目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十、创建集群
1.创建集群
开始安装集群
(1)Get Started
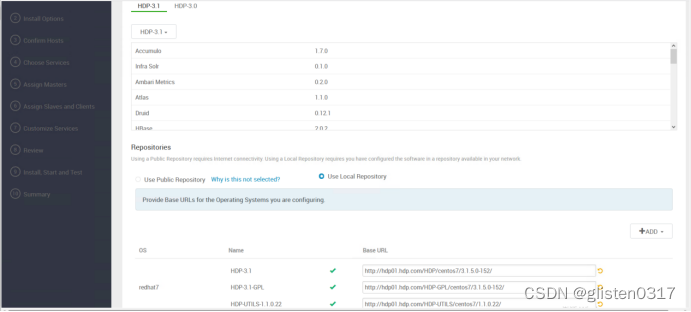
(2)Selected Version
选择使用本地镜像仓库安装(Use Local Repository),将其他os部分删除
HDP-3.1:http://hdp01.hdp.com/HDP/centos7/3.1.5.0-152/
HDP-3.1-GPL:http://hdp01.hdp.com/HDP-GPL/centos7/3.1.5.0-152/
HDP-UTILS-1.1.0.22:http://hdp01.hdp.com/HDP-UTILS/centos7/1.1.0.22/
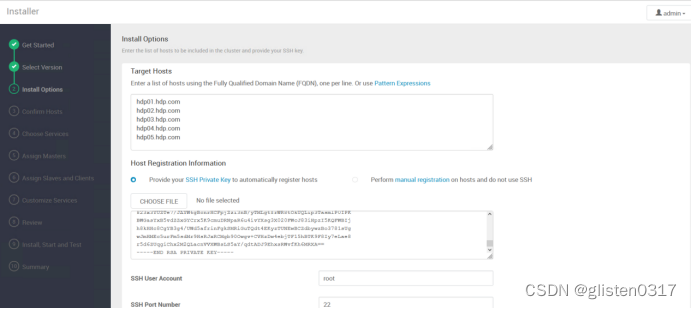
(3)Install Options
将hadoop集群中所有节点都加入(hdp01-05),并将hdp01的SSH私钥附上,查看私钥
hdp01.hdp.com
hdp02.hdp.com
hdp03.hdp.com
hdp04.hdp.com
hdp05.hdp.com
cat /root/.ssh/id_rsa
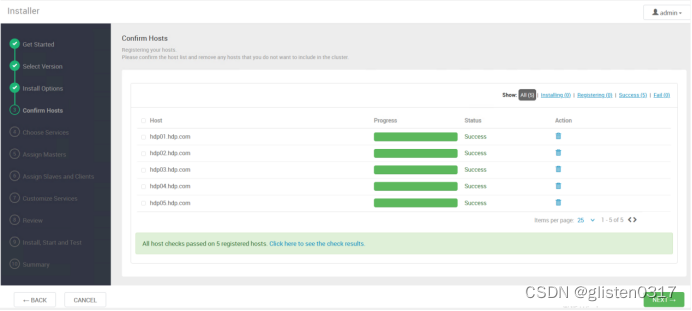
(4)Confirm Hosts
开始进入安装
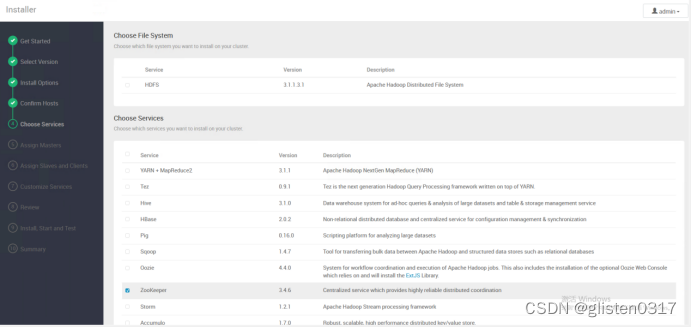
(5)Choose Services
仅安装最基础的ZooKeeper、Ambari Metrics和smartsense
smartsense是hortonworks一个商业的组件功能,作用是监控集群并提供建议,建议是不使用。通常,此组件是安装ambari的时候的一个必选项,也就是说在安装ambari的时候它就强制绑定安装了。后面可以删除。
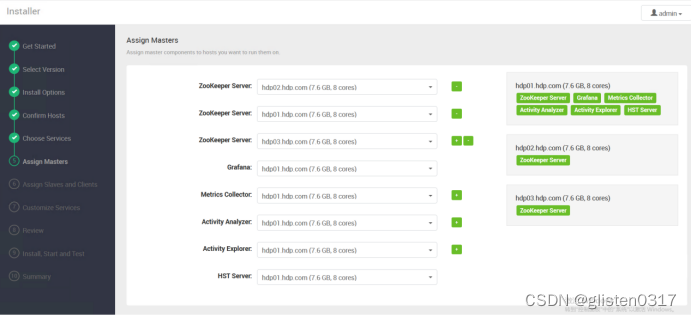
(6)Assign Masters
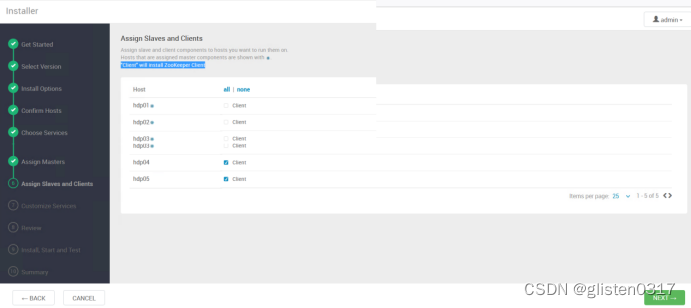
(7)Assign Slaves and Clients
按照指示,client为zookeeper的,选择在hdp04、hdp05上安装即可
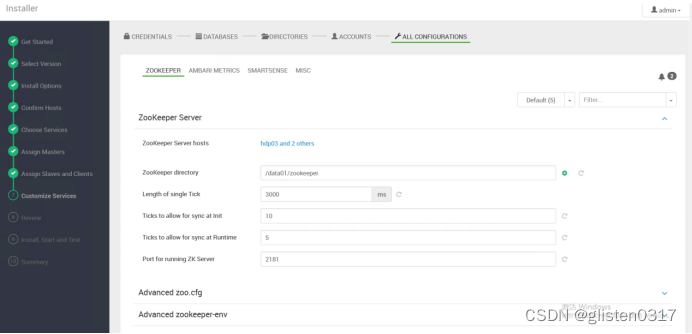
(8)Customize Services
密码设置为lnyd@LNsy115
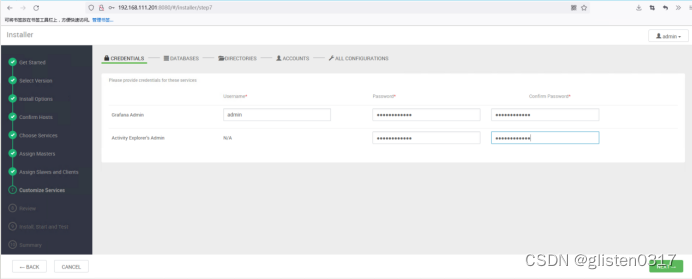
配置ZooKeeper路径
ZooKeeper directory:/data01/hadoop/zookeeper
ZooKeeper Log Dir:/var/log/zookeeper
ZooKeeper PID Dir:/var/run/zookeeper
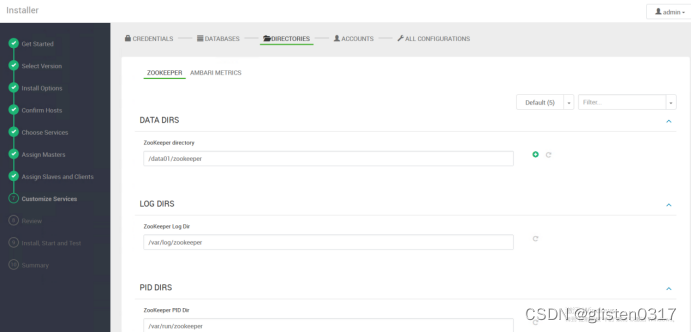
配置Ambari Metrics路径
Aggregator checkpoint directory:/var/lib/ambari-metrics-collector/checkpoint
Metrics Grafana data dir:/var/lib/ambari-metrics-grafana
