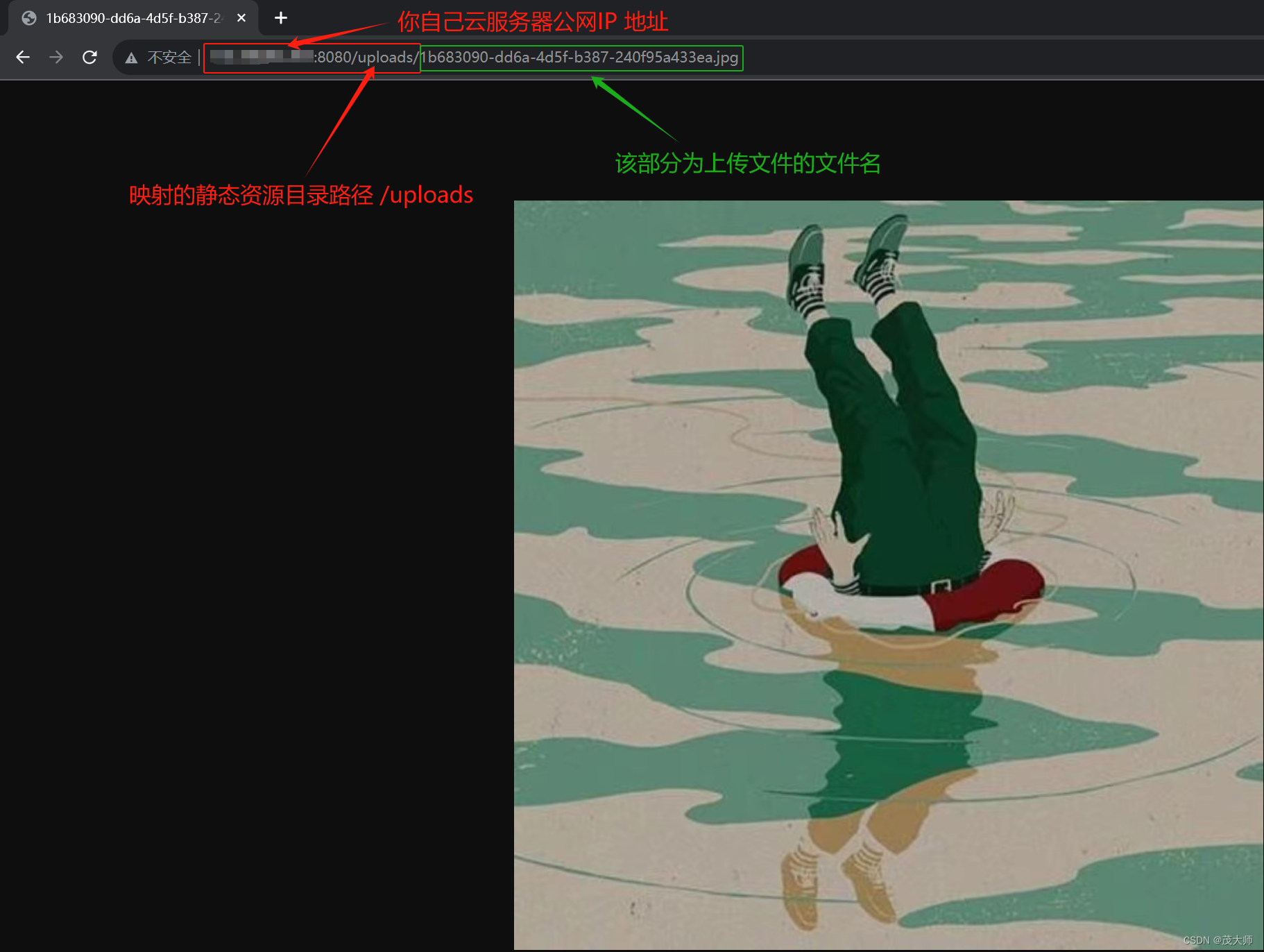
原创/朱季谦
一、HugeGraph-Hubble简介
关于HugeGraph,官方资料是这样介绍的,它是一款易用、高效、通用的开源图数据库系统(Graph Database), 实现了 Apache TinkerPop3 框架及完全兼容 Gremlin 查询语言, 具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。HugeGraph 支持百亿以上的顶点和边快速导入,并提供毫秒级的关联关系查询能力(OLTP), 并可与 Hadoop、Spark 等大数据平台集成以进行离线分析(OLAP)。
HugeGraph与其他图数据库系统一样都提供了一套前端展示工具。HugeGraph在0.10 server 版本之前,是通过HugeGraph-Studio提供的前端展示工具,只有一个页面用于来实现简单图操作。
在HugeGraph在0.10 server 版本之后,百度HugeGraph开始支持一套全新的Web图管理界面HugeGraph-Hubble,其功能相比之前的HugeGraph-Studio,可以说更加丰富,可以实现图管理、元数据建模、数据导入、图分析以及跑批操作,对于想要学习HugeGraph的同学,可以起到更好的帮助。

官网上,关于HugeGraph-Hubble是这样介绍的:HugeGraph-Hubble是HugeGraph的一站式可视化分析平台,平台涵盖了从数据建模,到数据快速导入,再到数据的在线、离线分析、以及图的统一管理的全过程,实现了图应用的全流程向导式操作,旨在提升用户的使用流畅度,降低用户的使用门槛,提供更为高效易用的使用体验。
相关的具体介绍,可以跳转至HugeGraph-Hubble官网详情——
很遗憾是,官网上并没有很详细地介绍如何搭建HugeGraph-Hubble集成到HugeGraph-Server中,我是根据之前的linux环境安装可操作图库语言Gremlin的图框架HugeGraph一文的搭建经验,来重新搭建HugeGraph-Hubble。
二、环境安装依赖版本
首先,是环境依赖,我选择的hadoop、hbase、hugegraph、hugegraph-hubble版本分别是——
| hadoop | hbase | hugegraph | hugegraph-hubble |
|---|---|---|---|
| 2.7.5 | 2.1.0 | 0.11.2 | 1.5.0 |
三、hugegraph服务部署文件参数
具体如何安装配置hugegraph的server端,请移步至我之前0.10.4版本的linux环境安装可操作图库语言Gremlin的图框架HugeGraph一文,整体相差不大,主要就修hugegraph安装目录里的hugegraph.properties和rest-server.properties两个文件。
1、rest-server.properties文件主要修改参数——
//图服务ip端口
restserver.url=http://192.168.200.153:8099
graphs=[hugegraph:conf/hugegraph.properties]
server.id=server-1
server.role=master
