归纳编程学习的感悟,
记录奋斗路上的点滴,
希望能帮到一样刻苦的你!
如有不足欢迎指正!
共同学习交流!
🌎欢迎各位→点赞 👍+ 收藏⭐ + 留言📝
一个人不是在逆境中成长,就是在逆境中消亡!
一起加油!

目录
一、前言:
二、构造函数:
💦属性为类中的公有成员,可以直接在类外进行赋初始值的操作,示例代码如下所示:
💦属性为类中的私有或保护成员,利用公有成员函数间接赋初值,部分代码如下:
💦使用构造函数来实现初始化:
☘️在学生类中添加构造函数,定义对象时自动调用构造函数完成数据成员的初始化。
🔑说明:
三、析构函数:
💦例 :在Student中定义构造函数以及析构函数。
🔑说明:
💦例:析构函数及构造函数重载,注意构造函数的调用顺序问题。
🔑说明:
☘️关于析构函数的特点,总结如下:
四、复制构造函数——“克隆”技术 :
💦默认复制构造函数
例:调用默认的复制构造函数,用已有对象初始化新建对象。
🔑说明:
💦深复制与浅复制:
例:调用默认的复制构造函数,完成对对象的浅复制。
🔑说明:
例:定义复制构造函数,完成深复制。
⚡注意:
☘️复制构造函数的特点总结如下:
五、总结:
六、共勉:
一、前言:
除了根据类的需要设计一些成员函数之外,在每个类中都存在几个特殊的成员函数,即使不定义,系统也会自动生成。
构造函数与析构函数在每个类中都存在,如果程序员在设计类时没有定义构造函数与析构函数,系统会自动为类生成一个默认的构造函数和析构函数。
二、构造函数:
类描述了一类对象的共同特征,而对象是类定义的变量即类的一个实例。声明一个变量后我们必须对它进行初始化,否则它的里面是一个随机数,当用类定义了对象以后,同样需要对对象进行初始化,对对象进行初始化实际上是给对象的属性赋值,即对许多数据成员进行初始化,只有属性初始化以后的对象才是有意义的。
与一般变量初始化只需一条赋值语句就能完成不同,对象初始化一般需要若干条赋值语句
或调用若干个公有成员函数才能完成。
对象的属性初始化,一般可以采用以下几种方法。
💦属性为类中的公有成员,可以直接在类外进行赋初始值的操作,示例代码如下所示:
#include<iostream> #include<string> using namespace std; struct Student{ int ID; string name; string sex; int age; }; int main(){ Student stu; stu.ID=20230011; stu.name="张三"; stu.sex="男"; stu.age=18; return 0; }出于封装和保护的目的,类中的属性部分的数据成员都会设成私有或保护的属性,所以这种初始化的方式一般很少用到。
💦属性为类中的私有或保护成员,利用公有成员函数间接赋初值,部分代码如下:
#include<iostream> #include<string> using namespace std; struct Student{ private: int ID; string name; string sex; int age; public: void input(int pID,string pname,string psex,int age); void output(); }; ……//此处省略input和output成员函数的实现 int main(){ Student stu; stu.input(20230011,"张三","男",18);//调用公有函数input完成初始化 stu.output(); return 0; }每个类的设计者可能都会按照自己的习惯设计一个用来初始化数据成员的函数,如果每个类都有自己特定的初始化方法,用户在使用时就不方便。由于类定义对象后,都需要进行初始化,设计者可以设计统一的接口来完成初始化。就如同每个电器需要接通电源才能使用,电源的接口必然是统一的,否则使用起来非常不方便。这个统一的接口就是将对象初始化的工作统一交给类的构造函数来完成。
💦使用构造函数来实现初始化:
构造函数比较特殊,每个类里面都有一个构造函数,如果程序员自己没有定义,那么系统会给类生成一个默认的构造函数,程序员不需要在类中显式地调用构造函数,当定义对象时,系统会自动地调用构造函数。
