YOLO系列目标检测算法目录 - 文章链接
- YOLO系列目标检测算法总结对比- 文章链接
- YOLOv1- 文章链接
- YOLOv2- 文章链接
- YOLOv3- 文章链接
- YOLOv4- 文章链接
- Scaled-YOLOv4- 文章链接
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
- PP-YOLO- 文章链接
- PP-YOLOv2- 文章链接
- YOLOR- 文章链接
- YOLOS- 文章链接
- YOLOX- 文章链接
- PP-YOLOE- 文章链接
本文总结:
- 本文借鉴YOLOX的成功方法,在PP-YOLOv2的基础上进行了优化,使用了anchor-free模式、更强大的backbone和neck结构,配备了CSPRepResStage、ET-head和动态标签分配算法TAL等等;
- PP-YOLOE避免使用可变形卷积和Matrix NMS等操作,以支持更好的部署在各种硬件上。
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
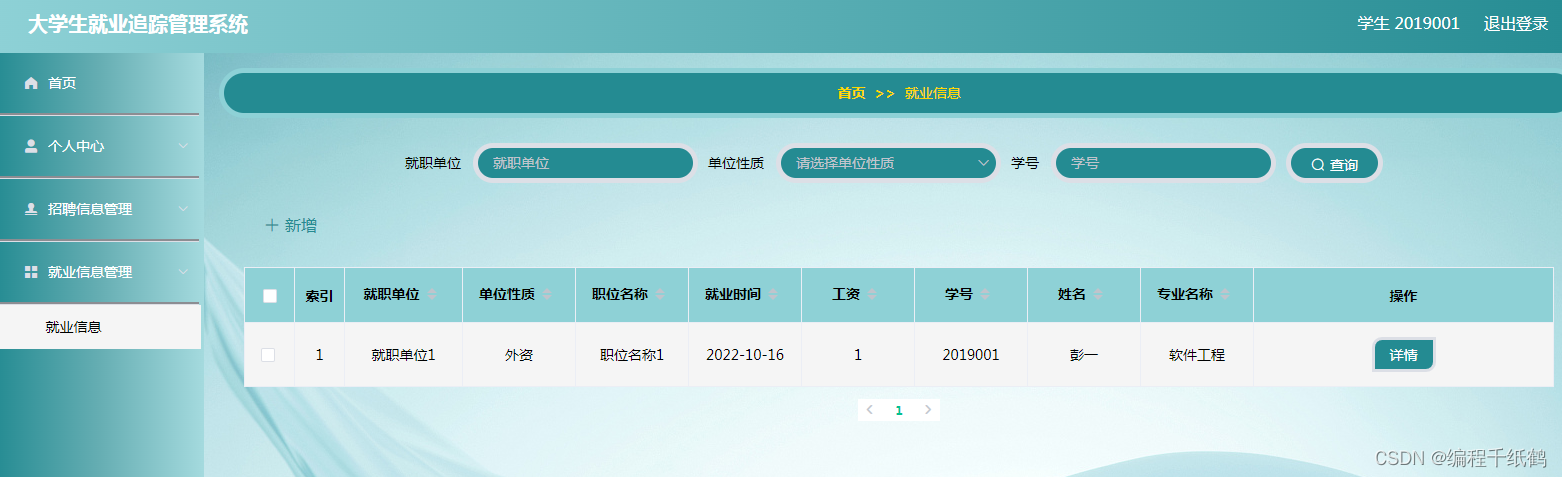
- 1. PP-YOLOv2回顾
- 2 PP-YOLOE的改进
- 2.1 Anchor-free
- 2.2 Backbone和Neck
- 2.3 Task Alignment Learning (TAL)
- 2.4 Efficient Task-aligned Head (ET-head)
- 3. 结论
1. PP-YOLOv2回顾
PP-YOLOv2的主要功能点包含:
- Backbone:带有可变性卷积的ResNet50-vd
- Neck:带有SPP layer和DropBlock的PAN
- Head:轻量级的IoU aware head
- ReLU激活函数用于backbone中,Mish激活函数用于neck
- 和YOLOv3保持一致,PP-YOLOv2仅为每个GT目标分配一个anchor
- 除了分类loss、回归loss和objectness loss之外,PP-YOLOv2还使用IoU loss和IoU aware loss来提高性能
- 更多细节参考文章PP-YOLOv2
2 PP-YOLOE的改进
2.1 Anchor-free
PP-YOLOv2中使用的使anchor-based的模式,这种模式引入了许多参数,且在不同数据集上需要进行不同的手工配置,扩展到其他数据集很复杂,所以在PP-YOLOE中将其改为anchor-free模式。
参考FCOS(在每个像素上平铺一个锚点)之后,本文为三个检测head设置上限和下限,以将GT分配给相应的特征图。然后,计算边界框的中心以选择最近的像素作为正样本。参考YOLO系列,预测4D向量(x,y,w,h)用于回归,实验结果如表2所示,该修改使模型速度稍快,但损失了0.3AP。尽管根据PP-YOLOv2的锚点大小仔细设置了上限和下限,但基于锚点的方式和无锚点的方式之间的分配结果仍存在一些细微的不一致,这可能会导致精度下降。