HBase Local directory:${hbase.tmp.dir}/local
HBase root directory:file:///var/lib/ambari-metrics-collector/hbase
HBase tmp directory:/var/lib/ambari-metrics-collector/hbase-tmp
HBase ZooKeeper Property DataDir:${hbase.tmp.dir}/zookeeper
Phoenix Spool directory:${hbase.tmp.dir}/phoenix-spool
Phoenix Spool directory:/tmp
Metrics Collector log dir:/var/log/ambari-metrics-collector
Metrics Monitor log dir:/var/log/ambari-metrics-monitor
Metrics Grafana log dir:/var/log/ambari-metrics-grafana
HBase Log Dir Prefix:/var/log/ambari-metrics-collector
Metrics Collector pid dir:/var/run/ambari-metrics-collector
Metrics Monitor pid dir:/var/run/ambari-metrics-monitor
Metrics Grafana pid dir:/var/run/ambari-metrics-grafana
HBase PID Dir:/var/run/ambari-metrics-collector/
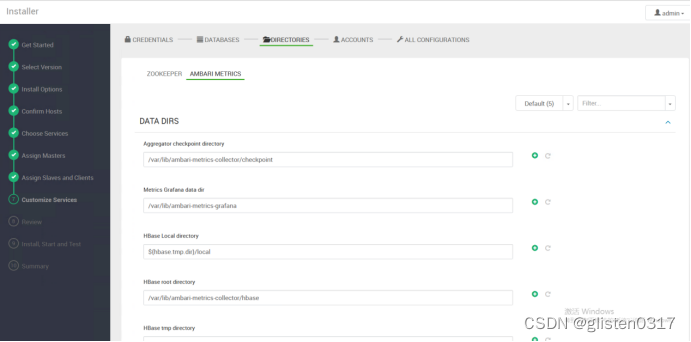
设置各个服务的账号
Smoke User:ambari-qa
Hadoop Group:hadoop
Ambari Metrics User:ams
ZooKeeper User:zookeeper
待安装服务的所有配置
SMARTSENSE中的smartsense.id需要指定,不能为unspecified,可设置为1000
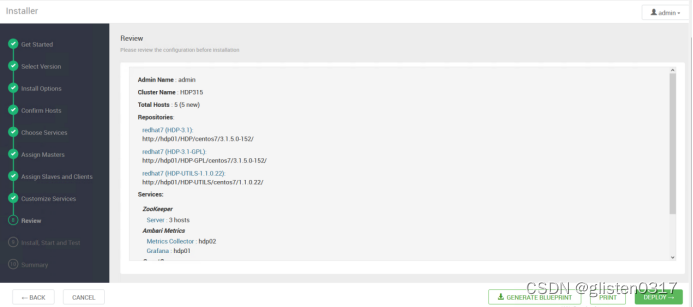
(9)Review
回顾之前的配置
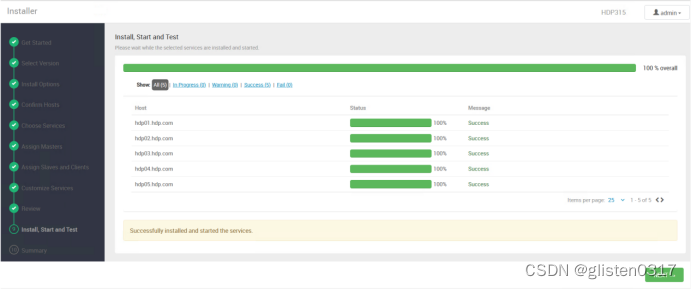
(10)Install, Start and Test
安装相关服务
(11)Summary
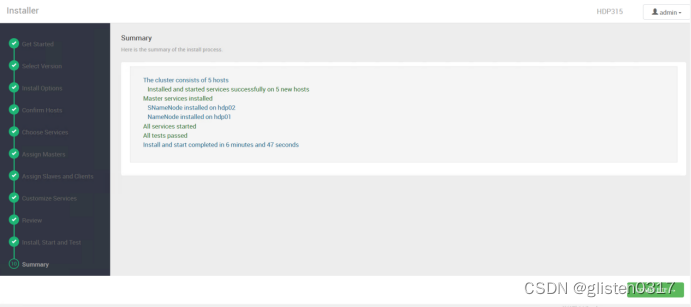
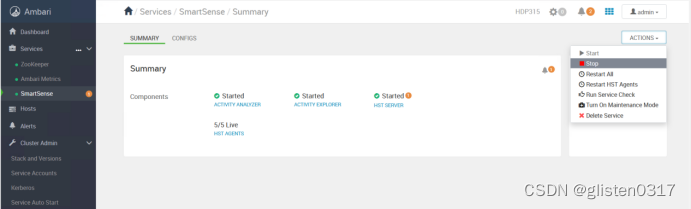
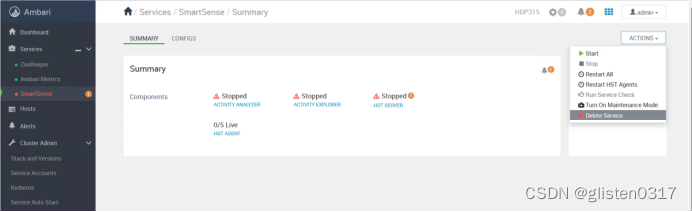
安装完成后,先stop然后delete掉SmartSense服务。
2.确认ZooKeeper配置
ZooKeeper的配置文件,/etc/zookeeper/conf/zoo.cfg
clientPort=2181
autopurge.purgeInterval=24
syncLimit=5
quorum.cnxn.threads.size=20
initLimit=10
dataDir=/data01/hadoop/zookeeper
tickTime=3000