这里需要注意一点,该图服务端口http://192.168.200.153:8099将在后面的hugegraph-hubble进行图建立时用到。
2、hugegraph配置持久化
本文主要介绍Hbase做持久化与MySql做持久化——
2.1、Hbase持久化设置
hbase需要求版本 在2.0 以上,修改hugegraph.properties以下参数:
//hbase持久化存储
backend=hbase
//后端存储的序列化程序,可用值为[text、binary、cassandra、hbase、mysql],选hbase就用hbase
serializer=hbase
//hbase连接的zookeeper集群连接
hbase.hosts=192.168.200.130,192.168.200.131,192.168.200.132
//hbase连接的zookeeper接口
hbase.port=2181
//存储库名
store=hugegraph
其中,hbase.hosts与hbase.port的参数是对应了hbase设置zookeeper注册中心的参数,hbase的zookeeper集群配置在hbase-2.1.0/conf/hbase-site.xml文件里,我的是——
<configuration>
......
<property>
<name>hbase.master</name>
<value>master1</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.200.130:2181,192.168.200.131:2181,192.168.200.132:2181</value>
</property>
......
</configuration>
而hbase的master默认端口是16000,当hugeGraph这样配置hbase如以下的hosts和post参数后,它起到作用是,会到zookeeper集群注册中心的/hbase/master节点处获取需要连接的hbase的master地址,进而连接hbase,我的hbase的master是放在192.168.200.150机器上。
hbase.hosts=192.168.200.130,192.168.200.131,192.168.200.132
//hbase连接的zookeeper接口
hbase.port=2181
可以稍微验证一下,假如我启动了zookeeper集群,但是没有启动hbase集群,那么当hugeGraph启动进行数据操作时,会出现以下异常——
org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /hbase/master, details=, see https://s.apache.org/timeout
其中KeeperErrorCode = NoNode for /hbase/master,说明zookeeper没有/hbase/master这个节点,那就以为着,hugeGraph持久化连接到zookeeper,获取存储到/hbase/master的数据,那么,该数据是什么呢?
很遗憾,我这边直接通过zookeeper客户端去看,出现了乱码,但其他地方的中文又是正常的,因此,我怀疑,该节点数据估计是做了序列化,导致无法看到正常数据......
