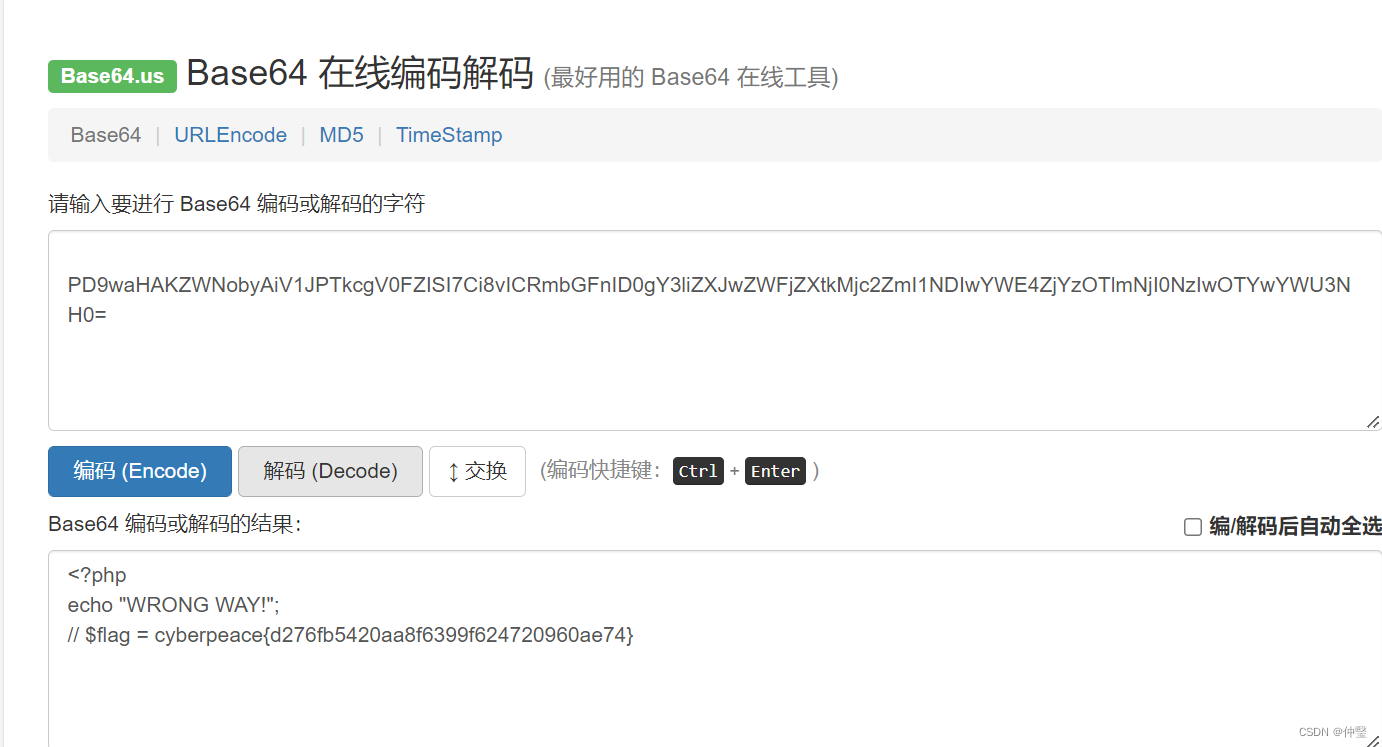
以代码的方式复习考研数据结构知识点,这里在考研不以代码为重点,而是以实现过程为重点
文章目录
- 1. 无向图最小生成树算法
- Kruskal算法
- C++代码实现
- Prim算法
- C++代码实现
1. 无向图最小生成树算法
常见基本概念记忆:
生成树定义:
无向图中一个连通图的最小连通子图称为生成树。(用最少的边把所有顶点连接起来)。n个顶点的连通图的生成树有n-1条边。
路径长度:对于不带权图为路径的边个数。带权图为路径所有边权值的和
最小生成树:所有生成树中,路径长度最小的生成树。
所以生成树一定是连通图。这个定义是在无向图的基础上开展的。
连通图:无向图中,若顶点A、B存在路径,称为A、B连通。若图中的任意两点都是连通的,则称此图为连通图。
构造最小生成树的方法:Kruskal算法和Prim算法。这两个算法都采用了逐步求解的贪心策略。
最小生成树的性质
-
最小生成树不是唯一的,即最小生成树的树形不唯一,田中可能有多个最小生成树。
当图G中的各边权值互不相等时,G的最小生成树是唯一的;
若无向连通图G的边数比顶点数少1,即G本身是一棵树时,则G的最小生成树就是它本身。
-
最小生成树的边的权值之和总是唯一的,虽然最小生成树不唯一,但其对应的边的权值之和总是唯一的,而且是最小的。
-
最小生成树的边数为顶点数减1。
Kruskal算法
克鲁斯卡尔算法查找最小生成树的方法是:将连通网中所有的边按照权值大小做升序排序,从权值最小的边开始选择,只要此边不和已选择的边一起构成环路,就可以选择它组成最小生成树。对于 N 个顶点的连通网,挑选出 N-1 条符合条件的边,这些边组成的生成树就是最小生成树。
Kruskal算法时间复杂度与图的边有关,与顶点无关,为O(ElogE)
Kruskal算法适合边稀疏而顶点较多的图
eg:C语言中文网
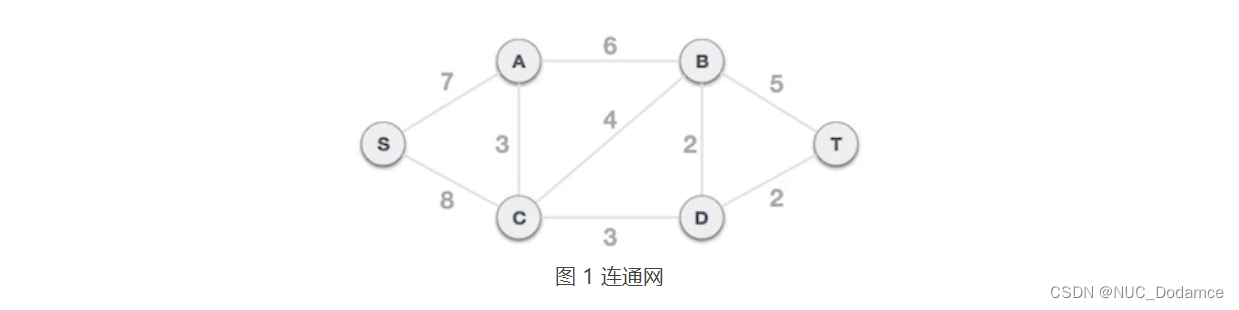
具体实现步骤:
-
将连通网中的所有边按照权值大小做升序排序

-
从 B-D 边开始挑选,由于尚未选择任何边组成最小生成树,且 B-D 自身不会构成环路,所以 B-D 边可以组成最小生成树。
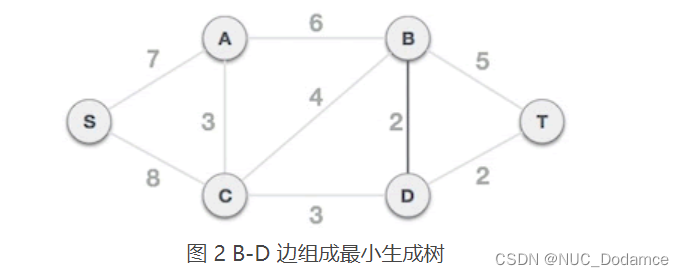
-
D-T 边不会和已选 B-D 边构成环路,可以组成最小生成树
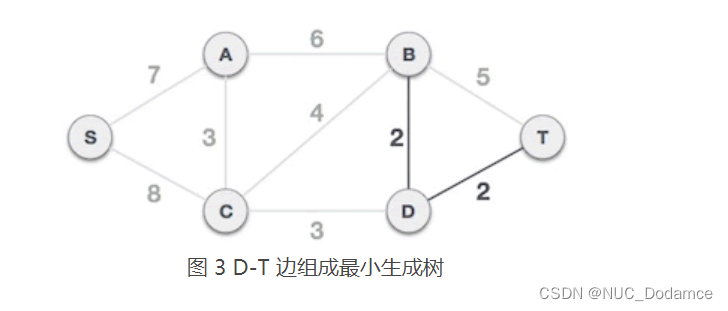
-
A-C 边不会和已选 B-D、D-T 边构成环路,可以组成最小生成树
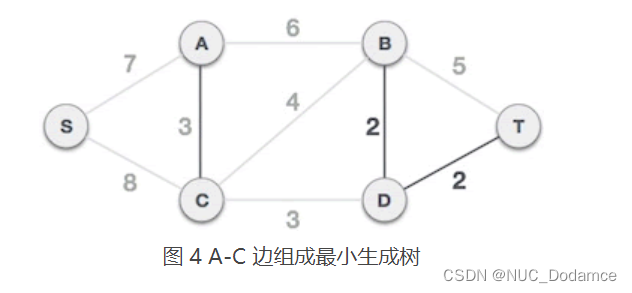
-
C-D 边不会和已选 A-C、B-D、D-T 边构成环路,可以组成最小生成树
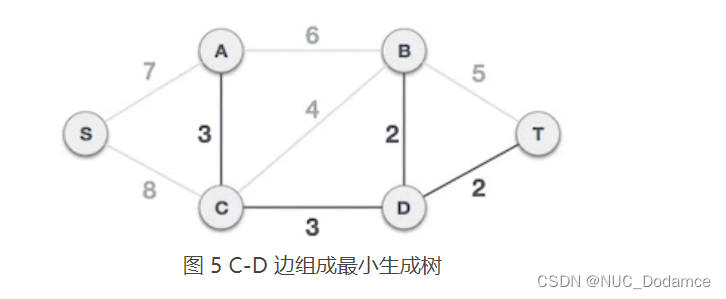
-
C-B 边会和已选 C-D、B-D 边构成环路,因此不能组成最小生成树
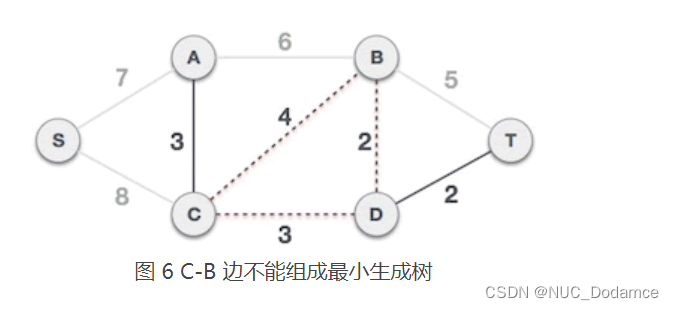
-
B-T 、A-B、S-A 三条边都会和已选 A-C、C-D、B-D、D-T 构成环路,都不能组成最小生成树。而 S-A 不会和已选边构成环路,可以组成最小生成树。
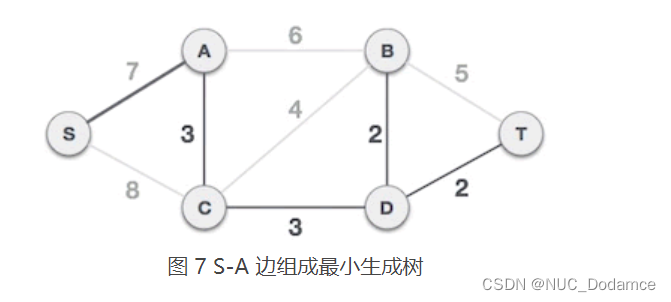
综上所述构造的最小生成树为:
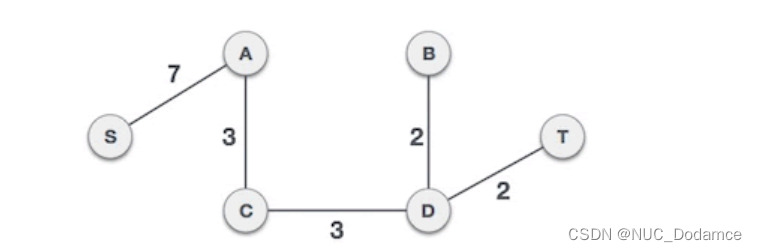
C++代码实现
- 权值从小到大排序使用C++优先级队列完成。默认大顶堆,我们这里要使用小顶堆
- 判断图是否产生闭环,可以采用并查集的方式。如果这个边的顶点在并查集中,则说明如果添加这条边的话就构成环
