近日,阿里云人工智能平台PAI与华东师范大学数据科学与工程学院合作在自然语言处理顶级会议EMNLP2023上发表基于双曲空间和对比学习的垂直领域预训练语言模型。通过比较垂直领域和开放领域知识图谱数据结构的不同特性,发现在垂直领域的图谱结构具有全局稀疏,局部稠密的特点。为了补足全局稀疏特点,将垂直领域中分层语义信息通过双曲空间注入到预训练模型中。为了利用局部图结构稠密特点,我们利用对比学习构造图结构不同难度的正负样本来进一步加强语义稀疏的问题。
论文:
Ruyao Xu, Taolin Zhang, Chengyu Wang, Zhongjie Duan, Cen Chen, Minghui Qiu, Dawei Cheng, Xiaofeng He, Weining Qian. Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding. EMNLP 2023
背景
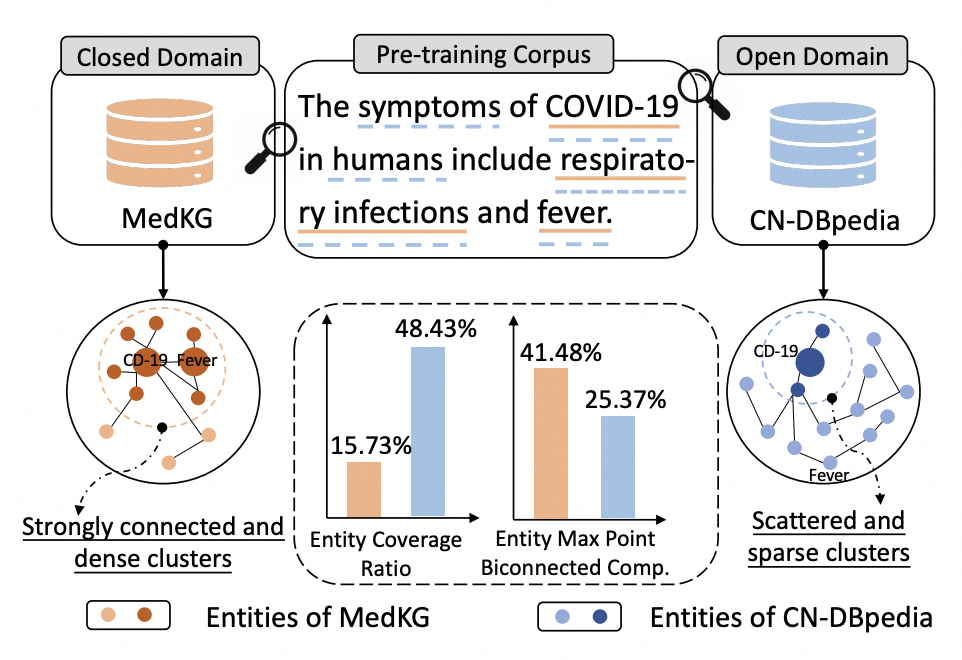
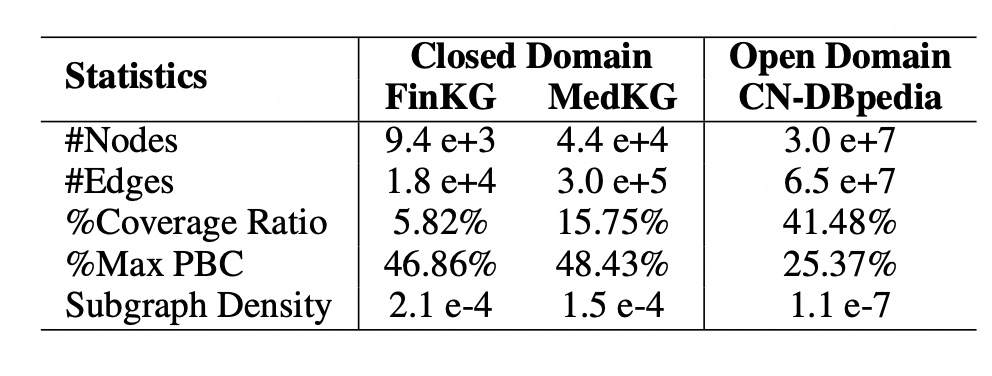
知识增强预训练语言模型(KEPLM)通过从大规模知识图(KGs)中注入知识事实来提高各种下游NLP任务的性能。然而,由于缺乏足够的域图语义,这些构建开放域KEPLM的方法很难直接迁移到垂直领域,因为它们缺乏对垂直领域KGs的特性进行深入建模。如下图所示,KG实体相对于纯文本的覆盖率在垂直领域中明显低于开放域,表明领域知识注入存在全局稀疏现象。这意味着将检索到的少数相关三元组直接注入到PLM中对于领域来说可能是不够的。我们进一步注意到,在垂直领域KGs中,最大点双连通分量的比率要高得多,这意味着这些KGs中同一实体类下的实体相互连接更紧密,并表现出局部密度特性。因此,本文研究是基于上述领域KG的数据特性提出了一个简单但有效的统一框架来学习各种垂直领域的KEPLM。
