文章目录
- 1. 简介:
- 速度测试
- 2. paddle 模型转onnx
- 3. onnx转为tensorRT的engine模型
- 4. tensorRT在vs2017中的配置
- 5. 源码
1. 简介:
tensorRT是nvdia GPU模型部署的一个框架,似乎只是部分开源,github地址.大多数时候用这个框架去部署模型效果提升还是比较好的。
整个项目依赖项版本如下
- cuda10.2
- cudnn 8.4.1
- tensorRT 8.4.2.4
速度测试
- GPU Quadro M4000
tensorRT8.4.2 cuda10.2, cuDNN8.4.1, Quadro M4000, 显存8GB。
实际测试时FP32和FP16的精度计算速度几乎一样,用trtexec.exe统计的推理时间如下
| 模型输入尺寸 | 总耗时(ms) | 单张耗时(ms/张) |
|---|---|---|
| 1x3x48x320 | 9.091 | 9.09 |
| 8x3x48x320 | 57.427 | 7.17 |
| 16x3x48x320 | 109.815 | 6.86 |
| 32x3x48x320 | 212.713 | 6.64 |
| 1x3x48x200 | 7.68 | 7.68 |
| 8x3x48x200 | 38.1006 | 4.76 |
| 16x3x48x200 | 71.7976 | 4.48 |
| 32x3x48x200 | 138.024 | 4.31 |
| 1x3x48x160 | 7.2558 | 7.26 |
| 8x3x48x160 | 31.614 | 3.95 |
为什么耗时这么高,比openVINO的都慢?原因是我的老爷显卡quadro M4000太老了,不管怎么测最低时间都是9ms,只能把batch提高来平摊,在quadro RTX4000显卡上1-2ms解决,但是我电脑上没有这块卡,所以只能测这个老爷卡的速度放着了。
- GPU RTX4000
定位一次,识别一次,GPU显存占用0.6GB
| 真实图片尺寸 | 耗时(ms) |
|---|---|
| 1x3x128x256 | 4.230 |
| 1x3x52x226 | 3.507 |
| 1x3x95x116 | 3.232 |
| 1x3x108x151 | 3.249 |
| 1x3x130x160 | 3.234 |
| 1x3x71x156 | 3.512 |
用RTX4000测试的包含定位和识别的速度,定位用的yolo,识别部分分了两个模型一个1x3x48x320,一个1x3x48x160,比较长的图片走320的宽度的模型,短的走160的。定位加识别的速度比M4000快乐太多太多,MD 快给我换新显卡!
2. paddle 模型转onnx
这里参见paddleOCRv3之一: rec识别部分用 openVINO(C++)部署
3. onnx转为tensorRT的engine模型
这里可以采用onnxparser在代码里面转,也可以采用trtexec.exe转,因为engine模型是和GPU硬件绑定的,不同型号的显卡上转换的模型并不通用。所以一般来说用代码转换的方式是更通用的,这一部分如果以后有时间再加吧,这里先用trtexec来转。
tensorRT安装:官网下载下来后直接解压即可
- 转换
命令行模式进入tensorRT的 bin目录,设置临时环境变量指明tensoRT的动态库位置,(否则会报没有nvinfer.dll、xxx.dll错误)
