
欢迎来到【微直播间】,2min纵览大咖观点
随着企业数据量的不断增加,为了提高深度学习训练的准确性、加快速度并且降低成本,许多企业开始逐步在云上实施分布式训练的方案,本期内容将结合阿里、微软等实际应用案例,分享如何通过Alluxio加速云上深度学习。
内容主要围绕两个部分展开:
内容概要:
Alluxio及其POSIX API简介
>> Alluxio是一个java开源项目,是云上的关于数据分析以及深度学习训练的一个数据抽象层。
>> 使用Alluxio,可以对数据应用以及数据源进行无缝连接。
>> Alluxio的一个很重要功能是能够对数据进行读写缓存,另一方面也可以对元数据进行本地缓存。
>> Alluxio可以把来自不同的远端存储系统,以及分布式文件系统的数据都挂载到Alluxio统一的命名空间之内。通过Alluxio POSIX API,把这些数据变成类似于本地文件的形式,提供给各种训练任务。
使用Alluxio加速云上训练
Level 1 读取缓存与加速:直接通过Alluxio来加速对底层存储系统中的数据访问。
Level 2 数据预处理和训练:之所以有二级玩法,主要因为一级玩法有一些先决条件,要么数据已经处理好就放在存储系统中,要么训练脚本已经包含了数据预处理的步骤,数据预处理与训练同时进行,而我们发现在很多用户场景中,并不具备这些条件。
Level 3 数据抽象层:把Alluxio作为整个数据的抽象层。
以上仅为大咖演讲概览,完整内容点击视频观看

附件:大咖分享文字版完整内容可见下文

Alluxio及其POSIX API简介

Alluxio是一个java开源项目,是云上的关于数据分析以及深度学习训练的一个数据抽象层。在Alluxio之上可以对接不同的数据应用,包括Spark、Flink这种ETL工具,Presto这种query工具,以及TensorFlow、PyTorch等深度学习框架。在Alluxio下面也可以连接不同数据源,比如阿里云、腾讯云、HDFS等。

