我们都知道在MergeTree中数据是按列存储的,但是具体到存储的细节、以及如何工作的,都存在很多疑问。数据存储,就好比一本书中的文字,在排版时,绝不会密密麻麻地把文字堆满,这样会导致难以阅读。更为优雅的做法是,将文字按段落的形式精心组织,使其错落有致。本节将介绍MergeTree在数据存储方面的细节,尤其是其中关于压缩数据块的概念。
列式存储
对于 OLAP 技术来说,一般都是这对大量行少量列做聚合分析,所以列式存储技术基本可以说是 OLAP 必用的技术方案。列式存储相比于行式存储,列式存储在分析场景下有着许多优良的特性。
- 分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也 要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询;
- 同一列中的数据属于同一类型,压缩效果显著,压缩比高。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本;
- 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短;
- 自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法;
- 高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
在MergeTree中,数据按列存储,而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。也正是这些.bin文件,最终承载着数据的物理存储。数据文件以分区目录的形式被组织存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据。而对应到存储的具体实现方面,MergeTree也并不是一股脑地将数据直接写入.bin文件,而是经过了一番精心设计:首先,数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用LZ4算法;其次,数据会事先依照ORDER BY的声明排序;最后,数据是以压缩数据块的形式被组织并写入.bin文件中的。
存储块
一个压缩数据块由头信息和压缩数据两部分组成,头信息固定使用 9 位字节表示,具体由 1 个 UInt8(1 字节)和 2 个 UInt32(4 字节)组成,分别代表使用的压缩算法类型、压缩后的数据大小、压缩前的数据大小。所以虽然存储的是压缩后的数据,但是在头信息中将压缩前的数据大小也记录了下来,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BCuVhvjv-1672192516907)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227135049630.png)]](https://img-blog.csdnimg.cn/3bba0265505b459ea6fa8bcaa8eb3fc8.png)
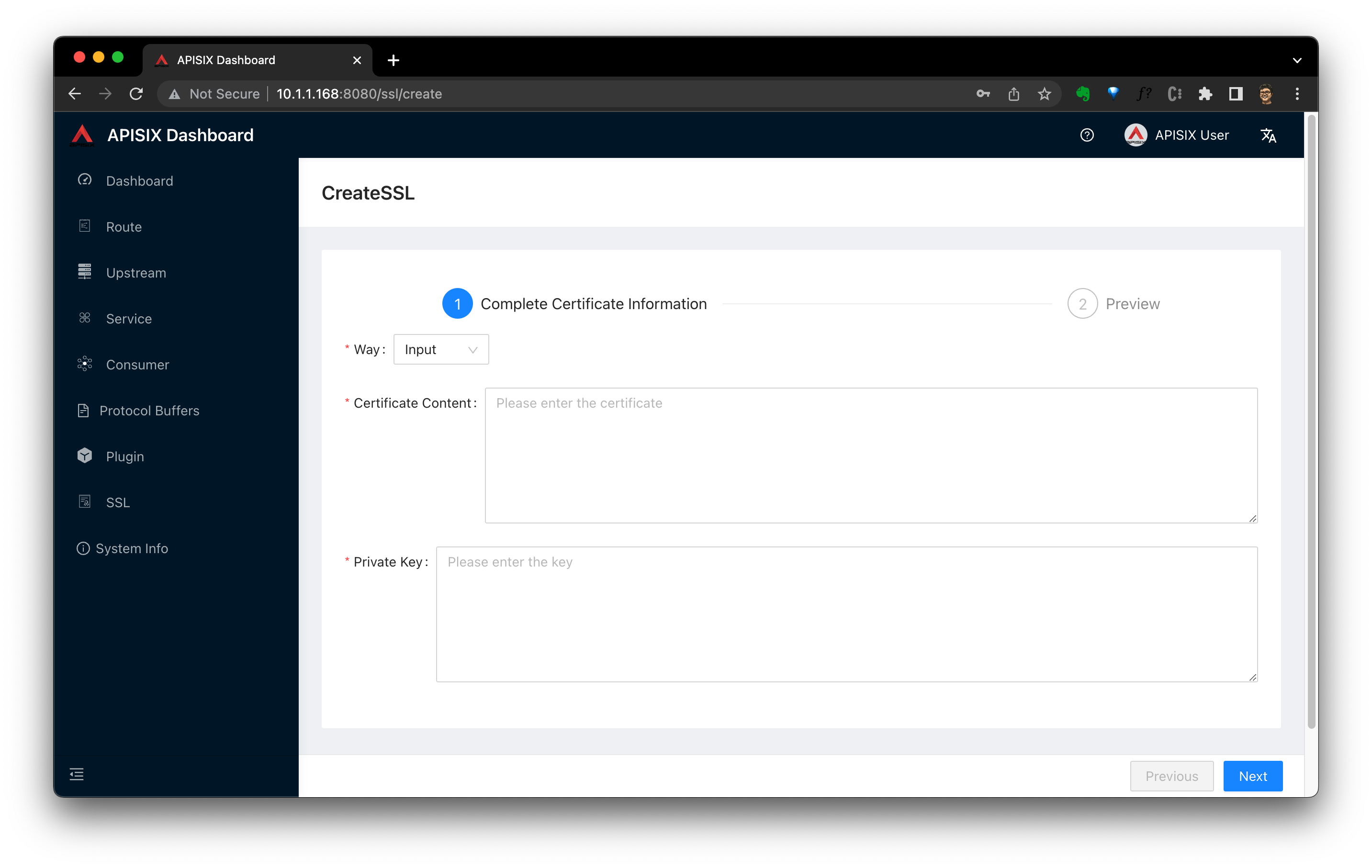
这是我们就有疑问了,压缩数据块的大小是怎么计算出来的呢?首先压缩数据块的最终大小是和索引粒度(index_granularity)相关的,MergeTree 在具体的数据写入过程中,会依照索引粒度按批次获取数据并写入(由于索引粒度默认是 8192,所以每批次会获取 8192 行)。如果把一批未压缩的数据的大小设为 size,则整个数据的写入过程遵循如下规则:
- 单个批次数据 size < 64KB:如果单个批次数据小于 64KB,则继续获取下一批数据,直至累积到size >= 64KB时,生成下一个压缩数据块。如果平均每条 记录小于8byte,多个数据批次压缩成一个数据块;
- 单个批次数据 64KB <= size <=1MB:如果单个批次数据大小恰好在 64KB 与 1MB 之间,则直接生成下一个压缩数据块;
- 单个批次数据 size > 1MB:如果单个批次数据直接超过 1MB,则首先按照 1MB 大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时, 会出现一个批次数据生成多个压缩数据块的情况。如果平均每条记录的大小超过 128byte,则会把当前这一个批次的数据压缩成多个数据块。
也就是说MergeTree在获取数据的时候会依照索引粒度按批次获取数据,所以默认情况下就是每批获取 8192 行,然后一批一批获取,而如果设当前批次的数据大小为 size,那么会根据 size 的不同,走上面三个分支中的一个,整个过程逻辑如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xcb3ZilX-1672192516908)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227135214079.png)]](https://img-blog.csdnimg.cn/3350a146101d4563a28401f722248c7b.png)
数据物理存储
