官方教程:
YOLO: Real-Time Object Detection
一、使用预训练模型进行检测
1、安装Darknet:
git clone https://github.com/pjreddie/darknet
cd darknet
make2、下载预训练权重https://pjreddie.com/media/files/yolov3.weights(打开链接或wget)
https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3.weights3、运行检测器
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpgdarknet/data文件夹下有还有其他图片可以进行测试。
data/eagle.jpg, data/dog.jpg, data/person.jpg, or data/horses.jpg!
检测命令和下面这条命令是等同的,如果只是想测试一张图片的话,不需要了解。如果想做其他更多的事情要了解该命令:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg4、多个图像
在提供图像命令部分,使用空格,此时将连续测试多个图像,配置和权重加载完成后可以看到如下提示:
./darknet detect cfg/yolov3.cfg yolov3.weightsLoading weights from yolov3.weights...Done!
Enter Image Path:
可以任选以下路径之一输入:
data/eagle.jpg, data/dog.jpg, data/person.jpg, or data/horses.jpg!
Loading weights from yolov3.weights...Done!
Enter Image Path: data/eagle.jpg
data/eagle.jpg: Predicted in 19.587430 seconds.
bird: 99%
Enter Image Path:
然后可以再次输入路径,使用ctrl-c或命令有错误时可以退出程序。
5、改变检测阈值
默认情况下,yolo仅显示检测到的置信度为0.25或者更高的对象,可以通过将-thread <val>标志传递给yolo更改设置,改为0表示显示所有检测。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 06、微型yolov3
yolov3-tiny非常小的模型用于受限环境,使用此模型,下载权重:
wget https://pjreddie.com/media/files/yolov3-tiny.weights运行检测器
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpgLoading weights from yolov3-tiny.weights...Done!
data/dog.jpg: Predicted in 0.771317 seconds.
dog: 57%
car: 52%
truck: 56%
car: 62%
bicycle: 59%
小的模型训练时间明显提升,本机测试时间从17~19s降到0.77s。
二、摄像头实时检测
1.运行此演示,需要cuda和opencv,安装教程如下:
cuda教程:(真心推荐该教程,按头安利)
深度学习必备NVIDIA三件套环境,大佬同学写了不错的教程,推荐给大家,祝大家科研顺利:
NVIDIA三件套环境配置 - PleasureReceiver
NVIDIA三件套安装问题汇总 - PleasureReceiver
这两篇文章+百度解决所有问题,本人使用该教程多次成功安装三件套。
opencv教程:
在ubuntu16.04下安装opencv3.4.10(超详细测试成功)_再打三年球的博客-CSDN博客_opencv-3.4.10压缩包下载
此方法安装依赖的时候,E: 无法定位软件包 libjasper-dev,使用下面方法的方式安装依赖。
ubuntu安装opencv的正确方法_普通网友的博客-CSDN博客_opencv ubuntu
2.编译 Darknet with CUDA and OpenCV
(1)with cuda
修改Makefile
GPU=1默认在0号显卡运行,如果想换卡,添加参数-i, -i <index>,eg:
./darknet -i 1 imagenet test cfg/alexnet.cfg alexnet.weights如果使用CUDA编译但是又想使用CPU,使用命令 -nogpu,eg:
./darknet -nogpu imagenet test cfg/alexnet.cfg alexnet.weights(2)with opencv
Darknet默认使用stb_image.h加载图像,想要使用更多格式支持就要改用opencv,使用opencv不需要将图像保存到磁盘就可以查看图像和检测结果。
同理修改Makefile
OPENCV=1修改完后,需要重新make以下工程,报错:是cudann版本问题,官网有更新对应的文件
./src/convolutional_layer.c:153:13: error: ‘CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT’ undeclared (first use in this function); did you mean ‘CUDNN_CONVOLUTION_FWD_ALGO_DIRECT’?
CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT,
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
CUDNN_CONVOLUTION_FWD_ALGO_DIRECT
compilation terminated due to -Wfatal-errors.
