginx-master容器(172.20.0.2)的keepalived.conf
文件位于/etc/keepalived/keepalived.conf
global_defs {
#keepalived节点唯一ID标识名称
router_id keep_02
}
vrrp_instance VI_1 {
#节点角色: MASTER、BACKUP
state MASTER
#绑定VIP的网卡名称
interface eth0
#虚拟路由ID组, 备用节点和主节点必须属于同一个组
virtual_router_id 172
#节点优先级, 取值范围 0-255, 主节点的优先级要大于备用节点
priority 100
#主备同步检查时间间隔
advert_int 1
#认证信息,主备一致
authentication {
auth_type PASS
auth_pass 1234
}
#VIP地址
virtual_ipaddress {
172.20.0.110
}
}启动keepalived:
keepalived -n -l # -n 前台运行 -l 显示运行日志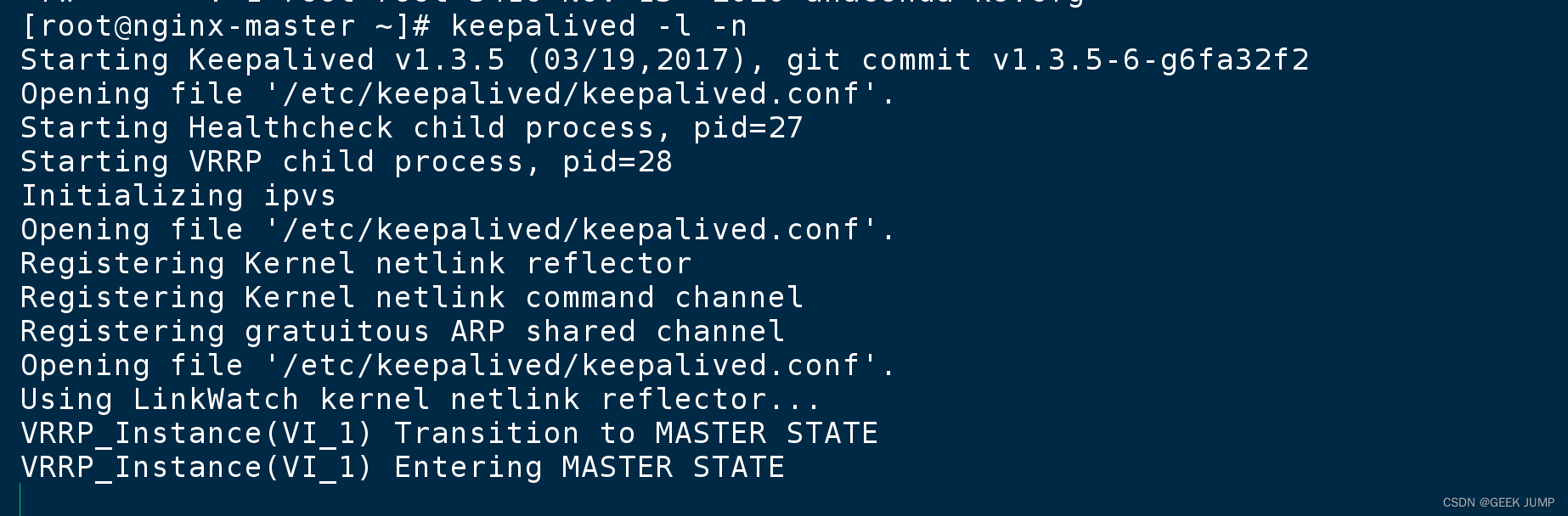
此时查看ip addr: 可以看到VIP 172.20.0.110 已经绑定在eth0网卡上了
宿主机此时curl 172.20.0.110得到结果是绑定在了master主节点的内容:

4、配置nginx-backup容器(172.20.0.3)的keepalived.conf
global_defs {
#keepalived节点唯一ID标识名称
router_id keep_03
}