数据文件(.bin)
经过上面分析,我们可以得出来一个column.bin数据文件是由1至多个压缩数据块组成的,每个压缩块大小在64KB~1MB之间,多个压缩数据块之间,按照写入顺序首尾相接,紧密地排列在一起。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SjN7RVvB-1672192516909)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227135310532.png)]](https://img-blog.csdnimg.cn/4cbfeca7a4614b1bbc48c110ec67f02e.png)
在.bin文件中引入压缩数据块的目的至少有以下两个:
其一,虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率,但数据的压缩和解压动作,其本身也会带来额外的性能损耗。所以需要控制被压缩数据的大小,以求在性能损耗和压缩率之间寻求一种平衡;
其二,在具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围。
数据标记(.mrk)
通过前面的分析,我们了解了分区,一级索引,二级索引,知道了数据文件是由多个压缩块组成的,那么如何根据索引定位查询的数据在哪个压缩块以及在压缩块中的数据精确位置,这时候我们就需要数据标记文件。数据标记是衔接一级索引和数据的桥梁,像极了书签,而且书本中每一个章节目录都有各自的书签,它记录了与一级章节目录对应的页码信息,以及一段文字在某一页中的起始位置信息。
数据标记生成规则
数据标记是衔接一级索引和数据的桥梁,它们之间的关系如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hpHI3HdK-1672192516909)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227150957899.png)]](https://img-blog.csdnimg.cn/b117e0b8393b462e9f5fb25399f7e66e.png)
从图中可以看到,数据标记的生成满足如下规则:
- 数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔,如此一来,只需简单通过索引区间的下标编号就可以直接找到对应的数据标记;
- 为了能够与数据衔接,数据标记文件也与
.bin文件一一对应,即每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;以及将该数据压缩块解压后,其未压缩数据的起始偏移量,下图是.mrk文件内标记数据示意:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Br3vqyRN-1672192516910)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227150903312.png)]](https://img-blog.csdnimg.cn/710461ade0194ec7a99425311a31bb1a.png)
数据标记生成实例
假设我们有表hits_v1,Age字段是UInt8,占用一个字节,我们来用该字段进行简单分析一批数据写入后的.bin和.mrk文件内容。
CREATE TABLE hits_v1 (
Age UInt8,
ID String,
EventDate Date
) ENGINE = MergeTree()
ORDER BY Age
PARTITION BY toYYYYMM(EventDate)
我们先回顾下存储块的生成规则,
- 单个批次数据 size < 64KB:如果单个批次数据小于 64KB,则继续获取下一批数据,直至累积到size >= 64KB时,生成下一个压缩数据块。如果平均每条 记录小于8byte,多个数据批次压缩成一个数据块;
- 单个批次数据 64KB <= size <=1MB:如果单个批次数据大小恰好在 64KB 与 1MB 之间,则直接生成下一个压缩数据块;
- 单个批次数据 size > 1MB:如果单个批次数据直接超过 1MB,则首先按照 1MB 大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时, 会出现一个批次数据生成多个压缩数据块的情况。如果平均每条记录的大小超过 128byte,则会把当前这一个批次的数据压缩成多个数据块。
假设我们每次按批读取8192行,因为一个UInt 8一字节,所以每次读取 8192 个字节,在读取8批之后(符合生成规则1)会进行压缩得到一个压缩数据块。生成的第一个压缩数据块为 276 个字节(压缩后大小),然后未压缩数据还剩下 34464 字节,小于 64KB,于是直接生成 155 字节的第二个压缩数据块。因此在 Age.bin 中两个偏移量的对应关系如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-coh0qys0-1672192516910)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227151552624.png)]](https://img-blog.csdnimg.cn/079e231d6cb04381a10dd8b3f8606f64.png)