path=%path%;G:\TensorRT-8.4.2.4\TensorRT-8.4.2.4\lib;
转换
trtexec.exe --onnx=K:\model\PaddleOCR\onnxv5\onnx_epoch42\PaddleOCRv3.onnx --saveEngine=K:\model\PaddleOCR\onnxv5\trt_epoch42\ppocr.engine --shapes=“x”:1x3x48x320
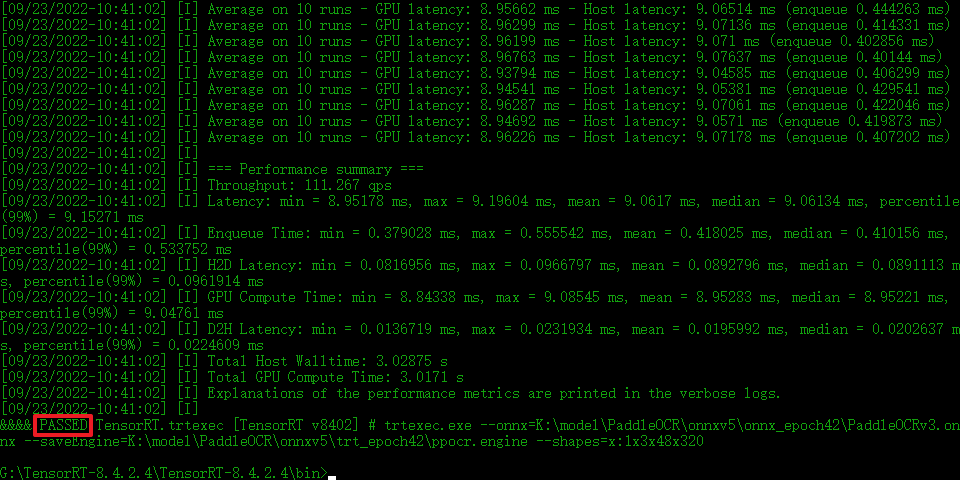
onnx模型是动态输入的,batchsize和width的维度都为-1,–shapes=“x”:1x3x48x320,表示把输入的尺寸固定为1x3x48x320,当然batchsize和width也可以设置为其他值例如:8x3x48x200. tensorRT支持动态尺寸推理,但是官网的原话说就是
Batch size can have a large effect on the optimizations TensorRT performs on our model.
Generally speaking, at inference, we pick a small batch size when we want to prioritize latency
and a larger batch size when we want to prioritize throughput. Larger batches take longer to
process but reduce the average time spent on each sample.
TensorRT is capable of handling the batch size dynamically if you don’t know until runtime
what batch size you will need. That said, a fixed batch size allows TensorRT to make
additional optimizations. For this example workflow, we use a fixed batch size of 64. For more
information on handling dynamic input size, see the NVIDIA TensorRT Developer Guide section
on dynamic shapes.
采用固定的尺寸可以更大程度的优化计算效率。更多关于动态尺寸输入的内容参考 this
4. tensorRT在vs2017中的配置
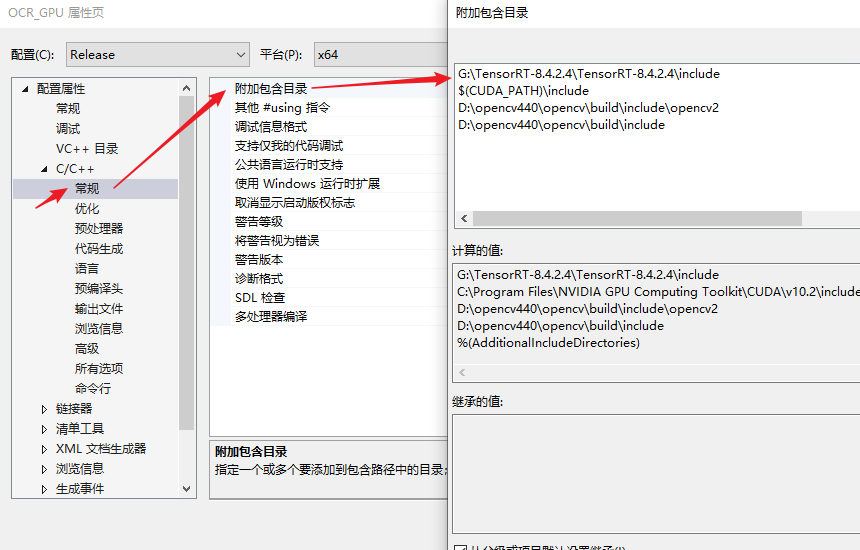
-
附加包含目录
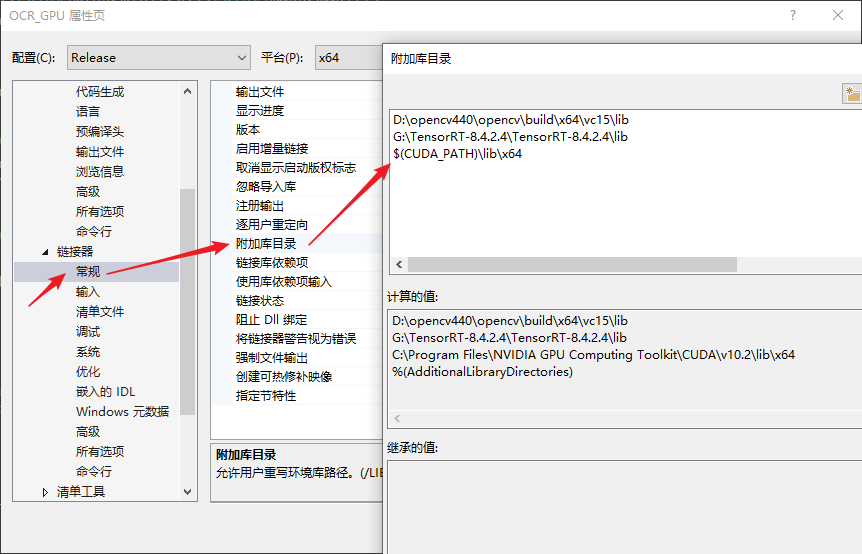
-
附加库目录
-
链接器\输入\附加依赖项
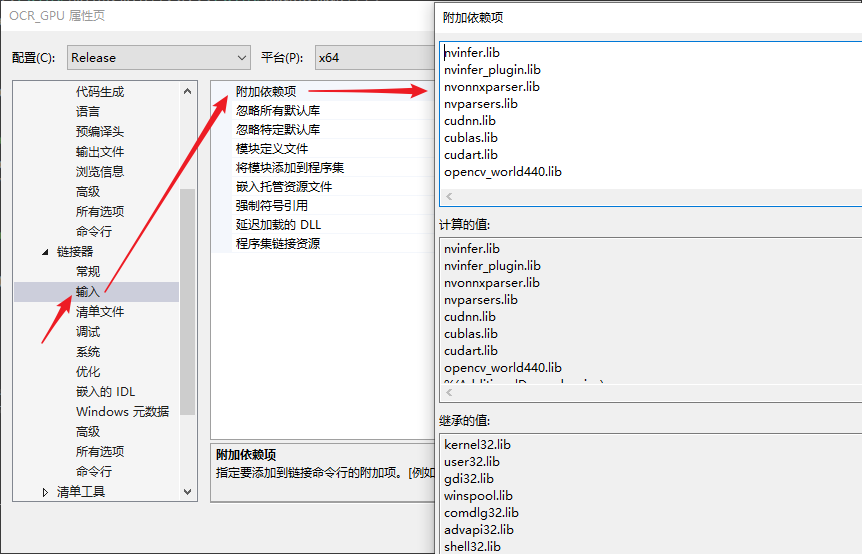
-
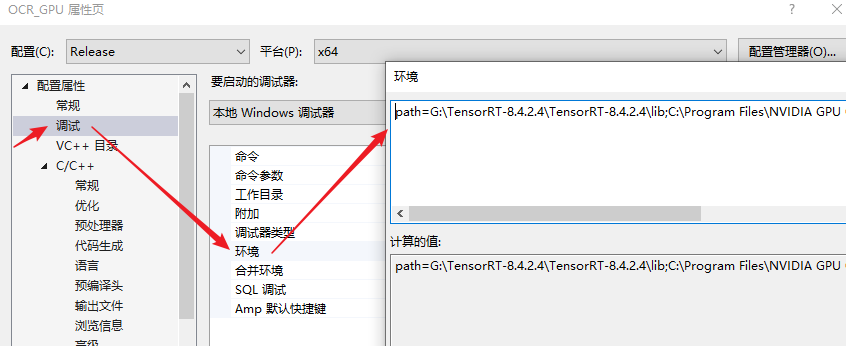
dll路径配置
这个可以选择直接拷贝把dll放入在运行项目旁边,或者添加系统环境变量,这里采用临时在vs工程中配置环境变量的方式。(不同dll项目路径用";"分号隔开,不能加换行符)
path=G:\TensorRT-8.4.2.4\TensorRT-8.4.2.4\lib;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin;D:\opencv440\opencv\build\x64\vc15\bin;