定义对象时系统会自动调用构造函数,把对象成员的初始化代码放在构造函数里是十分合适的。系统自动生成的默认构造函数是空的,所以要让构造函数能够完成初始化的功能,类的设计者必须自己定义类的构造函数。
构造函数的定义格式如下:
<类名>::<类名>(<参数表>)
{<函数体>
}
构造函数也是类的成员函数,具有一般成员函数的特性,同时构造函数还具有一些特殊的性质:
构造函数的函数名与类名相同;构造函数不需要返回值,构造函数是特殊的成员函数,不可以返回任意值;
构造函数是类的公有成员,在定义对象时由编译系统自动调用,其他时候都无法调用它因此构造函数只能一次性的影响对象成员的初值,就如同人出生以后一次性获得一些初始属性一样。
☘️在学生类中添加构造函数,定义对象时自动调用构造函数完成数据成员的初始化。
#include<iostream> #include<string> using namespace std; class Student{ private: int ID; string name; string sex; int age; public: Student(int pID,string pname,string psex,int page); void print(); }; Student::Student(int pID,string pname,string psex,int page){ ID=pID; name=pname; sex=psex; age=page; } void Student::print(){ cout<<"ID:"<<ID<<"\nname:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<endl; } int main(){ Student stu(20230011,"张三","男",18); stu.print(); return 0; }🔑说明:
构造函数并不是简单地替代了原来的 input 函数,两者有以下本质上的区别:
⭐普通的成员函数 input 名称只需要满足标识符的命名规范,而类的构造函数名称必须与类名相同,且不指定返回值类型;
⭐input 函数必须由程序员显示调用,而构造函数则是由编译系统自动调用;
⭐input 函数可以在程序任何地方多次调用,构造函数仅在定义对象时被调用一次;
⭐对于某个类而言,input 函数可有可无,但每个类都必须有一个构造函数,如果
象时自动调用构造丽数完成数报程序员没有定义构造函数,系统会生成一个默认的构造函数。
三、析构函数:
构造函数是在对象“出生”时由编译系统自动调用进行对象的初始化工作,析构函数则是在对象即将“死亡”一一生存期即将结束时由编译系统自动调用完成一些清理工作。
析构函数的定义格式如下:
<类名>:: ~<类名>(){
<函数体>
}
析构函数也是类的公有成员函数,函数名与类名相同。为了与构造函数区别开,函数名前面加一个“~”。它也不指定函数返回值类型,析构函数与构造函数不同,它的形参表中没有任何参数,因此不能重载。
每个类都有一个默认的析构函数,但是默认的析构函数几乎没有任何功能。如果需要对对象进行清理,程序员需要定义自己的析构函数完成特定的清理工作。通常当类的构造函数中涉及申请空间的一些操作时,需要定义析构函数完成相应空间的释放操作。
💦例 :在Student中定义构造函数以及析构函数。
#include<iostream>
#include<cstring>
using namespace std;
class Student{
protected:
int ID;
char *name;
char sex;
int age;
public:
Student(int pID,char *pname,char sex,int age);
void print();
~Student();
};
Student::Student(int pID,char *pname,char psex,int page){
ID=pID;
name=new char[strlen(pname)+1];
strcpy(name,pname);
sex=psex;
age=page;
}
void Student::print(){