算法概述
为了解决上述垂直领域知识增强框架的问题,KANGAROO模型分别通过双曲空间学习垂直领域图谱数据的分层语义信息来补充全局语义稀疏模块Hyperbolic Knowledge-aware Aggregator,通过捕捉领域图谱稠密的图结构构造基于点双联通分量的对比学习模块Multi-Level Knowledge-aware Augmenter,模型框架图如下所示:
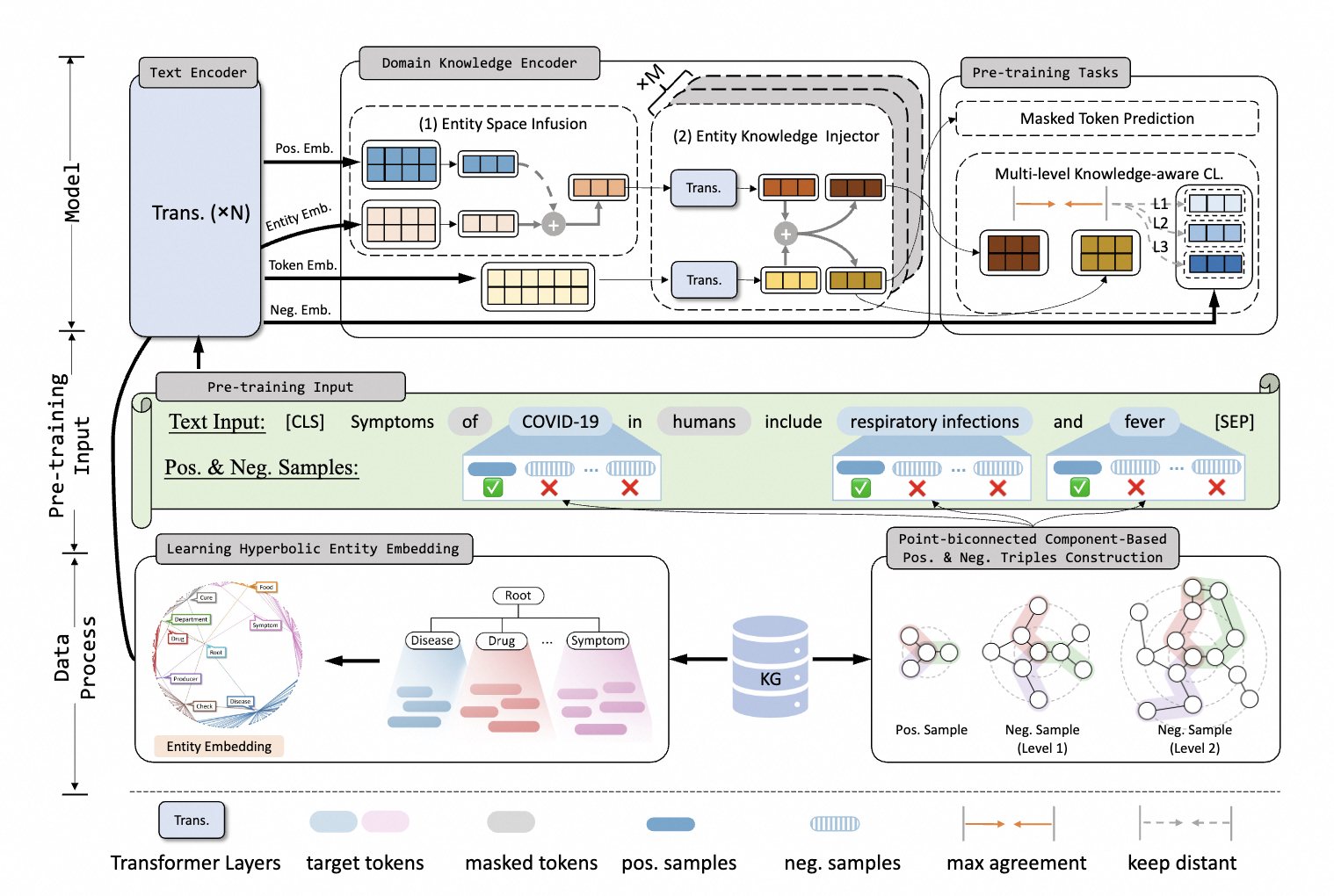
Hyperbolic Knowledge-aware Aggregator
Learning Hyperbolic Entity Embedding
首先,欧几里得空间中的嵌入算法由于嵌入空间的维度而难以对复杂模式进行建模。受庞加莱球模型的启发,由于重建的有效性,双曲空间对层次结构具有更强的代表能力,为了弥补闭域的全局语义不足,我们采用Poincaréball模型来同时学习基于层次实体类结构的结构和语义表示。两个实体(ei,ej)之间的距离为:
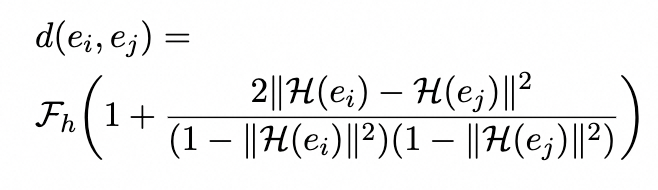
我们定义D={r(ei,ej)}是同义实体。然后我们最小化相关对象之间的距离以获得双曲嵌入
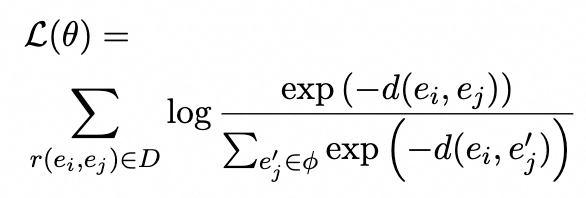
Domain Knowledge Encoder
该模块设计用于对输入token和实体进行编码,并融合它们的异构嵌入,包含两部分:Entity Space Infusion 和 Entity Knowledge Injector。
Entity Space Infusion
为了将双曲嵌入集成到上下文表示中,我们通过级联将实体类嵌入注入到实体表示中:
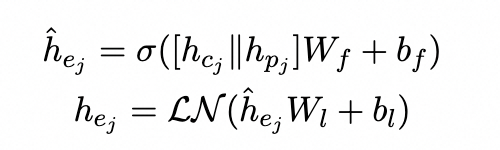
Entity Knowledge Injector
