目录
- 1. 语言模型
- 1.1 语言模型的计算
- 1.2 n n n元语法的定义
- 2. 循环神经网络RNN
- 2.1 不含隐藏状态的神经网络
- 2.2 含隐藏状态的循环神经网络
- 2.3 应用:基于字符级循环神经网络的语言模型
- 3. 总结
1. 语言模型
语言模型(language model)是自然语言处理的重要技术。在自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为 T T T的文本中的词依次为 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1,w2,…,wT,那么在离散的时间序列中, w t w_t wt( 1 ≤ t ≤ T 1 \leq t \leq T 1≤t≤T)可看作在时间步(time step) t t t的输出或标签。给定一个长度为 T T T的词的序列 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1,w2,…,wT,语言模型将计算该序列的概率:
P ( w 1 , w 2 , … , w T ) . P(w_1, w_2, \ldots, w_T). P(w1,w2,…,wT).
1.1 语言模型的计算
假设序列 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1,w2,…,wT中的每个词是依次生成的,我们有
P ( w 1 , w 2 , … , w T ) = ∏ t = 1 T P ( w t ∣ w 1 , … , w t − 1 ) . P(w_1, w_2, \ldots, w_T) = \prod_{t=1}^T P(w_t \mid w_1, \ldots, w_{t-1}). P(w1,w2,…,wT)=t=1∏TP(wt∣w1,…,wt−1).
例如,一段含有4个词的文本序列的概率
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) . P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3). P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).
因此,为了计算语言模型,我们需要计算词的概率,以及一个词在给定前几个词的情况下的条件概率,即语言模型参数。词的概率可以通过该词在训练数据集中的相对词频来计算。例如, P ( w 1 ) P(w_1) P(w1)可以计算为 w 1 w_1 w1在训练数据集中的词频(词出现的次数)与训练数据集的总词数之比。因此,根据条件概率定义,一个词在给定前几个词的情况下的条件概率也可以通过训练数据集中的相对词频计算。例如, P ( w 2 ∣ w 1 ) P(w_2 \mid w_1) P(w2∣w1)可以计算为 w 1 , w 2 w_1, w_2 w1,w2两词相邻的频率与 w 1 w_1 w1词频的比值,因为该比值即 P ( w 1 , w 2 ) P(w_1, w_2) P(w1,w2)与 P ( w 1 ) P(w_1) P(w1)之比;而 P ( w 3 ∣ w 1 , w 2 ) P(w_3 \mid w_1, w_2) P(w3∣w1,w2)同理可以计算为 w 1 w_1 w1、 w 2 w_2 w2和 w 3 w_3 w3三词相邻的频率与 w 1 w_1 w1和 w 2 w_2 w2两词相邻的频率的比值。以此类推。
1.2 n n n元语法的定义
当序列长度增加时,计算和存储多个词共同出现的概率复杂度会呈指数级增加。 n n n元语法通过马尔可夫假设(虽然并不一定成立)简化了语言模型的计算。马尔可夫假设是指一个词的出现只与前面 n n n个词相关,即 n n n阶马尔可夫链(Markov chain of order n n n)。如果 n = 1 n=1 n=1,那么有 P ( w 3 ∣ w 1 , w 2 ) = P ( w 3 ∣ w 2 ) P(w_3 \mid w_1, w_2) = P(w_3 \mid w_2) P(w3∣w1,w2)=P(w3∣w2)。如果基于 n − 1 n-1 n−1阶马尔可夫链,我们可以将语言模型改写为
P ( w 1 , w 2 , … , w T ) ≈ ∏ t = 1 T P ( w t ∣ w t − ( n − 1 ) , … , w t − 1 ) . P(w_1, w_2, \ldots, w_T) \approx \prod_{t=1}^T P(w_t \mid w_{t-(n-1)}, \ldots, w_{t-1}) . P(w1,w2,…,wT)≈t=1∏TP(wt∣wt−(n−1),…,wt−1).