数据结构-难点突破(C++实现并查集+路径优化,详解哈夫曼编码树)
为了简单,这里的图全部采用邻接矩阵存储,算法整体难度不高
并查集代码:
// 构建并查集
#include <assert.h>
#include <vector>
#include <stdio.h>
class UnionFindSet
{
private:
// 数组的下标保存的是并查集的数据,数组的值记录的是并查集这个节点的父节点下标
std::vector<int> ufs;
public:
UnionFindSet(size_t size)
{
ufs.resize(size, -1);
}
// x和y所在的两个集合合并
void Union(int x, int y)
{
assert(x < ufs.size() && y < ufs.size());
int root_x = FindRoot(x);
int root_y = FindRoot(y);
if (root_x != root_y)
{
// 不在一棵树上
ufs[root_x] += ufs[root_y];
ufs[root_y] = root_x;
}
}
// 找data的根
int FindRoot(int data)
{
int root = data;
while (ufs[root] >= 0)
{
root = ufs[root];
}
// 找到根后,这里做优化,降低并查集树的高度
// 把这个节点到根节点路径上的所有节点插入到根节点上
while (data != root)
{
int parent = ufs[data];
ufs[data] = root;
data = parent;
}
return root;
}
// 获取并查集中树的个数
int GetTreeSize()
{
int ret = 0;
for (int i = 0; i < ufs.size(); i++)
{
if (ufs[i] < 0)
ret += 1;
}
return ret;
}
// 打印并查集信息
void PrintUfs()
{
for (int i = 0; i < ufs.size(); i++)
{
printf("%2d ", i);
}
printf("\n");
for (int i = 0; i < ufs.size(); i++)
{
printf("%2d ", ufs[i]);
}
printf("\n");
}
//判断两个点是否在一个集合中
bool IsSameSet(int left, int right) {
return FindRoot(left) == FindRoot(right);
}
};
无向图,邻接矩阵,Kruskal算法:
// 邻接矩阵法存储图结构
#include <iostream>
#include <assert.h>
#include <map>
#include <vector>
#include <stdio.h>
#include <queue>
#include "UnionFindSet.h"
// v:图顶点保存的值。w:边的权值 max:最大权值,代表无穷。flag=true代表有向图。否则就是无向图
template <class v, class w, w max = INT_MAX, bool flag = false>
class graph
{
private:
std::vector<v> _verPoint; // 顶点集合
std::map<v, int> _indexMap; // 顶点与下标的映射
