Hadoop 的基础知识
- 1. Hadoop 简介
- 2. Hadoop 的发展简史
- 3. Hadoop 现状
- 4. Hadoop 特性优点
- 5. Hadoop 发行版本
- 6. Hadoop 架构变迁
- 7. Hadoop 集群集体概念
1. Hadoop 简介
Hadoop 官网: https://hadoop.apache.org/
Apache Hadoop 软件库是一个框架, 是 Apache 软件基金会的一款开源软件, Java 语言实现的. 允许使用简单的编程模型跨计算机集群分布式处理大型数据集. 它被设计为从单个服务器扩展到数千台机器, 每台机器都提供本地计算和存储. 与其依赖硬件来提供高可用性, 库本身设计用于检测和处理应用程序层的故障, 因此可以在计算机群集上提供高可用服务, 每个计算机群集都可能发生故障.
Hadoop 核心组件:
- Hadoop Common: 支持其他 Hadoop 模块的通用公共程序, 相当于在写项目时所使用的 Util 类的集合.
- Hadoop Distributed File System (HDFS): 提供对应用程序数据的高吞吐量访问的分布式文件系统, 解决海量数据存储.
- Hadoop YARN: 作业调度和集群资源管理的框架, 解决资源任务调度.
- Hadoop MapReduce: 基于 YARN 的大型数据集并行处理系统, 解决海量数据计算.
2. Hadoop 的发展简史
Hadoop 之父: Doug Cutting.
Hadoop 起源于 Apache Lucene 子项目: Nutch
Nutch 的设计目标是构建一个大型的全网搜索引擎. 在此过程中遇到了瓶颈, 如何解决数十亿网页的存储和索引问题.
Google 三篇论文:
1. 《The Google file system》: 谷歌分布式文件系统 GFS
2. 《MapReduce: Simplified Data Processing on Large Clusters》: 谷歌分布式计算框架 MapReduce
3. 《Bigtable: A Distributed Storage System for Structured Data》: 谷歌结构化数据存储系统
由于 Google 有技术解决 Doug Cutting 团队遇到的瓶颈问题, 倒是技术没有开源, 但是 Google 发了文章, Doug Cutting 团队根据这三篇论文生成了 Hadoop 的相关技术, 并开源.
3. Hadoop 现状
HDFS 作为分布式文件存储系统, 处在生态圈的底层与核心地位;
YARN 作为分布式通用的集群资源管理系统和任务调度平台, 支撑各种计算引擎运行, 保证了 Hadoop 地位;
MapReduce 作为大数据生态圈第一代分布式计算引擎, 由于自身设计的模型所产生的弊端, 导致企业一线几乎不再直接使用 MapReduce 进行编程处理, 但是很多软件的底层依然在使用 MapReduce 引擎来处理数据.
4. Hadoop 特性优点
- 扩容能力: Hadoop 是在可用的计算机集群间分配数据并完成计算任务的, 这些集群可方便灵活的方式扩展到数以千计的节点.
- 成本低: Hadoop 集群允许通过部署普通廉价的机器组成集群来处理大数据, 以至于成本很低. 看重的是集群整体能力.
- 先率高: 通过并发数据, Hadoop 可以在节点之间动态并行的移动数据, 使得速度非常快.
- 可靠性: 能自动维护数据的多份复制, 并且在任务失败后能自动地重新部署计算任务. 所以 Hadoop 的按位存储和处理数据的能力值得人们信赖.
- 通用性: Hadoop 是一项技术, 该技术不涉及任何业务内容, 与业务脱节.
- 简单: Hadoop 使用起来比较简单.