以上也叫 n n n元语法( n n n-grams)。它是基于 n − 1 n - 1 n−1阶马尔可夫链的概率语言模型。当 n n n分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列 w 1 , w 2 , w 3 , w 4 w_1, w_2, w_3, w_4 w1,w2,w3,w4在一元语法、二元语法和三元语法中的概率分别为
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ) P ( w 3 ) P ( w 4 ) , P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 2 ) P ( w 4 ∣ w 3 ) , P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 2 , w 3 ) . \begin{aligned} P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2) P(w_3) P(w_4) ,\\ P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_2) P(w_4 \mid w_3) ,\\ P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_2, w_3) . \end{aligned} P(w1,w2,w3,w4)P(w1,w2,w3,w4)P(w1,w2,w3,w4)=P(w1)P(w2)P(w3)P(w4),=P(w1)P(w2∣w1)P(w3∣w2)P(w4∣w3),=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w2,w3).
当 n n n较小时, n n n元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当 n n n较大时, n n n元语法需要计算并存储大量的词频和多词相邻频率。
如何在语言模型中更好地平衡以上这两点呢?后续内容会继续探究这一问题。
2. 循环神经网络RNN
上面介绍的 n n n元语法中,时间步 t t t的词 w t w_t wt基于前面所有词的条件概率只考虑了最近时间步的 n − 1 n-1 n−1个词。如果要考虑比 t − ( n − 1 ) t-(n-1) t−(n−1)更早时间步的词对 w t w_t wt的可能影响,我们需要增大 n n n。但这样模型参数的数量将随之呈指数级增长。
本节将介绍循环神经网络,它并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。
2.1 不含隐藏状态的神经网络
让我们考虑一个含单隐藏层的多层感知机。给定样本数为 n n n、输入个数(特征数或特征向量维度)为 d d d的小批量数据样本 X ∈ R n × d \boldsymbol{X} \in \mathbb{R}^{n \times d} X∈Rn×d。设隐藏层的激活函数为 ϕ \phi ϕ,那么隐藏层的输出 H ∈ R n × h \boldsymbol{H} \in \mathbb{R}^{n \times h} H∈Rn×h计算为
H = ϕ ( X W x h + b h ) , \boldsymbol{H} = \phi(\boldsymbol{X} \boldsymbol{W}_{xh} + \boldsymbol{b}_h), H=ϕ(XWxh+bh),
其中隐藏层权重参数 W x h ∈ R d × h \boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h,隐藏层偏差参数 b h ∈ R 1 × h \boldsymbol{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h, h h h为隐藏层单元个数。上式相加的两项形状不同,因此将按照广播机制相加。把隐藏变量 H \boldsymbol{H} H作为输出层的输入,且设输出个数为 q q q(如分类问题中的类别数),输出层的输出为
O = H W h q + b q , \boldsymbol{O} = \boldsymbol{H} \boldsymbol{W}_{hq} + \boldsymbol{b}_q, O=HWhq+bq,
其中输出变量 O ∈ R n × q \boldsymbol{O} \in \mathbb{R}^{n \times q} O∈Rn×q, 输出层权重参数 W h q ∈ R h × q \boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q, 输出层偏差参数 b q ∈ R 1 × q \boldsymbol{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q。如果是分类问题,我们可以使用 softmax ( O ) \text{softmax}(\boldsymbol{O}) softmax(O)来计算输出类别的概率分布。
2.2 含隐藏状态的循环神经网络
现在我们考虑输入数据存在时间相关性的情况。假设 X t ∈ R n × d \boldsymbol{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d是序列中时间步 t t t的小批量输入, H t ∈ R n × h \boldsymbol{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h是该时间步的隐藏变量。与多层感知机不同的是,这里我们保存上一时间步的隐藏变量 H t − 1 \boldsymbol{H}_{t-1} Ht−1,并引入一个新的权重参数 W h h ∈ R h × h \boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h,该参数用来描述在当前时间步如何使用上一时间步的隐藏变量。具体来说,时间步 t t t的隐藏变量的计算由当前时间步的输入和上一时间步的隐藏变量共同决定:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) . \boldsymbol{H}_t = \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh} + \boldsymbol{b}_h). Ht=ϕ(XtWxh+Ht−1Whh+bh).