每一行标记数据都标记了一个片段的数据(默认 8192 行)在 .bin 压缩文件中的读取位置信息,因为 Age 占 1 字节,所以每次读取 8912 行相当于每次读取 8192 个字节,因此 “未压缩数据的起始偏移量” 就是 0、8192、16384、24576、…。但是需要注意图中的 57344,它表示第 8 批未压缩数据的起始偏移量,因为此时已经达到了 64KB,所以会生成一个压缩数据块,于是接下来读取第 9 批未压缩数据的时候就会对应新的压缩数据块,因此起始偏移量会重置为0,而不是 65536。我们这里是 Age 字段为例,至于其它列也是同理,然后是 “压缩数据块的起始偏移量”,因为读了 8 批才生成了第一个压缩数据块,因此前 8 行都是 0。然后由于第一个压缩数据块的大小是 276,因此第 9 行、即索引为 8 的位置,存储的值就是 276,表示第二个压缩数据块的起始偏移量。
以上就是标记文件的存储原理,但是标记文件和一级索引不同,它不能常驻内存,而是使用 LRU(最近最少使用)缓存淘汰策略加快其取用速度。
数据标记与压缩块关系
由于压缩数据块的划分,与一个间隔(index_granularity)内的数据大小相关,每个压缩数据块的体积都被严格控制在64KB~1MB。而一个间隔(index_granularity)的数据,又只会产生一行数据标记。那么根据一个间隔内数据的实际字节大小,数据标记和压缩数据块之间会产生三种不同的对应关系。
- 多对一: 多个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时,会出现这种对应关系;
- 一对一: 一个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size大于等于64KB且小于等于1MB时,会出现这种对应关系;
- 一对多: 一个数据标记对应多个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时,会出现这种对应关系。
数据标记工作方式
MergeTree在读取数据时,必须通过标记数据的位置信息才能够找到所需要的数据。整个查找过程大致可以分为读取压缩数据块和读取数据两个步骤,我们使用上面实例中的数据进行解释:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U1UuLUrA-1672192516911)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227151452684.png)]](https://img-blog.csdnimg.cn/426477565a8945b88be142ff1cddf624.png)
-
读取压缩数据块:在查询某一列数据时,MergeTree无须一次性加载整个
.bin文件,而是可以根据需要,只加载特定的压缩数据块,而这项特性需要借助标记文件中所保存的压缩文件中的偏移量。从图中可以看到,上下相邻的两个压缩数据块的起始偏移量,构成了与当前标记对应的压缩数据块的偏移量区间,说人话就是通过第 n 个压缩数据块的起始偏移量和第 n + 1 个压缩数据块的起始偏移量,可以获取第 n 个压缩数据块。具体做法就是从当前偏移量开始向下寻找(当前块的起始位置 start),直到找到不同的偏移量位置(当前块的下一个块的起始位置 next_start),此时 start 到 next_start 便是当前块对应的偏移量区间,比如图中的 0 到 276。通过偏移量区间,即可获得当前的压缩块; -
读取数据:在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要,以index_granularity的粒度加载特定的一小段。为了实现这项特性,需要借助标记文件中保存的解压数据块中的偏移量。通过偏移量,ClickHouse 可以按需读取数据,比如通过 [0, 8192] 即可读取压缩数据块 0 中第一个数据片段对应的解压数据。
我们最后梳理一下整体的定位数据的思路,先通过索引查找到相应的MarRange,然后根据索引和数据标记之间的对应关系,找到相应的数据标记对应的数据压缩块,然后借助数据标记中的数据偏移量定位到具体压缩块的某段数据,从而实现精确地定位数据的效果。
参考
- https://mp.weixin.qq.com/s/VTTYMdY5A2SZNQdkZoXuhw
- https://www.cnblogs.com/traditional/p/15218743.html
- Clickhouse原理解析与应用实践 朱凯











![玩以太坊链上项目的必备技能(内联汇编 [inline assembly]-Solidity之旅十八)](https://img-blog.csdnimg.cn/c42047118c434f5abb2732c75cae566e.png#pic_center)