5. 源码
现在只能提供一部分核心代码了,完整的没法发出来了
后处理部分也是把输出转为cv::Mat然后用CTC的方式解码,这部分参考paddleOCRv3之一: rec识别部分用 openVINO(C++)部署
下面是三个比较关键的步骤,初始化模型、推理、释放模型和其他资源,有了这些就已经很明显了,仔细看看下面的步骤结合tensorRT的文档就没有什么问题了。
在这里实际使用的时候可以用设计模式中的template method,定义一个虚基类实现OCR的初始化和推理接口,以及前处理、后处理的一些公共,再定义两个子类分别实现openVINO和TensorRT的推理平台的初始化和推理过程就行。
- 头文件
/***
* @brief : OCR recognition part with tensorRT backend.
*/
class OCR_tensorRT : public OCRInfer
{
public:
OCR_tensorRT() {};
/***
* @brief : Release the resource of GPU and CPU.
* @in param input_para : none
* @return : none
*/
virtual ~OCR_tensorRT();
/***
* @brief : Input model path and load model to device, meanwhile
* set the input_size_ and output_size_ to specific size
* @in param model_path : model path
* @return : If initialize the model successfully ,return true, else return false.
*/
bool InitModel(const std::string &model_path);
/***
* @brief : The inference method of model.
* @in param input : The final input image.
* @out param output : Output tensor saved in output.
* @return : none
*/
virtual void Inference(const cv::Mat &input, cv::Mat &output);
protected:
std::string input_node_name_ = "x";
std::string output_node_name_ = "softmax_2.tmp_0";
bool is_initiated_ = false;
float* input_data_host_ = nullptr;//Host input blob
float* output_data_host_ = nullptr;//Host output blob
float* buffers_[2] = { nullptr,nullptr };;//Device input output buffers_
int input_index_ = -1 ;;//buffers_[input_index_] indicates the input buffer's address on device