std::vector<std::vector<w>> _matrix; // 邻接矩阵
int _getPosPoint(const v &point)
{
if (_indexMap.find(point) != _indexMap.end())
{
return _indexMap[point];
}
else
{
std::cout << point << " not found" << std::endl;
return -1;
}
}
public:
graph() = default;
// 根据数组来开辟邻接矩阵
graph(const std::vector<v> &src)
{
_verPoint.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_verPoint[i] = src[i];
_indexMap[src[i]] = i;
}
// 初始化邻接矩阵
_matrix.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_matrix[i].resize(src.size(), max);
}
}
// 添加边的关系,输入两个点,以及这两个点连线边的权值。
void AddEdge(const v &pointA, const v &pointB, const w &weight)
{
// 获取这个顶点在邻接矩阵中的下标
int posA = _getPosPoint(pointA);
int posB = _getPosPoint(pointB);
_matrix[posA][posB] = weight;
if (!flag)
{
// 无向图,邻接矩阵对称
_matrix[posB][posA] = weight;
}
}
// 打印邻接矩阵
void PrintGraph()
{
// 打印顶点对应的坐标
typename std::map<v, int>::iterator pos = _indexMap.begin();
while (pos != _indexMap.end())
{
std::cout << pos->first << ":" << pos->second << std::endl;
pos++;
}
std::cout << std::endl;
// 打印边
printf(" ");
for (int i = 0; i < _verPoint.size(); i++)
{
std::cout << _verPoint[i] << " ";
}
printf("\n");
for (int i = 0; i < _matrix.size(); i++)
{
std::cout << _verPoint[i] << " ";
for (int j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] == max)
{
// 这条边不通
printf("∞ ");
}
else
{
std::cout << _matrix[i][j] << " ";
}
}
printf("\n");
}
printf("\n");
}
// -------------------------------------Kruskal--------------------------------------------
typedef graph<v, w, max, flag> self;
// 代表图的一条边
struct edge
{
size_t src;