使用Alluxio,可以对数据应用以及数据源进行无缝连接,Alluxio负责处理与不同数据源以及不同系统的对接。
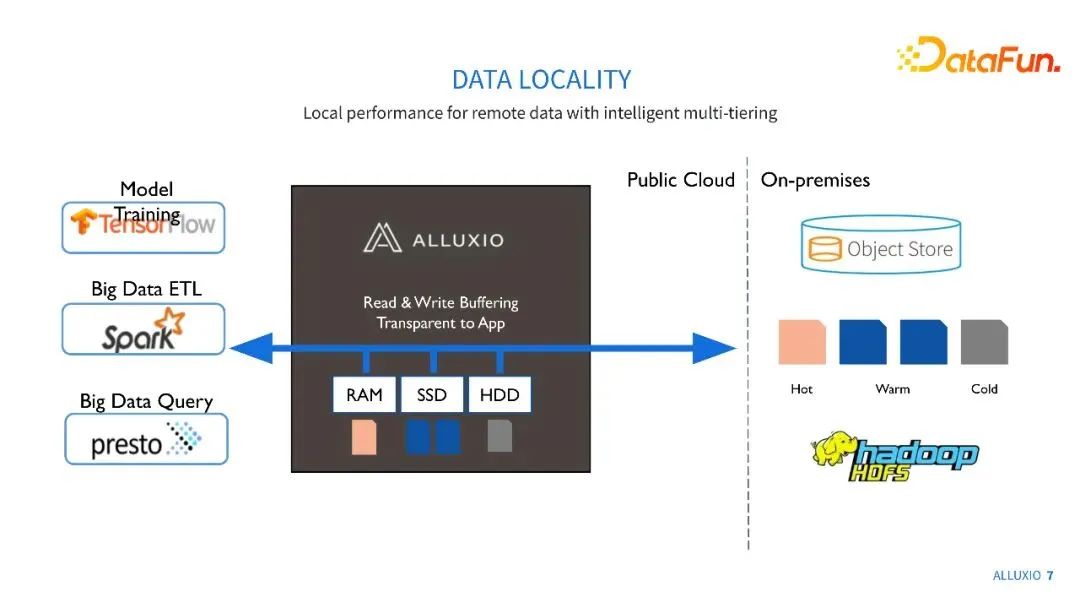
Alluxio的一个很重要功能是能够对数据进行读写缓存。大家可能很多数据是在云存储上,或者是在远端的HDFS和Ceph集群上,如果每一次的数据应用都要去远端不断重复地拿同样的数据,那么整个拿数据的流程是非常耗时的,而且可能会导致我们整体训练或数据处理效率不高。通过Alluxio,我们可以把一些热数据在靠近数据应用的集群进行缓存,从而提升重复数据获取的性能。
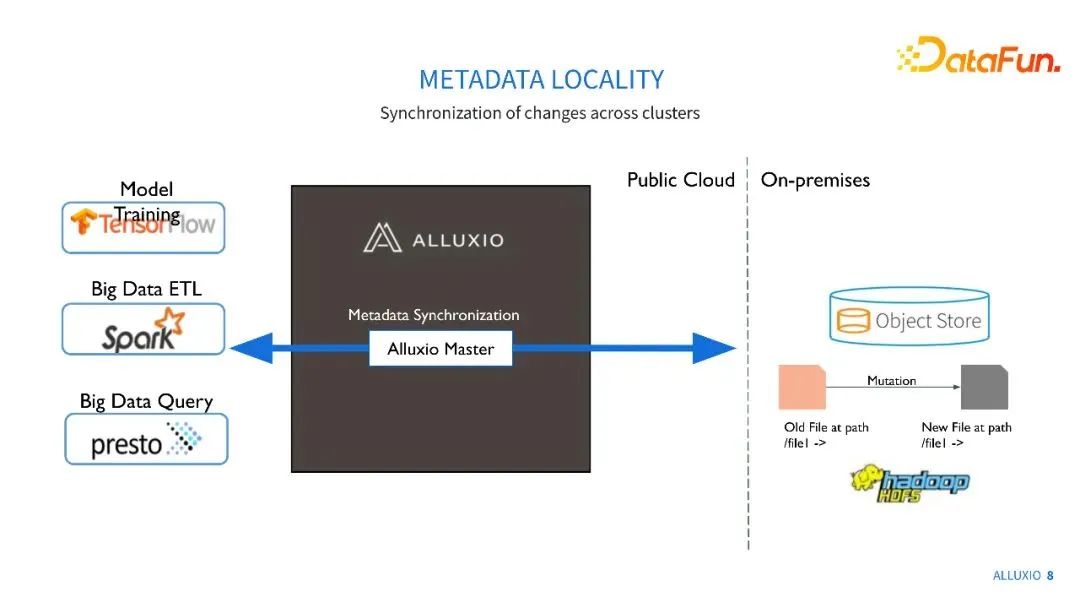
另一方面,我们也可以对元数据进行本地缓存。每一次获取元数据都要通过网络去获取是比较慢的。如果通过Alluxio,可以直接从本地集群获取元数据,延时会大大缩短。同时,模型训练的元数据需求是非常高压的,我们在与蚂蚁金服的实验中,可以看到成千上万QPS,如果全部压力都压到存储系统中,存储系统可能会不稳定,或进行一定的限流处理,导致一些读取错误。通过Alluxio可以很好地分担这部分元数据的压力。
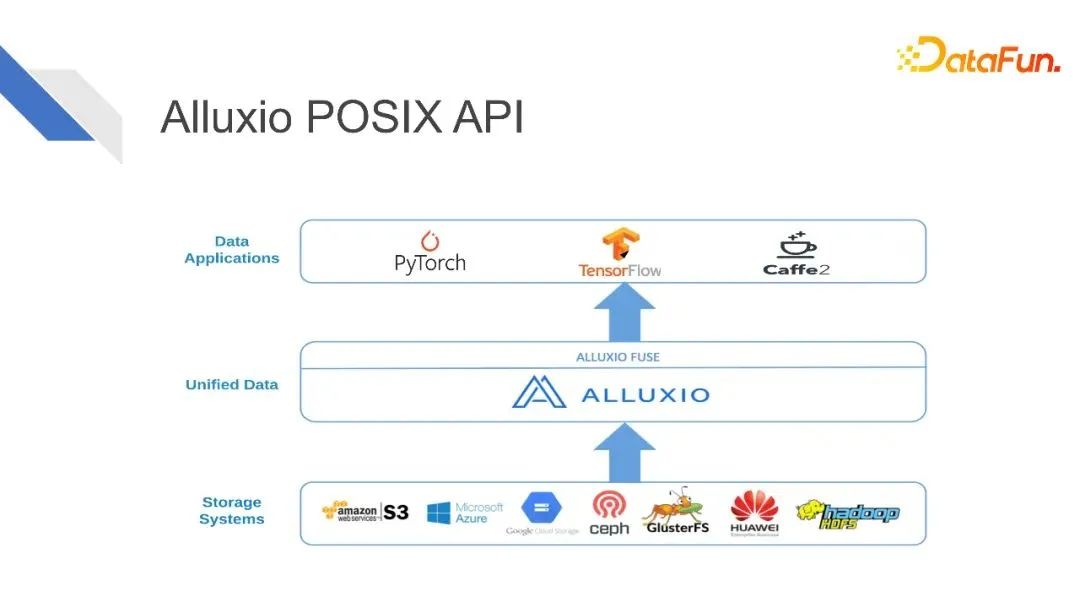
接下来重点讲解一下Alluxio的POSIX API。
深度学习训练框架PyTorch、TensorFlow、Caffe,它们的原生数据源都是本地文件系统。企业数据量日益扩大,导致我们需要去使用分布式数据源。Alluxio可以把来自不同的远端存储系统,以及分布式文件系统的数据都挂载到Alluxio统一的命名空间之内。通过Alluxio POSIX API,把这些数据变成类似于本地文件的形式,提供给各种训练任务。