2.2 Backbone和Neck

通过结合残差连接和dense连接,提出了一种新的RepResBlock,用于backbone和neck。
参考TreeBlock,RepResBlock在训练阶段如图3(b)所示,推理阶段如图3(c)所示。
首先简化了TreeBlock(如图3(a)),然后将串联操作替换为元素加法操作,因为RMNet在某种程度上显示了这两种操作的结果相近,因此,在推断阶段,将RepResBlock重参数化为ResNet-34以RepVGG样式使用的基本残差块。
使用RepResBlock构建backbone和neck。与ResNet类似,backbone命名为CSPRepResNet——包含一个stem由三个卷积层和由RepResBlock堆叠的四个后续阶段组成,如图3(d)所示。在每个阶段,使用跨阶段部分连接,以避免大量3×
3个卷积层。ESE((Effective Squeeze and Extraction)层还用于在构建backbone时在每个CSPRepResStage中施加通道attention。
在PP-YOLOv2之后,使用RepResBlock和CSPRepResStage构建neck,与backbone不同,RepResBlock中的快捷方式和CSPRepResStage中的ESE层在neck中被删除。
像YOLOv5一样,本文使用宽度系数α和深度系数β来缩放基本backbone和neck。因此,可以得到一系列具有不同参数和计算成本的检测网络。backbone的宽度设置为[64、128、256、512、1024],backbon的深度设置为[3,6,6,3],neck的宽度设置和深度设置分别为[192、384、768]和3。表1显示了不同模型的宽度乘数α和深度乘数β的规格。如表2所示,此类修改可提高0.7%的AP性能–49.5%的AP

2.3 Task Alignment Learning (TAL)
YOLOX中使用SimOTA作为标签分配策略,以提高性能。然而,为了进一步克服分类和定位的失准,TOOD中提出了任务对齐学习(TAL),它由动态标签分配和任务对齐loss组成。动态标签分配意味着预测/损失感知。根据预测,它为每个GT实况分配动态数量的正锚。通过明确对齐两个任务,TAL可以同时获得最高的分类分数和最精确的边界框。
对于任务对齐loss,TOOD使用标准化的t,即t^来替换丢失的目标,它采用每个实例中最大的IoU作为标准化。分类的Binary Cross Entropy(BCE)可以改写为:

本文使用不同的标签分配策略来研究性能,在上述修改的模型上进行了这个实验,该模型使用CSPRepResNet作为backbone。如表3所示,TAL实现了最好的45.2%AP性能。使用TAL替代FCOS风格的标签分配,并得到了0.9%的AP改善(50.4%的AP),如表2所示。

2.4 Efficient Task-aligned Head (ET-head)

3. 结论
本文对PPYOLOv2进行了一些更新,包括可扩展的backbone-neck架构、高效的任务对齐head、高级标签分配策略和精确的目标损失函数,这一切的改进形成了PP-YOLOE。同时,提出了s/m/l/x模型,这些模型可以涵盖实际中的不同场景。