[zk: localhost:2181(CONNECTED) 21] get /hbase/master
�master:16000�o]7��#PBUF
master1�}�����/��
cZxid = 0x10000032a
ctime = Thu Dec 16 07:50:34 CST 2021
mZxid = 0x10000032a
mtime = Thu Dec 16 07:50:34 CST 2021
pZxid = 0x10000032a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x27db96bfb240022
dataLength = 56
numChildren = 0
可以换一种方式验证,我在启动hbase过程中,操作hugeGraph,然后看hugeGraph日志,这时已经可以连接到zookeeper了,但出现以下日志——
2021-12-16 07:49:53 3324377514 [grizzly-http-server-3] [WARN ] org.apache.hadoop.hbase.client.ConnectionImplementation [] - Checking master connection
org.apache.hadoop.hbase.ipc.FailedServerException: Call to master1/192.168.200.150:16000 failed on local exception: org.apache.hadoop.hbase.ipc.FailedServerException: This server is in the failed servers list: master1/192.168.200.150:16000
其中,This server is in the failed servers list: master1/192.168.200.150:16000,说明最后hugeGraph是通过zookeeper拿到了hbase的master地址master1/192.168.200.150:16000,然后去连接hbase,但hbase正在启动中,故而还连接不到,后面有一条日志是连接到,但hbase的master正在启动的提示——
org.apache.hadoop.hbase.client.RpcRetryingCallerImpl [] - Call exception, tries=10, retries=16, started=58047 ms ago, cancelled=false, msg=org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
以上,就是配置hbase做hugeGraph持久化数据层的方式及原理。
2.2、MySql做持久化配置——
hugegraph.properties增加以下配置即可——
