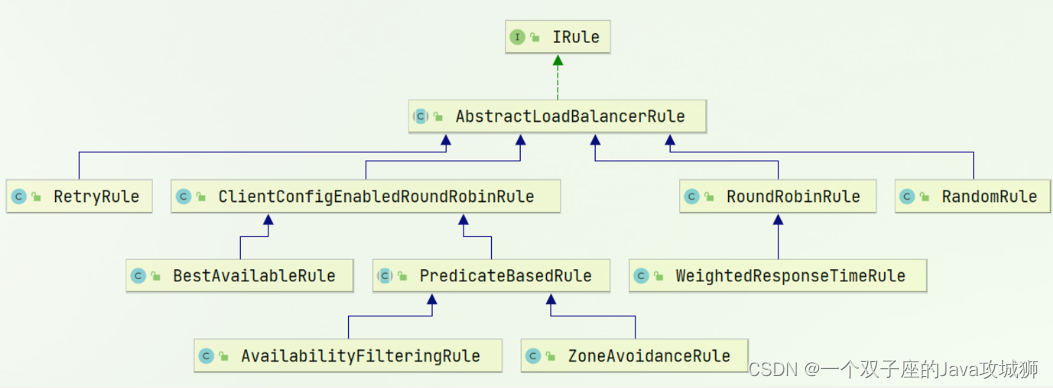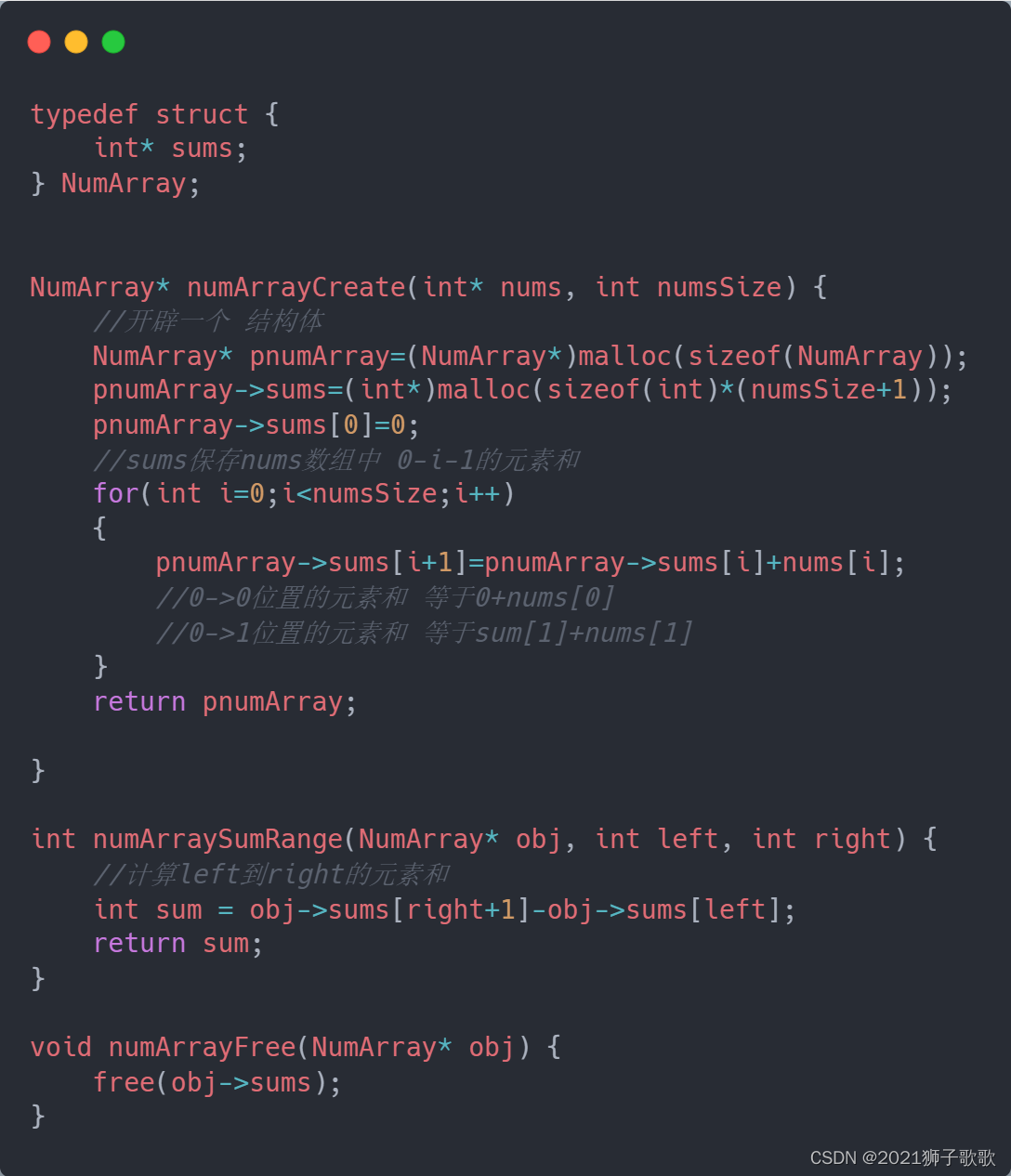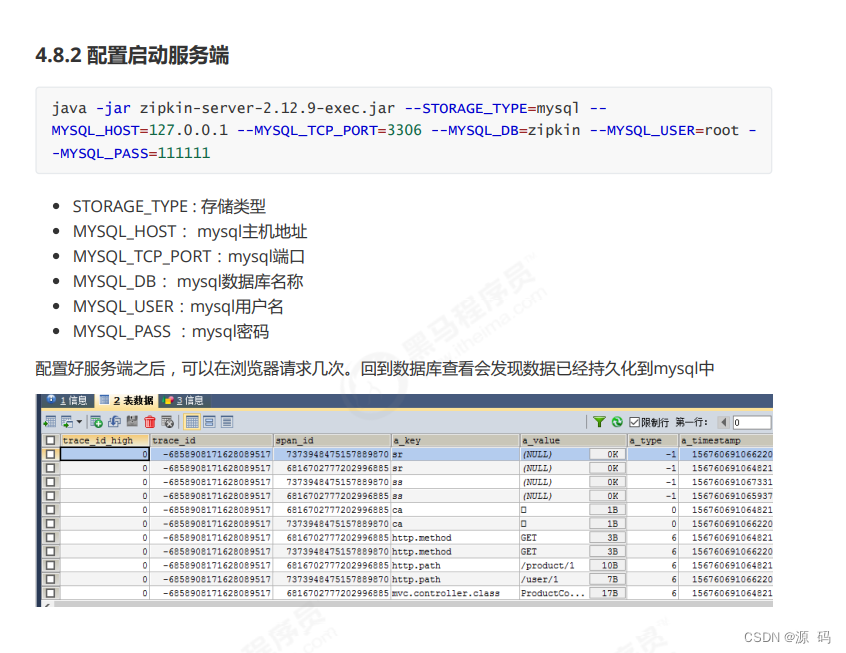
大多数据仓库的数据架构可以概括为:
数据源-->ODS(操作型数据存储)-->DW-->DM(data mart)
ETL贯穿其各个环节。
一、数据抽取:
可以理解为是把源数据的数据抽取到ODS或者DW中。
1. 源数据类型:
关系型数据库,如Oracle,Mysql,Sqlserver等;
文本文件,如用户浏览网站产生的日志文件,业务系统以文件形式提供的数据等;
其他外部数据,如手工录入的数据等;
2. 抽取的频率:
大多是每天抽取一次,也可以根据业务需求每小时甚至每分钟抽取,当然得考虑源数据库系统能否承受;
3. 抽取策略:
个人感觉这是数据抽取中最重要的部分,可分为全量抽取和增量抽取。
全量抽取,适用于那些数据量比较小,并且不容易判断其数据发生改变的诸如关系表,维度表,配置表等;
增量抽取,一般是由于数据量大,不可能采用全量抽取,或者为了节省抽取时间而采用的抽取策略;
如何判断增量,这是增量抽取中最难的部分,一般包括以下几种情况:
a) 通过时间标识字段抽取增量;源数据表中有明确的可以标识当天数据的字段的流水表,如createtime,updatetime等;