size_t dst;
w weight;
edge(size_t _src, size_t _dst, w _weight)
{
this->src = _src;
this->dst = _dst;
this->weight = _weight;
}
};
// 小堆排序规则,从小到打排序
struct rules
{
bool operator()(const edge &left, const edge &right)
{
return left.weight > right.weight;
}
};
// 最小生成树,返回最小生成树权值,传入一个图,这个参数是输入输出参数,函数结束后,minTree是图的最小生成树
w kruskal(self &minGraph)
{
size_t size = _verPoint.size();
minGraph._verPoint = _verPoint;
minGraph._indexMap = _indexMap;
// 初始化最小生成树的邻接矩阵
minGraph._matrix.resize(size);
for (size_t i = 0; i < size; i++)
{
minGraph._matrix[i].resize(size, max);
}
std::priority_queue<edge, std::vector<edge>, rules> queue;
// 将所有的边添加到优先级队列中,因为是无向图的边,所以只需要遍历一半数组即可
for (size_t i = 0; i < size; i++)
{
for (size_t j = 0; j < i; j++)
{
if (_matrix[i][j] != max)
{
queue.push(edge(i, j, _matrix[i][j]));
}
}
}
// 选出n-1条边
int dstSize = 0;
w total = w();
// 创建并查集来标记是否成环,大小为图顶点个数。
UnionFindSet unionSet(size);
while (!queue.empty())
{
edge MinEdge = queue.top();
queue.pop();
// 判断这条边顶点是否在并查集中,在并查集中构成环,不符合最小生成树定义。
if (!unionSet.IsSameSet(MinEdge.src, MinEdge.dst))
{
// 打印选的边测试
//std::cout << _verPoint[MinEdge.src] << "->" << _verPoint[MinEdge.dst] << " 权值:" << MinEdge.weight << "\n";
minGraph.AddEdge(_verPoint[MinEdge.src], _verPoint[MinEdge.dst], MinEdge.weight);
unionSet.Union(MinEdge.src, MinEdge.dst);
dstSize += 1;
total += MinEdge.weight;
}
}
if (dstSize != size - 1)
{
// 没有找到生成树
std::cout << "没有找到生成树" << std::endl;
return w();
}
return total;
}
};
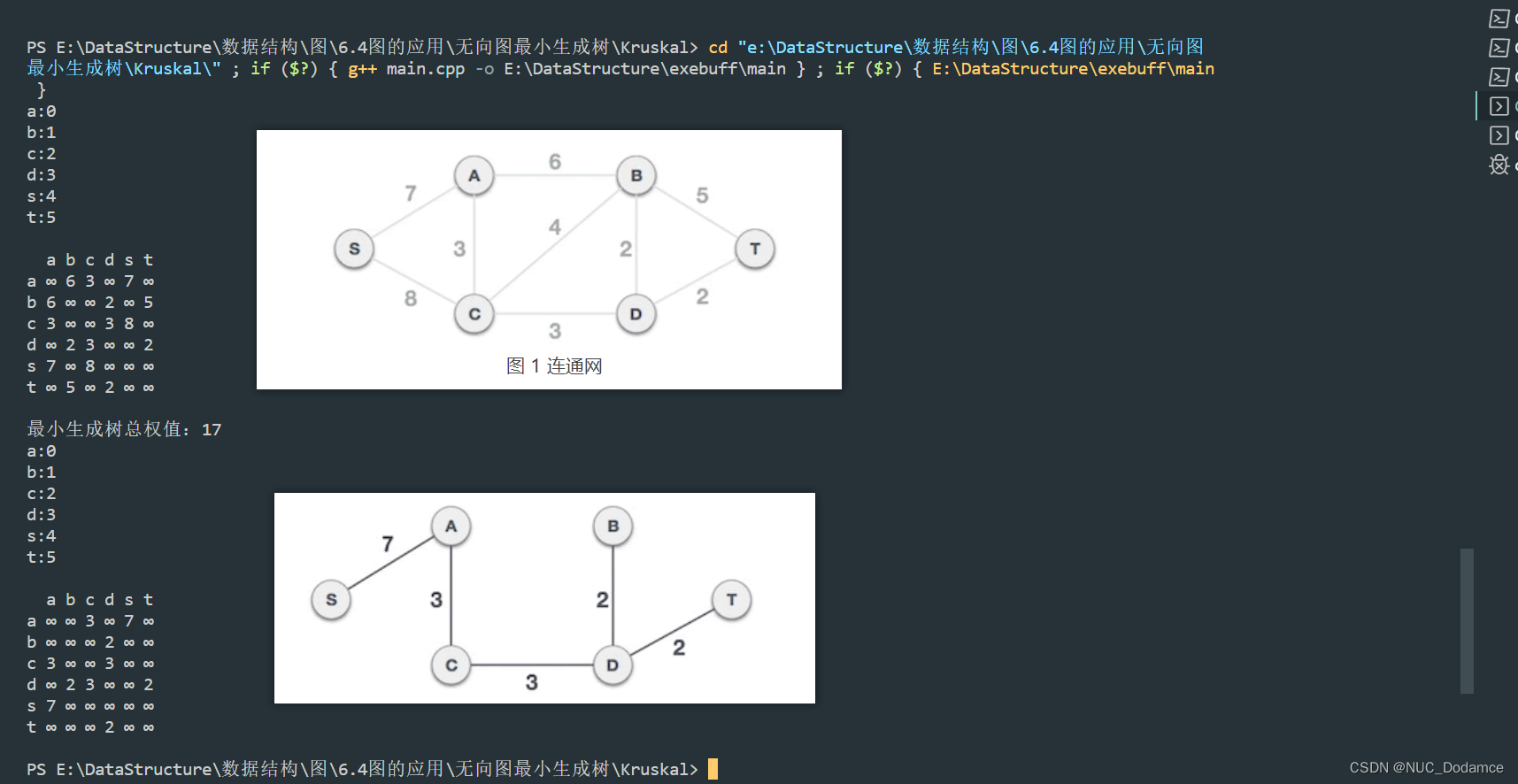
测试代码与结果图
#include "matrix.h"
using namespace std;
int main(int argc, char const *argv[])
