多模态的学习在最近几年异常火爆,除了普通的多模态学习,比如视觉问答,图文检索等,其实之前讲的所有这种Language Guided Detection,或者Language Guided Segmentation,这些任务都是多模态的,还有最近火的文本图像生成或者文本视频生成,我们耳熟能详的DALL·E2,Stable Diffusion、Phenaki Video、Imagen Video,以上这些统统属于多模态学习
这次的多模态串讲,可能更多的还是偏向传统的多模态学习,即下游任务是图文检索,即Image Text Retrieval、VQA【视觉问答】、Visual Reasoning【视觉推理】、Visual Entailment【视觉蕴含】,但即使如此,相关工作也是数不胜数。
串讲的第一部分讲一下只用Transformer Encoder的一些方法,比如说之前的ViLT、CLIP,还有我们今天讲解的ALBEF和VLMo。第二部分我们会讲解到用Transformer Encoder和Decoder一起的一些方法,比如说BLIP、CoCa、BEIT V3以及PaLI。
在讲解ALBEF之前,我们先简单回顾一下ViLT、CLIP。
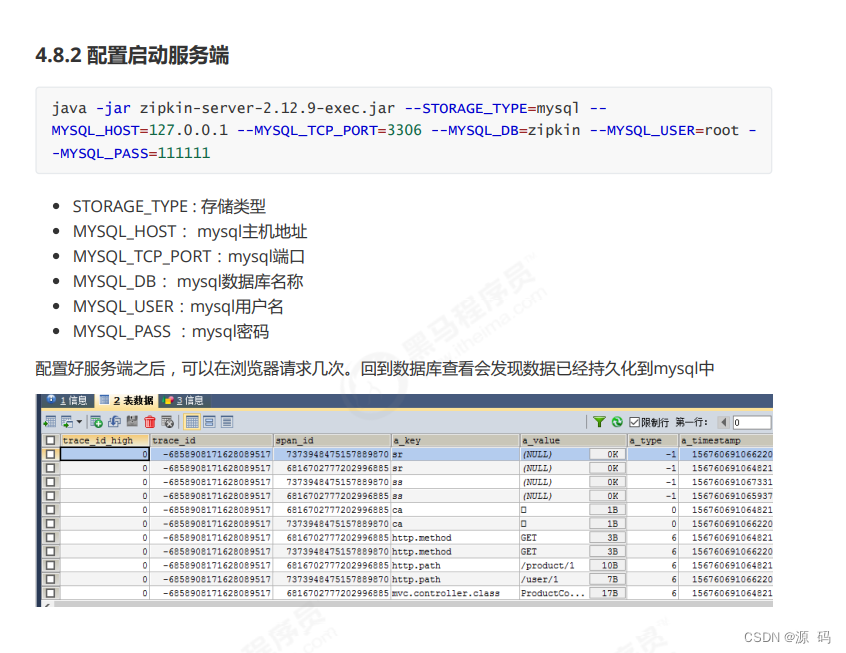
ViLT
以下图片来自ViLT论文的图二。

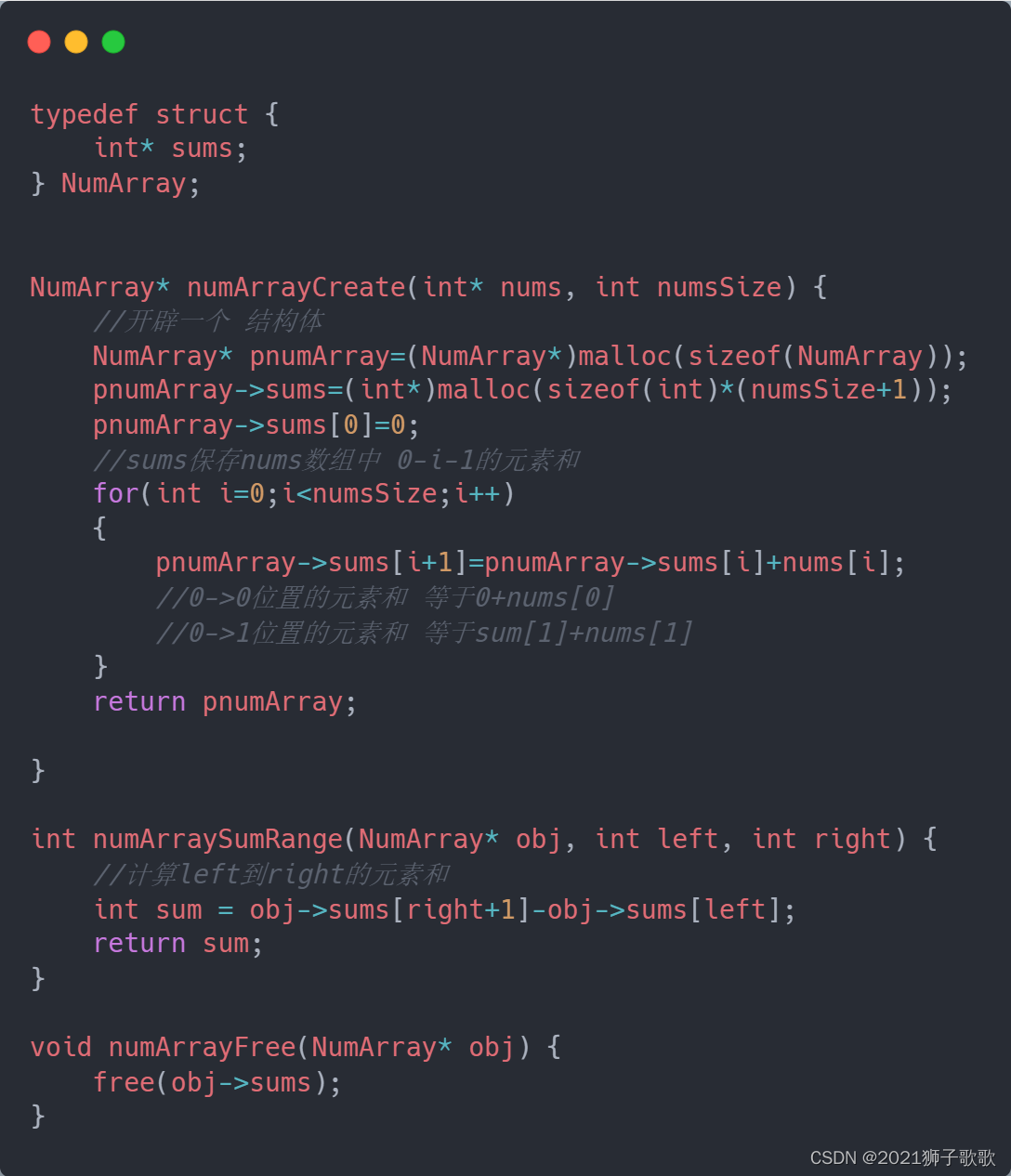
ViLT这篇论文的研究动机,其实就是为了把目标检测从视觉端拿掉,原因很简单,因为用一个预训练的目标检测器去抽取视觉特征的时候,其就会面临很多很多的局限性,但是直到Vision Transformer(21年之前)出现之前,很难有什么很好的办法能把这个预训练的目标检测器给移除掉,所以说最早期的工作,比如说分类(a)VSE或者VSE++的工作,他们的文本端就是直接抽一个文本特征,但是他们的视觉端就非常大,即需要的计算量非常的多,因为其是一个目标检测器,然后当得到了文本特征和视觉特征之后,最后只能做一个很简单的模态之间的交互,从而去做这种多模态的任务。