cout<<"ID:"<<ID<<"\nName:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<endl;
}
Student::~Student(){
delete []name;
}
int main(){
Student std(20230011,"Li Hui",'F',18);
std.print();
}🔑说明:
当类定义对象时,系统为每个对象分配一些存储空间用来存放数据成员;例如,当Student 类定义对象std 时,系统为对象 std分配空间如图A所示。
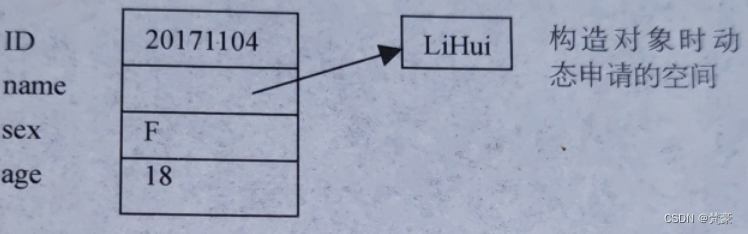
图A std 对象存储空间示意图 如果不显示定义析构函数,系统会自动生成默认的析构函数。默认的析构函数没有任何功能,对象std 生存期结束后,std 对象的空间会自动归还给系统。但是,构造对象时申请用来存放字符串的额外空间则没有被回收,就会造成内存的“泄漏”;因此,如果在构造函数中为对象申请了额外的空间,一定要在析构函数中释放此空间。
💦例:析构函数及构造函数重载,注意构造函数的调用顺序问题。
#include<iostream>
#include<cstring>
using namespace std;
class Student{
private:
char *ID;//需要动态申请空间存放ID
char *name;//需要动态申请空间存放name
char sex;
int age;
float score;
public:
Student();
Student(char *pID,char *pname,char psex,int page,float pscore);
void changeID(char *pID);
void changeName(char *pname);
void changesex(char psex){
sex=psex;
}
void changeage(int page){
age=page;
}
void changescore(float s){
score=s;
}
void print();
~Student();
};
Student::Student(){
ID=new char[10];
strcpy(ID,"00000000");
name=new char[10];
strcpy(name,"******");
sex=' ';
age=0;
score=0;
}
Student::Student(char *pID,char *pname,char psex,int page,float pscore){
ID=new char[strlen(pID)+1];
strcpy(ID,pID);
name=new char[strlen(pname)+1];
strcpy(name,pname);
age=page;
sex=psex;
score=pscore;
}
void Student::changeID(char *pID){
delete [] ID;
ID=new char[strlen(pID)+1];
strcpy(ID,pID);
}
void Student::changeName(char *pname){
delete [] ID;
name=new char[strlen(pname)+1];
strcpy(name,pname);
}
void Student::print(){
cout<<"ID:"<<ID<<"\nName:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<"\nscore"<<score<<endl;
}
Student::~Student(){
cout<<"Destructor called.Name:"<<name<<endl;
delete [] name;
delete [] ID;
}
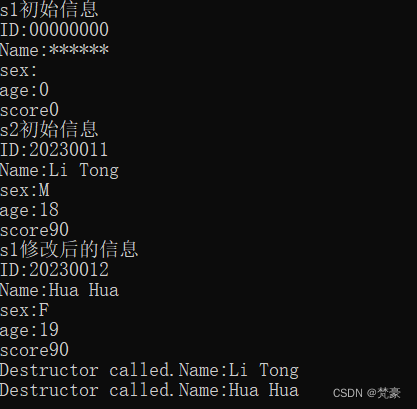
int main(){
Student s1;
Student s2("20230011","Li Tong",'M',18,90);
cout<<"s1初始信息"<<endl;
s1.print();
cout<<"s2初始信息"<<endl;
