1、什么是索引?
索引是存储引擎用于提高数据库表的访问速度的一种数据结构。通过给字段添加索引可以提高数据的读取速度,提高项目的并发能力和抗压能力。索引优化时mysql中的一种优化方式。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容
2、索引的作用
数据是存储在磁盘上的,查询数据时,如果没有索引,会加载所有的数据到内存,依次进行检索,读取磁盘次数较多。有了索引,就不需要加载所有数据,因为B+树的高度一般在2-4层,最多只需要读取2-4次磁盘,查询速度大大提升。
3、索引的优缺点
优点:
- 加快数据查找的速度
- 为用来搜索、排序或者是分组的字段添加索引,可以加快搜索、分组和排序的速度
- 加快表与表之间的连接
缺点:
- 建立索引需要占用物理空间
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长。
4、索引类型有哪些?如何创建索引?
按字段特性分类,MySQL索引按字段特性分类主要分为以下四种:
- 主键索引(PRIMARY KEY)
- 唯一索引(UNIQUE)
- 普通索引(INDEX)
- 全文索引(FULLTE)
按字段数量还有 联合索引(也叫复合索引、组合索引)
主键索引(PRIMARY KEY)
建立在主键上的索引被称为主键索引,一张数据表只能有一个主键索引,索引列值不允许有空值,通常在创建表时一起创建。 主键是一种唯一性索引,必须指定为PRIMARY KEY。
# 修改表时创建
ALTER TABLE tablename ADD PRIMARY KEY(`id`);
#创建表时直接指定
CREATE TABLE `tablename` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
PRIMARY KEY (`id`)
);唯一索引(UNIQUE)
建立在UNIQUE字段上的索引被称为唯一索引,一张表可以有多个唯一索引,索引列值允许为空,列值中出现多个空值不会发生重复冲突,如果是组合索引,则列值的组合必须唯一。
# 指定了索引名称为realname_index,如果不指定默认就是此字段名
ALTER TABLE table_name ADD UNIQUE INDEX `realname_index`(`realname`);
# 创建表时直接指定
CREATE TABLE `tablename` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`realname` varchar(20) NOT NULL ,
UNIQUE realname_index (`realname`)) ,
PRIMARY KEY (`id`)
);普通索引(INDEX)
建立在普通字段上的索引被称为普通索引,是最基本的索引,它没有任何限制。
# 修改表时创建
ALTER TABLE tablename ADD INDEX index_age (`age`);
# 直接创建索引
CREATE INDEX index_age ON tablename(`age`);
# 创建表时直接创建
CREATE TABLE `tablename`(
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`user_id` INT(11),
`realname` VARCHAR(20),
`age` INT(3),
PRIMARY KEY(`id`), -- 直接创建主键索引
UNIQUE index_realname (`realname`) , -- 直接创建唯一索引
INDEX index_age(`age`) -- 直接创建普通索引
) ENGINE=INNODB CHARSET=utf8mb4;
全文索引(FULLTEXT)
主要用于查找文本中的关键字,而不是直接比较是否相等,Full-text索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
- 可以通过create table,alter table ,create index创建
- 目前只有char、varchar,text 列上可以创建全文索引
- 对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。
- MyISAM支持全文索引,InnoDB在mysql5.6之后支持了全文索引。
- fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like
- 全文索引不支持中文需要借sphinx(coreseek)或迅搜<、code>技术处理中文。
# 修改表结构添加全文索引
ALTER TABLE tablename ADD FULLTEXT index_sheng(`sheng`);
# 直接创建全文索引
CREATE FULLTEXT INDEX index_sheng ON tablename(`sheng`);
# 创建表的时候创建全文索引
CREATE TABLE `tablename`(
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`user_id` INT(11),
`realname` VARCHAR(20),
`age` INT(3),