autopurge.snapRetainCount=30
quorum.auth.enableSasl=false
server.1=hdp01.hdp.com:2888:3888
server.2=hdp02.hdp.com:2888:3888
server.3=hdp03.hdp.com:2888:3888
配置解析:
① clientPort:客户端连接端口
客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
② autopurge.purgeInterval:日志自动清理频率
指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
③ syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
④ quorum.cnxn.threads.size:设置可使用的最大线程池
⑤ initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
⑥ dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
⑦ tickTime:CS通信心跳时间
Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
⑧ autopurge.snapRetainCount:sanp保留数量
内存中的数据作为snapshot保存下来,该参数指定了需要保留多少个snapshot,之前的全删除。默认是保留3个。
⑨ quorum.auth.enableSasl:Sasl开关
⑩ server.A= B:C:D :服务器名称与地址
(服务器编号,服务器地址,LF 通信端口,选举端口)
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C表示的是这个服务器与集群中的Leader服务器交换信息的端口;
D表示的是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
3.常用指令
(1)服务端
- 查看leader、follower
/usr/hdp/3.1.5.0-152/zookeeper/bin/zkServer.sh status



在hdp01-03上分别查询可知,hdp03为leader,因为hdp03的myid最大
ansible nn,192.168.111.203 -m shell -a 'cat /data01/hadoop/zookeeper/myid'

(2)客户端
- 连接
zkCli.sh -server host:port
指定连接节点,默认host=localhost,port=2181
/usr/hdp/3.1.5.0-152/zookeeper/bin/zkCli.sh -server hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181
- znode节点操作
ls path [watch]
列出znode的子节点,同时可以设置一个监听器
ls /node1
create [-s] [-e] path data acl
创建一个znode节点,同时设置节点权限acl,-s表示创建有序节点,-e创建临时节点