Makefile:90: recipe for target 'obj/convolutional_layer.o' failed
make: *** [obj/convolutional_layer.o] Error 1
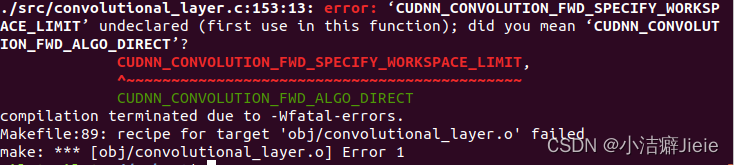
如何解决pjreddie版darknet不能使用cudnn8编译的问题_Arnold-FY-Chen的博客-CSDN博客_./src/convolutional_layer.c:153:13: error: 鈥楥udnn_
可以去官网找到相应文件进行替换:
GitHub - arnoldfychen/darknet: Convolutional Neural Networks
又有new bug:opencv版本问题,本人安装的opencv是3.4.10
./src/image_opencv.cpp:63:20: error: conversion from ‘cv::Mat’ to non-scalar type ‘IplImage {aka _IplImage}’ requested
IplImage ipl = m;
^
compilation terminated due to -Wfatal-errors.
Makefile:87: recipe for target 'obj/image_opencv.o' failed
make: *** [obj/image_opencv.o] Error 1

DarkNet——OpenCV版本遇到的问题_Captain_zp的博客-CSDN博客
new new bug;
nvcc fatal : Unsupported gpu architecture 'compute_30'
Makefile:93: recipe for target 'obj/convolutional_kernels.o' failed
make: *** [obj/convolutional_kernels.o] Error 1
这篇cadn教材有提到过这个bug,把Makefile里的配置修改一下
如何解决pjreddie版darknet不能使用cudnn8编译的问题_Arnold-FY-Chen的博客-CSDN博客_./src/convolutional_layer.c:153:13: error: 鈥楥udnn_
参考csdn教程:本教程指出,Makefile文件中的NVCC也要修改,NVCC=/usr/local/cuda-9.0/bin/nvcc,原为 NVCC = nvcc,cuda后面的紧跟自己的cuda版本,如cuda-9.0,cuda-10.0等
Ubuntu18.04下YOLOv3详解——搭建、训练、测试、评估_夜夜coding到天明的博客-CSDN博客_yolo v3 imx8
再次make后成功,然后使用 imtest 例程测试图片加载和显示:
./darknet imtest data/eagle.jpg3.现在cuda和opencv编译完成,运行命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weightsYOLO 将显示当前的 FPS 和预测的类别,以及在其上绘制边界框的图像