上图直观地展现了Alluxio POSIX API把远端的分布式数据变成了本地文件夹的形式。
使用Alluxio加速云上训练
下面来具体讲解如何使用Alluxio来加速云上训练。
Level 1 读取缓存与加速
一级玩法比较简单,就是直接通过Alluxio来加速对底层存储系统中的数据访问。

如上图示例,我们有一些数据存储在我们的存储系统中,它可能是已经经过数据预处理的数据,也可能是一些原始数据。我们的训练在云上的K8s集群上,与数据源之间存在一定的地理差异,获取数据存在延时。我们的训练需要重复去获取同样的数据源,在这种情况下,使用Alluxio集群,在靠近训练的集群内进行数据的缓存可以极大地提升我们获取数据的性能。
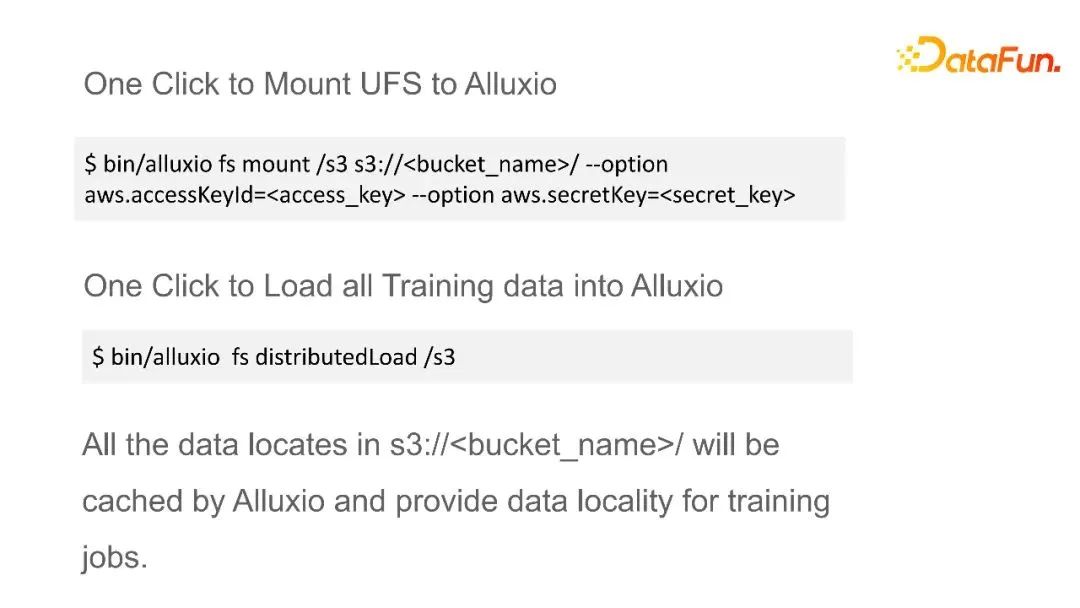
可以用简单的命令来设置数据源,以及一些安全参数,让Alluxio可以去访问这些数据源。提供了数据源地址以及安全参数之后,就可以把它挂载到Alluxio命名空间内的一个文件夹目录下面。挂载后,可以用一个命令来把所有的数据都一键地分布式加载到Alluxio当中,这样所有数据都会进行分布式的缓存,为我们的训练任务提供本地数据性能。

上图是阿里巴巴进行的一个实测,如果他们的训练通过oss Fuse直接去访问阿里云存储,整个性能可能是几百兆每秒,而通过Alluxio进行缓存后,可以达到千兆每秒。