{
vector<char> vet = {'a', 'b', 'c', 'd', 's', 't'};
graph<char, int> Graph(vet);
Graph.AddEdge('a', 'b', 6);
Graph.AddEdge('b', 't', 5);
Graph.AddEdge('t', 'd', 2);
Graph.AddEdge('d', 'c', 3);
Graph.AddEdge('c', 's', 8);
Graph.AddEdge('s', 'a', 7);
Graph.AddEdge('c', 'a', 3);
Graph.AddEdge('c', 's', 8);
Graph.AddEdge('b', 'd', 2);
Graph.PrintGraph();
graph<char, int> minGraph;
cout << "最小生成树总权值:" << Graph.kruskal(minGraph) << endl;
minGraph.PrintGraph();
return 0;
}
Prim算法
与Kruskal算法类似,Prim算法也是通用最小生成树算法的一个特例。
Prim算法的工作原理与Dijkstra最短路径算法类似,也是使用局部贪心。
Prim算法:
开始指出一个起点,从起点开始找最小生成树。Prim算法将所有顶点分成两部分:已经选入的点,未选入的点。算法思路是从未选入部分顶点中选出一个点,再从选入的点中选择一个。这两个点的关系是:直接相连构成边,且这条边是所有选择中权值最小的。将选则的点添加到已经选择部分顶点集合中。
Prim算法的时间复杂度为 O(N2),不依赖于边,依赖顶点个数,因此它适用于求解边稠密的图的最小生成树
具体实现步骤:
eg:C语言中文网

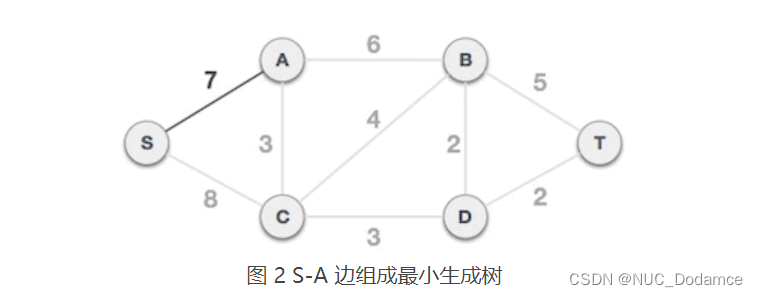
- 将图中的所有顶点分为 A 类和 B 类,初始状态下,A = {},B = {A, B, C, D, S, T}。
- 从 B 类中任选一个顶点,假设选择 S 顶点,将其从 B 类移到 A 类,A = {S},B = {A, B, C, D, T}。从 A 类的 S 顶点出发,到达 B 类中顶点的边有 2 个,分别是 S-A 和 S-C,其中 S-A 边的权值最小,所以选择 S-A 边组成最小生成树,将 A 顶点从 B 类移到 A 类,A = {S, A},B = {B, C, D, T}。
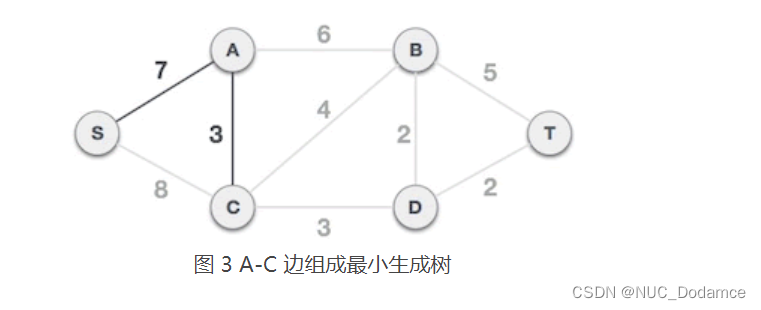
- 从 A 类中的 S、A 顶点出发,到达 B 类中顶点的边有 3 个,分别是 S-C、A-C、A-B,其中 A-C 的权值最小,所以选择 A-C 组成最小生成树,将顶点 C 从 B 类移到 A 类,A = {S, A, C},B = {B, D, T}。
- 从 A 类中的 S、A、C 顶点出发,到达 B 类顶点的边有 S-C、A-B、C-B、C-D,其中 C-D 边的权值最小,所以选择 C-D 组成最小生成树,将顶点 D 从 B 类移到 A 类,A = {S, A, C, D},B = {B, T}。

- 从 A 类中的 S、A、C、D 顶点出发,到达 B 类顶点的边有 A-B、C-B、D-B、D-T,其中 D-B 和 D-T 的权值最小,任选其中的一个,例如选择 D-B 组成最小生成树,将顶点 B 从 B 类移到 A 类,A = {S, A, C, D, B},B = {T}。
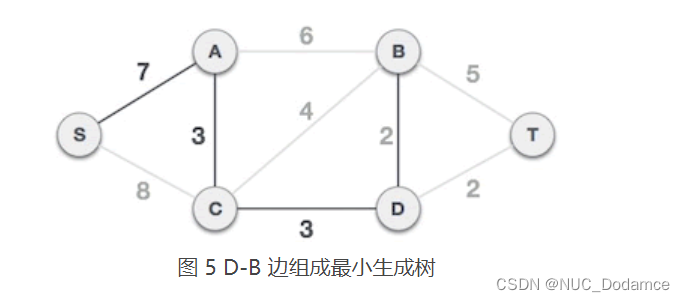