b) 根据上次抽取结束时候记录的自增长ID来抽取增量;无createtime,但有自增长类型字段的流水表,如自增长的ID,抽取完之后记录下最大的ID,下次抽取可根据上次记录的ID来抽取;
c) 通过分析数据库日志获取增量数据,无时间标识字段,无自增长ID的关系型数据库中的表;
d) 通过与前一天数据的Hash比较,比较出发生变化的数据,这种策略比较复杂,在这里描述一下,比如一张会员表,它的主键是memberID,而会员的状态是有可能每天都更新的,我们在第一次抽取之后,生成一张备用表A,包含两个字段,第一个是memberID,第二个是除了memberID之外其他所有字段拼接起来,再做个Hash生成的字段,在下一次抽取的时候,将源表同样的处理,生成表B,将B和A左关联,Hash字段不相等的,为发生变化的记录,另外还有一部分新增的记录,根据这两部分记录的memberID去源表中抽取对应的记录;
e) 由源系统主动推送增量数据;例如订单表,交易表,有些业务系统在设计的时候,当一个订单状态发生变化的时候,是去源表中做update,而我们在数据仓库中需要把一个订单的所有状态都记录下来,这时候就需要在源系统上做文章,数据库触发器一般不可取。我能想到的方法是在业务系统上做些变动,当订单状态发生变化时候,记一张流水表,可以是写进数据库,也可以是记录日志文件。当然肯定还有其他抽取策略,至于采取哪种策略,需要考虑源数据系统情况,抽取过来的数据在数据仓库中的存储和处理逻辑,抽取的时间窗口等等因素。