在Microsoft,他们的场景是:训练数据全部存在Microsoft Azure里面,有超过400个任务需要从Azure读数据,并写回到Azure中。这400个任务会涉及到上千个节点,而他们的训练数据又是比较统一的。在使用Alluxio之前,他们的方案是把一份数据从Azure中不停地拷贝到上千台机器上。整个过程耗时大,并且由于任务量太大了,常常会导致Azure对他们的数据请求进行限流处理,从而导致下载失败,还要人工去恢复下载。通过使用Alluxio之后,Alluxio可以从Azure拿取一份数据,然后同样的一份数据可以供给不同的训练任务以及不同的机器,这样load一次数据,就可以进行多次读取。

在使用Alluxio之后,训练任务无需等待数据完全下载到本地就可以开始训练了。训练结束之后,也可以通过Alluxio直接写回到Azure。整个流程非常方便,并且gpu的使用率比较稳定。
Level 2 数据预处理和训练
接下来看二级玩法。之所以会有二级玩法,主要是因为一级玩法有一些先决条件,要么数据已经处理好就放在你的存储系统中,要么你的训练脚本已经包含了数据预处理的步骤,数据预处理与训练同时进行,然而我们发现在很多用户场景中,并不具备这些条件。
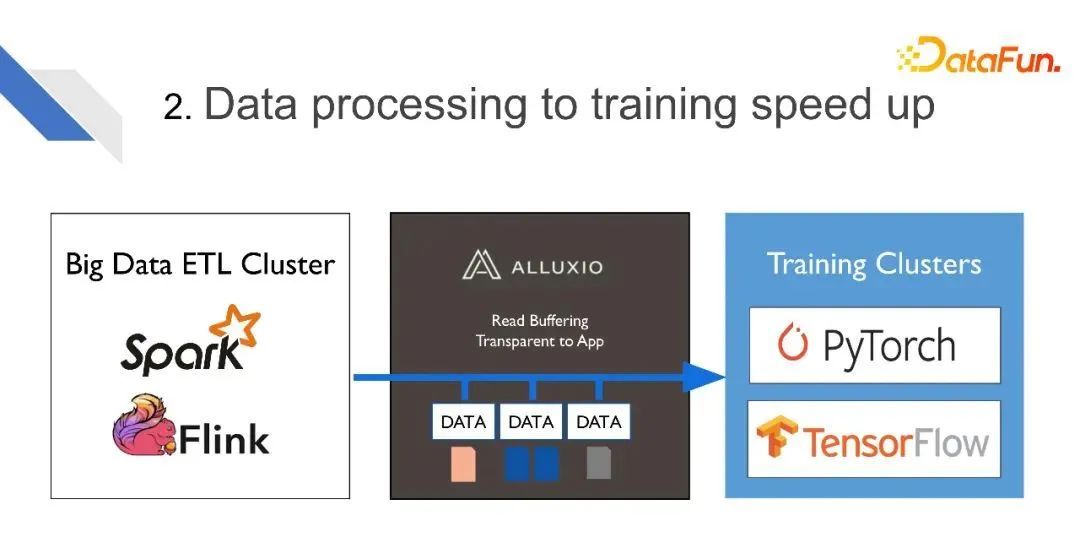
在很多用户的场景里,他们需要用其它方式来先对数据进行预处理,然后这部分预处理后的数据才能供给训练。比如会用Spark、Flink等大数据ETL工具来进行数据预处理,处理好的数据写到Alluxio,之后由Alluxio供给给训练集群。同时,对这部分数据可以进行备份、加速,来更快地提供给训练集群。

我们通过一个具体案例来了解这个流程。
在BOSS直聘,他们有两个任务,首先是用Spark/Flink来对数据进行预处理,之后再对这部分预处理好的数据进行模型训练。所有的中间结果和最后处理好的数据,都直接持久化到Ceph上,再由Ceph为模型训练提供数据。把中间处理结果也放到Ceph中,会给Ceph增加很多的压力。高压的模型训练给Ceph造成很大压力。当ETL工作以及训练多的时候,Ceph非常不稳定,整体性能受到影响。他们的解决办法就是把Alluxio加到Spark/Flink和模型训练之间。

Spark/Flink把中间结果写到Alluxio之中,由Alluxio来提供给模型训练。Alluxio在背后异步地把这部分数据持久化到Ceph中,以保证这些预处理好的数据不会丢失。所以无论我们的数据源是在本地还是远端,即使数据持久化的速度比较慢,也不影响我们的训练流程。并且Alluxio可以是一些单独的集群,如果ETL或training任务多的时候,可以起更多的Alluxio cluster来分担这些任务,也可以对不同的Alluxio集群进行资源分配、读写限额、权限控制等。