znode需要按照层级去创建,如创建/node1/node2,需要先创建/node1,再创建/node1/node2
create /node1 test1
create /node1/node2 test2
ls2 path [watch]
列出znode的子节点,同时可以设置一个监听器,如:ls2 /,与ls的区别是ls2还可以获取到子节点个数等等状态信息
ls2 /node1
get path [watch]
获取znode节点的数据,同时可以注册一个监听器,如:get /mynode
get /node1
get /node1/node2
stat path [watch]
查看znode状态,如数据长度,时间戳等等,同时可以注册一个监听器
stat /node1
stat /node1/node2
set path data [version]
设置znode的数据,同时可以设置一个监听器,如:set /mynode “hello world”
set /node1 test3
设置完成后,mZxid(数据节点最后一次更新时的事务ID)会发生变化


delete path [version]
删除znode节点,注意路径为绝对路径,且不可删除拥有子节点的znode
delete /node1/node2/node3

rmr path
递归删除znode节点,与delete的区别是可以删除拥有子节点的znode
rmr /node1

- ACL权限控制
Zookeeper的acl权限由[scheme : id :permissions]三部分组成,其中scheme是认证类型,id一般指的是账号,也就是权限所针对的对象,permissions表示对节点的空权限类型
Scheme可选项:
world:默认模式,所有客户端都拥有指定的权限。world下只有一个id选项,就是anyone,通常组合写法为world:anyone:[permissons];比如:setAcl /mynode world:anyone:crwda
auth:只有经过认证的用户才拥有指定的权限。通常组合写法为auth:user:password:[permissons],使用这种模式时,你需要先进行登录,之后采用auth模式设置权限时,user和password都将使用登录的用户名和密码;比如:setAcl /mynode auth:feng:123456:crwda
digest:只有经过认证的用户才拥有指定的权限。通常组合写法为digest:user:BASE64(SHA1(password)):[permissons],这种形式下的密码必须通过SHA1和BASE64进行双重加密;比如:setAcl /mynode digest:feng:xHBaNtDKjaz0G0F0dq11735c9r8=:crwda
ip:限制只有特定IP的客户端才拥有指定的权限。通常组成写法为ip:182.168.0.168:[permissions];比如:setAcl /mynode ip:192.168.28.213:crwda
super:代表超级管理员,拥有所有的权限,需要修改Zookeeper启动脚本进行配置。
Permissions可选项,在使用时,可以使用首字母进行简写(crwda,Creat/Read/Write/Delete/Admin):
CREATE:允许创建子节点;
READ:允许从节点获取数据并列出其子节点;
WRITE:允许为节点设置数据;
DELETE:允许删除子节点;