二、数据清洗:
顾名思义,就是把不需要的,和不符合规范的数据进行处理。数据清洗最好放在抽取的环节进行,这样可以节约后续的计算和存储成本;当源数据为数据库时候,其他抽取数据的SQL中就可以进行很多数据清洗的工作了。
数据清洗主要包括以下几个方面:
1. 空值处理;根据业务需要,可以将空值替换为特定的值或者直接过滤掉;
2. 验证数据正确性;主要是把不符合业务含义的数据做一处理,比如,把一个表示数量的字段中的字符串替换为0,把一个日期字段的非日期字符串过滤掉等等;
3. 规范数据格式;比如,把所有的日期都格式化成YYYY-MM-DD的格式等;
4. 数据转码;把一个源数据中用编码表示的字段,通过关联编码表,转换成代表其真实意义的值等等;
5. 数据标准,统一;比如在源数据中表示男女的方式有很多种,在抽取的时候,直接根据模型中定义的值做转化,统一表示男女;
6. 其他业务规则定义的数据清洗。。。
三、数据转换和加载:
很多人理解的ETL是在经过前两个部分之后,加载到数据仓库的数据库中就完事了。
数据转换和加载不仅仅是在源数据-->ODS这一步,ODS-->DW, DW-->DM包含更为重要和复杂的ETL过程。
1. 什么是ODS?