`sheng` varchar(30),
PRIMARY KEY(`id`), -- 直接创建主键索引
UNIQUE index_realname (`realname`) , -- 直接创建唯一索引
INDEX index_age (`age`) , -- 直接创建普通索引
fulltext (`sheng`) -- 直接创建全文索引
) ENGINE=INNODB CHARSET=utf8mb4;联合索引 (复合索引、组合索引)
建立在多个列上的索引被称为联合索引,又叫复合索引、组合索引。在MySQL中使用联合索引时要遵循最左前缀匹配原则。所以我们需要注意如下几个方面:
- 实际业务场景中创建联合索引时,我们应该把识别度比较高的字段放在前面,提高索引的命中率,充分的利用索引。
- 创建联合索引后,该索引的任何最左前缀都可以用于查询。比如当你有一个联合索引(col1, col2, col3),该索引的所有最左前缀为(col1)、(col1, col2)、(col1, col2, col3),包含这些列的所有查询都会使用该索引进行查询。
- 虽然联合索引可以避免回表查询,提高查询速度,但同时也会降低表数据更新的速度。因为联合索引列更新时,MySQL不仅要保存数据,还要维护一下索引文件。所以不要盲目使用,应根据业务需求来创建。
# 修改表结构添加联合索引
ALTER TABLE `tablename_two` ADD INDEX `index_sheng_shi_xian` (`sheng`, `shi`, `xian`);
ALTER TABLE `tablename_two` ADD UNIQUE INDEX `index_sheng_shi_xian` (`sheng`,`shi`, `xian`);
# 触发此索引的查询遵循最左原则
-- 如上最左边的一个字段是sheng, 下面的查询中只有包含sheng字段的查询都会触发。
-- 以下查询都会触发此索引
EXPLAIN SELECT * FROM `tablename` WHERE sheng = '山东省';
EXPLAIN SELECT * FROM `tablename` WHERE sheng = '山东省' AND shi = '菏泽市';
EXPLAIN SELECT * FROM `tablename` WHERE sheng = '山东省' AND shi = '菏泽市' AND xian = '牡丹区';
EXPLAIN SELECT * FROM `tablename` WHERE sheng = '山东省' AND xian = '牡丹区';
EXPLAIN SELECT * FROM `tablename` WHERE xian = '牡丹区' AND sheng = '山东省'; -- 与sheng的查询位置无关,
-- 以下语句不触发,因为没有包含sheng字段的查询
EXPLAIN SELECT * FROM `tablename` WHERE shi = '菏泽市' AND xian = '牡丹区'; -- 不触发
5、如何查看表的所有索引
SHOW INDEXES FROM `表名`;
-- 或
SHOW KEYS FROM `表名`;
-- 查看索引的使用情况
SHOW STATUS LIKE '%Handler_read%';
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效6、如何删除索引
DROP INDEX `索引名` ON `表名`;
-- 或
ALTER TABLE `表名` DROP INDEX `索引名`;7、如何判断索引是否生效?
答:在查询语句前使用Explain。
explain函数作用:显示了MYSQL如何使用索引来处理select语句以及连接表。
EXPLAIN SELECT * FROM 表名 WHERE sheng = '山东省';
-- 或者 group by 也会触发索引
EXPLAIN SELECT * FROM 表名 GROUP BY sheng;Explain 返回的参数如图: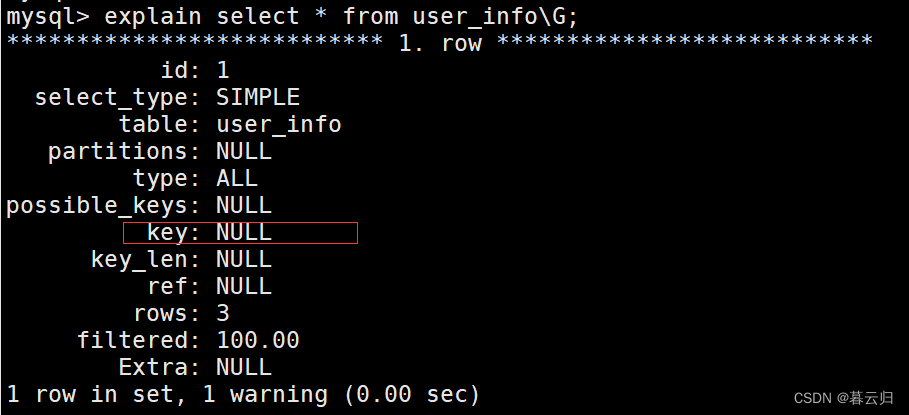 key字段为null表示未触发索引,有值的未启用的索引。
key字段为null表示未触发索引,有值的未启用的索引。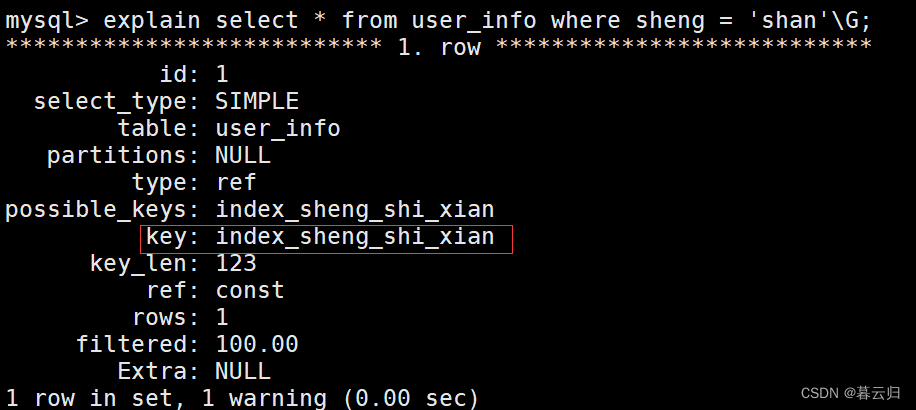
Explain 函数返回的参数如下:
8、哪些情况下索引无效
- where 子句中使用 != 或 <> 或 not in 操作符,引擎将放弃使用索引而进行全表扫描。特别地,如果是主键 如 where id > 10 ,这种情况也会走索引。
- where 子句中使用 or 来连接条件,or前后条件都包含索引则走索引,or前后只要有一个不包含索引索引失效。
- like的模糊查询以 % 开头,索引失效, 如 where title like '%abc' 、where title like '%abc%' 都会导致索引失效,但是 where title like 'abc%' 索引有效 。
- 特别的like查询,如果是全覆盖索引,即便是 ‘%abc%’ 也会走索引。 如select * from 表名 where realname like '%abc%' 不走索引, 如果是 select id, realname from 表名 where realname like '%abc%' 这时就走索引了,(附:索引包含所有满足查询需要的数据的索引,称为覆盖索引(Covering Index)。)