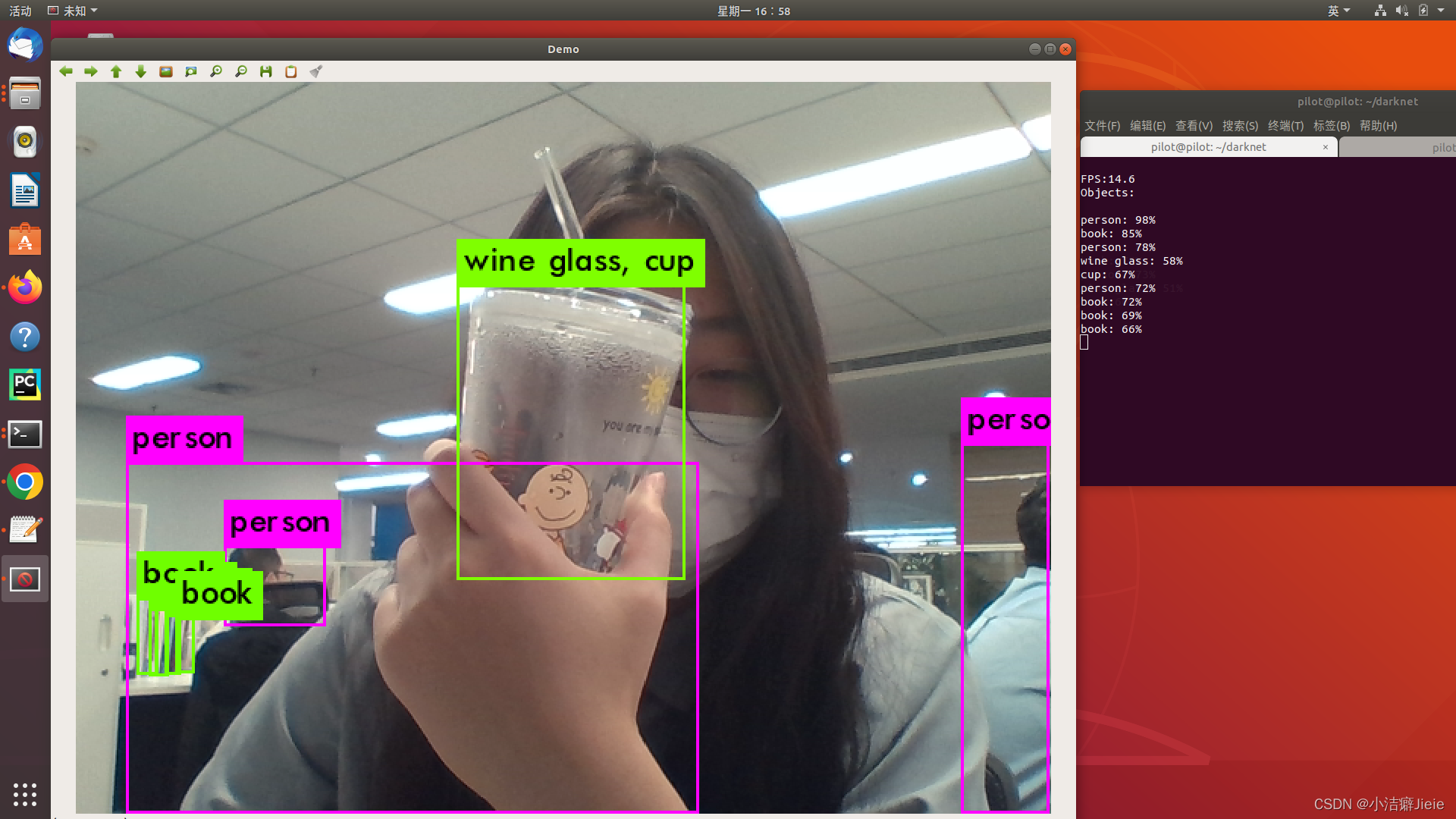

如果连接了多个摄像头,可以添加参数-c <num>,选择摄像头,opencv有指令可以查看摄像头编号,笔记本自带摄像头默认是0。
如果 OpenCV 可以读取视频,也可以在视频文件上运行它:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>测试了一下本人手机拍摄的视频.mp4文件,对文件没有做任何处理

三、VOC数据集上训练
1.下载数据集,VOCdevkit/ 中包含所有 VOC 训练数据。
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar2.生成labels文件
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py几分钟后完成,此时文件结构如下:
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tarDarknet 需要一个文本文件,其中包含您要训练的所有图像。在此示例中,使用除 2007 测试集之外的所有内容进行训练,以便可以测试模型。运行:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt4.修改 Pascal 数据的 Cfg
更改 cfg/voc.data 配置文件以指向自己的数据, <path-to-voc>修改为自己的地址:
1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backup5.下载预训练的卷积权重
wget https://pjreddie.com/media/files/darknet53.conv.746.训练模型
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74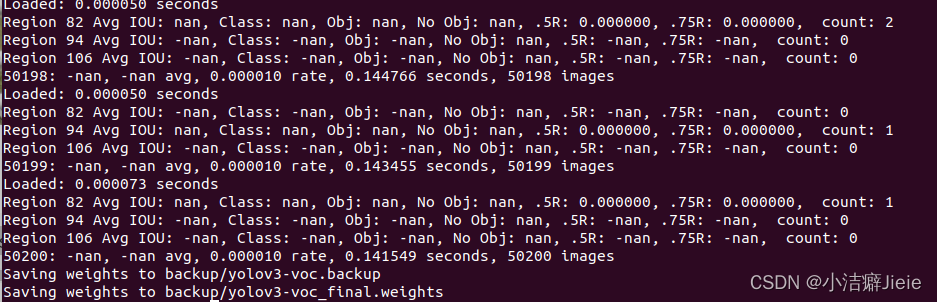
训练过程中在backup文件中生成权重文件,本人用时差不多一天,但是模型训练不好,IOU为nan,正常情况应该是一个接近1的值,git的issue里有类似情况,需要进行优化。
GitHub - pjreddie/darknet: Convolutional Neural Networks
模型训练完,可以进行检测,单图检测,选出一张图像放入darknet文件夹下,然后运行:
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_10000.weights 000275.jpg然后使用测试集的全部图像进行预测,进而得出准确率。
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_10000.weights简单记录了一下安装配置测试过程,后面还有很多工作要做,如:yolov3测试自己数据集,优化测试VOC数据集,测试coco数据集等等~后面继续更新记录



![[oeasy]python0033_回车_carriage_return_figlet_字体变大](https://img-blog.csdnimg.cn/img_convert/a9449abfc66311ac42530d04a6d26e4a.png)