ODS(Operational Data Store)是数据仓库体系结构中的一个可选部分,ODS具备数据仓库的部分特征和OLTP系统的部分特征,它是“面向主题的、集成的、当前或接近当前的、 不断变化的”数据。---摘自百度百科
其实大多时候,ODS只是充当了一个数据临时存储,数据缓冲的角色。一般来说,数据由源数据加载到ODS之后,会保留一段时间,当后面的数据处理逻辑有问题,需要重新计算的时候,可以直接从ODS这一步获取,而不用再从源数据再抽取一次,减少对源系统的压力。另外,ODS还会直接给DM或者前端报表提供数据,比如一些维表或者不需要经过计算和处理的数据;还有,ODS会完成一些其他事情,比如,存储一些明细数据以备不时之需等等;
2. 数据转换(刷新):
数据转换,更多的人把它叫做数据刷新,就是用ODS中的增量或者全量数据来刷新DW中的表。DW中的表基本都是按照事先设计好的模型创建的,如事实表,维度表,汇总表等,每天都需要把新的数据更新到这些表中。更新这些表的过程(程序)都是刚开始的时候开发好的,每天只需要传一些参数,如日期,来运行这些程序即可。
3. 数据加载:
个人认为,每insert数据到一张表,都可以称为数据加载,至于是delete+insert、truncate+insert、还是merge,这个是由业务规则决定的,这些操作也都是嵌入到数据抽取、转换的程序中的。
四、ETL工具:
在传统行业的数据仓库项目中,大多会采用一些现成的ETL工具,如Informatica、Datastage、微软SSIS等。这三种工具我都使用过,优点有:图形界面,开发简单,数据流向清晰;缺点:局限性,不够灵活,处理大数据量比较吃力,查错困难,昂贵的费用;选择ETL工具需要充分考虑源系统和数据仓库的环境,当然还有成本,如果源数据系统和数据仓库都采用ORACLE,那么我觉得所有的ETL,都可以用存储过程来完成了。。
在大一点的互联网公司,由于数据量大,需求特殊,ETL工具大多为自己开发,或者在开源工具上再进行一些二次开发,在实际工作中,一个存储过程,一个shell/perl脚本,一个java程序等等,都可以作为ETL工具。
五、ETL过程中的元数据:
试想一下,你作为一个新人接手别人的工作,没有文档,程序没有注释,数据库中的表和字段也没有任何comment,你是不是会骂娘了?业务系统发生改变,删除了一个字段,需要数据仓库也做出相应调整的时候, 你如何知道改这个字段会对哪些程序产生影响?。。。。源系统表的字段及其含义,源系统数据库的IP、接口人,数据仓库表的字段及其含义,源表和目标表的对应关系,一个任务对应的源表和目标表,任务之间的依赖关系, 任务每次执行情况等等等等,这些元数据如果都能严格的管控起来,上面的问题肯定不会是问题了。。。
Q:使用ETL 我都是用的存储过程,ETL工具有什么用处呢?
A:1.如果你的数据来自于不同的物理主机,而物理主机存放在不同的地区.使用自己的SQL语句就显得比较吃力和需要更大的开销.
2.若数据是不自不同的数据库软件,如有MySQL,oracl,SAP,DB2等,多套数据库的资料,如何使用SQL语句.先将它们集中到一个MS SQL server,再自己实现SQL语句.但这仍是复杂,繁琐;而且各数据库厂商之间的数据格式也是多样的。甚至它们也存放在不同的子公司里头。
3.若使用自己的存储过程,在处理海量数据时也较为吃力.
SSIS中的ETL则可以通过不同的工作流和控件流,统一的连接管理器,对多源的数据进行抽取(E),转换(T),加载(L).使得整个过程更系统化,统一.