- 从 A 类中的 S、A、C、D、B 顶点出发,到达 B 类顶点的边有 B-T、D-T,其中 D-T 的权值最小,选择 D-T 组成最小生成树,将顶点 T 从 B 类移到 A 类,A = {S, A, C, D, B, T},B = {}。
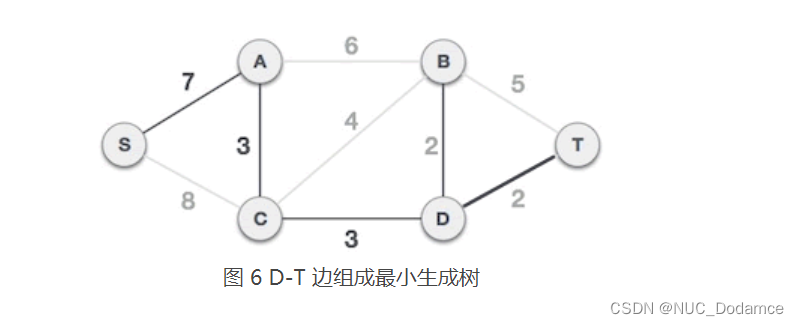
综上,使用Prim算法可以得出最小生成树为:
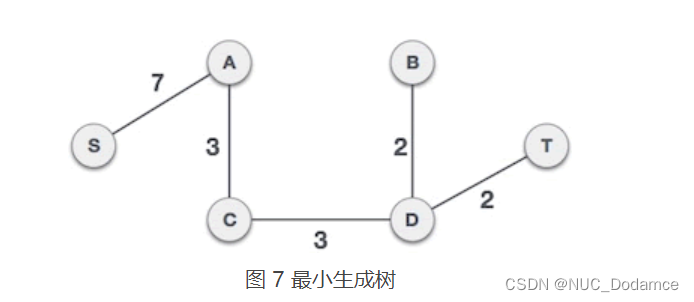
C++代码实现
通过上面的流程图分析可知,这个算法不需要并查集来判断是否成环。
但是这里处理时使用优先级队列,因为优先级队列开始时把顶点周围的所有边添加进去,而优先级队列又不支持指定删除元素。所以当优先级队列弹出最小权值边的时候,还需要判断这条边的两个顶点是不是在同一个数组,如果在同一个数组,说明这条边构成环。
在书写代码时,只要记得不要构成环即可,剩下步骤按照流程图走即可
无向图,邻接矩阵,Prim算法
// 邻接矩阵法存储图结构
#include <iostream>
#include <assert.h>
#include <map>
#include <vector>
#include <stdio.h>
#include <queue>
// v:图顶点保存的值。w:边的权值 max:最大权值,代表无穷。flag=true代表有向图。否则就是无向图
template <class v, class w, w max = INT_MAX, bool flag = false>
class graph
{
private:
std::vector<v> _verPoint; // 顶点集合
std::map<v, int> _indexMap; // 顶点与下标的映射
std::vector<std::vector<w>> _matrix; // 邻接矩阵
int _getPosPoint(const v &point)
{
if (_indexMap.find(point) != _indexMap.end())
{
return _indexMap[point];
}
else
{
std::cout << point << " not found" << std::endl;
return -1;
}
}
public:
graph() = default;
// 根据数组来开辟邻接矩阵
graph(const std::vector<v> &src)
{
_verPoint.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_verPoint[i] = src[i];
_indexMap[src[i]] = i;
}
// 初始化邻接矩阵
_matrix.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_matrix[i].resize(src.size(), max);
}
}
// 添加边的关系,输入两个点,以及这两个点连线边的权值。
void AddEdge(const v &pointA, const v &pointB, const w &weight)
{
// 获取这个顶点在邻接矩阵中的下标
int posA = _getPosPoint(pointA);
int posB = _getPosPoint(pointB);
_matrix[posA][posB] = weight;
if (!flag)
{
// 无向图,邻接矩阵对称
_matrix[posB][posA] = weight;
}
}
// 打印邻接矩阵