与多层感知机相比,我们在这里添加了 H t − 1 W h h \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh} Ht−1Whh一项。由上式中相邻时间步的隐藏变量 H t \boldsymbol{H}_t Ht和 H t − 1 \boldsymbol{H}_{t-1} Ht−1之间的关系可知,这里的隐藏变量能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。因此,该隐藏变量也称为隐藏状态。由于隐藏状态在当前时间步的定义使用了上一时间步的隐藏状态,上式的计算是循环的,使用循环计算的网络即循环神经网络(recurrent neural network)。
循环神经网络有很多种不同的构造方法。若无特别说明,循环神经网络均基于上式中隐藏状态的循环计算。在时间步 t t t,输出层的输出和多层感知机中的计算类似:
O t = H t W h q + b q . \boldsymbol{O}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_q. Ot=HtWhq+bq.
循环神经网络的参数包括隐藏层的权重 W x h ∈ R d × h \boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h、 W h h ∈ R h × h \boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h和偏差 b h ∈ R 1 × h \boldsymbol{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及输出层的权重 W h q ∈ R h × q \boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q和偏差 b q ∈ R 1 × q \boldsymbol{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q。
注意:即便在不同时间步,循环神经网络也始终使用这些模型参数。因此,循环神经网络模型参数的数量不随时间步的增加而增长。
下图展示了循环神经网络在3个相邻时间步的计算逻辑。在时间步 t t t,隐藏状态的计算可以看成是将输入 X t \boldsymbol{X}_t Xt和前一时间步隐藏状态 H t − 1 \boldsymbol{H}_{t-1} Ht−1连结后输入一个激活函数为 ϕ \phi ϕ的全连接层。该全连接层的输出就是当前时间步的隐藏状态 H t \boldsymbol{H}_t Ht,且模型参数为 W x h \boldsymbol{W}_{xh} Wxh与 W h h \boldsymbol{W}_{hh} Whh的连结,偏差为 b h \boldsymbol{b}_h bh。当前时间步 t t t的隐藏状态 H t \boldsymbol{H}_t Ht将参与下一个时间步 t + 1 t+1 t+1的隐藏状态 H t + 1 \boldsymbol{H}_{t+1} Ht+1的计算,并输入到当前时间步的全连接输出层。
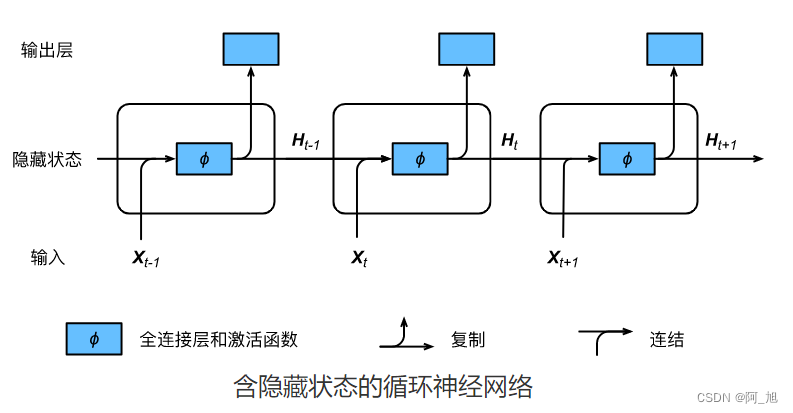
我们刚刚提到,隐藏状态中
X
t
W
x
h
+
H
t
−
1
W
h
h
\boldsymbol{X}_t \boldsymbol{W}_{xh} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh}