int output_index_ = -1;;//buffers_[output_index_] indicates the output buffer's address on device
nvinfer1::IRuntime* runtime_ = nullptr;
nvinfer1::ICudaEngine* engine_ = nullptr;
nvinfer1::IExecutionContext* context_ = nullptr;
cudaStream_t cuda_stream_ = nullptr;;
};
#include "OCR_recognize_GPU.h"
//namespace {
// void Logger::log(nvinfer1::ILogger::Severity severity, const char* msg) noexcept
// {
// // Suppress info-level messages
// if (severity != Severity::kINFO)
// std::cout << msg << std::endl;
// }
//}
bool OCR_tensorRT::InitModel(const std::string &model_path)
{
//Read tensorRT engine model
std::ifstream file(model_path, std::ios::binary);
if (!file.good())
{
is_initiated_ = false;
return is_initiated_;
}
//Get model size
size_t size = 0;
file.seekg(0, file.end);//set the file pointer to the end
size = file.tellg();
file.seekg(0, file.beg);//set the file pointer to the start
//Read model
char *model_stream = new char[size];
file.read(model_stream, size);
file.close();
Logger logger;//tensorRT needs a logger to create inference engine
//Prepare cuda resource
runtime_ = nvinfer1::createInferRuntime(logger);
engine_ = runtime_->deserializeCudaEngine(model_stream, size);
context_ = engine_->createExecutionContext();
delete[] model_stream;
//Get model's input , output shape
this->input_index_ = engine_->getBindingIndex(input_node_name_.c_str());
this->output_index_ = engine_->getBindingIndex(output_node_name_.c_str());
nvinfer1::Dims input_shape = engine_->getBindingDimensions(input_index_);//NCHW (1,3,48,320,...)