ADMIN:允许为节点设置权限。
setAcl path acl
给已有节点赋予权限,其中acl是权限
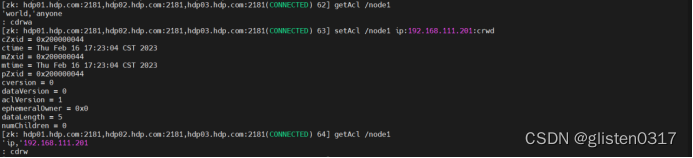
setAcl /node1 ip:192.168.111.201:crwd
getAcl path
查看节点的权限
getAcl /node1
- 其他命令操作
history
查看当前会话中使用过的命令,每个命令会携带一个编号
redo cmdno
重新执行命令,cmdno是命令编号,可以使用history查看
printwatches [on|off]
是否输出watch事件,如果使用on或者off则表示设置
sync path
会强制客户端所连接的服务器状态与leader的状态同步,这样在读取path的值就是最新的值了
quit
直接退出当前的zkCli命令行
close
关闭连接,但不会退出当前zkCli命令行
4.常见错误
(1)ambari-metrics-collector重启后失败
查看日志/var/log/ambari-metrics-collector/ambari-metrics-collector.log
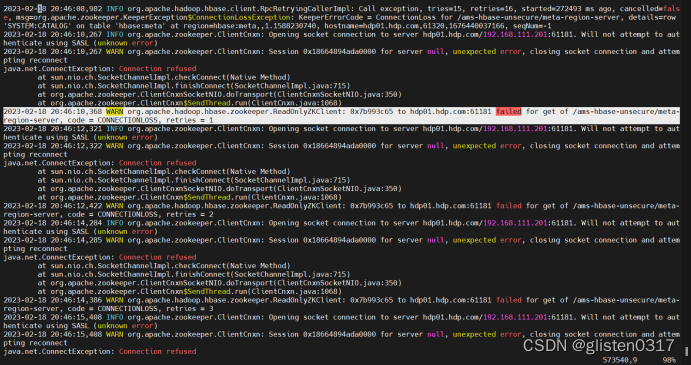
需要把/var/lib/ambari-metrics-collector/下的checkpoint、hbase和hbase-tmp删除,如需要也可以先备份,然后在重新启动metrics-collector服务
rm -rf /var/lib/ambari-metrics-collector/*
(2)Ambari-agent注册失败
报错信息
Internal Exception: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry \'hdp04.hdp.com\' for key \'UQ_hosts_host_name\'\
Error Code: 1062\
Call: INSERT INTO hosts (host_id, cpu_count, cpu_info, discovery_status, host_attributes, host_name, ipv4, ipv6, last_registration_time, os_arch, os_info, os_type, ph_cpu_count, public_host_name, rack_info, total_mem) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\
\\tbind => [16 parameters bound]\
确认错误原因为在MySQL中的hosts表中INSERT数据时主键的值已经存在导致,登录到ambari的MySQL数据库中,首先关闭外键约束,然后删除对应的记录,再打开外键约束,
use ambari;
select host_name from hosts;
SET FOREIGN_KEY_CHECKS=0;
delete from hosts where host_name = 'hdp04.hdp.com';
select host_name from hosts;
SET FOREIGN_KEY_CHECKS=1;

重启ambari-server服务,并重新注册即可恢复
ambari-server restart