分析器
两种常用的英语分析器
1 测试工具
#可以通过这个来测试分析器 实际生产环境中我们肯定是配置在索引中来工作
GET _analyze
{
"text": "My Mom's Son is an excellent teacher",
"analyzer": "english"
}
2 实际效果
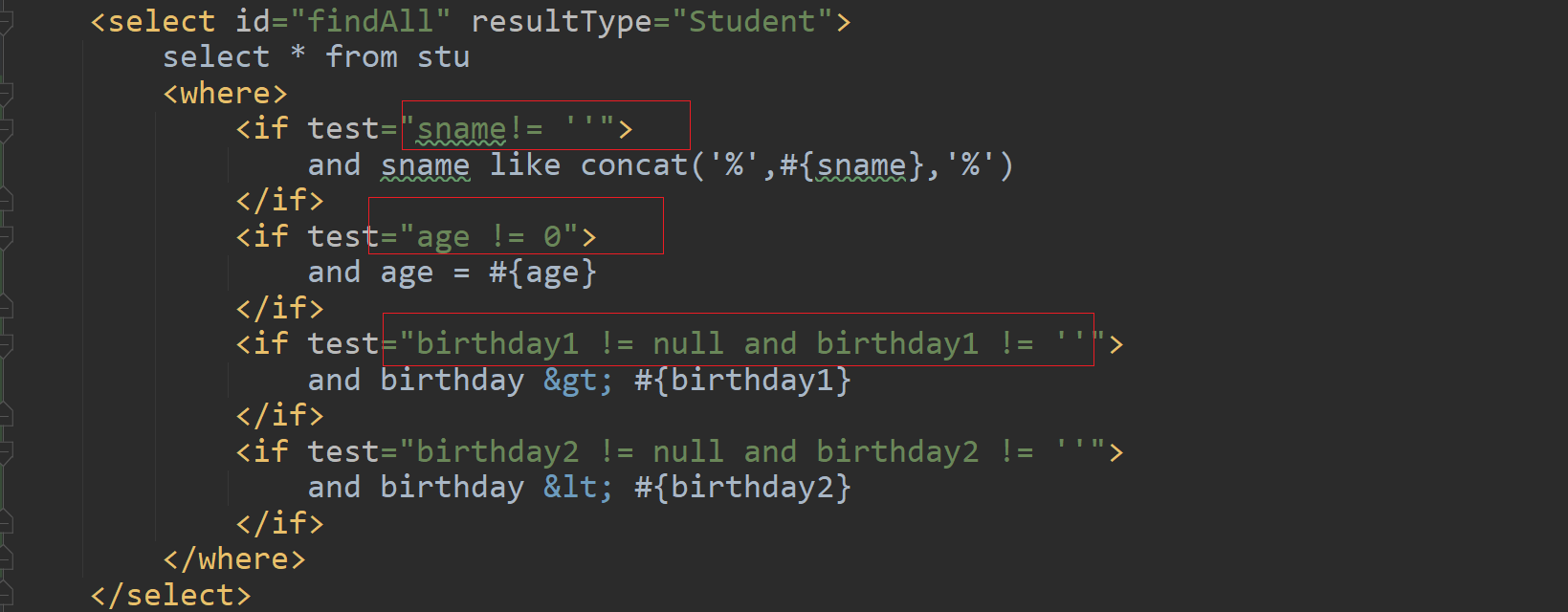
比如我们有下面这样一句话:My Mom’s Son is an excellent teacher
GET _analyze
{
"text": "My Mom's Son is an excellent teacher",
"analyzer": "english"
}
分析器分析以后,大写统一转换为了小写,is 被省了 等,所以经过这个分析器处理以后会得到下面的结果
我们换一个分析器结果就会不一样
GET _analyze
{
"text": "My Mom's Son is an excellent teacher",
"analyzer": "standard"
}
结果如下:

char_filter
- html_strip 用来处理html标签
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
#这里是申明
"my_char_filter": {
"type": "html_strip", #过滤html 标签
"escaped_tags": [
"a" #忽略a标签
]
}
},
"analyzer": {
#这里是使用
"my_analyzer": {
"char_filter": [
"my_char_filter"
],
"tokenizer": "keyword"
}
}
}
}
}
GET /my_index/_analyze
{
"text" : "<html>fdsf</html>",
"analyzer": "my_analyzer"
}
可以看到html这个表签被替换掉了:

- mapping 用来处理映射
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": ["S=>*","B=>*"]
}
},
"analyzer": {
"my_analyzer": {
"char_filter": [
"my_char_filter"
],
"tokenizer": "keyword"
}
}
}
}
}
GET /my_index/_analyze
{
"text" : "总是加班真SB",
"analyzer": "my_analyzer"
}
结果如下:

- pattern_replace
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern":"(\\d{3})\\d(\\d{4})",
"replacement" : "$1****$2"
}
},
"analyzer": {
"my_analyzer": {
"char_filter": [
"my_char_filter" #这里是可以写多个的
],
"tokenizer": "keyword"
}
}
}
}
}
GET /my_index/_analyze
{
"text" : "1008610086",
"analyzer": "my_analyzer"
}

Filter
- synonym_graph
PUT my_index
{
"settings": {
"analysis": {
"filter": {
"my_filter": {
"type": "synonym_graph",
"synonyms_path" : "analysis/analysis.txt" #这里修改文件好像是不能直接生效需要重新创建索引
}
},
"analyzer": {
"my_analyzer": {
"filter": [
"my_filter"
],
"tokenizer": "keyword"
}
}
}
}
}
GET /my_index/_analyze
{
"text" : ["liyong","love","baby"],
"analyzer": "my_analyzer"
}
运行结果如下:

也可以直接写到下面:
PUT my_index
{
"settings": {
"analysis": {
"filter": {
"my_filter": {
"type": "synonym_graph",
"synonyms" : ["liyong,love,baby=>99"] #直接把映射的东西写到这里
}
},
"analyzer": {
"my_analyzer": {
"filter": [
"my_filter"
],
"tokenizer": "keyword"
}
}
}
}
}
GET /my_index/_analyze
{
"text" : ["liyong","love","baby"],
"analyzer": "my_analyzer"
}

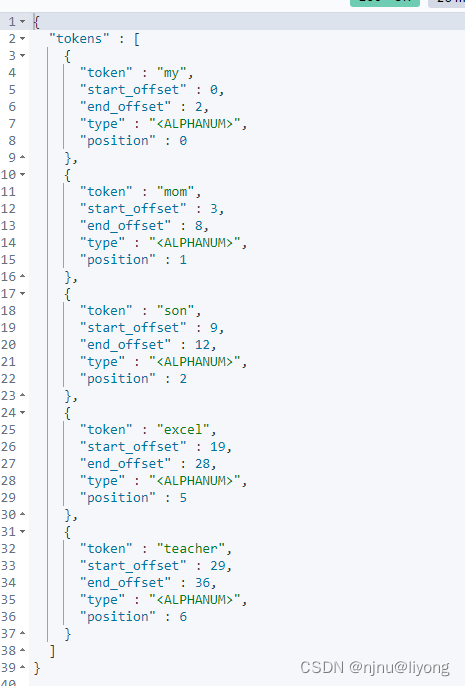
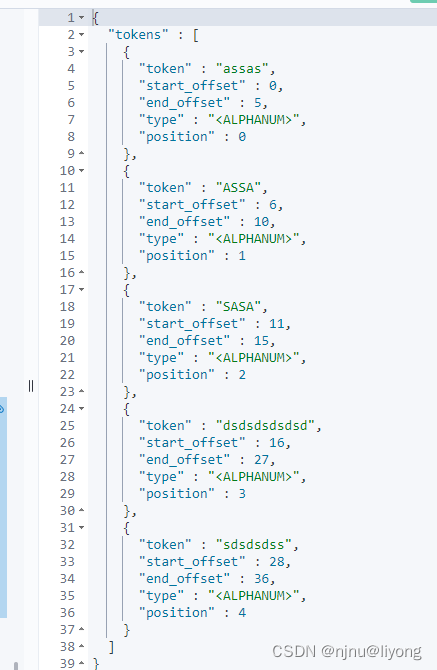
GET my_index/_analyze
{
"tokenizer": "standard",
"filter":{
"type": "condition", #条件也就是根据下面的条件
"filter":"uppercase", #转换为大写
"script": {
"source": "token.getTerm().length()<5" #小于5的字符串替换为大写
}
},
"text":["assas assa sasa dsdsdsdsdsd sdsdsdss"]
}
- stop
Stopwords⽤于删除不要的介词和词语,以下为简写
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard",
"stopwords": [
"me",
"you"
]
}
}
}
}
}
也可以这样写:
PUT my_index
{
"settings": {
"analysis": {
"filter": {
"my_filter": {
"type": "stop",
"stopwords": [
"me",
"you"
]
}
},
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": [
"my_filter"
]
}
}
}
}
}
自定义分析器
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"&=>and",
"|=>or"
]
}
},
"filter": {
"my_filter": {
"type": "stop",
"stopwords": [
"is",
"in",
"a",
"at"
]
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": "[ ,.!]"
}
},
"analyzer": {
"my_analyzer": {
"char_filter": [
"my_char_filter"
],
"filter": [
"my_filter"
],
"tokenizer": "my_tokenizer",
"type": "custom" #指定自定义
}
}
}
}
}
tokenizer 重写了分词方式 比如这个例子就是按照, . !来分割,然后进行后续的过滤处理,在实际生产环境中非常重要。
中文分词器
ik下载
安装到插件下面:
#由于没有对应的版本需要修改这个文件强行改成我们的版本
vim plugin-descriptor.properties
注意ik文件的所属用户和所属组
- 使用
GET /my_index/_analyze
{
"text": "我是一个兵来自老百姓",
"analyzer": "ik_smart"
}