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引,如realname字段是varchar 类型,里面有个123的值,我们使用 where realname = 123 也能擦到数据,但是不会触发索引, 必须使用 where realname = '123'才能使用索引。
- 在 where 子句中对字段进行表达式操作,导致引擎放弃使用索引而进行全表扫描。
- 在 where 子句中对字段进行函数操作,导致引擎放弃使用索引而进行全表扫描。
- 在 where 子句中的 “=” 左边进行函数、算术运算或其他表达式运算,导致系统将可能无法正确使用索引,函数包括ABS,UPPER,DATE,DAY,YEAR等
- 对于多列索引,不是使用的一部分,则不会使用索引。
- 不适合键值较少的列(重复数据较多的列)。
- 字段内容为null,导致索引失效。索引字段上使用is null, is not null,可能导致索引失效
- mysql估计使用全表扫描要比使用索引快,则不使用索引
9、 在什么情况下建立索引
- 在where查询中经常作为查询条件的字段做索引。
- 该字段的内容不是唯一的几个值,如性别字段通常只有男、女两个值,不适合使用索引。
- 字段内容不是频繁变化的字段适合做索引,更新非常频繁的字段 不适合作为索引
- 不会出现在where子句中的字段不该创建索引
10、为什么我们添加完索引后查询速度为变快?
传统的查询方法,是按照表的顺序遍历的,不论查询几条数据,mysql需要将表的数据从头到尾遍历一遍。在我们添加完索引之后,mysql一般通过BTREE算法生成一个索引文件,在查询数据库时,找到索引文件进行遍历(折半查找大幅查询效率),找到相应的键从而获取数据
11、索引的代价
创建索引是为产生索引文件的,占用磁盘空间。索引文件是一个二叉树类型的文件,可想而知我们的dml操作同样也会对索引文件进行修改,所以性能会下降
12、唯一索引比普通索引快吗, 为什么?
唯一索引不一定比普通索引快, 还可能慢。
查询时, 在未使用limit 1的情况下, 在匹配到一条数据后, 唯一索引即返回, 普通索引会继续匹配下一条数据, 发现不匹配后返回. 如此看来唯一索引少了一次匹配, 但实际上这个消耗微乎其微.
更新时, 这个情况就比较复杂了. 普通索引将记录放到change buffer中语句就执行完毕了. 而对唯一索引而言, 它必须要校验唯一性, 因此, 必须将数据页读入内存确定没有冲突, 然后才能继续操作. 对于写多读少的情况, 普通索引利用change buffer有效减少了对磁盘的访问次数, 因此普通索引性能要高于唯一索引。
13、MySQL 索引使用有哪些注意事项?
可以从三个维度回答这个问题:索引哪些情况会失效,索引不适合哪些场景,索引规则
索引哪些情况会失效:
- 查询条件包含or,可能导致索引失效
- 如果字段类型是字符串,where时一定用引号括起来,否则索引失效
- like通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效
- 在索引列上使用mysql的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql估计使用全表扫描要比使用索引快,则不使用索引。
- 后端程序员必备:索引失效的十大杂症
索引不适合哪些场景
-
数据量少的不适合加索引。
-
更新比较频繁的也不适合加索引
-
区分度低的字段不适合加索引(如性别)
索引的一些潜规则
- 覆盖索引
- 回表
- 索引数据结构(B+树)
- 最左前缀原则
- 索引下推
14、索引的数据结构有哪些?
索引的数据结构主要有B+树和 哈希表,对应的索引分别为B+树索引和哈希索引。InnoDB引擎的索引类型有B+树索引和哈希索引,默认的索引类型为B+树索引。
B+树索引(BTREE)
B+ 树是基于B 树和叶子节点顺序访问指针进行实现,它具有B树的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ 树中,节点中的 key 从左到右递增排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
进行查找操作时,首先在根节点进行二分查找,找到key所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出key所对应的数据项。MySQL 数据库使用最多的索引类型是BTREE索引,底层基于B+树数据结构来实现。
哈希索引
哈希索引是基于哈希表实现的,对于每一行数据,存储引擎会对索引列进行哈希计算得到哈希码,并且哈希算法要尽量保证不同的列值计算出的哈希码值是不同的,将哈希码的值作为哈希表的key值,将指向数据行的指针作为哈希表的value值。这样查找一个数据的时间复杂度就是O(1),一般多用于精确查找。
15、Hash索引和B+树索引的区别?
- 哈希索引不支持排序,因为哈希表是无序的。
- 哈希索引不支持范围查找。
- 哈希索引不支持模糊查询及多列索引的最左前缀匹配。
- 因为哈希表中会存在哈希冲突,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。