vrrp_instance VI_1 {
#节点角色: MASTER、BACKUP
state BACKUP
#绑定VIP的网卡名称
interface eth0
#虚拟路由ID组, 备用节点和主节点必须属于同一个组
virtual_router_id 172
#节点优先级, 取值范围 0-255, 主节点的优先级要大于备用节点
priority 90
#主备同步检查时间间隔
advert_int 1
#认证信息,主备一致
authentication {
auth_type PASS
auth_pass 1234
}
#VIP地址
virtual_ipaddress {
172.20.0.110
}
}
启动keepalived:
keepalived -n -l # -n 前台运行 -l 显示运行日志 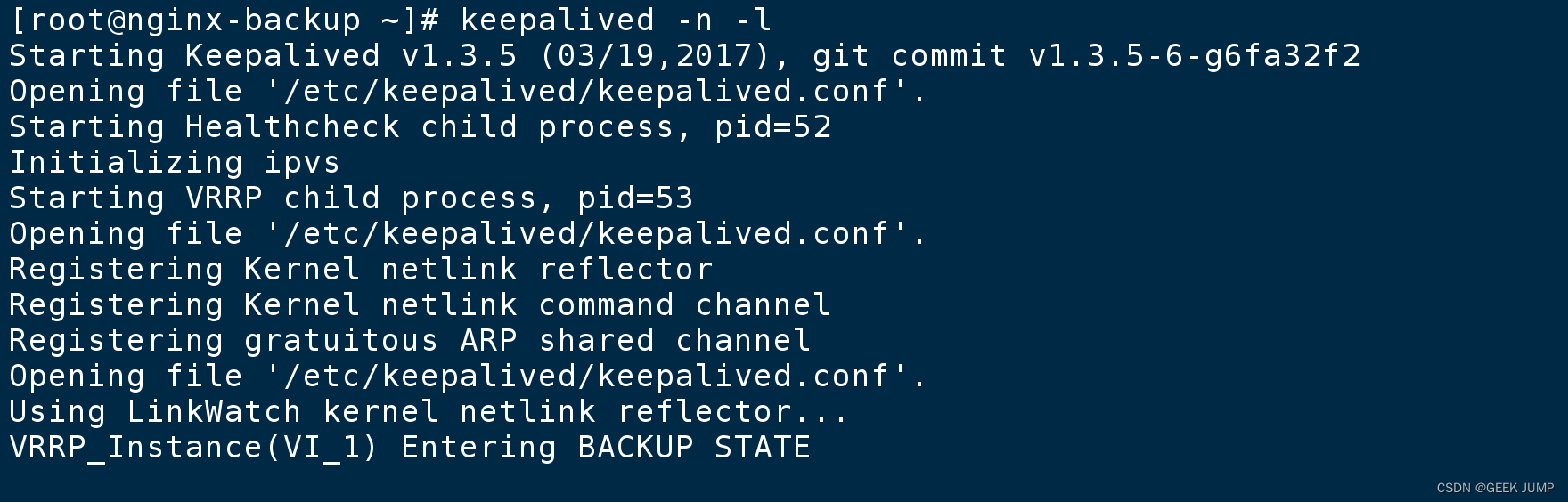
此时查看: ip addr 主节点keepalived还正常运行,自然备用节点拿不到VIP
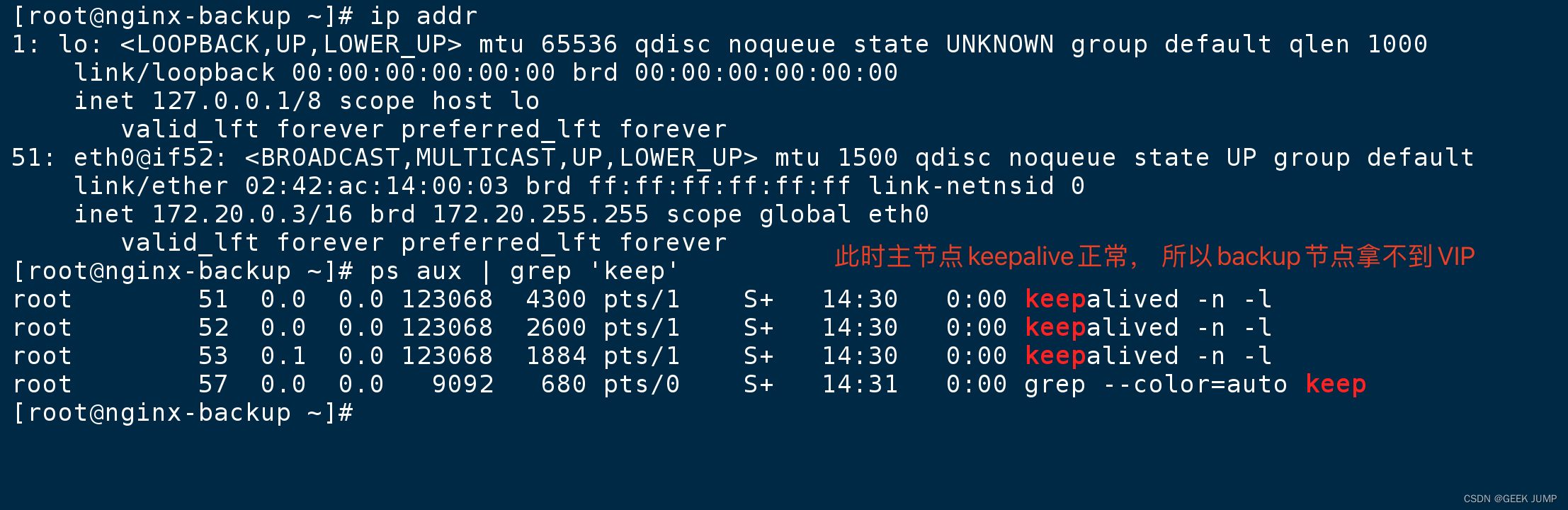
5、模拟主节点故障,手动关闭keepalived

此时在宿主机访问VIP curl 172.20.0.110:
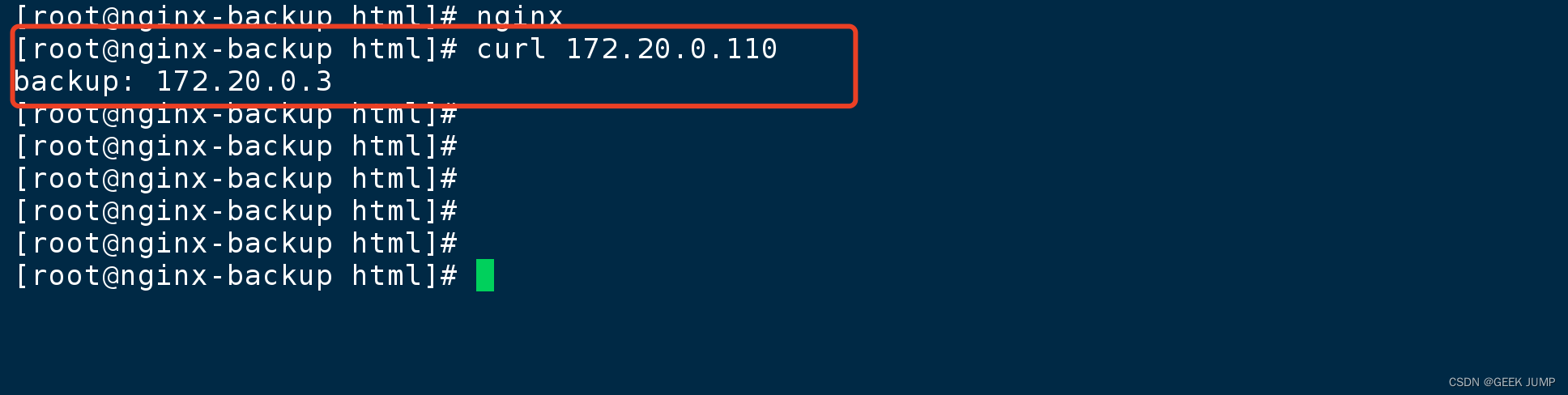
此时我们看到,同样是访问VIP地址, 第4步骤访问的时候返回的是master: 172.20.0.2, 但是我们手动关闭主节点的keepalived进程模拟故障的时候, 再次curl VIP地址, 访问得到的内容就是backup: 172.20.0.3 。