- 自定义分词库
我再config 新建一个目录config/custom.dic 自定义输入

<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">./custom/custom.dic;./custom/custom1.dic</entry> #如果有多个用;隔开
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 --> #这里支持远程网址词典获取这样做的好处是不用重启es 这里就可以写一个controller 来把词典打印到网页上 https://blog.csdn.net/qq_34304427/article/details/123539694?spm=1001.2014.3001.5502 可以参考这篇博客
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
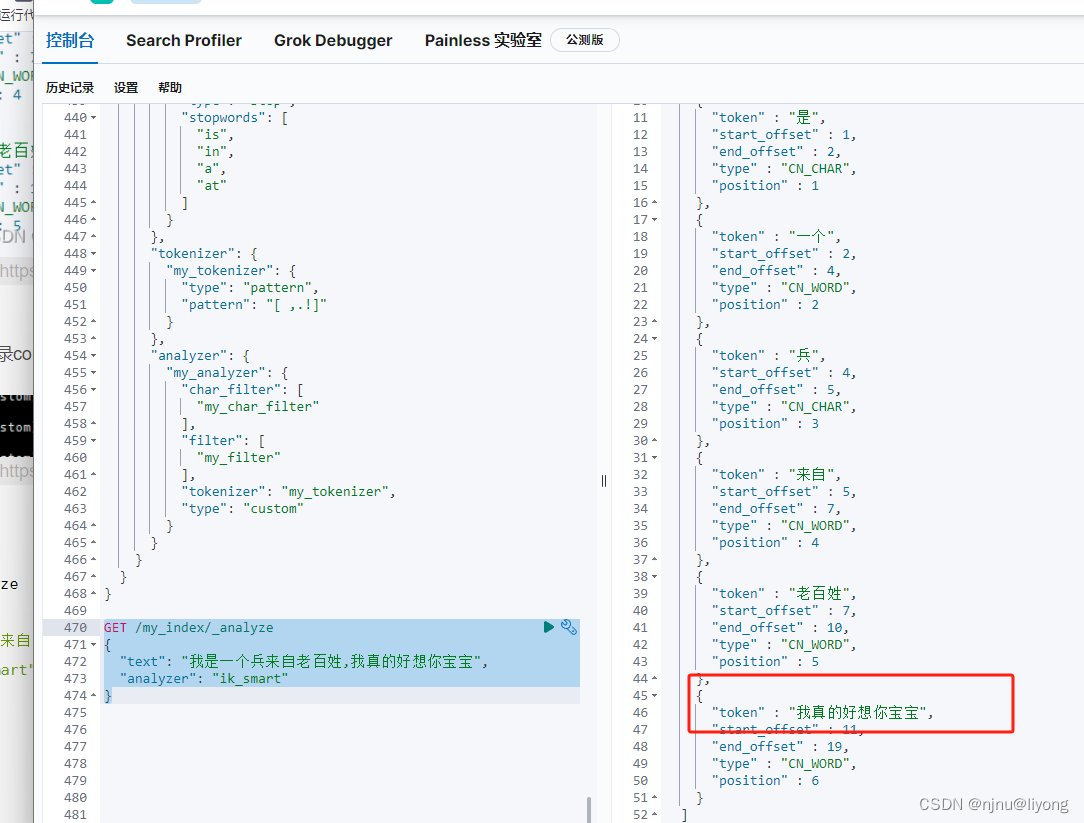
GET /my_index/_analyze
{
"text": "我是一个兵来自老百姓,我真的好想你宝宝",
"analyzer": "ik_smart"
}