void PrintGraph()
{
// 打印顶点对应的坐标
typename std::map<v, int>::iterator pos = _indexMap.begin();
while (pos != _indexMap.end())
{
std::cout << pos->first << ":" << pos->second << std::endl;
pos++;
}
std::cout << std::endl;
// 打印边
printf(" ");
for (int i = 0; i < _verPoint.size(); i++)
{
std::cout << _verPoint[i] << " ";
}
printf("\n");
for (int i = 0; i < _matrix.size(); i++)
{
std::cout << _verPoint[i] << " ";
for (int j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] == max)
{
// 这条边不通
printf("∞ ");
}
else
{
std::cout << _matrix[i][j] << " ";
}
}
printf("\n");
}
printf("\n");
}
// -------------------------------------Prim--------------------------------------------
typedef graph<v, w, max, flag> self;
// 代表图的一条边
struct edge
{
size_t src;
size_t dst;
w weight;
edge(size_t _src, size_t _dst, w _weight)
{
this->src = _src;
this->dst = _dst;
this->weight = _weight;
}
};
// 小堆排序规则,从小到打排序
struct rules
{
bool operator()(const edge &left, const edge &right)
{
return left.weight > right.weight;
}
};
// 最小生成树,返回最小生成树权值,传入一个图,这个参数是输入输出参数,函数结束后,minTree是图的最小生成树
// src:Prim算法传入的起始点
w Prim(self &minGraph, const v &src)
{
size_t pos = _getPosPoint(src);
// 初始化minTree
minGraph._verPoint = _verPoint;
minGraph._indexMap = _indexMap;
size_t size = _verPoint.size();
minGraph._matrix.resize(size);
for (size_t i = 0; i < size; i++)
{
minGraph._matrix[i].resize(size, max);
}
std::vector<bool> A(size, false); // 已经加入的顶点的集合
std::vector<bool> B(size, true); // 未加入的顶点的集合
A[pos] = true;
B[pos] = false;
// 从两个集合中选择两个点,构成权值最小的边
std::priority_queue<edge, std::vector<edge>, rules> queue;