backend=mysql
serializer=mysql
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306
jdbc.username=root
jdbc.password=root
jdbc.storage_engine=InnoDB
四、hugegraph与hugegraph-hubble启动服务
配置完后,就可以启动hugeGraph了——(这里需要注意,首次启动,需要进行初始化,初始化指令为bin/init-store.sh,执行完后,再进行服务启动)
[root@slave2 bin]# ./start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://192.168.200.153:8099/graphs).OK
Started [pid 39235]
当HugeGraphServer服务成功启动后,就可以开始安装启动web图管理界面 hugegraph-hubble1.5.0了。
上传至虚拟机,解压,进入到/hugegraph-hubble-1.5.0/conf目录,修改hugegraph-hubble.properties文件,我修改后的参数主要为以下——
//允许本机与本机之外的机器访问
server.host=0.0.0.0
//图管理页面端口
server.port=8088
gremlin.suffix_limit=250
//顶点默认查询数量
gremlin.vertex_degree_limit=100
//边默认查询数量
gremlin.edges_total_limit=500
gremlin.batch_query_ids=100
配置完成后,启动hugegraph-hubble——
[root@slave2 bin]# ./start-hubble.sh
starting HugeGraphHubble....OK
logging to /app/hugegraph-hubble-1.5.0/logs/hugegraph-hubble.log
完成后,浏览器上访问http://192.168.200.153:8088/
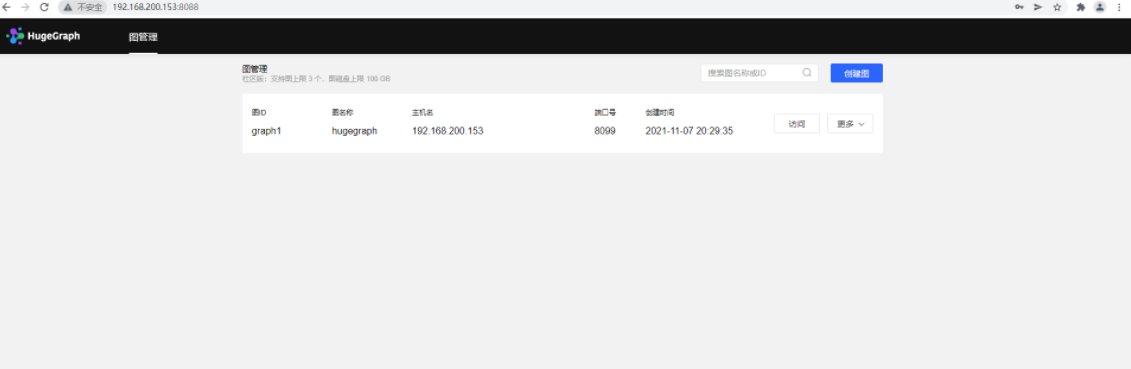
截图里,我已经创建了一个图,社区版本允许最大创建三个图。
平台的模块使用流程如下:

创建图的方式很简单,直接点击创建图,弹出框上填入相关服务器配置信息即可,可参考我已经配置好的——
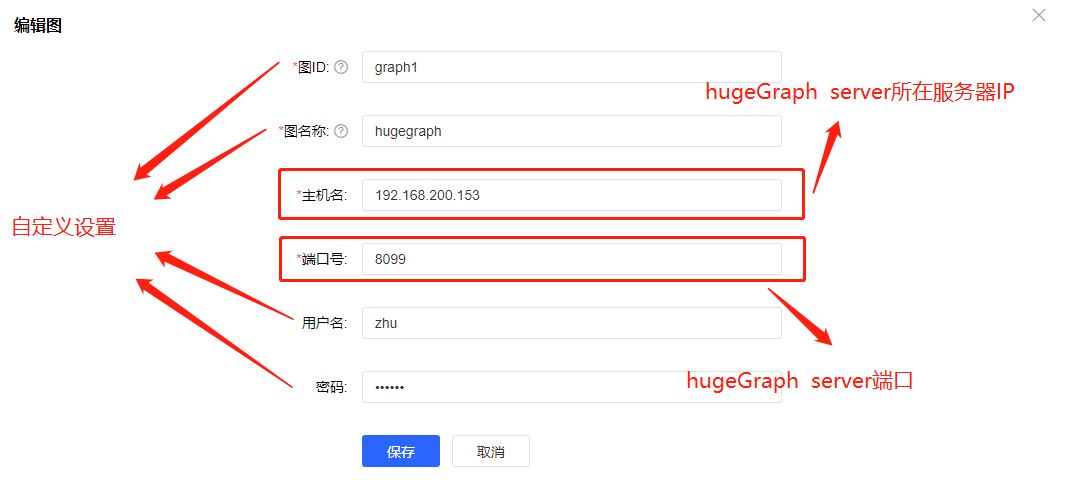
这里主机名和端口号的参数需根据hugegraph.properties配置的ip与端口进行设置。
创建完成后,就可进入到图管理页面了——
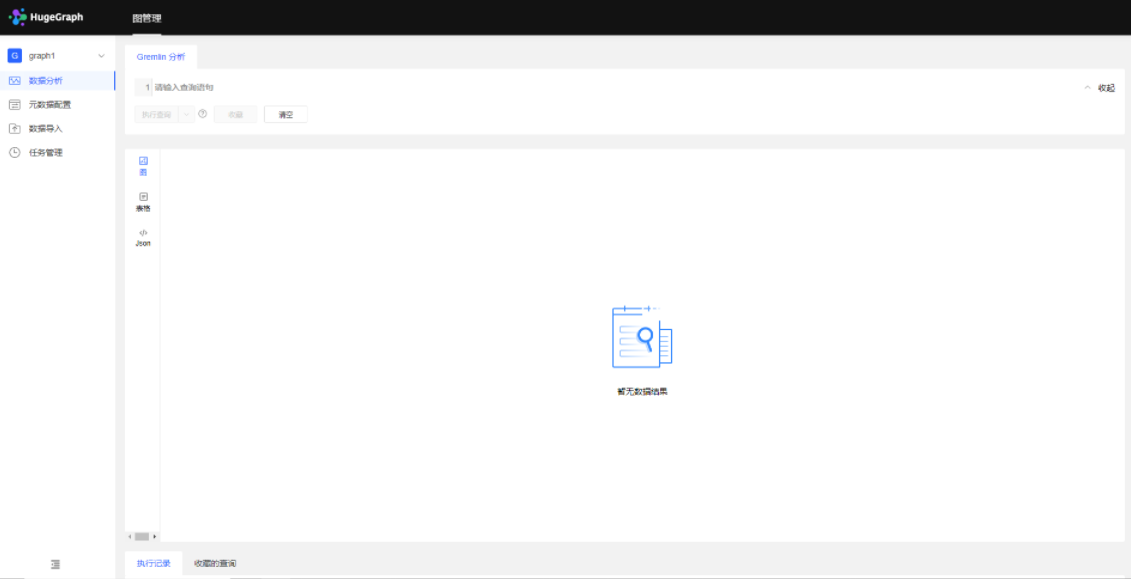
我将在下一篇文章当中,分享如何居于hugegraph-hubble图管理进行图实例设计与图分析。