s2.print();
s1.changeID("20230012");
s1.changeName("Hua Hua");
s1.changeage(19);
s1.changescore(90);
s1.changesex('F');
cout<<"s1修改后的信息"<<endl;
s1.print();
return 0;
}
🔑说明:
该类中声明了两个构造函数,一个带参数,一个没有参数。在构造对象时,根据是否给定参数决定调用哪一个构造函数。在执行 main 函数中的最后一条语句后,对象生存期结束,编译系统自动调用析构函数,执行完析构函数,系统收回对象所占用的内存。从运行结果看,上例中先调用析构函数析构对象 s2,再调用析构函数析构对象s1。
☘️关于析构函数的特点,总结如下:
- ✨析构函数是成员函数,函数体可以写在类中,也可以写在类外;
- ✨析构函数的函数名与类名相同,并在前面加“~”字符,用来与构造函数进行区分,析构函数不指定返回值类型;
- ✨析构函数没有参数,因此不能重载,一个类中只能定义一个析构函数;
- ✨每个类都必须有一个析构函数,若类中没有显式定义析构函数,则编译系统自动生成一个默认形式的析构函数,作为该类的公有成员;
- ✨析构函数在对象生存期结束前由编译系统自动调用,表现为两种情况:1.如果一个对象被定义在另一个函数体内,但这个函数结束时;2当一个对象是通过 new 运算符动态创建的,当使用 delete 运算符释放它时。
四、复制构造函数——“克隆”技术 :
如果我们要使用已有的对象来初始化一个新的对象,可以使用 C++中的“克隆技术”克隆技术”可以方便地建立一个属性和已有对象完全一样的新对象。在 C++使用复制构造函数可以完成从已有对象到新建对象的“克隆”过程。复制构造函数本质上也是构造函数,和构造函数有很多相同点,也是在定义一个新的对象时由编译系统自动调用完成新建对象的初始化工作。
💦默认复制构造函数
如果没有定义复制构造函数,则编译系统会自动生成一个默认的复制构造函数
例:调用默认的复制构造函数,用已有对象初始化新建对象。
#include<iostream>
#include<cstring>
using namespace std;
class Student{
protected:
int ID;
char *name;
char sex;
int age;
public:
Student(int pID,char *pname,char sex,int age);
void print();
~Student();
};
Student::Student(int pID,char *pname,char psex,int page){
ID=pID;
strcpy(name,pname);
sex=psex;
age=page;
}
void Student::print(){
cout<<"ID:"<<ID<<"\nName:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<endl;
}
Student::~Student(){ }
int main(){
Student std1(20230011,"Li Hui",'F',18);
Student std2(std1);//使用默认复制构造函数完成std2对象的初始化
std1.print();
std2.print();
}🔑说明:
新建对象 std2 是用已有对象 std1 作为参数进行初始化的,此时 std2的初始化工作由系统默认生成的复制构造函数完成,默认复制构造函数的功能是把已知对象的每个数据成员的值依次赋值到新定义的对象对应成员中,不做其他处理。
复制构造函数的原型声明如下所示:
<类名>(const <类名>& <obj>);
复制构造函数的函数名和类名相同,形参必须是本类对象的常引用
💦深复制与浅复制:
系统自动生成的默认的复制构造函数只能完成对象成员之间的简单赋值,无法进行其他处理。一般情况下无需显式地定义复制构造函数,使用系统默认的复制构造也能完成用已知对象初始化新定义对象的操作,但有时使用系统默认的复制构造函数运行可能会产生严重问题。
例:调用默认的复制构造函数,完成对对象的浅复制。
#include<iostream>