后续这些工作,即分类(c)里的工作,即我们耳熟能详的OSCAR或者ViLBERT、UNITER,他们发现对于这种多模态 的任务来说,最后这个模态之间的交互非常重要的,只有有了模态之间更深层的交互,对于这种VQA、VR、VE这些任务来说,效果才会非常好,所以他们把最初的这种简单的点乘的,这种模态之间的交互,便变成了一个Transformer的Encoder,或者变成别的更复杂的模型结构,去做这种模态之间的交互,所以这些方法的性能都非常好,但是随之而来的缺点也非常明显,所有这一系列的工作,统统都用了这个预训练的目标检测器,再加上后边这个更大的模态融合的部分,这个模型不论是训练还是部署都非常困难,所以说当Vision Transformer出来之后,ViLT这篇论文也就应运而生了。
因为他们发现,在Vision Transformer里,这种基于Patch的视觉特征,其实跟之前这种基于Bounding Box的视觉特征也没什么太大区别,他也能很好的拿来做图片分类、目标检测的任务,这样,我们就把一个预训练好的目标检测器直接换成了一层的Patch Embedding,就能去抽取这个视觉的特征了,大大降低了计算复杂度, 尤其是在做推理的时候。
但是如果你的文本特征,直接简单的tokenize一下,视觉特征也只是简单的patch embedding一下,那肯定是远远不够的。所以对于多模态任务来说,这个后面的模态融合非常关键,所以ViLt就把之前(c)类里的这些方法,这个模态融合的方法直接借鉴了过来,用一个很大的Transformer encoder 去做模态融合从而达到了还不错的效果。
因为移除了预训练的目标检测器,换成了可以学习的Patch embedding layer,所以说ViLT模型极其简单,虽然作为一个多模态学习的框架,但是其实跟NLP那边的框架没有什么区别,无非就是先都tokenized了一下,然后直接扔给一个Transformer去学习,所以非常简单易学,但是ViLT也有它自己的缺点。首先,第一个缺点就是性能不够高,ViLT在很多任务上比不过(c)类里的这些方法。原因是对于现有的这些多模态任务而言,有可能是这些数据集的bias,也有可能是这个任务需要更多的视觉能力,总之,我们需要更强的视觉部分,即视觉模型应该要比文本模型要大,最后和这个效果才能好。但是在ViLT里,文本端用的tokenizer其实是很好的,但是visual embedding是random initialized,所以其效果自然就很差。其次,ViLT虽然说它的推理时间很快,但训练时间非常非常慢。在非常标准的一个4 million的set,ViLT需要64张GPU,而且是32G的,训练三天,所以它在训练上的复杂度和训练上的时间丝毫不亚于(c)类的方法。所以它是结构上简化了多模态学习,但没有真的让多模态学习所有人都玩得起。