5. Hadoop 发行版本
| 发行版本类型 | 来源 | 链接 | 优点 | 缺点 |
|---|---|---|---|---|
| 开源社区版 | Apache 开源社区发行也是官方发行版本 | https://hadoop.apache.org/ | 更新迭代快 | 兼容稳定性不周 |
| 商业发行版 | 商业公司发行基于 Apache 开源协议某些服务需要收费 | https://www.cloudera.com/ | 稳定兼容好 | 收费版本更新慢 |
6. Hadoop 架构变迁
Hadoop 1.0
- HDFS (分布式文件存储)
- MapReduce (资源管理和分布式数据处理)
Hadoop 2.0
- HDFS (分布式文件存储)
- MapReduce (资源管理和分布式数据处理)
- YARN (集群资源管理, 任务调度)
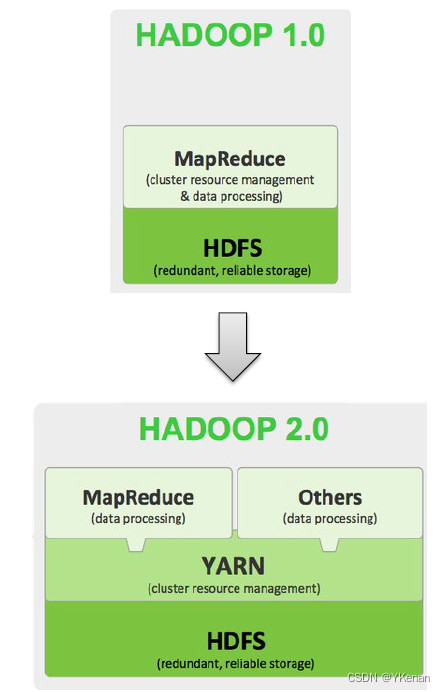
主要看一革命性的变化, 就是 1.0 版本到 2.0 版本的变迁, 因为 hadoop 发展到现在, 大概经历了三个大的版本变化, 仔细对比一下发现底层都是 HDFS, 没有什么变化, 说明数据怎么存储的, 没有什么变化.
1.0 到 2.0 最大的变化, 就是对 MR 进行了大的拆分, 并且引入了一个新的组件, 叫做 YARN. 不难发现这个 MapReduce 这个组件太累了, 他除了要做集群的资源管理, 还要做数据的处理, 这一个组件身兼数职, 并且这两件事情都非常的重要, 那他的性能能好吗? 所以到 2.0 版本之后, hadoop 做了一个非常大的构架变化, 就是把 MR 做了拆分, MR 你只负责处理数据就可以了, 资源管理的事情, 交给专门的组件来做, 这个组件就是 YARN, 并且 YARN 这个组件做的非常通用, 不仅支持 MapReduce, 还支持其他的计算框架, 什么 Spark, Flink 等. 目前市面上 1.0 基本上没什么人用了, 但是 2.8、2.9 这些还是有在用.
Hadoop 3.0 架构组件和 Hadoop 2.0 类似, 3.0 着重于性能优化. 比如支持 GPU, 支持多重备份, 并且内部的数据支持动态平衡, 并且存储效率变高了, 采用删码存储等等. 以上就是 hadoop 各个版本之间的一些区别.