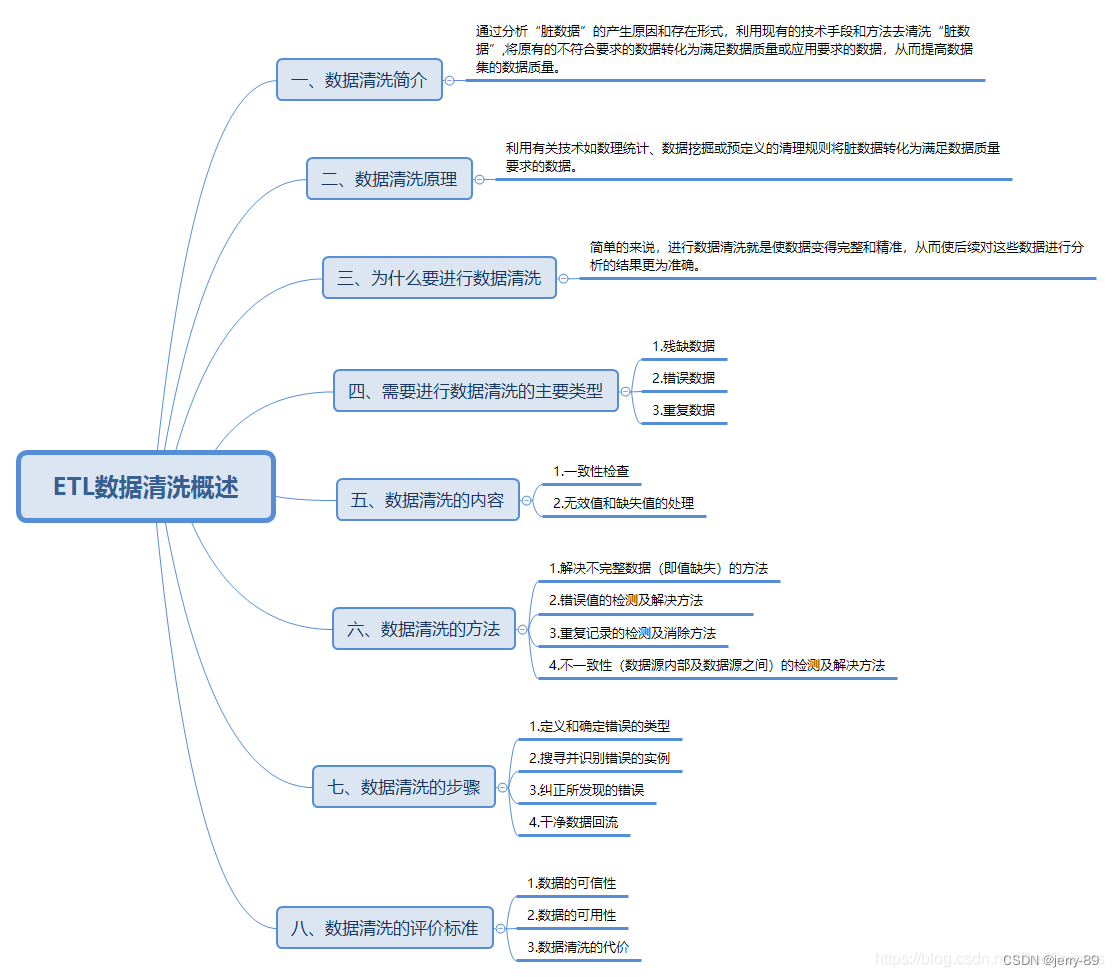
一、数据清洗简介
数据清洗(Data Cleaning)原理即通过分析“脏数据”的产生原因和存在形式,利用现有的技术手段和方法去清洗“脏数据”,将原有的不符合要求的数据转化为满足数据质量或应用要求的数据,从而提高数据集的数据质量。
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成 。
二、数据清洗原理
数据清洗原理:利用有关技术如数理统计、数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。
在这里插入图片描述
三、为什么要进行数据清洗
《纽约时报》将数据清洗称为看门人工作,并称数据科学家百分之八十的时间都花费在了这些清洗任务上。
不会真的有人因为没有见过人们聚众讨论看门人的工作多么有趣、多么酷而开始评头论足吧?说起来还真是惭愧,这工作没比做家务强到哪里去,但话又说回来,与其对它弃之不理、抱怨不断、恶语相加,还不如先把活儿干完,这能让我们过得更好些。
还不相信是吗?那让我们打个比方,你不是数据看门人,而是数据大厨。现在有人交给你一个购物篮,里面装满了你从未见过的各种各样的漂亮蔬菜,每一样都产自有机农场,并在最新鲜的时候经过人工精挑细选出来。多汁的西红柿,生脆的莴苣,油亮的胡椒。你一定激动地想马上开启烹饪之旅,可再看看周围,厨房里肮脏不堪,锅碗瓢盆上尽是油污,还沾着大块叫不出名的东西。至于厨具,只有一把锈迹斑斑的切刀和一块湿抹布。水槽也是破破烂烂的。而恰恰就在此时,你发现从看似鲜美的莴苣下面爬出了一只甲虫。
即使是实习厨师也不可能在这样的地方烹饪。往轻了说,无外乎是暴殄天物,浪费了一篮子精美的食材。如果严重点儿讲,这会使人致病。再说了,在这种地方烹饪根本毫无乐趣可言,也许全天的时间都得浪费在用生锈的破刀切菜上面。
与厨房道理一样,事先花费些时间清洗和准备好数据科学工作区、工具和原始数据,都是值得的。“错进,错出。”这句源于上20世纪60年代的计算机编程箴言,对如今的数据科学来说亦为真理。
简单的来说,进行数据清洗就是使数据变得完整和精准,从而使后续对这些数据进行分析的结果更为准确。
四、需要进行数据清洗的主要类型
1.残缺数据
这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
2.错误数据
这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
3.重复数据
对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
五、数据清洗的内容
1.一致性检查