#include<cstring>
using namespace std;
class Student{
protected:
int ID;
char *name;
char sex;
int age;
public:
Student(int pID,char *pname,char sex,int age);
void print();
~Student();
};
Student::Student(int pID,char *pname,char psex,int page){
ID=pID;
name=new char[strlen(pname)+1];
strcpy(name,pname);
sex=psex;
age=page;
}
void Student::print(){
cout<<"ID:"<<ID<<"\nName:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<endl;
}
Student::~Student(){
delete [] name;
}
int main(){
Student std1(20230011,"Li Hui",'F',18);
Student std2(std1);//使用默认复制构造函数完成std2对象的初始化
std1.print();
std2.print();
}🔑说明:
编译成功,运行程序,结果能够正常显示,但是在一些编译环境下,最后出现“内存访问错误”的提示。出现错误提示的原因在哪里呢?在创建对象 std2 时,调用了系统默认的复制构造函数,如图(a)所示,默认的复制构造函数将 std 成员的值依次赋给 std2 中的成员,导致 std2 对象中的指针变量name 和 std1 对象中的指针变量name 指向同一存储空间。当一个对象的生存期结束而调用析构函数释放内存空间后,另一个对象中的指针变量悬空。当再次访问它时(调用析构函数释放其指向的空间 )出现了内存访问错误,如图(b)所示。
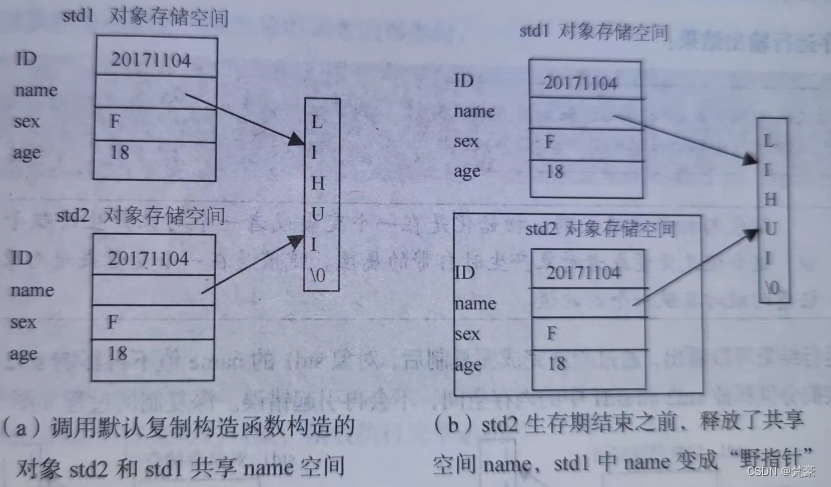
当一个类有指针成员(可能会拥有资源,如堆内存 ),这时使用默认的复制构造函数,可能会出现两个对象拥有同一个资源的情况,当对象析构时,一个资源会经历两次释放,因此程序会出错。
默认的复制构造函数只实现了成员之间数值的“浅复制”,并没有复制资源,如果不存在资源冲突,程序就能够正常运行。
如果存在资源问题,必须显示定义复制构造函数,则在显示定义的复制构造函数体中不仅要复制成员,还要复制资源。这种显示定义的复制构造函数要完成“深复制”工作。
这里资源都是指堆资源,不仅仅是堆资源,当类中涉及需要打开文件、占有硬件设备服务等也需要深复制。简单来说,如果类需要析构函数来释放资源时,则类也需要显式定义一个复制构造函数实现深复制。
例:定义复制构造函数,完成深复制。
#include<iostream>
#include<cstring>
using namespace std;
class Student{
protected:
int ID;
char *name;
char sex;
int age;
public:
Student(const Student& s);
Student(int pID,char *pname,char sex,int age);
void print();
~Student();
};
Student::Student(const Student& s){
ID=s.ID;
name=new char[strlen(s.name)+1];
strcpy(name,s.name);
sex=s.sex;
age=s.age;
}
Student::Student(int pID,char *pname,char psex,int page){
ID=pID;
name=new char[strlen(pname)+1];
strcpy(name,pname);
sex=psex;
age=page;
}
void Student::print(){
cout<<"ID:"<<ID<<"\nName:"<<name<<"\nsex:"<<sex<<"\nage:"<<age<<endl;
}
Student::~Student(){