此时已经发生故障转移了,但是客户端访问的VIP没发生变化,我们在宿主机上执行的curl命令一模一样,但是返回的内容不一样了(实际情况来说,没出故障前以及出故障之后,得到的AIP的内容应该是一致的。 只是在这里做演示,让大家看情况故障转移过程,所以故意让返回的页面内容存在差异,容易对比)
6、模拟恢复主节点故障,启动keepalived进程
此时我们再次访问curl VIP : curl 172.20.0.110, 得到的内容又是master: 172.20.0.110, VIP已经实现了故障转移(IP漂移)

四、 总结
整个测试流程还算简单、清晰的。 我们使用keepalived要注意几点:
1、主节点、备用节点要属于同一个广播域,也就是同一个交换机下
2、启动keepalived默认是后台运行,启动后进入后台。但是为了更好调试错误加入了-n参数进行前台运行, 为了显示日志便于排错又增加了-l参数。 所以整体参数是
keepalived -n -l3、通过ip addr查看VIP代替ifconfig, ifconfig有时候是看不到VIP的存在,只看到了物理IP的存在
那使用Keepalived上述过程,就能确保服务高正无忧、毫无缺点了么? 其实不尽然。
1、大家会发现VIP时刻只会漂移到一个物理IP上,那么BACKUP备用节点都处于闲置状态,是不是太浪费资源了呢?
2、IP漂移或者不漂移是通过Keepalived进程是否存活来决定的。 那么如果存在一种情况就是Keepalived进程存活,此时拿到了VIP,但是Nginx挂了, 那本质上就是VIP拿到了占着茅坑不拉屎,整个服务都挂了。这种情况又该如何处理IP及时漂移到可用Nginx节点来达到高可用的目的呢?
预知后事如何,请听下回分解~