基于以上两点,ALBEF呼之欲出。
CLIP
CLIP模型也是一个非常简单的结构,其是一个典型的双塔模型,即他有两个模型,一个对应文本,一个对应视觉。在训练的时候,通过对比学习,让已有的图像文本对在空间上拉得更近,让不是一个对的图像文本拉的更远,从而最后学到非常好的图像文本特征,然后一旦学到很好的图像文本特征之后,CLIP只需要做很简单的点乘,就可以去做多模态任务。尤其是对图像文本匹配,或者图像文本检索来说,CLIP简直是神一样的存在,它不光效果好,而且跟高效。
因为我们往往做图像文本匹配,或者图像文本检索任务的时候,我们是有一个很大的已有的数据库的,这个时候如果我们新来一张图片,或者新来一个文本,我们要跟已有的数据库去做匹配 ,那其他所有的方法,比如图上的(a)(c)(d)都会非常的慢,因为其所有的数据都要过一遍编码器,但是CLIP模型就不需要,它可以提前把数据库里所有的图像文本的特征提前都抽取好,并且是想什么时候抽取就什么时候抽取,抽取好放在那里即可,等我们真正想用的时候,直接做一个点乘就好,矩阵乘法还是相当快的。所以CLIP的这个实际应用非常广泛。
但是CLIP模型也有他的缺陷,他虽然对图文匹配的任务非常在行,但是对别的任务,比如VQA、VR、VE这些任务来说 ,性能就不够好了,因为毕竟只靠一个简单的点乘,还是不能够分析特别复杂的情况。
回顾到这里,我们来捋一下,总结一下之前的这些方法,哪些是好的,哪些是不好的。我们接下来该提出怎么样的改进呢?
首先我们来看模型的结构,因为我们有图像的输入和文本的输入,刚开始的模型很定是有两支的,因为它需要去抽取这个文本图像特征,但是我们一直强调,在多模态学习里,视觉特征要远远大于文本特征,所以我们知道使用更大更强的视觉模型,比如一个更大的ViT是好的,是我们需要坚持使用的。同时,作为多模态学习,模态之间的融合也是非常关键的,我们也要保证这个模态融合的模型,也要尽可能的大。
所以,我们大概知道,如果想做一个很好的多模态学习,其网络结构应该很像这个(c),即 文本编码器应该要比图像编码器要小,最后多模态融合部分尽可能的大。当然,这里的视觉模型很定不想要再用一个目标检测模型了,所以我们更多的是我们会采取一个比较的Vision Transformer,而不是简单的一个Patch embedding去做。
总之,模型大概就长以下这个样子。

模型有了,我们如何训练呢?