一致性检查(consistency check)是根据每个变量的合理取值范围和相互关系,检查数据是否合乎要求,发现超出正常范围、逻辑上不合理或者相互矛盾的数据。例如,用1-7级量表测量的变量出现了0值,体重出现了负数,都应视为超出正常值域范围。SPSS、SAS、和Excel等计算机软件都能够根据定义的取值范围,自动识别每个超出范围的变量值。具有逻辑上不一致性的答案可能以多种形式出现:例如,许多调查对象说自己开车上班,又报告没有汽车;或者调查对象报告自己是某品牌的重度购买者和使用者,但同时又在熟悉程度量表上给了很低的分值。发现不一致时,要列出问卷序号、记录序号、变量名称、错误类别等,便于进一步核对和纠正
2.无效值和缺失值的处理
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
采用不同的处理方法可能对分析结果产生影响,尤其是当缺失值的出现并非随机且变量之间明显相关时。因此,在调查中应当尽量避免出现无效值和缺失值,保证数据的完整性。
六、数据清洗的方法
一般来说,数据清理是将数据库精简以除去重复记录,并使剩余部分转换成标准可接收格式的过程。数据清理标准模型是将数据输入到数据清理处理器,通过一系列步骤“ 清理”数据,然后以期望的格式输出清理过的数据。数据清理从数据的准确性、完整性、一致性、惟一性、适时性、有效性几个方面来处理数据的丢失值、越界值、不一致代码、重复数据等问题。
数据清理一般针对具体应用,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出相应的数据清理方法。
1.解决不完整数据(即值缺失)的方法
大多数情况下,缺失的值必须手工填入( 即手工清理)。当然,某些缺失值可以从本数据源或其它数据源推导出来,这就可以用平均值、最大值、最小值或更为复杂的概率估计代替缺失的值,从而达到清理的目的。
2.错误值的检测及解决方法
用统计分析的方法识别可能的错误值或异常值,如偏差分析、识别不遵守分布或回归方程的值,也可以用简单规则库( 常识性规则、业务特定规则等)检查数据值,或使用不同属性间的约束、外部的数据来检测和清理数据。
3.重复记录的检测及消除方法
数据库中属性值相同的记录被认为是重复记录,通过判断记录间的属性值是否相等来检测记录是否相等,相等的记录合并为一条记录(即合并/清除)。合并/清除是消重的基本方法。
4.不一致性(数据源内部及数据源之间)的检测及解决方法
从多数据源集成的数据可能有语义冲突,可定义完整性约束用于检测不一致性,也可通过分析数据发现联系,从而使得数据保持一致。目前开发的数据清理工具大致可分为三类。
数据迁移工具允许指定简单的转换规则,如:将字符串gender替换成sex。sex公司的PrismWarehouse是一个流行的工具,就属于这类。
数据清洗工具使用领域特有的知识( 如,邮政地址)对数据作清洗。它们通常采用语法分析和模糊匹配技术完成对多数据源数据的清理。某些工具可以指明源的“ 相对清洁程度”。工具Integrity和Trillum属于这一类。
数据审计工具可以通过扫描数据发现规律和联系。因此,这类工具可以看作是数据挖掘工具的变形。
七、数据清洗的步骤
1.定义和确定错误的类型
数据分析
数据分析是数据清洗的前提与基础,通过详尽的数据分析来检测数据中的错误或不