它旨在融合实体嵌入{hej}m的异构特征。为了匹配来自领域KGs的相关实体,我们采用重叠单词数量大于阈值的实体。利用M层聚合器作为知识注入器,能够集成不同级别的学习融合结果。在每个聚合器中,两个嵌入都被输送到多头注意力层:
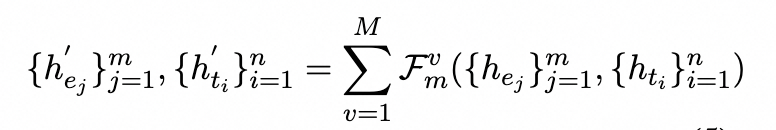
我们将实体嵌入注入上下文感知表示中,并从混合表示中重新获取它们:
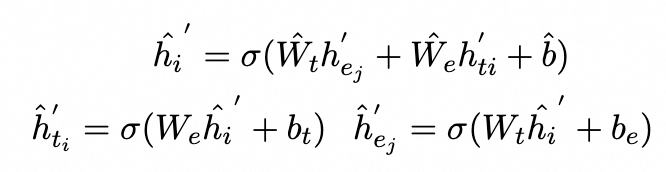
Multi-Level Knowledge-aware Augmenter
它使模型能够学习注入的知识三元组的更细粒度的语义关系,利用图谱局部结构特征来进一步纠正全局稀疏性问题。我们着重于通过点双连通分量子图结构构造具有多个难度级别的高质量正样本和负样本。示例构造流程如下图所示。
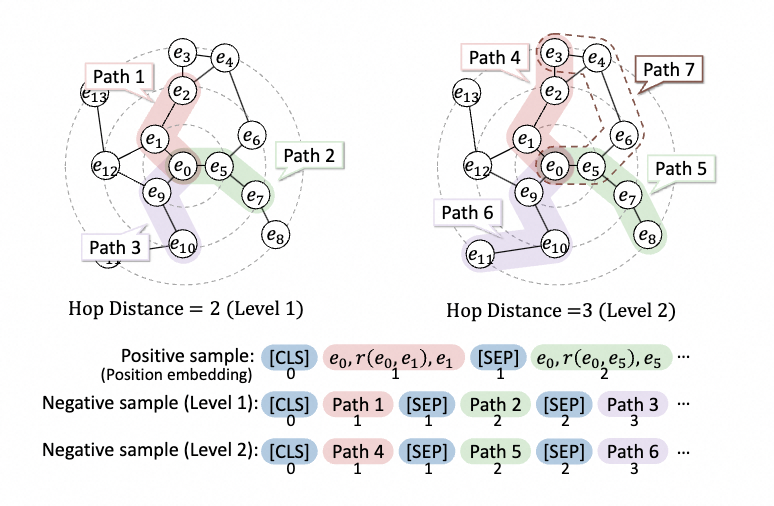
Positive Sample Construction
我们提取目标实体的K个相邻三元组作为正样本,它们在相邻候选子图结构中最接近目标实体。这些三元组中包含的语义信息有利于增强上下文知识。为了更好地聚合目标实体和上下文标记表示,将K个相邻三元组转换后拼接到一个句子中。通过共享的文本编码器(例如BERT)获得统一的语义表示。由于来自离散实体和关系的不同三元组的采样之间存在语义不连续性,我们修改位置嵌入,使相同三元组的标记共享相同的位置索引,反之亦然。例如,上图中输入标记的三元组位置(e0,r(e0、e1)、e1)均为1。为了统一表示空间,我们采用[CLS](即BERT中的输入格式的token)表示为正样本嵌入以表示样本序列信息。
Point-biconnected Component-based Negative Sample Construction
在领域KGs中,由于具有有利于图的局部稠密性质,节点与相邻节点是稠密连接的搜索。因此,我们搜索大量距离目标实体更远的节点作为负样本。