我们知道CLIP模型就用了一个对比学习的Loss,即Image Text Contrastive,即ITC LOSS训练,效果已经很好了。所以我们知道ITC训练不错还高效,我们应该采纳。
之前(c)类的这种方法,他们往往有目标检测,所以他们提出了一个叫做Word Patch Alignment,即文本的一个单词和这个图像的一个patch,应该有一个对应的关系,但是因为现在这个目标检测模型已经没有了,而且在ViLT里头,我们发现这个WPA Loss算起来是非常的慢的,所以才导致这个ViLT模型训练起来这么费劲,所以我们不太想使用WPA Loss了
剩下常用的还有两个Loss,一个是我们耳熟能详的Mask Language Modeling【即Bert的训练方式,遮住一个词然后再去预判这个词语(完形填空)】,这个loss肯定是非常有用,到现在为止,不光是NLP还是Vision ,基本都大一统的全部使用Mask Modeling。另外还有一个Image text Matching的Loss,在之前的(c)和(d)的这种方法之中,都取得了很好的结果,所以我们也想继续采纳。
所以我们发现,可能对于一个好的多模态学习的模型结构来说,我们的目标函数应该也就是ITC、ITM和MLM这三个的合体,最后效果应该不错。
ALBEF
现在我们来看ALBEF的这个模型结果,其实就会发现,我们通过总结做出来的这些预测,基本上都是正确的。比如从模型结构来说,在图像这边的编码器,其实就是一个12层的Transformer Base Model。
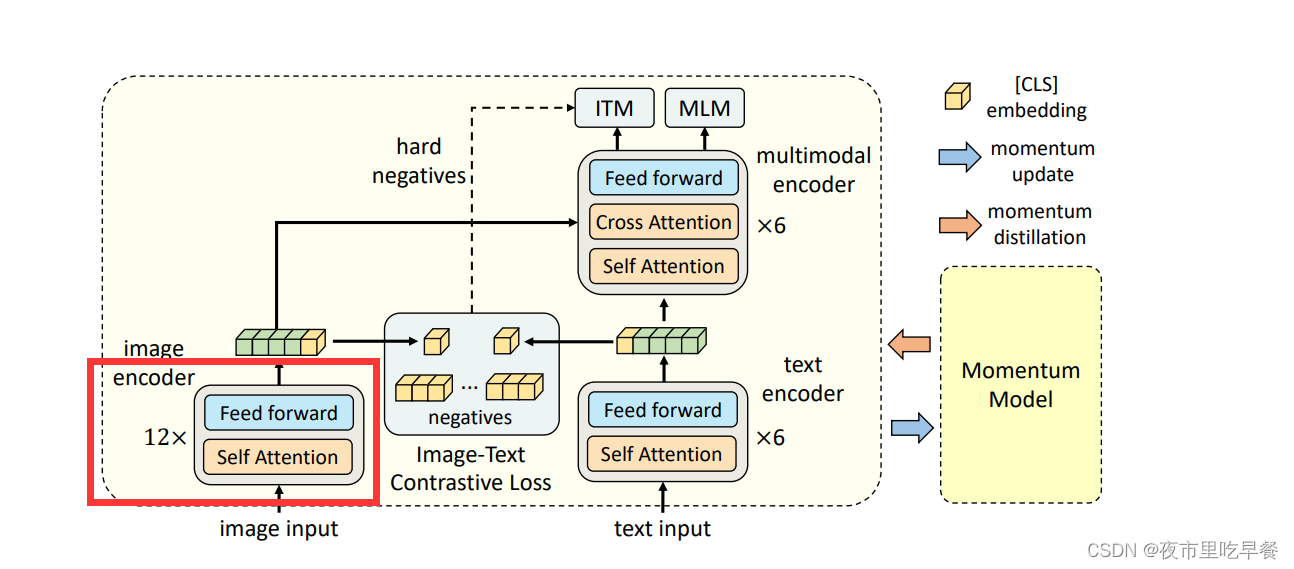
但是在文本这边,将一个12层的Bert Model,劈成了两个部分,前六层,拿来做文本的编码器,后六层做多模态融合的编码器。

满足我们刚刚所做的两个假设。第一个假设是整个图像编码器会比文本编码器要大,一边有12层的Transformer Block,另一边只有6层的Transformer Block。第二个是模态之间的融合也必须要大,所以这里面并不是一个简单的点乘,而是使用了6层的Transformer Block。
从目标函数来说,ALBEF就是用了这个Image Text Contrastive【ITC loss】和这个Image Text Matching和Mask Language Modeling,三个loss 的合体去训练这个模型。
之所以我们可以通过之前的一些对比和总结,得到接下来研究方向的一些假设,而且真的被一些后续的工作所验证,其实不是巧合,因为大部分工作的出发点 ,或者它的研究动机,其实就是在总结前人工作这个优缺点之中得到的,所以如果我们没有一些研究的idea,或者说我们不知道接下来研究方向该如何走的时候,还是需要去更相关的文献,并且不光是读这些文献,更重要的是做一个总结,每一篇论文我们都得到哪些insight,有什么东西是可取的,可以继续发扬光大,有什么东西不要,最好我们可以将其移除,通过这种不停地阅读、总结和对比。绝大多数便会给我们一个很明确的研究方向
ALBEF
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation

这个团队在做出ALBEF这论文之后,又相继作了BLIP、MUST,还有Video那边的ALPro一系列的多模态工作。
(1)摘要部分
最近图像文本的这种大规模的特征学习,已经变得非常火爆了,因为这个时候CLIP和Align这些工作都已经出来,基于CLIP的后续工作也出来很多。
大部分的方法都是用一个、、、、、、、
写到这里,突然发现自己有点不感冒,先挖个坑在这吧
【多模态论文串讲·上【论文精读】】 https://www.bilibili.com/video/BV1Vd4y1v77v/?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
以上是学习链接,感兴趣的小伙伴,自行查看哟!
有用的话,请多多给老师一键三连!