delete [] name;
}
int main(){
Student std1(20230011,"Li Hui",'F',18);
Student std2(std1);//使用默认复制构造函数完成std2对象的初始化
std1.print();
std2.print();
}⚡注意:
赋值与初始化的区别。初始化是在一个变量或者一个对象产生时赋予的一个初始值,这个值是变量或者对象产生时自带的属性。赋值是在一个变量或者对象产生之后的任意时刻对其赋一个新的值。
从运行结果可以看出,通过程序完成深复制后,对象 std1的 name 值不再影响 std2 的 name值程序结束前分别释放 std2 和 std1 中的内存空间,不会再引起错误。深复制的过程如图B所示
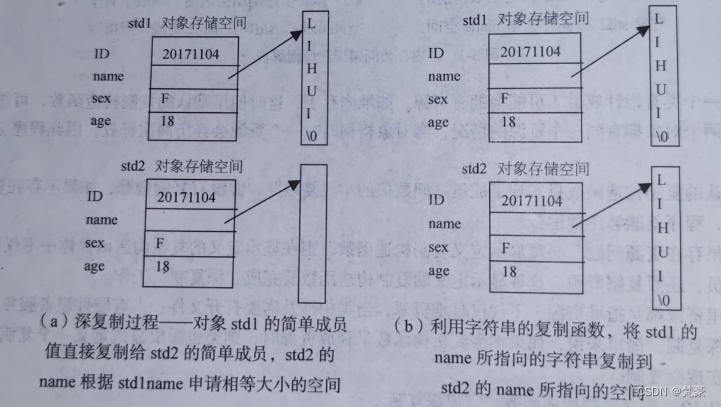
☘️复制构造函数的特点总结如下:
- ✨复制构造函数本质上也是构造函数,所以函数名与类名相同,不指定返回值类型,也是在对象初始化的时候被编译系统自动调用,复制构造函数的形参只有一个,并且是本类对象的常引用。
- ✨每个类都必须有一个复制构造函数,如果类中没有显示定义复制构造函数,则编译系统生成一个默认的复制构造函数,默认复制构造函数只能实现对象之间的浅复制。
- ✨复制构造函数在以下三种情况下由编译系统自动调用。
//(1)用已有的对象初始化一个新定义的对象时 int main(){ Student std1(20230011,"Li Hui",'F',18); Student std2(std1); std1.print(); std2.print(); } //(2)当对象作为函数的实参传递给函数的形参时 void f(Student std){ std.print(); } int main(){ Student std1(20230011,"Li Hui",'F',18); f(std1); } //(3)当函数的的返回值是类的对象,函数执行完毕返回时 Student f(){ Student std1(20230011,"Li Hui",'F',18); return std1; } int main(){ Student std=f(); std.print(); }
五、总结:
- ✨声明一个变量后我们必须对它进行初始化,否则它的里面是一个随机数
- ✨要让构造函数能够完成初始化的功能,类的设计者必须自己定义类的构造函数。
-
✨构造函数的函数名与类名相同;
-
✨构造函数不需要返回值,构造函数是特殊的成员函数,不可以返回任意值;
-
✨构造函数是类的公有成员
- ✨析构函数是成员函数,函数体可以写在类中,也可以写在类外;
- ✨析构函数的函数名与类名相同,并在前面加“~”字符,用来与构造函数进行区分,析构函数不指定返回值类型;
- ✨析构函数没有参数,因此不能重载,一个类中只能定义一个析构函数;
- ✨每个类都必须有一个析构函数,若类中没有显式定义析构函数,则编译系统自动生成一个默认形式的析构函数,作为该类的公有成员;
- ✨析构函数在对象生存期结束前由编译系统自动调用,表现为两种情况:1.如果一个对象被定义在另一个函数体内,但这个函数结束时;2当一个对象是通过 new 运算符动态创建的,当使用 delete 运算符释放它时。
- ✨复制构造函数本质上也是构造函数,所以函数名与类名相同,不指定返回值类型,也是在对象初始化的时候被编译系统自动调用,复制构造函数的形参只有一个,并且是本类对象的常引用。
- ✨每个类都必须有一个复制构造函数,如果类中没有显示定义复制构造函数,则编译系统生成一个默认的复制构造函数,默认复制构造函数只能实现对象之间的浅复制。
六、共勉:
以上就是我对类和对象——(4)特殊的成员函数的理解,希望本篇文章对你有所帮助,也希望可以支持支持博主,后续博主也会定期更新学习记录,记录学习过程中的点点滴滴。如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对类和对象的理解,请持续关注我哦!!!


![[ffmpeg] aac 音频编码](https://img-blog.csdnimg.cn/direct/1f2114f23baa4ce5960f70d0fef7f610.png)