- 第一步:以起始节点Estart(即e0)为中心点,沿着这些relation向外进行搜索,我们得到了具有不同hop(P(G,estart,eend))的端节点Eend,其中hop(·)表示跳距,P(G,ei,ej)表示图G中实体之间的最短路径。例如,路径3中的跳跃点(P(G,e0,e10))=2,路径6中的跃点数(P(G,e0、e11))=3
- 我们利用跳跃距离来构建具有不同结构难度水平的负样本,其中,对于1级样本,hop(·)=2,对于n级样本,hop(·)=n+1。我们假设跳跃距离越近,就越难区分三元组与起始节点之间包含的语义知识。
- 负样本的构造模式类似于正样本,正样本具有相同距离的路径被合并成句子。注意,当节点对包含至少两条不相交的路径(即点双连通分量)时,我们选择最短路径(例如,路径4)。对于每个实体,我们构建k个级别的负样本。
Training Objectives
我们模型的损失函数主要包含了两个部分,一个是普通token级别的MLM掩码任务,另外一个是基于点双联通分量的对比学习任务。
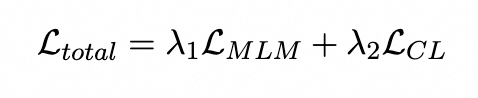
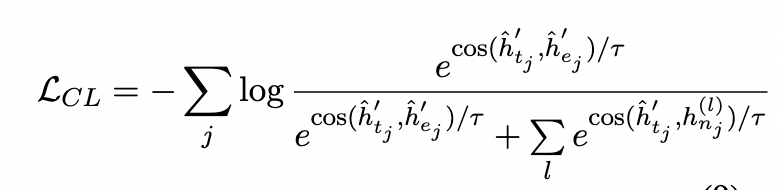
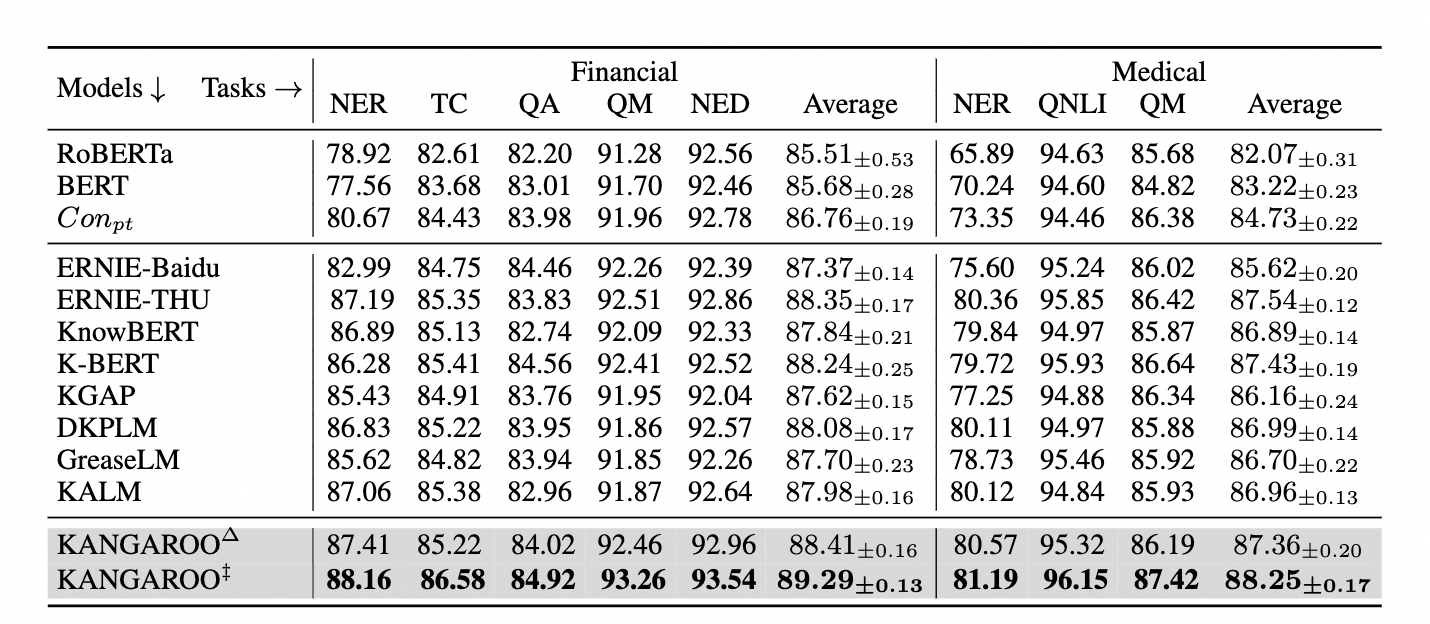
算法精度评测
为了评估KANGAROO模型在垂直领域预训练模型的效果,我们选取了金融和医疗等领域的各种下游任务的全数据量和少样本数据量场景进行评测。
- 全数据量微调实验结果
- 少样本数据微调数据结果

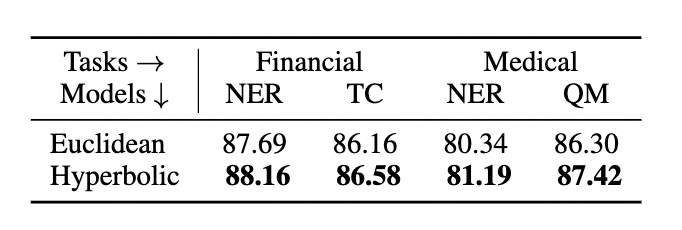
为了比较不同图谱数据表示方法的效果不同,我们对比了欧式距离和双曲距离之间的结果如下:
为了更好地服务开源社区,KANGAROO算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:GitHub - alibaba/EasyNLP: EasyNLP: A Comprehensive and Easy-to-use NLP Toolkit
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: enhanced language representation with informative entities. In ACL, pages 1441–1451.
- Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. 2021. KEPLER: A unified model for knowledge embedding and pre-trained language representation.Trans. Assoc. Comput. Linguistics, 9:176–194.
- Yusheng Su, Xu Han, Zhengyan Zhang, Yankai Lin, Peng Li, Zhiyuan Liu, Jie Zhou, and Maosong Sun. 2021. Cokebert: Contextual knowledge selection and embedding towards enhanced pre-trained language models. AI Open, 2:127–134
论文信息
论文标题:Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
论文作者:徐如瑶、张涛林、汪诚愚、段忠杰、陈岑、邱明辉、程大伟、何晓丰、钱卫宁
论文pdf链接:https://arxiv.org/abs/2311.06761