这个流程可以提升存储系统的稳定性,同时加速从数据预处理到训练的整个流程,并且可以用更多的Alluxio集群来应对更多的ETL或训练需求。

我们发现大家会有不同的数据预处理方式。有些用户用C++、python程序来进行数据清理、转换等数据预处理。他们使用Alluxio把原始数据从底层存储系统中加载到Alluxio的缓存内,由Alluxio提供这部分数据预处理的框架,处理好的结果再写回到Alluxio当中,模型训练就可以用这部分预处理好的数据进行训练。
Level 3 数据抽象层
Alluxio的三级玩法,就是把Alluxio作为整个数据的抽象层。

整个训练集群,不管它需要的数据源来自何方,来自一些存储系统,由大数据ETL处理好的数据,或者是C++、python处理好的数据,都可以通过Alluxio进行读缓存,供给给训练。

另一方面,所有数据预处理的中间数据,以及训练的中间数据,都可以通过Alluxio进行暂时的写缓存。对于数据预处理和训练的结果,我们也可以通过Alluxio持久化到不同的存储系统之中。
不管大家有什么样的数据应用,都可以通过Alluxio来对不同的数据源中的数据进行读写操作。

比如陌陌,有很多Alluxio集群,数千个节点,存储超过100TB的数据,服务于搜索以及训练任务,他们还在不断地开发新的应用场景。
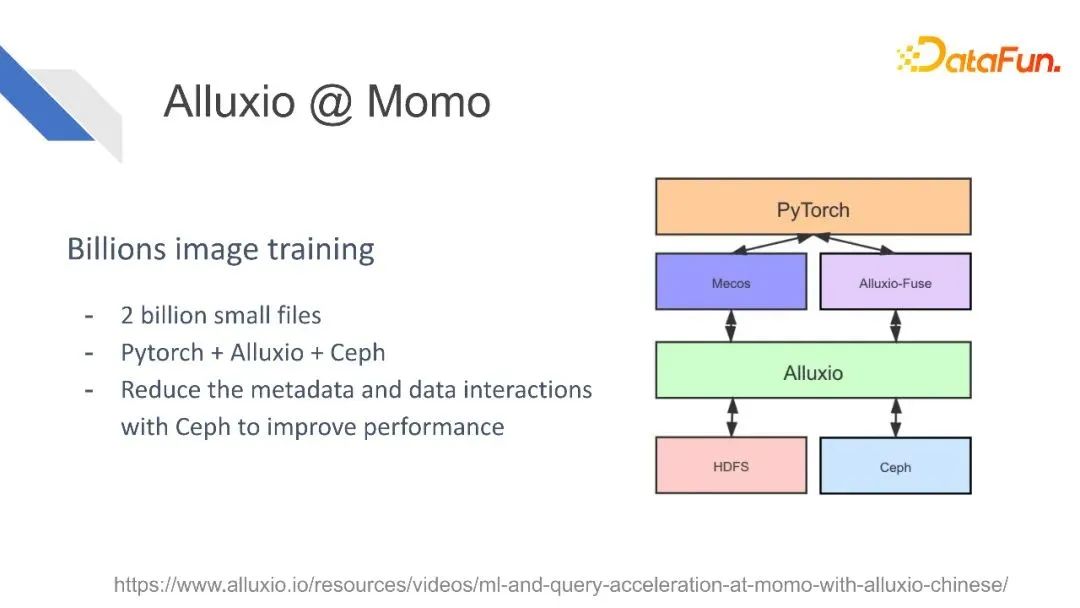
陌陌把Alluxio用作一个二十亿的小文件的训练。
他们使用Alluxio来加速推荐系统模型的加载,以及ANN系统index的加载。

总结一下,Alluxio可能在以下这些场景对企业有所助益:
- 想要进行分布式训练;
- 有大量的数据,可能无法在本地磁盘完整地存下来,或者有大量的小文件/小图片;
- 想要通过网络I/O直接去读取数据,但网络I/O性能无法满足GPU需求;
- 保证存储系统的稳定性,避免超出限额的情况;
- 在多个不同的训练任务中进行数据分享。
想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点击进入【Alluxio智库】:









![[笔记] - springboot-jpa 使用sqlite 踩坑](https://img-blog.csdnimg.cn/img_convert/08eef9009cc26c1611732509fb6b842f.png)