XtWxh+Ht−1Whh的计算等价于
X
t
\boldsymbol{X}_t
Xt与
H
t
−
1
\boldsymbol{H}_{t-1}
Ht−1连结后的矩阵乘以
W
x
h
\boldsymbol{W}_{xh}
Wxh与
W
h
h
\boldsymbol{W}_{hh}
Whh连结后的矩阵。接下来,我们用一个具体的例子来验证这一点。首先,我们构造矩阵X、W_xh、H和W_hh,它们的形状分别为(3, 1)、(1, 4)、(3, 4)和(4, 4)。将X与W_xh、H与W_hh分别相乘,再把两个乘法运算的结果相加,得到形状为(3, 4)的矩阵。
import torch
X, W_xh = torch.randn(3, 1), torch.randn(1, 4)
H, W_hh = torch.randn(3, 4), torch.randn(4, 4)
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
输出:
tensor([[ 5.2633, -3.2288, 0.6037, -1.3321],
[ 9.4012, -6.7830, 1.0630, -0.1809],
[ 7.0355, -2.2361, 0.7469, -3.4667]])
将矩阵X和H按列(维度1)连结,连结后的矩阵形状为(3, 5)。可见,连结后矩阵在维度1的长度为矩阵X和H在维度1的长度之和(
1
+
4
1+4
1+4)。然后,将矩阵W_xh和W_hh按行(维度0)连结,连结后的矩阵形状为(5, 4)。最后将两个连结后的矩阵相乘,得到与上面代码输出相同的形状为(3, 4)的矩阵。
torch.matmul(torch.cat((X, H), dim=1), torch.cat((W_xh, W_hh), dim=0))
输出:
tensor([[ 5.2633, -3.2288, 0.6037, -1.3321],
[ 9.4012, -6.7830, 1.0630, -0.1809],
[ 7.0355, -2.2361, 0.7469, -3.4667]])
2.3 应用:基于字符级循环神经网络的语言模型
最后我们介绍如何应用循环神经网络来构建一个语言模型。设小批量中样本数为1,文本序列为“想”“要”“有”“直”“升”“机”。下图演示了如何使用循环神经网络基于当前和过去的字符来预测下一个字符。在训练时,我们对每个时间步的输出层输出使用softmax运算,然后使用交叉熵损失函数来计算它与标签的误差。在图中,由于隐藏层中隐藏状态的循环计算,时间步3的输出 O 3 \boldsymbol{O}_3 O3取决于文本序列“想”“要”“有”。 由于训练数据中该序列的下一个词为“直”,时间步3的损失将取决于该时间步基于序列“想”“要”“有”生成下一个词的概率分布与该时间步的标签“直”。
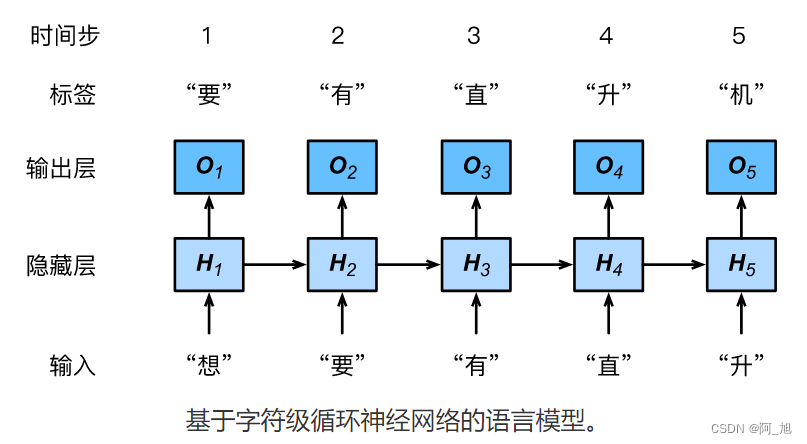
因为每个输入词是一个字符,因此这个模型被称为字符级循环神经网络(character-level recurrent neural network)。因为不同字符的个数远小于不同词的个数(对于英文尤其如此),所以字符级循环神经网络的计算通常更加简单。
3. 总结
- 使用循环计算的网络即循环神经网络。
- 循环神经网络的隐藏状态可以捕捉截至当前时间步的序列的历史信息。
- 循环神经网络模型参数的数量不随时间步的增加而增长。
- 可以基于字符级循环神经网络来创建语言模型。
如果文章内容对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,可获取更多干货内容~欢迎共同学习交流