一致情况,除了手动检查数据或者数据样本之外,还可以使用分析程序来获得关于数据属性的元数据,从而发现数据集中存在的质量问题。
定义清洗转换规则
根据上一步进行数据分析得到的结果来定义清洗转换规则与工作流。根据数据源的个数,数据源中不一致数据和“脏数据”多少的程度,需要执行大量的数据转换和清洗步骤。
要尽可能的为模式相关的数据清洗和转换指定一种查询和匹配语言,从而使转换代码的自动生成变成可能。
2.搜寻并识别错误的实例
自动检测属性错误
检测数据集中的属性错误,需要花费大量的人力、物力和时间,而且这个过程本身很容易出错,所以需要利用高的方法自动检测数据集中的属性错误,方法主要有:基于统计的方法,聚类方法,关联规则的方法。
检测重复记录的算法
消除重复记录可以针对两个数据集或者一个合并后的数据集,首先需要检测出标识同一个现实实体的重复记录,即匹配过程。检测重复记录的算法主要有:基本的字段匹配算法,递归的字段匹配算法,Smith—Waterman算法,Cosine相似度函数
3.纠正所发现的错误
从自由格式的属性字段中抽取值(属性分离)
自由格式的属性一般包含着很多的信息,而这些信息有时候需要细化成多个属性,从而进一步支持后面重复记录的清洗
确认和改正
这一步骤处理输入和拼写错误,并尽可能地使其自动化。基于字典查询的拼写检查对于发现拼写错误是很有用的。
标准化
为了使记录实例匹配和合并变得更方便,应该把属性值转换成一个一致和统一的格式。
4.干净数据回流
当数据被清洗后,干净的数据应该替换数据源中原来的“脏数据”。这样可以提高原系统的数据质量,还可避免将来再次抽取数据后进行重复的清洗工作。
八、数据清洗的评价标准
1.数据的可信性
可信性包括精确性、完整性、一致性、有效性、唯一性等指标。
(1)精确性:描述数据是否与其对应的客观实体的特征相一致。
(2)完整性:描述数据是否存在缺失记录或缺失字段。
(3)一致性:描述同一实体的同一属性的值在不同的系统是否一致。
(4)有效性:描述数据是否满足用户定义的条件或在一定的域值范围内。
(5)唯一性:描述数据是否存在重复记录。
2.数据的可用性
数据的可用性考察指标主要包括时间性和稳定性。
(1)时间性:描述数据是当前数据还是历史数据。
(2)稳定性:描述数据是否是稳定的,是否在其有效期内。
3.数据清洗的代价
数据清洗的代价即成本效益,在进行数据清洗之前考虑成本效益这个因素是很必要的。因为数据清洗是一项十分繁重的工作,需要投入大量的时间、人力和物力。在进行数据清洗之前要考虑其物质和时间开销的大小,是否会超过组织的承受能力。通常情况下大数据集的数据清洗是一个系统性的工作,需要多方配合以及大量人员的参与,需要多种资源的支持。
企业所做出的每项决定目标都是为了给公司带来更大的经济效益,如果花费大量金钱、时间、人力和物力进行大规模的数据清洗之后,所能带来的效益远远低于所投入的,那么这样的数据清洗被认定为一次失败的数据清洗。故,在进行数据清洗之前进行成本效益的估算是非常重要的。