7. Hadoop 集群集体概念
Hadoop 集群包括两个集群: HDFS 集群, YARN 集群
两个集群逻辑上分离, 通常物理上在一起
两个集群都是标准的主从架构集群
- HDFS 集群 (分布式存储):
1.1 主角色: NameNode
1.2 从角色: DataNode
1.3 主角色辅助角色: SecondaryNameNode- HDFS 集群 (资源管理, 调度):
2.1 从角色: ResourceManager
2.2 从角色: NodeManager
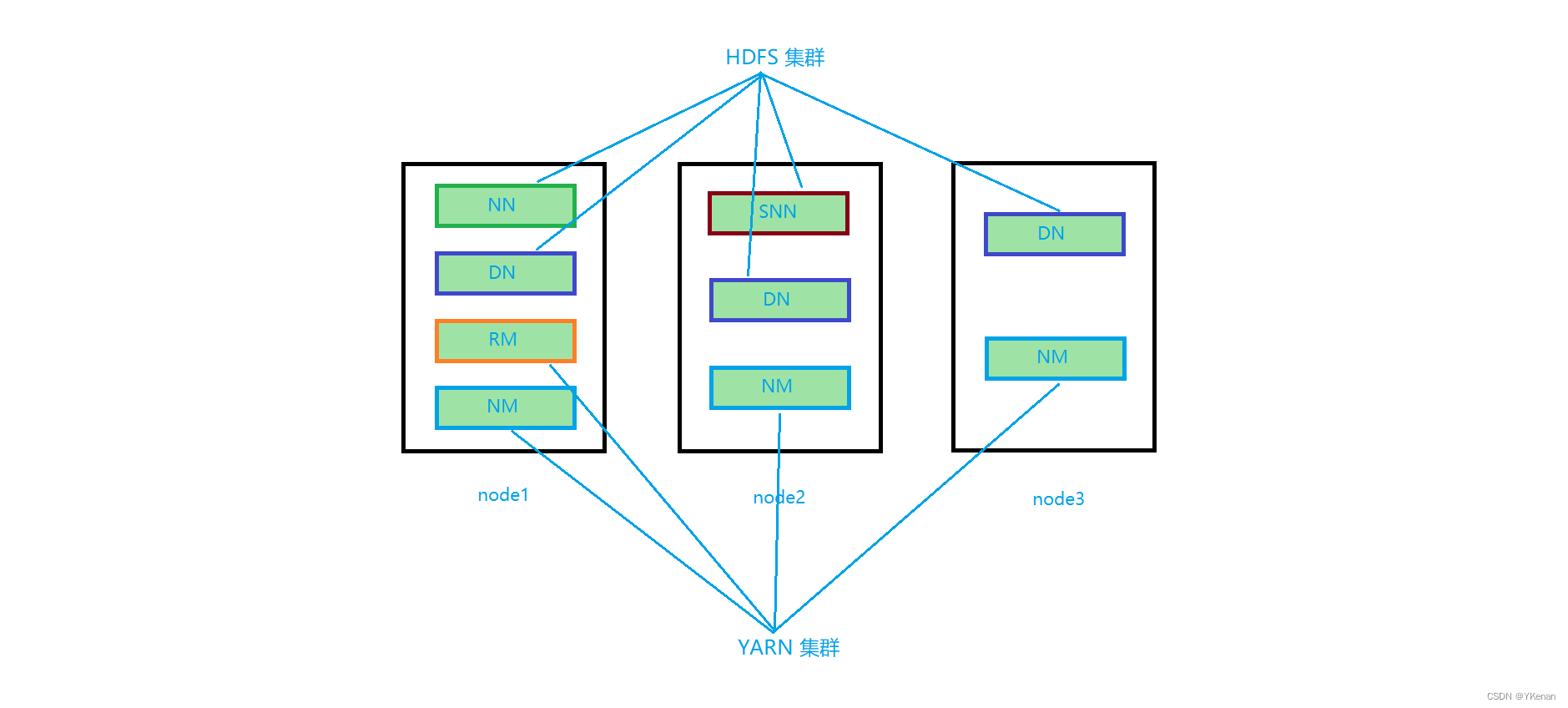
逻辑上分离: 两个集群互相之间没有依赖, 互不影响
物理上在一起: 某些角色进程往往部署在同一台物理服务器上
关于 MapReduce: MapReduce 是计算框架, 代码层面的组件没有集群之说



![玩以太坊链上项目的必备技能(内联汇编 [inline assembly]-Solidity之旅十八)](https://img-blog.csdnimg.cn/c42047118c434f5abb2732c75cae566e.png#pic_center)








![【GO】 K8s 管理系统项目[API部分--Namespace]](https://img-blog.csdnimg.cn/5791e0ae3bf64221a96e3a0febbb4f4f.png)