// 将这个点连接的周围的点入队列
for (int i = 0; i < size; i++)
{
if (_matrix[pos][i] != max)
{
queue.push(edge(pos, i, _matrix[pos][i]));
}
}
// 选择权值最小的边
size_t dstSize = 0;
w total = w();
while (!queue.empty())
{
edge minEdge = queue.top();
queue.pop();
// 如果这条边的两个点都在同一个集合中,那么说明构成环
if (A[minEdge.dst])
{
// 构成环
continue;
}
// DEBUG:
//std::cout << minEdge.src << "->" << minEdge.dst << " 权值:" << minEdge.weight << "\n";
minGraph.AddEdge(_verPoint[minEdge.src], _verPoint[minEdge.dst], minEdge.weight);
A[minEdge.dst] = true;
B[minEdge.dst] = false;
dstSize += 1;
total += minEdge.weight;
if (dstSize == size - 1)
{
// size个点选了size-1条边,已经结束了
break;
}
// 将minEdge.dst这个点周围的边(除了minEdge.dst->minEdge.src这条边)入队列,同时保证不构成环
for (size_t i = 0; i < size; i++)
{
if (_matrix[minEdge.dst][i] != max && A[i] == false)
{
queue.push(edge(minEdge.dst, i, _matrix[minEdge.dst][i]));
}
}
}
if (dstSize != size - 1)
{
// 没有找到生成树
std::cout << "没有找到生成树" << std::endl;
return w();
}
return total;
}
};
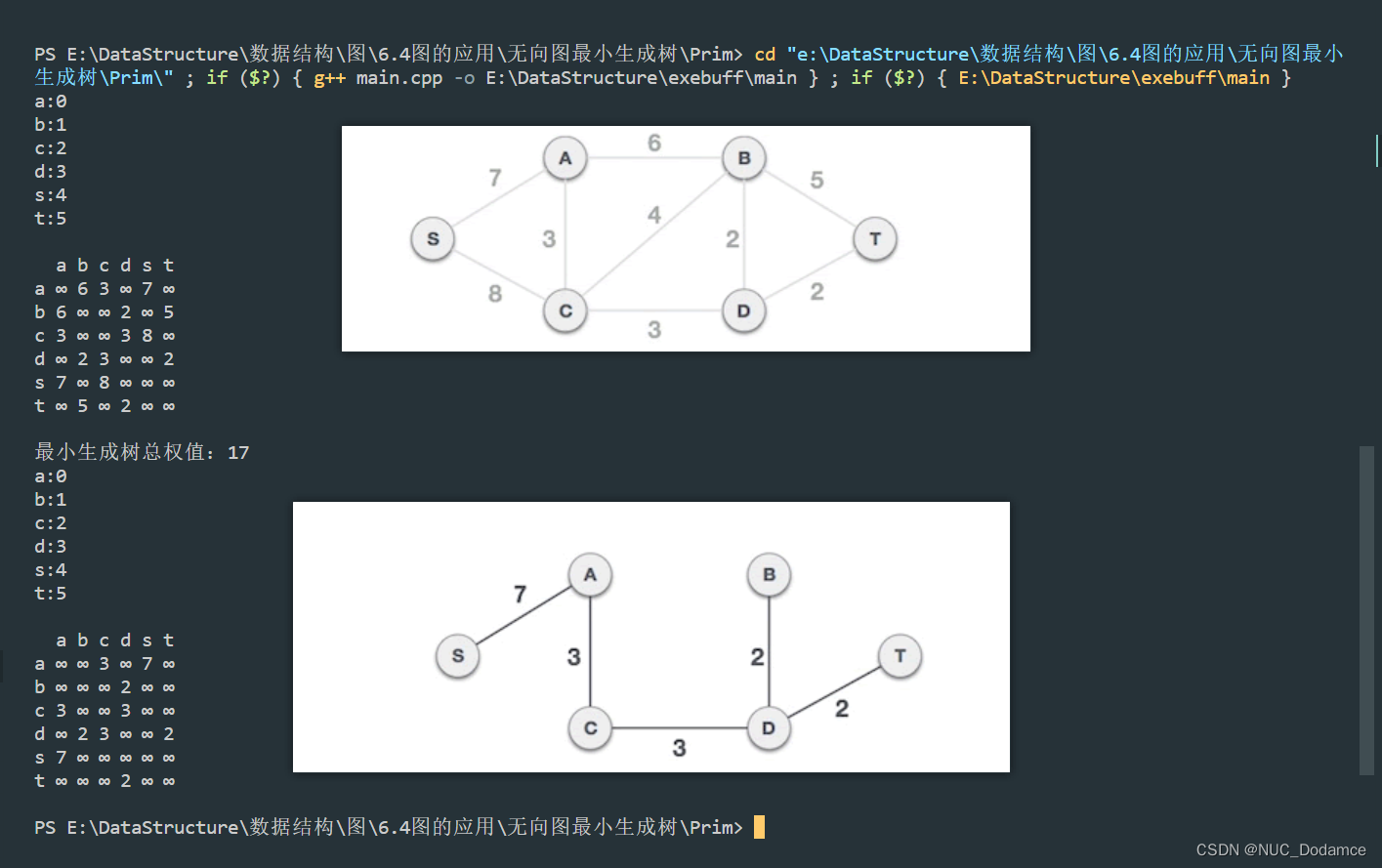
测试代码和结果
#include "matrix.h"
using namespace std;
int main(int argc, char const *argv[])
{
vector<char> vet = {'a', 'b', 'c', 'd', 's', 't'};
graph<char, int> Graph(vet);
Graph.AddEdge('a', 'b', 6);
Graph.AddEdge('b', 't', 5);
Graph.AddEdge('t', 'd', 2);
Graph.AddEdge('d', 'c', 3);
Graph.AddEdge('c', 's', 8);
Graph.AddEdge('s', 'a', 7);
Graph.AddEdge('c', 'a', 3);
Graph.AddEdge('c', 's', 8);
Graph.AddEdge('b', 'd', 2);
Graph.PrintGraph();
graph<char, int> minGraph;
cout << "最小生成树总权值:" << Graph.Prim(minGraph, 's') << endl;
minGraph.PrintGraph();
return 0;
}