nvinfer1::Dims output_shape = engine_->getBindingDimensions(output_index_);//NHW(1,40,67,...)
size_t input_batch_size = input_shape.d[0];
size_t input_channels = input_shape.d[1];
size_t input_height = input_shape.d[2];
size_t input_width = input_shape.d[3];
size_t input_size = input_batch_size * input_channels * input_height * input_width;
size_t output_batch_size = output_shape.d[0];
size_t output_height = output_shape.d[1];
size_t output_width = output_shape.d[2];
size_t output_size = output_batch_size * output_height * output_width;
//Set base class input_size_ output_size_
std::vector<int> input_size_vec = { (int)input_batch_size,(int)input_channels,
(int)input_height,(int)input_width };
std::vector<int> output_size_vec = { (int)output_batch_size,(int)output_height,(int)output_width };
this->SetInputSize(input_size_vec);
this->SetOutputSize(output_size_vec);
//Prepare input output blobs on host
input_data_host_ = (float*)malloc(input_size * sizeof(float));
output_data_host_ = (float*)malloc(output_size * sizeof(float));
if (!input_data_host_ || !output_data_host_)
{
is_initiated_ = false;
return is_initiated_;
}
//Prepare input output buffers_ on device
cudaMalloc((void**)&buffers_[input_index_], input_size * sizeof(float));
cudaMalloc((void**)&buffers_[output_index_], output_size * sizeof(float));
if (!buffers_[input_index_] || !buffers_[output_index_])
{
is_initiated_ = false;
return is_initiated_;
}
//Create a cuda stream
cudaStreamCreate(&cuda_stream_);
is_initiated_ = true;
return is_initiated_;
}
void OCR_tensorRT::Inference(const cv::Mat &input, cv::Mat &output)
{
//Prepare input blob on host
size_t input_height = input.rows;
size_t input_width = input.cols;
size_t input_channels = input.channels();
size_t image_size = input_height * input_width;
for (size_t pid = 0; pid < image_size; ++pid)
{
for (size_t ch = 0; ch < input_channels; ++ch)
{
input_data_host_[image_size*ch + pid] = input.at<cv::Vec3f>(pid)[ch];
}
}
//Copy input from host to device(GPU)
size_t input_size = input_height * input_width * input_channels;
cudaMemcpyAsync(buffers_[input_index_], input_data_host_, input_size* sizeof(float), cudaMemcpyHostToDevice, cuda_stream_);
//Inference
context_->enqueueV2((void**)buffers_, cuda_stream_, nullptr);
//Copy output from device to host
size_t output_height = this->output_size_[1];
size_t output_width = this->output_size_[2];
size_t output_size = output_height * output_width;
cudaMemcpyAsync(output_data_host_, buffers_[output_index_], output_size * sizeof(float), cudaMemcpyDeviceToHost, cuda_stream_);
cv::Mat outputMat(output_height, output_width, CV_32FC1, output_data_host_);
output = outputMat;
return ;
}
OCR_tensorRT::~OCR_tensorRT()
{
//Destroy model
if (context_)
{
context_->destroy();
context_ = nullptr;
}
if (engine_)
{
engine_->destroy();
engine_ = nullptr;
}
if (runtime_)
{
runtime_->destroy();
runtime_ = nullptr;
}
//Release GPU memory
if (buffers_[input_index_])
{
cudaFree(buffers_[input_index_]);
buffers_[input_index_] = nullptr;
}
if (buffers_[output_index_])
{
cudaFree(buffers_[output_index_]);
buffers_[output_index_] = nullptr;
}
//Destroy cuda stream
if (cuda_stream_)
{
cudaStreamDestroy(cuda_stream_);
cuda_stream_ = nullptr;
}
//Release host memory
if (input_data_host_)
{
free(input_data_host_);
input_data_host_ = nullptr;
}
if (output_data_host_)
{
free(output_data_host_);
output_data_host_ = nullptr;
}
}